Figure 3-6. Spanning Tree is used to eliminate loops and activate backup links
Before moving on to larger-scale topologies, it is important to review some of the systems for automated fault recovery that are used in large networks. Just inserting backup switches and routers connected with backup links is not enough. The network has to be able to detect problems quickly with its primary paths and activate the backup devices and links.
There are two main methods for doing this, and most large-scale networks use both. You can detect and repair the fault at either Layer 2 or at Layer 3. The Layer 2 mechanism employs a special IEEE standard called Spanning Tree. As an IEEE standard, Spanning Tree is applicable across a wide range of Layer 2 networks, including the commonly used Ethernet and Token Ring protocols.
Conversely, there are many different ways of detecting and working around faults at Layer 3. Selecting among these different possibilities depends on what the Layer 3 protocols on the network are and on the scope of the fault tolerance. There are purely local mechanisms as well as global ones.
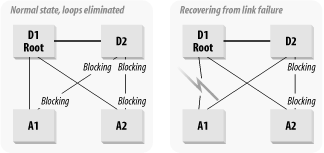
Spanning Tree, also called STP or IEEE 802.1d, is a Layer 2 protocol that is designed to accomplish two important tasks. It eliminates loops and it activates redundant links for automated fault recovery. Figure 3-6 shows a simple bridged network that employs Spanning Tree for both of these purposes.
Figure 3-6 has four switches. D1 and D2 are the central Distribution switches, while A1 and A2 are downstream Access switches that connect to end-device segments. The Spanning Tree priorities have been adjusted to give D1 the lowest value, making it the "Root Bridge."
Now, suppose D1 has a packet intended for a device on A1. It has several ways to get there. It can go directly, or it can go over to D2, which also has a link to A1. Or, it can go to A2, back to D2, and over to A1. The worst thing it could do is to go around in circles, which it can also do in this diagram. In fact, every device in the picture except the one containing the end device wants to helpfully forward the packet along to any other device that might be able to deliver it. This forwarding results in a big mess of loops. Spanning Tree removes this problem.
Each port taking part in Spanning Tree can be in one of five different states: blocking, forwarding, listening, learning, or disabled. Blocking means that Spanning Tree is preventing this port from forwarding packets. Each switch looks at its neighbors and inquires politely whether they are the Root Bridge or whether they can help it get to the Root Bridge. Only one Root Bridge is allowed in a broadcast domain, and that device is the logical center of the network. This is why the priorities have been set manually to force the network to elect D1 as the Root Bridge. D2 is configured to be the second choice in case D1 fails. You never want a switch that serves the end-device Access level of the network to be Root Bridge.
In this way, the network is always able to designate a Root Bridge. This device serves as the main Distribution point for all packets that a switch can't otherwise deliver itself. Every switch keeps track of the next hop that will take it to the Root Bridge. In effect, the network, with all of its redundant cross-connections, becomes a simple tree topology, which eliminates the loops.
Now suppose the link from A1 to D1 suddenly fails, as shown in the diagram. A1 knows it has lost its Root Bridge connection because it stops exchanging hello packets on that port. These packets exist purely for this reason—to keep checking that everything is working properly. When the link breaks for any reason, A1 remembers that it had another link to the Root Bridge via D2, and so it tentatively activates that port. It isn't certain yet that this way is correct, so it doesn't start forwarding data; instead, it goes into a "listening" state. This state allows it to start exchanging Spanning Tree information over this other port—to see if this is the right way.
Once A1 and D2 have established that they can use this link as a valid backup, both ports go into a learning state; they still do not forward data packets; they first must update their MAC address tables. Until the tables are updated, switch D2 doesn't know what devices are on A1. Then, once they have synchronized all of this information, both switches set this new port to a forwarding state, and the recovery process is complete.
In this picture, all switches are connected directly to the Root Bridge, D1. All links that do not lead to Rome are set to the blocking state, so A1 and A2 both block their links to D2. At the same time, D2 sets all the links it has that do not lead to D1 to blocking as well. The other links—the ones that do lead to the Root Bridge—are all set to their forwarding state.
The thick line connecting D1 and D2 is a higher bandwidth link. Suppose the thin lines are 100Mbps Ethernet links, while the thick line is a 1000Mbps Gigabit Ethernet link. Clearly the thick line is a better link to the Root Bridge than one of the slower links. So, the engineer sets the priority on this port so that, if there is a choice between what link to use, the switch always chooses the faster one.
Having a link between D1 and D2 is important. Imagine what would happen if it were not present and the link between A1 and D1 failed. A1 would discover the new path to the Root Bridge through D2, exactly as before. However, D2 doesn't have its own link directly to D1, so it must instead pass traffic through A2 to get to the Root Bridge. This means that traffic from A1 to the Root Bridge must follow the circuitous path—A1 to D2 to A2 to D1. In this simple example, the traffic passes through every switch in the network! This situation is clearly inefficient.
But wait—it gets worse. Now suppose a third switch, A3, is connected to both D1 and D2, and the link from A1 to D1 fails. A1 will again try to use D2 as its backup, but D2 now has two possible paths to the Root Bridge—one through A2 and the other through A3. It picks one of these links at random as the best path—say A2—and it blocks the other. Now, because of an unrelated failure elsewhere in the network, A2 has extra traffic load and A3 has no redundancy.
In the hierarchical network designs that this book recommends, the configuration with two redundant Core (or Distribution) switches connected to each of several Access switches will be common. Therefore, it is important to include a separate trunk connecting the two central switches each time this configuration is used.
It can take several seconds for conventional Spanning Tree to activate a backup link. This may not sound like a long time, but it can be a serious problem for some applications. Fortunately, trunk failures don't happen very often, but techniques for improving recovery time are available.
Spanning Tree has three adjustable timers that can be modified to make convergence faster. These times are called hello, forward delay, and maximum age. All bridges or switches taking part in Spanning Tree send out hello packets to their neighbors periodically, according to the hello timer. All neighboring devices must agree on this interval so that they all know when to expect the next hello packet. If the timers do not agree, it is possible to have an extremely unstable network, as the switch with the smaller timer value thinks that its trunks are continuously failing and recovering.
The forward delay timer determines how long the switch will wait in the listening and learning states before it sets a port to the forwarding state. The maximum age timer determines how long the switch should remember old information.
By reducing the hello and forward delay timers, you can improve your convergence time in a failure, but there are limits to how far you can push these numbers. The forward delay timer exists to prevent temporary loops from forming while a network tries to recover from a serious problem. The switch has to be certain that the new link is the right one before it starts to use it.
For example, suppose your Root Bridge fails. In this case, all switches must elect a new Root Bridge. In the example, the priorities are adjusted so that, if D1 fails, D2 becomes the Root Bridge. D2 has to realize that D1 has failed and has to alert every other device that it is now the Root Bridge. The forward delay timers on all of these switches have to be long enough to allow this process to complete.
Having a short hello interval is the easiest way to speed up the convergence of a Spanning Tree network. But even this process has to be done carefully. Remember that a packet is sent in both directions over all of your production trunks once every time interval. If the interval becomes too short, then link congestion and CPU loading problems can result. If hello packets are dropped for these reasons, Spanning Tree may assume that links have failed and try to find alternate paths.
The best set of Spanning Tree timers vary from network to network. By default, the values of the hello and forward delay timers will be approximately a few seconds each. The best way to determine the appropriate values is to start with the defaults and then try reducing them systematically. Then try deliberately failing links to verify that these settings result in a stable network. In most cases, the default parameters are very close to optimal. Since timer changes must be made on all devices, it is generally best to use the defaults unless there is a compelling requirement to improve convergence efficiency.
Some switch vendors have implemented additional Spanning Tree features that facilitate faster convergence and greater stability. Generally, these features work by allowing ports that are nominally in blocking states to behave as if they are in a perpetual learning state. This way, in the event of a simple failure, they can find the new path to the Root Bridge more quickly. Of course, in the case of a Root Bridge failure, the network still has to calculate a new topology, and this calculation is difficult to speed up.
There are two main methods of implementing fault tolerance at Layer 3. You can either take advantage of the dynamic routing protocol to reroute traffic through the backup link or you can use an address-based redundancy scheme, such as HSRP (Hot Standby Router Protocol) or VRRP (Virtual Router Redundancy Protocol). The choice depends on the location.
I have already said that running a dynamic routing protocol on any end devices is a bad idea. If the problem is to allow end devices to stop using a failed default gateway on their LAN segment and use its backup instead, the dynamic routing protocol can't help. Instead, you need to use HSRP or VRRP. There is considerable similarity between these two protocols, which is why I mention them together. HSRP is a Cisco proprietary system defined in RFC 2281, and VRRP is an open standard defined in RFC 2338. In general, it is not a big problem to use the proprietary standard in this case because, if two routers are operating as a redundant pair, the chances are good that they are as nearly identical as possible; they will almost certainly be the same model type and probably have the same software and card options. This is one of the relatively rare cases in which the open standard doesn't matter very much.
Both of these protocols work by allowing end devices to send packets to a default gateway IP address that exists on both routers. However, end devices actually send their packets to the Layer 2 address associated with that default gateway IP address in their ARP cache. They don't use the default gateway address directly. When the backup router takes over for the primary router's default gateway functions, it must adopt both the IP address and the Layer 2 MAC address. Both VRRP and HSRP have quick and efficient methods of making this change. When one router fails, the other takes over and the end stations on that segment are not even aware that a problem has occurred.
On segments that do not have any end stations, particularly router-to-router segments, there is no need for HSRP or VRRP. In these cases, all devices can take part in the dynamic routing protocol (such as OSPF). In these places, using HSRP or VRRP is not a good idea because it has the potential to confuse the routing tables of the other routers on the segment. These routing protocols are very good at maintaining lists of alternative paths and picking the one that looks the best. If two paths have the same "cost," then most routers simply use both, alternating packets between them. If one router fails, the other routers quickly drop it out of their routing tables and start using the remaining path exclusively.
![]()