Figure 10-2. IPv6 header options
In the early 1990s the IETF recognized that it was starting to run short of IP addresses. The common practice at that time was for large organizations to connect their networks directly to the public Internet. Every device had to have a registered IP address.
To make matters worse, there was extensive wasting of IP addresses caused by how the address ranges were subnetted. Address ranges were only allocated as Class A, B, or C ranges. It was clear at that time that IP was heading for a terrible crunch as the number of available addresses dwindled away. Thus, the IETF undertook a number of important initiatives to get around this problem. One of these initiatives developed a new version of the IP protocol that had a much larger address space. The result, IPv6, was first published in late 1995.
IPv6 was an ambitious project because, not only did it increase the address range, it also included many of the new optional features that were added to the previous IP protocol (frequently called IPv4) over the years. The engineers who developed this new protocol wanted to build something that would last.
At the same time, two other important initiatives helped alleviate the pressure of the addressing shortage. These initiatives included Classless Inter-Domain Routing (CIDR) and the combination of Network Address Translation (NAT) and unregistered addressing. These topics were discussed earlier in this book.
The problem for IPv6 is that these other developments worked too well at reducing the pressure. After an initial urgent push, adoption of IPv6 has been slow. But these developments only fixed one of the most pressing problems with IPv4—the shortage of address space.
In truth, IPv6 includes many significant improvements over IPv4, not just an increase in address space. There are several good reasons to migrate to IPv6 even though the urgency is gone. However, it will be a long, difficult, and expensive process for most organizations to make this transition, despite the advantages that it may bring. This process has created a barrier to acceptance of the new protocol that will probably persist until external factors force the change. This could happen because of the eventual shortage of IPv4 address, or because of important new services that, for either technical or ideological reasons, are available only over IPv6.
Although several commercial IPv6 networking products are currently available, the protocol has not enjoyed wide acceptance. Very few large organizations have built IPv6 networks. Consequently, a lot of the discussion that follows is somewhat theoretical, as the practical hands-on experience doesn't yet exist.
This is particularly true when it comes to security. The existing IPv4 public Internet is an extremely active testing ground for security concepts, much as a war zone is an active testing ground for military tactics. Whenever a new security measure is developed, somebody tries to violate it. IPv6 has not yet had the opportunity to demonstrate its real-world reliability in this way. Thus, it seems quite likely that there will be some serious growing pains as it reaches wider acceptance.
The presence of this discussion in this book does not mean that I recommend rushing out and implementing IPv6 networks. Rather, it's here because knowing what sorts of technology are coming along in the future is important. If a network designer knows that the network will eventually have to support IPv6, then it can be designed with that eventual migration in mind.
I may be accused of being a Luddite, but I never like to be the first kid on my block with the latest technology. It's usually better to let somebody else find the problems and then get the improved version. This is particularly true when the technology replaces something that has been tested and refined over the course of almost 20 years, as is the case for IPv4. Inevitably, there will be unforeseen problems with the first releases of IPv6 software. It is also inevitable that they will be found quickly and fixed as more networks adopt the new technology. Where you fit into this time line is largely a matter of choice.
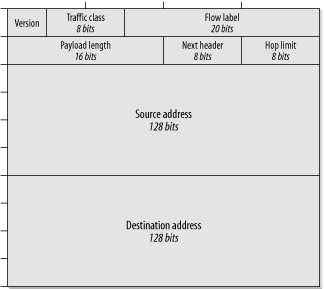
The IETF has taken advantage of the opportunity represented by a new protocol version to simplify the Layer 3 header structure. IPv4 headers have a fixed format involving a large number of optional fields that are frequently unused (or unnecessary). IPv6, on the other hand, uses a much simpler modular approach. The IPv6 header involves several components that can be combined in various ways. The first header is always the standard IPv6 header that contains the source and destination addresses. Figure 10-2 shows this first header format. The layout used in this diagram is becoming a relatively common way to show large binary structures. The marks along the top show the 8-bit boundaries. The marks down the left side show every 32-bit division. In this layout, it is easy to see how the various fields line up with the byte boundaries.
The first field in the IPv6 header is a version code whose value is, simply enough, 6. This field is 4 bits long.
Next comes the 8-bit traffic class field. This field is identical to the DSCP field discussed in the previous chapter. It is used for defining Quality of Service levels.
The third field is the first that is new with IPv6. This field is the flow label. The discussion of IPv4 queuing mechanisms in the previous chapter frequently mentioned traffic flows. In IPv4, these flows are defined by looking at a common set of source and destination addresses along with protocol information. It is important for mechanisms such as fair queuing to identify particular traffic flows uniquely. However, in IPv4, it is extremely difficult to identify them, which causes significant router overhead in identifying and classifying flows. IPv6 gets around this problem by creating a new field that identifies each flow uniquely. The end devices are responsible for assigning a value to this particular traffic stream. This assignment is expected to reduce the CPU and memory loading on routers. At the same time, it should reduce both latency and jitter caused by busy routers having to buffer packets before classifying them.
The payload length field comes next. It is always 16 bits long, making the maximum packet size 65,535 bytes long, although an IPv6 specification exists for longer packets. The value does not include the length of this initial header.
The next header field replaces the Protocol field in the IPv4 header. For the most part, it uses the same protocol identification numbers as IPv4. In IPv6, though, it is also possible to use this field to specify that this header is followed by an IPv6 extension header to give additional functionality. I discuss why this header is important later in this section.
Next comes the hop limit field. This field renames the IPv4 TTL parameter, which is appropriate since the value has nothing to do with time.[1] This is an 8-bit field, which allows for a maximum of 255 hops between any two devices. The IETF believes that this number should theoretically be high enough to accommodate the highest complexity that will ever be seen in the Internet.
[1] The "time" in the name is actually a vestige of the earliest IP implementations. In the early days, the TTL field counted seconds. The meaning gradually shifted from counting time to counting hops as typical per-hop latencies dropped.
Finally, the bulk of this header consists of the 128-bit source and destination addresses.
Remember that this header is always exactly the same length and that the important features, such as the destination address, are always at exactly the same offset. This arrangement was done deliberately to help routers to find these fields easily; it should also help to improve router performance.
After this basic IPv6 header, the packet can have a standard IP data payload. For example, if it is a TCP packet, then everything that follows would look identical to a TCP packet in IPv4. The next header field indicates what comes next. This field is the same as the IPv4 Protocol field. In the case of TCP, a value of 6 is used in the next header field to indicate that what follows will be TCP information.
There are several new options with IPv6. The new header types are called Hop-by-Hop Options, Destination Options, Routing, Fragmentation, Authentication, and Encapsulating Security Payload.
The Hop-by-Hop Options header communicates with each router along the path. As the packet passes through the network, it may be necessary to have each router do something special. For example, the router might include special QoS information or it might be used to help trace a path.
The Destination Options header allows similar special control, but only the ultimate destination of the packet is allowed to react to these options.
A type of source routing is possible with the Routing header. It allows a packet to loosely specify which routers it would like to pass through on its path. A similar feature is present in IPv4, but it is not widely used.
Fragmentation is never done by the network in IPv6. This is another way IPv6 differs from IPv4. In the new protocol, end devices are expected to do a path-MTU discovery procedure and fragment their own packets. The standard specifies a minimum MTU of 1280 bytes. Any device that wants to avoid fragmentation problems and doesn't want to do a path-MTU discovery can always default to this MTU value to avoid problems. Media that cannot support this MTU, such as ATM, are supposed to emulate it with lower-level fragmentation.
The last two types of extension headers, Authentication and Encapsulating, are used for security purposes. These headers will be discussed later in Section 10.3.
While IPv4 uses a 32-bit address, the IPv6 address has 128 bits. This capacity allows over 3 x 1038 different addresses, which is a vast improvement over the IPv4 capacity of roughly 4 x 109. Increasing the available range of addresses was one of the driving forces behind the creation of IPv6. One disadvantage to having these large-number addresses is that they are cumbersome—even to write down. Therefore, the protocol designers have come up with a set of textual conventions for expressing IPv6 addresses.
The 128-bit address is broken down into 8 16-bit segments that can be expressed as hexadecimal numbers separated by colons. Each 16-bit segment is represented by 4 hexadecimal digits. For example, a valid address would be:
1A30:5BFE:0000:48C9:8A10:03BF:7801:0A3F
The sixth and eighth fields in this address have leading zeros. It is not necessary to write down leading zeros. This situation also applies to the third field, which is composed of all zeros. This same address can also be written as:
1A30:5BFE:0:48C9:8A10:3BF:7801:A3F
The IPv6 specification allows any field, including the first and last, to have a binary pattern of either all zeros or all ones (FFFF). In fact, fields with all zeros are expected to be so common that there are special rules for them.
Consider an address with several fields of all zeros:
1A30:0:0:0:8A10:0:0:A3F
The rule is that any string of adjacent zeros can be replaced by the compact form ::. Because this replacement could be extremely confusing, it can only appear once in an address. Thus, this address can also be written as follows:
1A30::8A10:0:0:A3F
To take this notation to extremes, the new loopback address to replace the IPv4 127.0.0.1 is 0:0:0:0:0:0:0:1, which can be written simply as ::1.
Another notation for these addresses is used for expressing IPv4 addresses for IPv6. This notation is used to allow tunneling IPv4 packets through IPv6 networks without requiring explicit tunnels—a technique that is discussed later in Section 10.2.7.
There are two ways that IPv4 addresses can be encoded within IPv6 addresses. IPv6 devices, such as routers able to communicate in both IPv4 and IPv6, have addresses that are simply 6 16-bit groups of 0s (96 bits) followed by the 32 bits of the IPv4 address. Pure IPv4 devices whose traffic is tunneled dynamically through an IPv6 network have a slightly different address format. In this case, the address consists of 5 16-bit groups of 0s (80 bits), then 1 16-bit group of 1s, followed by the 32 bits of the IPv4 address.
To see some examples of this, imagine an IPv6 part of the network, and suppose that it must communicate with an IPv4 device. Suppose there is an IPv6 device whose IP address appears to the IPv4 world as 10.1.15.223. This device communicates with an IPv4 device whose address is 10.0.192.17.
In the IPv6 part of the network, these addresses are written with the last 2 16-bit groups written out in IPv4 format. The first 1 will be 0:0:0:0:0:0:10.1.15.223, and the second will be 0:0:0:0:0:FFFF:10.0.192.17. Of course, these addresses can also be written as ::10.1.15.223 and ::FFFF:10.0.192.17, respectively.
To denote address prefixes, the notation is derived from the IPv4 CIDR notation. A subnet that has an address range from 1A30:5BFE:0:0:0:0:0:0 to 1A30:5BFE:FFFF:FFFF:FFFF:FFFF:FFFF:FFFF would be written as 1A30:5BFE::/16.
As with CIDR, this address could represent a number of smaller subnets, such as 1A30:5BFE::/48 and 1A30:5BFE:1::F300/120.
The IPv6 addressing architecture defines several reserved ranges for special purposes. This definition is based on the leading bits in the address. I already mentioned a few special cases such as loopback addresses and the embedding of IPv4 addresses. These adresses both fall into the first reserved range, which begins with eight bits of zeros. Table 10-1 shows the initial address allocations.
|
Binary |
Hex of first field |
Allocation |
|---|---|---|
|
0000 0000 |
0000 to 00FF |
Reserved |
|
0000 0001 |
0100 to 01FF |
Unassigned |
|
0000 001 |
0200 to 03FF |
NSAP |
|
0000 010 |
0400 to 05FF |
IPX |
|
0000 011 |
0600 to 07FF |
Unassigned |
|
0000 1 |
0800 to 0FFF |
Unassigned |
|
0001 |
1000 to 1FFF |
Unassigned |
|
001 |
2000 to 3FFF |
Aggregatable Global Unicast Addresses |
|
010 |
4000 to 5FFF |
Unassigned |
|
011 |
6000 to 7FFF |
Unassigned |
|
100 |
8000 to 9FFF |
Unassigned |
|
101 |
A000 to BFFF |
Unassigned |
|
110 |
C000 to DFFF |
Unassigned |
|
1110 |
E000 to EFFF |
Unassigned |
|
1111 0 |
F000 to F7FF |
Unassigned |
|
1111 10 |
F800 to FBFF |
Unassigned |
|
1111 110 |
FC00 to FDFF |
Unassigned |
|
1111 1110 0 |
FE00 to FE7F |
Unassigned |
|
1111 1110 10 |
FE80 to FEBF |
Link-Local Unicast Addresses |
|
1111 1110 11 |
FEC0 to FEFF |
Site-Local Unicast Addresses |
|
1111 1111 |
FF00 to FFFF |
Multicast Addresses |
Note that in this allocation, most of this range is initially unassigned—but there are some interesting allocations. In particular, the address architecture sets aside space for mapping IPX and OSI NSAP addressing. This space is intended to allow these other protocols to exist effectively as subnets of IPv6 space and to allow communication between the protocols. This space is most likely to be useful as an interim measure when migrating a network from one of these protocols to IPv6.
The Aggregatable Global Unicast Addresses indicated in Table 10-1 are used as the main method of connecting to the public IPv6 Internet. The basic idea is to break down the address range into a hierarchy of ranges and then to assign these ranges to Internet service providers.
Top Level providers connect directly to the Internet backbone. These providers are specified by a 13-bit identifier, so there can be up to 8192 of these Top Level providers.
Below the Top Level providers are so-called Next Level and Site Level address ranges. A Top Level provider allocates a range of addresses to each of their Next Level providers. The Next Level providers allocate 80-bit Site Level address ranges.
If the site then uses the autoconfiguration mechanism described next, 16 bits are left to specify every local network. This is the same size as the Class B range in IPv4.
The point of this hierarchy is to allow several levels of aggregation. Allowing these levels should have the same effect of reducing routing tables that is achieved by using route summarization, as discussed earlier in this book. Achieving this benefit globally across the entire Internet should improve its scalability.
Because IPv6 has so much more address space than IPv4, it should be possible to avoid Network Address Translation (NAT). By eliminating NAT, it should also be possible to eliminate the problems that it causes. For example, the previous chapter discussed how NAT can complicate network management, and earlier sections of this book talked about how address translation can break or complicate many applications.
There are two main reasons for using NAT in IPv4 networks. The first is to allow the use of unregistered addresses. A network of thousands of nodes can be represented by a small number of registered addresses. NAT just replaces the internal unregistered addresses with these few registered ones as the packets cross out of the network. IPv6 also has ranges of unregistered address space. However, the amount of registered adress range is expanded so much that an organization should be able to address every internal device.
The second reason for using NAT in IPv4 networks is security. NAT makes it possible to obscure the internal network architecture. This information can be useful to an attacker. However, IPv6 includes several special security features that should improve the overall security of the network, even without address translation.
Quality of Service (QoS) in IPv6 is essentially similar to that of IPv4. Differentiated Services works in exactly the same way, using the traffic-class field in the main IPv6 packet header. Similarly, Integrated Services accompanied by a reservation protocol, such as RSVP, are supported by the new protocol.
The main thing that is new is the flow-label field in the IPv6 header. This field facilitates much of the work of differentiating and classifying traffic for routers. They are no longer forced to look at several fields to establish when two packets are part of the same conversation. As discussed in Chapter 8, looking at several fields is necessary for many popular queuing algorithms, such as Fair Queuing. IPv6 makes the process much easier.
In some cases, the fields that are used in IPv4 to identify flows are not readily available. For example, when the data stream is encrypted, it is sometimes difficult for the routers to see all of the required fields. By putting a flow-identification field right in the Layer 3 header, IPv6 allows much better control over queuing. As a simple example, suppose a device is connected to the network via a VPN tunnel. This tunnel will carry all of the device's traffic in encrypted form. As this encrypted tunnel passes through a router, all traffic inside of it will appear as a single flow in IPv4. However, this situation may not be desirable. If this device is a user's workstation, it means a file transfer has the ability to choke off an interactive session.
Because IPv6 identifies these different flows separately, it can treat the traffic within the tunnel appropriately. This is extremely difficult to accomplish in IPv4; it requires that different flows be given different DSCP or TOS values before they enter the encrypted tunnel.
IPv6 includes both authentication and encryption options in the protocol at Layer 3. These options make it possible to include in the packet's header an authentication fingerprint that verifies that this packet came from the right source. It is also possible to encrypt packets either as a whole tunnel, as in a VPN, or on an individual basis.
The packet-authentication option is the most important new feature here because it is possible to use VPN-style encryption with IPv4. Authentication of individual packets is much harder in IPv4.
Some common types of Internet security attacks involve spoofing and hijacking. A spoof is when the source address in the packet is not the actual source, but is some other device. Spoofing can be used in many ways. For example, it is possible to send an ICMP ping packet that requests a response from a device. The device that receives this packet sends its response to the source address in the packet. If this source address has been spoofed, then the response is sent somewhere else. If thousands of devices around the Internet all suddenly send unsolicited ping responses to a single device, serious problems can occur. Furthermore, this attack is essentially untraceable.
A hijack attack is similar, except that it involves sending a source-spoofed TCP packet. In this case, the destination has an open TCP session already in progress with the real source device. Thus, it happily accepts the source-spoofed TCP packet that actually originates somewhere else.
In IPv6, these problems should be reduced by the presence of the authentication header. This header is a digital signature that validates the source of the packet. Cryptographers say that the scheme should be extremely difficult to break.
Technically, IPv4 also has the same packet-authentication mechanism available through IPsec. However, IPsec is optional in IPv4, and very few end devices take advantage of it.
Encryption in IPv6 uses the encryption header extension. This extension allows any packet to be encrypted. Of course, it is necessary to have a reasonable way to decrypt the packet when it reaches its destination. Thus, it is probably not practical to encrypt individual packets in a flow. Rather, encrypting an entire conversation is far more effective. Of course, IPv4 has several mechanisms to accomplish the same thing. The industry standard is called IPsec, which forms the basis for the IPv6 implementation as well.
One of the features that IPv6 supporters mention frequently is autoconfiguration of IP-addressing information on end devices. The concept is fairly simple, and it takes advantage of the greatly expanded address space.
Autoconfiguration can occur in either a stateless or stateful way. The stateful method involves the use of an explicit configuration protocol and server, as in DHCP. This method is essentially the same as in IPv4. It is called stateful because the server maintains information about the states of every end device. The stateless autoconfiguration mechanism, on the other hand, allows end devices to deduce enough information by listening to the network, that they can configure themselves.
Combining these two mechanisms is also possible. For example, a device might get its initial basic configuration with the stateless method and then obtain the rest of the information from a server.
The stateless autoconfiguration method is defined in RFC 2462. It is a multiple step process.
In the first step, the device constructs a temporary unicast address using a link-local prefix and its own MAC address. This link-local prefix is a well-defined address prefix that is present on the router, but is not routed off the local segment. Before the device assigns this address to its interface, it sends out a Neighbor Solicitation packet. In IPv4 terminology, this packet is essentially a ping. If there is a response, then there is a conflict, and the address cannot be used.
If the temporary address is not in conflict, the device can carry on with the autoconfiguration process. The next step is to send a multicast Router Solicitation packet to the All-Routers multicast address. This packet finds any routers that have interfaces on the same LAN segment.
One or more of the routers on the segment respond to this query with a Router Advertisement. The response packet can tell the end device that it needs to talk to a DHCP server for either its address, for other required information, or both. Talking to the server is necessary for sites that do not wish to use stateless autoconfiguration or that have important server information that needs to be configured. In the default case, the Router Advertisement packet contains information about the address prefix, which is essentially the same as the IPv4 concept of a subnet and netmask. At the same time, the packet inherently tells the end device about a router that can be used for off-segment traffic.
The device then generates its final address using this address prefix and its own MAC address. Once again, it needs to poll the segment to see if any other devices already use this address. If there is a conflict at either this stage or the earlier link-local address stage, then it is necessary to configure the device manually.
The stateless autoconfiguration method uses the MAC address for the last 64 bits of IP address. On any given VLAN, there is sufficient address space to address over 18 x 1018 devices. This space is extremely wasteful of addresses, but the remaining 64 bits of address range that can be used for the prefix is still far greater than the 32 bits available in the entire IPv4 address.
However, the important issue is not how many bits are in the entire address, but how many bits the organization has available. IPv6 is intended to provide a hierarchical addressing scheme that allows many levels of subnetting. It is possible that an organization will have to use an Internet provider that is many steps removed from the backbone. In this case, it may turn out that they have too few bits to use this stateless autoconfiguration method. For example, suppose that the address prefix for the entire organization is only 72 bits. Then using 64 of these bits for local addressing leaves only 8 bits for defining all of the network segments. This means that the organization can have at most 256 LAN segments, which is definitely not sufficient for many large organizations.
Fortunately, in these cases it is still possible to use an IPv6 version of DHCP to configure the addressing. Using this option immediately opens up the organization's internal address range far beyond the size of the entire IPv4 Internet.
This autoconfiguration method has an extremely important architectural consequence. If end devices listen to the network to determine an appropriate address prefix, then there can only be one address prefix on each LAN segment. Note that this situation is different from IPv4, where a single LAN segment can hold several subnets. In fact, the entire method bears a close resemblance to the system of autoconfiguration used in IPX networks. See Chapter 7 for a discussion of IPX.
The multicast functionality of IPv6 is similar to that of IPv4. The most important difference is that IPv6 no longer has any broadcast functionality. Everything is done with multicasts of various scopes.
This fact is important because the various broadcast types of IPv4 have caused great confusion. For example, IPv4 tried to make distinctions between all-hosts broadcasts and all-networks broadcasts. However, the all-networks broadcast turned out to be incompatible with the hierarchical addressing structure of CIDR, so it had to be dropped.
IPv6 brings back the same functionality by using multicast. Because it allows good control over multicast scope, the problems IPv4 had with controlling the scope of all-networks broadcasts are no longer relevant.
There are several basic levels for the scope of multicast addresses in IPv6. The difference is defined in the last 4-bit section in the first field of the address.
As I mentioned in Section 10.2.2 after Section 10.2, any address whose first field is in the range from FF00 to FFFF is a multicast. The third hexadecimal number actually has only two defined values: 0 or 1. If the value is 0, then it indicates a permanently assigned, static multicast address. A value of 1, on the other hand, specifies that this multicast address is transient. Transient addresses can be generated dynamically for short-lived applications. The rest of the range from 2 to F is left open for future assignment.
The final hexadecimal number in the first field of the multicast address specifies the scope. Only a few of the possible values were assigned. These values are listed in Table 10-2.
|
Assignment |
Value |
|---|---|
|
Reserved |
0 |
|
Node-local |
1 |
|
Link-local |
2 |
|
Site-local |
5 |
|
Organization-local |
8 |
|
Global scope |
E |
|
Reserved |
F |
For example, the multicast address FF01::1 is a static address that is local to the end device. Similarly, any address beginning with FF02 is confined to the local Layer 2 medium, just as IPv4 broadcasts are. Thus, the link-local all-nodes multicast address FF02::1 effectively fills the same role as the IPv4 broadcast address.
For multicasts that leave the segment, there are three defined levels of scope. The multicast can be site-local, organization-local, or global. Global scope means that the multicast reaches the entire Internet. These definitions leave several gaps for future scope definitions.
Anycast is a new feature with IPv6. It was previously proposed in RFC 1546 as a feature for IPv4, but was never implemented. I think anycast is one of the most interesting and potentially useful new features in the protocol. Basically, it is halfway between a unicast and a multicast. It allows the multicast server to send a packet to any group members—usually just the closest group member.
In practice, the network may opt to deliver the packet to more than one group member, and it is also possible that subsequent packets will be delivered to different group members. Therefore, anycast communication is not appropriate for any conversation that needs a concept of what was already said. Instead, it can be used only for stateless applications.
Anycast addresses are taken from the regular unicast address ranges, so there is no intrinsic way of distinguishing them. In effect, each anycast address is simply a unicast address that is assigned to many different hosts. These addresses are then distributed through the network as host routes. This distribution has some potential scaling problems. If the anycast addresses are drawn from a different address range that cannot be summarized easily, then these addresses must exist as host routes in the routing table of every router on the network. If anycast addressing is not allocated carefully, it has the potential to cause serious problems in the future.
Anycast can be useful in many ways. The server can use it, for example, to determine whether it still has any subscribers. By sending an anycast packet that requests a response, the server can discover that it is not currently required and go to sleep. Then it can wake up periodically and do an anycast poll to see if new group members have signed on.
The most exciting possibilities for this feature actually work in the other direction—allowing any of a group of servers to respond to a client request.
IPv4 has several well-known problems with using redundant network devices. For example, it is common to use some sort of traffic-director device to distribute packets to a group of identical servers. This arrangement is most commonly used for web servers. With a traffic-director device, it is necessary to have all servers located both logically and physically together on the network behind this device.
Another method IPv4 uses to accomplish similar levels of redundancy or load sharing is a protocol such as VRRP or HSRP. Typically, these protocols are just used to allow two routers to share the same IP address. Two devices sharing the same address must be able to communicate directly with the same LAN segment.
With anycast, it should be possible to eliminate extra elements such as traffic director boxes and special protocols by just using a single anycast address that represents all servers. The same technique could be used for DNS servers, NTP servers, or any other situation when multiple servers are used for redundancy and load sharing.
In fact, this feature is exciting because an organization could have servers in a dozen countries around the world and users could automatically access whichever one was closest by using the anycast address. Furthermore, if one of these servers was unreachable for any reason, the network would simply find another one transparently.
In general, one would probably not use anycast to provide router redundancy in IPv6. Instead, the specification allows two or more devices to share an IP address on the same LAN segment. There are a number of ways that this sharing could be implemented. This feature will probably emulate VRRP.
The IPv6 protocol has several features designed specifically to help with migration from IPv4. These features include the ability to tunnel IPv6 traffic in existing IPv4 networks, as well as IPv4 in IPv6 networks.
The tunneling of IPv6 in IPv4 requires the manual creation of point-to-point tunnels between IPv4 routers. When IPv4 is tunneled in IPv6, it is possible to have these tunnel generated dynamically. But this tunneling requires the use of a special reserved range of IPv6 addresses.
Many organizations have had to do protocol migrations in the past. For example, some migrations from IPX or Appletalk to IPv4 have allowed users to access the Internet. In the previous generation of networks, migrations involved Banyan, DECNET, and LAT. Thus, the methodology for doing a successful protocol migration has been worked through a few times in different contexts.
Usually, the best way to proceed is to build parallel infrastructure. Building the infrastructure doesn't necessarily mean that all of the equipment needs to be replaced, though. It should be possible to build most of this parallel network over the same gear, using the same physical links, but there must be software changes on the routers and end devices. The equipment all needs to support IPv6, which usually means that a new protocol stack needs to be installed.
In any organization, there will necessarily be legacy equipment that cannot be upgraded and will never run the new protocol. This situation is not a showstopper, however. It can be handled readily using gateway devices to do the protocol conversion. These gateways have a relatively simple job because they only need to replace Layer 3 information in a packet. Everything from Layer 4 up is unchanged in IPv6.
The first step should be to obtain registered IPv6 addresses and decide on a final IPv6 addressing structure. This step, in many cases, simply copies the existing IPv4 structure. Whenever one is given a chance to eliminate flaws in an existing system, however, it's a good idea to at least think about it.
For example, the age of the network may have caused an imbalance in the OSPF areas. Cisco has already announced an IPv6 version of EIGRP. Similarly, an IPv6 RIP and an IPv6 OSPF now exist, so it should not be necessary to change routing protocols. However, the change may provide an opportunity either to change or restructure the routing protocols if the network has outgrown the existing IPv4 structure.
Once the target architecture is clear, the designer needs to figure out how to get there incrementally without taking down the whole network. Only in the smallest offices is it practical to take everything down at once and spend the weekend rebuilding the network.
The other thing to remember is that you don't want just to get to IPv6; you should get to your target architecture. Thus, the migration plan needs to take the network to the ultimate goal as directly and painlessly as possible.
This means, for example, that you probably don't want to make widespread use of temporary IPv6 addressing. IPv6 makes autoconfiguration possible for end devices, and it even includes the concept of a deprecated address to allow a device to change addresses gracefully without losing packets sent to the old address. However, the more changes that you make, the more trouble you will have, so try to go directly to your final addressing structure whenever possible.
Special features, such as dynamic tunnel generation of IPv4 through an IPv6 backbone, will require introducing an extra readdressing phase late in the migration project. Instead, I advocate a migration strategy that involves running both networks in parallel for a period of time and migrating devices from one to the other gradually. The way to implement this migration strategy is to provide dual protocol stacks on both the routers and end devices. The migration can start at the Core by simply upgrading the backbone routers to support IPv6 and defining IPv6 addresses on their interfaces. For the initial phase, there will be no user traffic over this IPv6 backbone structure. Having no user traffic allows the network engineers a chance to test everything.
From the Core, the upgrade can proceed outward to include at least one user community and the servers that they use. It should be possible to keep everything running over the IPv4 infrastructure while observing one or two end devices using IPv6.
At the same time, implementing IPv6 versions of certain network services, such as DHCP and DNS, is necessary. These services can be used to help control the migration, as the end devices consult these servers for their configurations and for information about their servers. When you want a particular user to start using a particular network server through IPv6 instead of IPv4, the DHCP server simply directs the end device to consult the IPv6 DNS server. This DNS server then instructs the end device to use the IPv6 application server. Converting these users to IPv6 should be simply a matter of setting their workstations to prefer the IPv6 view of their applications. If there are problems, converting back to the IPv4 network is simply a user-by-user software change. It should be possible to make most of these changes centrally without extensive use of field technicians.
The converted user workstations need to retain their IPv4 protocol stacks for a while because they still have to access systems that were not converted. However, as more of the network is converted, you will reach a point where the number of legacy IPv4 services is relatively small. At this point, it should be possible to implement IPv4 to IPv6 gateway devices that will do the protocol conversion.
These gateways could even be ordinary routers that are configured to do the conversion. They will probably continue to exist even after the main migration is complete. They will be required to support any legacy IPv4 equipment that is still required but for whatever reason cannot be converted. Once these gateways are in place, it should be possible to eliminate native IPv4 from the end devices gradually, and finally from the routers as well.
Other migration strategies have been suggested in some protocol RFCs. For example, RFC 2529 suggests using a particular range of IPv6 addresses that maps onto the IPv4 address range. Using this range of addresses allows a very direct conversion process because the routers inherently act as gateways between the two protocols. Thus, it should be possible to migrate an entire network quickly by first setting up dual protocols on the routers, as shown previously, and then changing end devices. The new addresses will be IPv6 representations of the old IPv4 addresses.
This method should be quite effective, but remember that it is necessary to then renumber the entire network to the target IPv6 addressing structure. As this renumbering is in progress, the dynamic routing protocol has to keep track of two different ranges of addresses. More importantly, it will have problems summarizing these addresses.
Also note that the IPv6 autoconfiguration mechanism implies that each LAN segment can have only one IPv6 prefix (analogous to the IPv4 subnet address) at a time. Each segment must be converted all at once. This is the second en masse conversion that has to be done. Because of this additional step, I prefer the previously mentioned procedure.