Figure 10-1. A simple multicast network
Most TCP/IP applications operate like a telephone conversation. That is, one device makes a connection with another, they exchange information, and then they disconnect. This activity is appropriate and efficient for some types of applications. Allowing any device to call up any other device avoids the overhead of maintaining a mesh network in which every device is permanently attached to every other.
There are some types of applications that do not work well in this telephone-call model, though. For example, it would be extremely inefficient to run a radio station this way. Radio stations work by broadcasting a single signal. This common signal is received by many end devices simultaneously. Thus, everybody who listens to this station hears the same news or music at the same time. It would be extremely inefficient if this simultaneous broadcast required sending the same signal separately to every device.
Sending the same signal thousands of times is not only inefficient on the server; it also uses the network bandwidth poorly. Radio and television broadcasting are effective partly because the signals are sent only once. Sending the signals once allows a much higher-quality signal to be transmitted than what would be possible if the available bandwidth had to be broken into a separate channel for every listener or viewer. All receivers share the same signal and the same bandwidth.
IP networks have exactly the same problem of limited bandwidth resources, so the IETF has developed a set of standards that allow for multicast IP applications.
There are three parts to a successful implementation of a multicast application. First, the server and the application must have a sensible way of sending multicast information. This means in part that the application must have enough duplication of information that it makes sense to send it as a multicast.
Second, the network must be able to handle multicast traffic. There are many subtle aspects to this ability. The multicast information should reach only those devices that want to see it to avoid wasting the resources of devices that don't care about this application. The network needs a way to duplicate the flow whenever it hits a fork in the road. The network also needs some way of figuring out which end devices listen to each multicast stream so that it can deliver them appropriately.
Third, the end devices that receive the multicast data need a way to identify this traffic and process it into something meaningful. By definition, it is not addressed to them directly. Yet somehow it must be addressed so that only those devices that listen in on this data stream will pick it up.
Chapter 5 pointed out that the range of IP addresses from 224.0.0.0 to 239.255.255.255 is reserved for multicast addressing. Chapter 4 noted that in Ethernet, the lowest bit in the first octet of any multicast Ethernet MAC address is always 1.
The IETF reserved a block of Ethernet MAC addresses for IP multicast purposes. The addresses fall into the range spanning 01:00:5E:00:00:00 to 01:00:5E:7F:FF:FF. Looking at this in binary, 23 bits can be used to express each multicast address uniquely. That is, there are 2 full 8-bit bytes plus 7 bits of a third byte.
However, in the multicast range of IP addresses, there are three full bytes plus four bits in the first byte of the address. So this gives a total of 28 bits to specify unique multicast IP addresses. No matter how these IP addresses are encoded into MAC addresses, there will be some overlap.
The rule for converting between multicast IP addresses and Ethernet MAC address is to copy the 23 lowest-order bits of the IP address into the 23 lowest-order bits of the MAC address. For example, the multicast IP address 224.0.0.5 is used by OSPF for routers to update one another efficiently. The corresponding MAC Ethernet address is 01:00:5E:00:00:05. However, there could easily be a multicast application using a multicast IP address of 225.0.0.5, or even 224.128.0.5. The corresponding Ethernet MAC addresses for both of these addresses are exactly the same as the OSPF address, 01:00:5E:00:00:05.
This situation is not a problem because the IP protocol stack on the device that is listening for OSPF updates always checks the IP address to make sure that it has the right data stream. The same end device can even take part in both applications because the multicast protocol simply delivers the two data streams to the appropriate applications by using their destination IP addresses.
For Token Ring networks, the addresses come from a similar rule, but with a different byte ordering. The byte-ordering rule for converting Ethernet to Token Ring addresses is discussed in Chapter 4.
As discussed earlier in this book, there are IP-address ranges that anybody can use anywhere for any purpose, provided that they don't appear on the public Internet. These address ranges, like 10.0.0.0, allow network designers to develop flexible, internal addressing standards.
The same is also true for multicast IP addresses. The range of IP multicast addresses from 239.0.0.0 to 239.255.255.255 is reserved for "administratively scoped multicast" purposes. This means that these multicast addresses are purely local to a network. No multicast applications using an address in this range can pass into the public Internet.
In addition to this address block for administratively scoped multicasting, there are a two other important blocks of multicast IP addresses. For multicast traffic that is local to a segment and used for low-level network-topology discovery and maintenance, such as OSPF and VRRP, there is a block of addresses from 224.0.0.0 to 224.0.0.255.
However, all other well-known multicast applications are assigned addresses in the range from 224.0.1.0 to 238.255.255.255. These addresses must be registered to be used—in contrast to the administratively scoped multicast addresses, which can be used freely. A current list of registered multicast addresses can be found online at http://www.iana.org/assignments/multicast-addresses/.
The way a multicast application works is relatively simple in concept. It is quite similar to the earlier example of a radio transmission. The server has a designated multicast IP address for the application. When it wants to send a piece of information to all of the listening devices, it simply creates a normal IP packet and addresses it to this designated multicast IP address. The network then distributes this packet to all devices that take part in this multicast group. The server generally knows nothing about who those group members are or how many there are. It just sends out packets to these multicast addresses and relies on the network to deliver them.
The most common type of multicast application operates in a simple one-to-many mode. That is, a central server sends the same information to a large number of client devices. This server might send out stock quotes or news stories, for example. Each time it has a new piece of information to disseminate, it just sends it out in a single multicast packet to the common multicast IP address.
The listening devices have some special work to do, however. Usually, an IP device just listens for its own IP address and its own Layer 2 MAC address. When an appropriately addressed packet comes along, it picks it up and reads it. If this device takes part in one or more IP multicast applications, it must also listen for these multicast IP addresses and the corresponding multicast MAC addresses. Conceptually, this is not difficult to understand, but it means that these devices need to have special multicast extensions to their IP protocol stack. Thus, not all end devices are capable of running multicast client software.
The listening devices can receive the multicast packets in two ways. They might be on the same Layer 2 medium (the same Ethernet segment, for example), in which case they receive the multicast packets directly. Or, they might be somewhere else in the network, in which case the network has to figure out a way to get the packet to the clients.
The network knows where the clients are by using the IGMP protocol, which is discussed in the next section. That protocol only works once the clients and the server know about the multicast IP address for this application. This address can be assigned statically, as in the previous OSPF example.
Multicast applications are deployed dynamically in some cases. This deployment requires another protocol that is responsible for dispensing and managing multicast IP addresses, similar to how DHCP dispenses and manages normal IP addresses. The protocol for doing this is called MADCAP. It is defined in RFC 2730.
Some organizations might find it useful to use dynamically assigned, multicast IP addresses. However, there is significant overhead in using MADCAP, just as there is in DHCP. It requires the existence of one or more specialized MADCAP servers to manage and dispense these addresses. Of course, these servers must be maintained, just as DHCP servers are. Before deploying a MADCAP server, it is important to figure out how frequently the organization needs to allocate dynamic multicast IP addresses. In many cases, it is easier to simply work with static addressing.
There is one important multicast example that makes extensive use of dynamic multicast addresses. This is the general class of conference-type applications. In this case, a large number of end devices wish to share data with one another, similar to a telephone conference call or a mailing list. In this case, all (or many) of the devices either send or receive data to the multicast group address. There is no central server in this configuration, as it is the multicast equivalent of peer-to-peer communication. To let these conference groups spontaneously form and then spontaneously disband again, it is necessary to use dynamic multicast addressing. This, in turn, requires one or more MADCAP servers to manage this dynamic addressing process.
Note that multicasting in IP is always essentially one-way communication. Each multicast server is the base of a tree. The leaves of this tree are the devices that listen to the multicast. There is no backward communication from the client to the server. If the application requires that the multicast client devices talk back to the server, then this must be done through some other method. A common example would be to use standard unicast UDP packets to communicate from the client to the server. In that case, each device that can send multicast packets to the group is itself a root to a multicast tree.
The point is that the network must work out each of these paths separately. The existence of more than one server talking to the same group means extra work for the network in determinining how the downstream relationships work.
Also note that the multicast server is not necessarily a member of the multicast group. If it is a member, then it will receive the packets that are sent to all group members, including the ones that it sends.
In an application with one multicast server, it would be quite reasonable for this server to not be a member of the group. However, if there are several servers, then it might be useful to the application if these different servers kept track of what information the others were sending.
The protocol that handles multicast group membership is called Internet Group Management Protocol (IGMP). It is currently in its second version, which is defined in RFC 2236. A third version is currently under development, but is not yet published.
IGMP operates locally between end devices and their first-hop routers. Some version of IGMP is required on every device that supports IP multicast functionality.
The basic operation is relatively simple. When an end device wishes to join a multicast group, it sends a multicast packet to the local LAN segment reporting that it is now a member. If this device is the first member of the group on that segment, then the router has to start forwarding multicast packets for this group onto this segment. IGMP doesn't tell the router how it should find this multicast group if it isn't already receiving it. That router-to-router functionality is the responsibility of other protocols such as MOSPF and DVMRP.
Periodically, the router polls the segment to find out if all members of a group have stopped listening. If there are no responses for a group, then it stops forwarding multicast data for that group.
The idea is simply to avoid congestion that would be caused by sending all multicast packets everywhere in the network. IGMP makes it possible to restrict multicast traffic to only those LAN segments where devices listen to that specific multicast data stream. The router doesn't keep track of which specific devices are members of which groups. It only registers that there is at least one member of a group. As long as there is one member, it forwards the group's multicast data stream.
The main differences between Versions 1 and 2 have to do with groups that change membership quickly and bandwidth-intensive multicast applications. If the membership in a group changes quickly, it can be difficult to know when the last member of the group left. Thus, IGMP Version 2 includes a number of features to help with this termination process. This process is particularly important for multicast groups that consume large amounts of bandwidth. For these applications, the network needs to keep track of membership very closely. Keeping track of it allows the network to conserve bandwidth resources that would otherwise have been consumed by this heavy data stream.
Versions 1 and 2 interoperate well. It is possible to have a mixture of both Version 1 and 2 routers and end devices on the same LAN segment without causing problems. The segment is not able to gain the full benefits of Version 2 in this case, however.
A third version is currently under development. Although it has not yet been published, at least one router vendor has already started to release equipment that uses this new version. Version 3 includes new features to restrict which devices are allowed to send multicast data streams. The receiving devices can specify multicast servers by their source IP address. Specifying these servers has security benefits, as it makes it more difficult for unwanted devices to act as multicast servers. A malicious multicast server can insert unwanted data into another multicast data stream. In most security-sensitive multicast applications, the data stream is encrypted. This encryption makes it difficult for the malicious server to insert bad data. However, it is still possible to use this technique to launch a denial-of-service attack.
The new features of Version 3 also make it possible to optimize bandwidth better by restricting which multicast servers are received on which LAN segments.
Although it is not the best way to solve the problem, source-address restrictions of this kind can be used to help enforce scope. This issue is discussed later in this chapter.
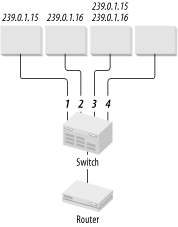
One of the most useful recent developments in multicast networking is the ability to run IGMP on LAN switches, as well as routers. If devices are connected directly to switch ports, then, ideally, the switch should forward only multicast traffic for the groups to which each device belongs. Suppose, for example, that a switch connects to four devices that receive multicast data, as shown in Figure 10-1. The device on Port 1 receives group 239.0.1.15. The device on Port 2 receives 239.0.1.16. The device on Port 3 receives both of these groups, and Port 4 has no multicast membership.
If the switch understands the IGMP packets as these devices join their respective multicast groups, then it can forward the multicast data selectively. If the switch doesn't understand IGMP, then all four devices will see all of the multicast traffic. This is not a problem for Port 3, which sees both groups anyway, but Port 4 doesn't require any of this traffic. Ports 1 and 2 only want to see the groups to which they belong. This is particularly useful in a VLAN environment, where there can be large numbers of devices sharing the same broadcast domain.
Not all switches support IGMP, but it is an increasingly popular feature. It is most frequently seen on switches that have other Layer 3 functionality, such as Layer 3 switching.
Although IGMP does a good job of managing groups at the network layer, it does not include application-level functionality. That is, it allows individual devices to join existing groups only if they know the multicast IP address corresponding to that group. It does not provide a way for users to find out what multicast services are offered. It cannot determine the dynamically generated, multicast IP address for a particular application. Suppose, for example, that a user wants to join a multicast group that disseminates a news service. This service might be set up so that it always uses the same multicast IP address. In this case, the application can simply have this static address hardcoded into its configuration. If this application uses dynamically generated addresses or if the client application simply doesn't know the multicast address, then none of the protocols discussed so far provide a way for it to learn this information.
This deficiency is well known, and a group within the IETF called the Multiparty Multimedia Session Control Working Group (MMUSIC) is currently working on solving it. The focus of this group is to develop protocols that are appropriate for large-scale multimedia applications. Small-scale applications do not have the same scaling problems as large-scale applications. If there are only three clients to a server, then it is much easier to build the application so that the server simply talks to the clients directly.
The reason for the focus on multimedia applications is simply that the applications are the most likely areas where multicast transmission will be useful.
MMUSIC currently has several higher-layer protocols in development used to manage groups and their members. The problems have been broken down into a number of key phases such as group creation and destruction, announcing new groups, and inviting members to join. To accomplish this task, they have worked on protocols such as Session Initiation Protocol (SIP), Session Description Protocol (SDP), and Session Directory Announcement Protocol (SDAP). As of the time of writing this book, these protocols were still not fully adopted as standards, and there were no available commercial products based on them.
For the time being, multicast applications must rely on other methods for handling group membership. Thus, most applications currently work with static addressing, or the clients query a known server to find information about the multicast groups it currently uses.
Routing of multicast traffic is different from standard IP routing. Because multicast traffic is essentially one way, the network only cares about how to route traffic from the multicast server to the various listening devices. All devices share the same multicast IP address. They are scattered throughout the network randomly. To make the problem harder, these end devices can join and leave multicast groups as often as they like.
The edge routers communicate with the end devices directly using IGMP. These routers always know which multicast groups they need to forward. In a large network, there is a significant possibility that the edge routers are not already receiving this multicast group. In this case, these routers have to have a way to look for the required groups from other routers in the network.
A few multicast routing protocols have been developed to allow routers to find and forward multicast groups as required. The most popular protocols are Multicast OSPF (MOSPF), Distance Vector Multicast Routing Protocol (DVMRP), and Protocol Independent Multicast (PIM). It is not possible to implement a multicast network involving more than one router that doesn't involve such a protocol.
Not all of the following were considered official standards at the time of writing this book, however. Therefore, it may prove difficult to find commercial equipment that supports one or more of them. For all of its promise, IP multicast networking is still in its infancy.
MOSPF is a set of extensions to OSPF that efficiently handles routing of multicast traffic. As in OSPF, MOSPF is a Link State algorithm. All multicast routers in an MOSPF area have identical copies of the Link State database. The Link State database for conventional OSPF keeps track of the status of the various IP connections on all routers in the area. In MOSPF, on the other hand, the Link State database keeps track of where all of the multicast group members are. For each multicast group, there are one or more servers and one or more group members. Every router running MOSPF builds a shortest-path tree not from itself, as in OSPF, but from the source to all of the destinations. In this way, MOSPF builds a reliable and loop-free multicast routing table for every group. This table updates dynamically as the group membership changes.
At many points in this shortest-path tree, there will be branch points where the same packet has to go to two downstream neighbors. MOSPF attempts to minimize the number of branch points, using common links wherever possible. At a certain point, however, it is necessary to split these data streams.
MOSPF takes care of not only the routing, but also tells the router where and how to forward and duplicate packets. This information will be different for every different multicast group. The branch points will change as group membership changes. The packets for each group are only forwarded down links that lead to group members. Bandwidth efficiency means that this information should not be sent anywhere it isn't needed. All of this information must be dynamically updated.
One of the biggest advantages to MOSPF is that it scales well over large networks, just like OSPF. It also interoperates well with OSPF. Thus, MOSPF is a natural choice for the multicast dynamic routing protocol in any network that already uses OSPF.
DVMRP is, as the name suggests, a distance vector protocol. It was the first dynamic, multicast routing protocol. As such, it is missing many useful features and optimizations that are available in later protocols. However, it is simple and easy to configure in most networks, especially for networks that use another distance vector protocol such as RIP or IGRP, for regular IP routing. It may be the most natural choice in these cases.
DVMRP uses IGMP as one of its basic tools. When an end device joins a multicast group, it informs its local router using IGMP. This router then uses IGMP to tell all of its neighbors that it, too, is a member of this group. Then, to eliminate loops, DVMRP takes advantage of the fact that the path back to the source is unique. It assumes that this same path can be used in the forward direction as well. Using it in the forward direction allows each router to calculate the best path back to the source. It can then simply request multicast packets for this group from whatever router is one hop closer to the multicast source.
Unfortunately, DVMRP suffers from many of the same scaling problems as other distance vector protocols. It is probably not the best choice in a large network.
PIM can operate either in dense or sparse mode. Dense mode means that routers send all group information to all neighbors. They then prune back the links that do not require particular groups.
Dense mode is efficient when there are relatively few groups and when membership is widespread throughout the network. However, if the network supports a large number of dynamic multicast applications, dense mode is extremely inefficient. (Technically, DVMRP is also considered a dense-mode protocol.)
In sparse mode, on the other hand, individual routers send their neighbors explicit messages asking that they be included or excluded from forwarding particular groups, as downstream devices join or leave these groups. Protocol Independent Multicast—Sparse Mode (PIM-SM) is defined in RFC 2362. This protocol is much more complex than either MOSPF or DVMRP. It includes the ability, for example, to switch from a semistatic forwarding structure based on "rendezvous points" to a dynamic shortest-path tree depending on traffic volume. This switch can be made on a group-by-group basis, according to a locally configured volume trigger.
PIM-SM scales very well to large networks, although setting it up is complicated. This protocol is a good choice for a large network whose unicast IP routing protocol is not OSPF. EIGRP networks, for example, are good candidates for PIM-SM multicast routing.
Since most of the unicast routing information through the public Internet is maintained with BGP, the IETF has added multicast extensions to this protocol as well. The extended protocol is called Border Gateway Multicast Protocol (BGMP). However, the public Internet does not fully support multicast routing yet. Isolated pockets of the Internet do support it, including an experimental multicast backbone called MBONE. The main use of BGMP is to enable inter-Autonomous System multicast routing within an organization. In this case, it is often easier to simply use DVMRP or PIM instead.
If a network is going to support multicast traffic, it is a good idea to carefully evaluate which protocols will be used. This decision depends on what protocols are used in the handling of regular unicast traffic, as well as the nature of the applications. In particular, if a network uses OSPF for its unicast routing protocol, it is natural to use MOSPF for the multicast routing. These two protocols interoperate well. It is not even necessary to convert all routers in the network. Conversion can be done in stages.
However, there is one important case when OSPF and MOSPF can cause problems for one another. On any LAN segment that holds several OSPF routers, one of these routers will become designated router (DR) for the segment. A second router will become backup designated router (BDR), and the others will have no special status. The DR router will then handle all Link State flooding for the segment, and it will also summarize all routing information for this segment to the rest of the network. The DR for OSPF will also be the DR for MOSPF.
So if a segment has a mix of OSPF and MOSPF routers, it is critical that an MOSPF router must be the DR. Otherwise, no multicast routing will be correctly handled on this segment. This routing is easily handled by setting the OSPF priorities to zero for all non-MOSPF routers on the segment.
Other than this, MOSPF can be easily deployed to any network that already runs OSPF. The area structures, including the Area Border Routers (ABRs), and Autonomous System Border Routers (ASBRs) all map readily from one to the other. Naturally, this implies that if multicast traffic is to flow between areas, the ABRs must run MOSPF.
Similarly, to allow multicast traffic to flow between Autonomous Systems (ASes), the ASBR devices must also have MOSPF. Of course, having MOSPF also implies that some sort of exterior gateway protocol that supports multicast routing exist between the ASes.
Another important design consideration for multicast networks is whether the LAN switches can take part in IGMP. By default, only the routers run IGMP. Consequently, every time one device on a VLAN joins a multicast group, the entire VLAN sees all of the group traffic. The traffic load can become rather heavy if there are many multicast groups, each with a small number of members.
Many newer LAN switches see the IGMP requests. As each device joins a particular multicast group, the switch starts allowing traffic to pass to the corresponding LAN port. Ports connecting to devices that are not members of this multicast group do not receive this traffic.
If the switches can go further than this and support IGMP over trunk links, then the protocol is much more efficient. If none of the downstream switches contain members of a particular multicast group, then there is no need to forward multicast traffic out of the trunk port. Not forwarding the traffic may save a great deal of valuable trunk bandwidth.
So far, I have avoided talking about one of the most important potential problems with multicast networks—scope. Returning to the earlier radio analogy, radio stations have severe restrictions about how much power they can use to transmit signals. These restrictions have the effect of limiting how far these signals travel. A local radio station in one country might broadcast using the same frequency as another radio station in another country. There may even be other radio stations in a distant part of the same country using the same frequency.
If every radio station in the world had to have a distinct frequency, radio receivers would become much more cumbersome. A lot of transmissions, such as weather or traffic reports from a distant part of the world, are probably not of universal interest.
Multicast applications have exactly the same characteristics. Worse still, many commercial multicast application vendors always use the same static multicast address. If Company X and Company Y both implement multicast applications on their networks using the same type of server, then they probably use the same multicast IP address. Thus, it is often necessary to restrict how far multicast traffic goes. Even within a particular organization this restriction is often important, as one department may not care about the multicast applications in another department.
The original method for controlling this sort of scope was to use the IP Time to Live (TTL) field. This is a standard field in the IP packet header that is used only for loop elimination in conventional traffic.
Most unicast applications don't restrict how far apart the client and server can be. These applications simply set the value to its maximum value, 255. As I mentioned in Chapter 6, the main use for this field is to help to eliminate loops. However, for multicast applications in particular, TTL can also be a good way to restrict scope.
TTL is a standard field in the IP header that is always 8-bits long. Thus, it can have a value between 0 and 255. If it has a value of zero, the packet is dropped. However, if the value is anything other than zero, the router receiving this packet decreases it by one. For example, whenever a multicast packet is intended only for the local segment, it always has a TTL value of 1. This is the case with all IGMP traffic, for example.
If there is an application that must be restricted to a small area in the network, the server might set the TTL field to a small number like 4. Then the packet will travel three hops before being dropped. It is possible to go even further when restricting traffic. Many routers can be configured to drop any incoming packets that have a TTL value lower than some defined threshold.
A multicast region can be confined by having the server generate the multicast packets with a value that is high enough to reach the farthest corner of the required region. Then all routers that border on the required region would set a TTL threshold value that is high enough to prevent the packets from passing any farther. For example, you might decide that a TTL value of 8 is high enough to get to the entire required area. Then, at all boundaries of the area, you would set a TTL threshold that is high enough to stop the traffic from going farther. Certainly, a value of 8 would be high enough no matter where the server is located in the region.
The trouble with this TTL-based scheme for limiting the scope of multicast zones is its inflexibility. Some applications may need to be confined to the zone, while others need to cover a larger area. Furthermore, it is relatively easy to misconfigure one or more routers and allow multicast groups to leak out of the zone. This leaking could cause serious problems if the same multicast IP address is in use in a neighboring zone for another application.
To address this problem, RFC 2365 defines the concept of administratively scoped IP multicasts. One of the key points in this document is the reservation of the address ranges from 239.0.0.0 to 239.255.255.255 for purely local purposes. Any organization can use these multicast addresses for any purpose. The only restriction is that, like the reserved IP addresses such as 10.0.0.0, they cannot be allowed to leak out onto the public Internet. Furthermore, RFC 2776 defines a protocol called Multicast-Scope Zone Announcement Protocol (MZAP) that handles the boundaries of these multicast zones automatically, preventing leakage between zones.
For most networks, the multicast requirements are far too simple to require MZAP. Indeed, most organizations should be able to get by with a simple TTL-based scope implementation.
Several of the most interesting uses for multicast technology revolve around multi-media applications. However, as discussed in Chapter 8, multimedia applications generally have serious latency and jitter limitations.
For multimedia multicast applications, latency is usually less of a factor than jitter. In live television broadcasting, it is not important if a delay of a few seconds occurs between the actual event and the time remote viewers see it. In fact, television stations use this fact to allow them to edit and censor the outgoing signals.
Latency is not a problem, but jitter is critical. If a stream of video or audio data is sent out to a number of remote receivers, the packets have to arrive in the same order and with the same timing as they were sent. Otherwise, the end application needs to do extensive buffering. In many cases, this buffering is not practical, however. In these cases, the multicast application requires some sort of QoS.
The RSVP protocol is capable of reserving network resources along a multicast path. Many designers developing multicast networks like to use RSVP. But, as I indicated in Chapter 8, a simpler technique based on the IP TOS or DSCP field is usually easier to deploy and frequently more effective in a large network. This is as true for multicast applications as it is for unicast. Before going too far in deploying any QoS system based on RSVP or Integrated Services, it is worthwhile to consider whether Differentiated Services could do the same job with less overhead.