Figure 3-1. Bus topology
There are four basic topologies used to interconnect devices: bus, ring, star, and mesh. In a large-scale LAN design, the ultimate goal includes a number of these segments. Figure 3-1 to Figure 3-4 show these four basic topologies.
Before getting into the solutions, I want to spend a little bit of time making sure that the potential problems are clear. What are the real goals of the network design? What are the options? Ultimately, I want to help point you toward general approaches that can save a lot of worry down the road.
The main goal is to build an infrastructure that allows end devices to communicate with one another. That sounds simple enough. But what is an end device? I don't include network devices when I talk about end devices. This fact sounds pedantic, but it's important. A network device is one that cares about the lower layers of the protocol stack. It exists to facilitate the flow of traffic between end devices. End devices are the devices that care about Layer 7. End devices run applications, request data from one another, present information to humans, or control machinery; most importantly, end devices should never perform network functions.
Why do I make this point? I believe that a number of common practices on networks are dangerous or at least misguided, and they should be stopped. Here are some examples of cases in which end devices are permitted to perform network functions (such as bridging or routing) at the expense of network stability:
File servers with two LAN NIC cards, configured to bridge between the two interfaces
Application servers with one or more WAN cards in them that allow bridging or routing
Servers with any number of NIC cards taking part in dynamic routing protocols such as RIP or OSPF
In each of these cases (which I am quite sure will get me in trouble with certain vendors), an end device is permitted to perform network functions. No file or application server should ever act as a router or a bridge. If you want a router or a bridge, buy a real one and put it in. Note that I am not talking about devices that just happen to have a PC form factor or use a standard PC CPU. For example, a dedicated firewall device with a specialized secure operating system is a network device. As long as you refrain from using it as a workstation or a server, you're fine. But in no case should a file or application server act as a bridge or a router.
The concern is that any device that is not dedicated to performing network functions should not be permitted. Furthermore, with the exception of highly specialized security devices such as firewalls and similar gateways, using any general-purpose computing device in a network function is a bad idea. So, even if you only use the Linux PC as a router, and that's the only thing it does, it is still going to be less reliable and probably more expensive than using a device designed from the outset as a router. I don't like home-rolled network equipment. Real routers and switches are not very expensive, and trying to build your own is not going to save you any money in the long run, no matter how good of a programmer you are. At some point in the distant future, somebody else will inevitably have to deal with it and will fail to understand the unique system.
The same thing is true in reverse. Network devices should not perform Layer 7 functions. No router should run an email server. No firewall should be a web or email server. Sometimes you will run applications on your network devices, but they are never Layer 7 functions. For example, running a DHCP server from a router might be expedient. Or, having a web server on a router is often worthwhile if it is used only for the purposes of managing the router itself in performing its network functions. Having a Network Time Protocol (NTP) server running on your network equipment, with all other devices synchronizing their clocks to "the network" is also useful. But these are all very specific exceptions, and none of them are really user applications.
Failing to separate network functions from application functions creates so many problems that it is hard to list them. Here are a few of the most compelling:
Generally, network engineers are not properly trained to deal with application issues. In most organizations, there are staff members who are better equipped to manage applications and servers. These people can't do their jobs properly if the network staff controls the resources. For example, if the corporate web site is housed inside of the corporate firewall, how effectively will the web mistress work with it? What if a bug is in the web server? Upgrading code could mean taking the whole Internet connection offline.
The same situation is true of devices that include email functions such as POP servers with network functions. Such devices, if also central components of the network, make maintenance on the email server extremely difficult.
Running applications is hard work. Running network functions is also hard work. Doing both at the same time often creates serious memory and CPU resource problems. These problems tend to occur during the most busy peak periods of the day, thereby breaking not just the application, but the entire network when it is most needed.
I've already indicated that the network must be more reliable than any end device. If the network is an end device, then it presents an inherent reliability problem.
If an end device takes part in a dynamic routing protocol such as RIP or OSPF, and it is either misconfigured or suffers a software bug, then that one end device can disrupt traffic for the entire network. This is why no end device should ever be permitted to take part in these protocols. There are much more reliable ways of achieving redundancy, which I will discuss throughout this book.
Finally, it is common for file servers with multiple NICs to be configured for bridging. Having multiple NICs can be very useful—it might allow the server to exist simultaneously on several segments, or it might allow the server to handle significantly more traffic. But if these NICs are also permitted to bridge or route traffic between them, they can easily create network loops that disrupt traffic flows. These bridging and routing functions should always be disabled on servers. Consult your server vendor for information on how to ensure that these functions are disabled.
With respect to running dynamic routing protocols on an end device, a device might passively listen to a routing protocol (particularly RIP) but not send out routing information. This situation is certainly less dangerous than allowing the end device to affect network routing tables, but it is still not a good idea; in a well-designed network, no end device should ever need to care how the network routes its packets. It should simply forward them to a default gateway and forget about them. Part of the problem here is that RIP in particular can take a long time to update after a failure. In general, allowing the network to take full responsibility for traffic flow is more reliable.
In a bus topology, there is a single communication medium,
which I often call "the wire." It actually doesn't need to be a physical piece
of wire, but a wire is a useful image. In fact, 10Base2 Ethernet looks exactly
like Figure 3-1, with a long 50
![]() (50 ohm
characteristic impedance) coaxial cable connecting all of the devices. Because
of the analogy with 10Base2, it is customary to draw an Ethernet segment like
this, with a straight line intersected at various points by the connections
(sometimes called "taps") to the various devices. In the drawing, this line (the
wire, or bus) extends beyond the last device at each end to symbolize the fact
that the bus must be terminated electrically at both ends.
(50 ohm
characteristic impedance) coaxial cable connecting all of the devices. Because
of the analogy with 10Base2, it is customary to draw an Ethernet segment like
this, with a straight line intersected at various points by the connections
(sometimes called "taps") to the various devices. In the drawing, this line (the
wire, or bus) extends beyond the last device at each end to symbolize the fact
that the bus must be terminated electrically at both ends.
On a bus, any device can communicate directly with any other device and all devices see these messages. This is called a "unicast."[1] Similarly, any device can send a single signal intended for all other devices on the wire. This is a "broadcast."
[1] This odd word, "unicast," comes from the word "broadcast." A broadcast is sent to everybody, a "mulitcast" is sent to several recipients, and a "unicast" is sent to just one recipient.
If every device sees every signal sent by all other devices, then it's pretty clear that there's nothing fancy about a broadcast. To get point-to-point unicast communication going, however, there has to be some sort of address that identifies each device uniquely. This is called the MAC address.
There also has to be some sort of mechanism to ensure that all devices don't try to transmit at the same time. In Ethernet the collision detection algorithm (CSMA/CD), which I will talk about more in Chapter 4, prevents such a problem. The other network standard that employs this basic topology is called "token bus," which works by passing a virtual "token" among the devices. Only the device that holds the token is allowed to transmit. The term "token bus" is not used much anymore, so I will not cover it in detail in this book.
There are a few common failure modes in a bus topology. It is possible to have cable break in the middle, thereby isolating the two sides from each other. If one side holds the router that allows devices on the segment to get off, then the devices on the other side are effectively stranded. More serious problems can result if routers are on both sides of the break.
The other problem that often develops in bus architectures is loss of one of the bus termination devices. In the case of 10Base2, this termination was a small electrical resister that cancelled echoes from the open end of the wire. If this terminator was damaged or removed, then every signal sent down the wire was met by a reflected signal. The result was noise and a seriously degraded performance.
Both of these problems are avoided partially by using a central concentrator device such as a hub or a switch. In fact, new Ethernet segments are usually deployed by using such a device.
The second basic segment architecture is a simple ring. The most common example of the simple ring architecture is Token Ring. SONET and FDDI are based on double ring architectures.
In Token Ring, each device has an upstream and a downstream neighbor. If one device wants to send a packet to another device on the same ring, it sends that packet to its downstream neighbor, who forwards it to its downstream neighbor, and so on until it reaches the destination. Chapter 4 describes the Token Ring protocol in more detail.
Token Ring relies on the fact that it is a ring. If a device sends a frame on the network, it expects to see that frame coming around again. If it was received correctly, then this is noted in the frame. Thus, the ring topology allows a simple verification that the information has reached its destination.
The closed ring also facilitates token passing and ensures that the network is used efficiently. Thus, a broken ring is a serious problem, although not as serious as a broken bus, since the Token Ring protocol has a detailed set of procedures for dealing with physical problems such as this.
It might look like each device taking part in the Token Ring acts as a bridge, forwarding each frame from its upstream neighbor to the downstream neighbor. But this is not really accurate, since the network interface cards in each device passes the Layer 2 frames along, regardless of their content. Even if the frame is intended for the local device, it still must pass along a copy, although it will change a bit in the header to indicate that it has been received.
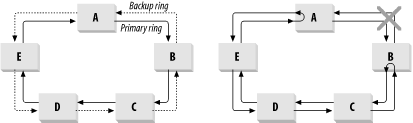
FDDI uses another ring architecture that gets around this broken ring problem in a rather clever way. In FDDI, two rings run at all times. The tokens on these two rings travel in opposite directions, so the upstream neighbor on one ring is the downstream neighbor on the other. However, in normal operation, only one of these rings is used. The second ring acts as a backup in case of a failure, such as a broken ring.
Figure 3-5 shows what happens when the rings break. If the connection between devices A and B breaks, then the devices know about it immediately because there is two-way communication between them, and they have now lost contact with one another. They respond by closing the ring. Now when device A receives a token from device E on the clockwise-rotating ring, instead of sending it on to B, it turns around and sends it back to E on the counterclockwise-rotating ring. The token doesn't get lost because the rings have healed around the fault. The same thing happens if one of the devices taking part in the FDDI ring disappears.
In practice, most Ethernet and Token Ring LANs are implemented in a star topology. This implementation means that a central device connects to all of devices. All devices communicate with one another by passing packets first to this central device.
In one option for a star topology, the central device aggregates the traffic from every device and broadcasts it back out to all other devices, letting them decide for themselves packet by packet what they should pay attention to. This is called a hub. Alternatively, the central device could act as a switch and selectively send traffic only where it is intended to go.
The star topology is often called hub and spoke, as an analogy to a bicycle wheel. This term can be misleading because sometimes the hub is a hub and sometimes it's a switch of some kind. So I prefer the term star.
Most modern LANs are built as stars, regardless of their underlying technology. There are many reasons for this. It's certainly easier to upgrade a network by upgrading only the device in the closet, without having to change the expensive cabling to every desk. It's also much easier to make fast switching equipment in a small self-contained box than it would be to distribute the networking technology throughout the work area.
Even when Token Ring and Ethernet are implemented using a star topology, they still obey their own rules internally. For example, a Token Ring MAU transmits frames to each port in succession, waiting each time until it receives the frame back from the port before transmitting it to the next port. In Ethernet, however, the hub simultaneously transmits the frame to all ports.
The prevalence of star topology networks has made it possible to build general-purpose structured cable plants. The cable plant is the set of cables and patch panels that connect all user workspaces to the aggregation point at the center of the star.
With a structured cable plant of Category 5 cabling and IBDN patch panels, it's relatively easy, for example, to switch from Token Ring to Ethernet or from Ethernet to Fast Ethernet. Executing a change like this means installing the new equipment in the wiring closet, connecting it to the rest of the network in parallel with the existing infrastructure, and then changing the workstations one by one. As each workstation is changed, the corresponding cable in the wiring closet is moved to the new switching equipment.
Chapter 4 discusses structured cable plants in more detail.
When it comes to fault tolerance, however, star topologies also have their problems. The central aggregation device is a single point of failure. There are many strategies for reducing this risk, however. The selection and implementation of these strategies are central to a good network design.
A mesh topology is, in some ways, the most obvious way to interconnect devices. A meshed network can be either fully meshed or partially meshed. In a fully meshed network, every device is connected directly to every other device with no intervening devices. A partial mesh, on the other hand, has each device directly connected to several, but not necessarily all of the other devices.
Clearly, defining a partial mesh precisely is a bit more difficult. Essentially, any network could be described as a partial mesh with this definition. Usually, a mesh describes a network of multiple point-to-point connections that can each send and receive in either direction. This definition excludes descriptions of both the ring and bus topologies because the ring circulates data in only one direction and the bus is not point-to-point.
Since a mesh has every device connected to every other device with nothing in between, the latency on this sort of network is extremely low. So why aren't mesh networks used more? The short answer is that mesh networks are not very efficient.
Consider a fully meshed network with N devices. Each device has to have (N-1) connections to get to every other device. Counting all connections, the first device has (N-1) links. The second device also has (N-1) links, but the one back to the first device has already been counted, so that leaves (N-2). Similarly there are (N-3) new links for the third device, all the way down to (N-N = 0) for the last device (because all of its links were already counted). The easiest way to see how to add these devices up is to write it in a matrix, as shown in Table 3-1.
|
1 |
2 |
3 |
4 |
... |
N |
|
|---|---|---|---|---|---|---|
|
1 |
x |
1 |
1 |
1 |
1 |
|
|
2 |
x |
1 |
1 |
1 |
||
|
3 |
x |
1 |
1 |
|||
|
4 |
x |
1 |
||||
|
... |
... |
... |
||||
|
N |
x |
An "x" runs all the way down the diagonal of the matrix
because no device talks to itself. The total number of boxes in the matrix is
just N2. The number of entries along
the diagonal is N, so there are (N2-N)
links. But only the upper half of the matrix is important because each link is
only counted once (the link from a
![]() b is
included, but not b
b is
included, but not b
![]() a,
because that would be double counting). Since there is exactly the same number
above the diagonal as below, the total number of links is just
N(N-1)/2.
a,
because that would be double counting). Since there is exactly the same number
above the diagonal as below, the total number of links is just
N(N-1)/2.
Making a fully meshed network with 5 devices requires 5(5-1)/2 = 10 links. That doesn't sound so bad, but what happens if this number is increased to 10 devices? 10(9)/2 = 45 links. By the time you get to a small office LAN with 100 devices, you need 100(99)/2 = 4950 links.
Furthermore, if each of these links is a physical connection, then each of the 100 devices in that small office LAN needs 99 interfaces. It is possible to make all those links virtual—for example, with an ATM network. But doing so just moves the problem and makes it a resource issue on the ATM switching infrastructure, which has to keep track of every virtual circuit.
The other reason why meshed networks are not particularly efficient is that not every device needs to talk to every other device all of the time. So, in fact, most of those links will be idle most of the time.
In conclusion, a meshed topology is not very practical for anything but very small networks. In the standard jargon, it doesn't scale well.
This discussion has just looked at certain basic network topologies. These concepts apply to small parts of networks, to workgroups, or to other local groupings. None of the basic topologies mentioned is particularly useful for larger numbers of users, however. A mesh topology doesn't scale well because the number of links and ports required grow too quickly with the number of devices. But ring and bus architectures also don't scale particularly well.
Everybody seems to have a different rule about how many devices can safely connect to the same Ethernet segment. The number really depends on the traffic requirements of each station. An Ethernet segment can obviously support a large number of devices if they all use the network lightly. But in a Token Ring network, even devices that never talk must take the token and pass it along. At some point, the time required to pass the token all the way around the ring becomes so high that it starts to cause timeouts. The number of ring members required to achieve this state is extremely high, though. Other types of problems generally appear first.
Both Ethernet and Token Ring networks have theoretical upper limits to how much information can pass through them per second. Ethernet has a nominal upper limit of 10Mbps (100Mbps for Fast Ethernet and 1000Mbps for Gigabit Ethernet), while 4, 16, and 100Mbps Token Ring specifications are available. Clearly, one can't exceed these nominal limitations. It actually turns out that the practical limits are much lower, though, particularly for Ethernet.
The collision rate governs throughput on an Ethernet network. Thus, the various rules that people impose to set the maximum number of devices in a particular collision domain (i.e., a single Ethernet segment) are really attempts to limit collision rates. There is no generally reliable rule to decide how many devices can go on one segment.
This fact is easy to deduce from a little calculation. Suppose you have an Ethernet segment with N devices. Each device has a certain probability, P, of wanting to use the network at any given moment. The probability of having k simultaneous events is:
![]()
Thus, for two devices, both wanting to talk at the same time, k = 2.
![]()
![]()
Taking this equation a step further to work out real numbers is more difficult because it would require a detailed discussion of collision back-off algorithms. One would also have to be very careful about how P was calculated, as a collision is only counted when two devices actually send packets simultaneously. Usually, one sends first and the second device simply buffers its packet and waits until the wire is free. But the most important result is already here. The probability that two devices want to talk at the same time is proportioned to N2, where N is the number of devices on the segment.
Interestingly, the probability goes like P2. P is the probability that a particular device will want to use the network (in a suitable unit of time, such as the MTU divided by the nominal peak bandwidth). This probability is clearly going to be proportional to the average utilization of each device. The probability 2PN is essentially the probability that a device will have to wait to transmit because another device is already transmitting. Since the probability of having to wait is proportional to P2, a small increase in the average utilization per device can result in a relatively large increase in the collision rate. But the real scaling problem is because of the factor of N2, which rises very quickly with the number of devices.
This is why there are so many different rules for how many devices to put on an Ethernet segment. The number depends on the average utilization per device. A small increase in this utilization can result in a large increase in the collision rate, so it is not safe to trust these general rules.
Remember that collision rates cause the effective throughput on an Ethernet segment to be significantly smaller than the nominal peak. You will never get a 10Mbps throughput on a shared 10BaseT hub. You will never get 100Mbps on a Fast Ethernet hub, either. In fact, if there are more than 2 or 3 devices you probably can't get close to that nominal peak rate. Typically, the best you will be able to get on a shared Ethernet segment is somewhere between 30 to 50%. Sometimes you can do better, but only if the number of talking devices is very small. This is true for both Ethernet and Fast Ethernet hubs, but it is not true for switches.
Each port on an Ethernet switch is a separate collision domain. If every device is connected to its own switch port, then they are all on their own collision domains. Now they can all talk at the same time, and the switch will make sure that everything gets through.
Token Ring, on the other hand, has a much simpler way of avoiding contention. If two devices want to talk at the same time, they have to wait their respective turns. If another device is inserted into the ring, then everybody has to wait slightly longer. The average amount of time that each device has to wait is roughly proportional to the number of devices on the ring, N. This result is much better than N2.
Also note that in Ethernet, the collision rate goes up proportionally to the square of the average utilization of each device. In Token Ring, the average wait time between each device's transmission bursts is the corresponding rate limiting factor. This factor scales roughly to the average per device utilization, not its square.[2]
[2] Some people say that Token Ring is deterministic because of this property, meaning that you can readily calculate how the traffic from a group of devices will aggregate on the entire ring. But you can do similar calculations for Ethernet if you understand how to combine probabilities and how the collision mechanisms work. It's just a harder calculation. Since everything is measured statistically anyway, having a deterministic model for your network is actually not much of an advantage.
As a result, a Token Ring "segment" can hold more devices than an Ethernet segment before contention becomes a serious problem. It's also much safer to rely on general rules for how many devices to put on a ring. Even with Token Ring, there is an upper limit of how many devices can take part in a particular segment. Efficiency usually demands that you break up your rings through a bridge or a switch, exactly the same as for Ethernet.
You have seen that all of the basic LAN building blocks have different types of scaling problems. A 16Mbps Token Ring can hold more devices than a 10Mbps Ethernet segment, but in both cases there is a practical upper limit to how many devices you can put on the network before you start having performance problems. I have already alluded to one practical solution that allows us to continue growing our network beyond these relatively small limitations: switches.
You can connect a large number of Ethernet segments or Token Rings with a central switch. This switch will create a single point of failure, as I discussed in the previous chapter, but it will also move the problem up only a level. Now, instead of having a limit of N devices per segment, there is a limit of N devices times the number of ports on the switch. Expanding beyond this new upper limit is going to create a new problem.
Solving this new problem is what this whole book is about.