Figure 3-8. A simple network backbone technology
Until now, this chapter looked at small-scale LAN structures and described some of the concepts, such as VLANs and reliability mechanisms, that allow designers to glue these small-scale concepts together into a large network. Now I'd like to move on to talk about how these basic building blocks are used to put together large-scale networks. To do this, I need to put many of these ideas into their historical context. New technology has allowed larger and more stable networks. It is useful to talk about the simpler creatures that evolved into more sophisticated modern networks. By reviewing how we got where we are, I hope to prevent you from making old mistakes or reinventing old wheels.
There are many ways to create larger networks from basic LAN segments. The simplest is to just interconnect several Ethernet segments or Token Rings via a single switch. This type of large-scale LAN architecture is called a Collapsed Backbone. Although it may sound like the painful result of a highway accident, the Collapsed Backbone topology gets its name from the concept of a network backbone that interconnects various segments.
In general, the backbone of the network can be either collapsed or distributed. I use the general term backbone to refer to a high-capacity part of the network that collects traffic from many smaller segments. It can gather traffic from several remote LANs onto a network backbone that connects to a central computer room.
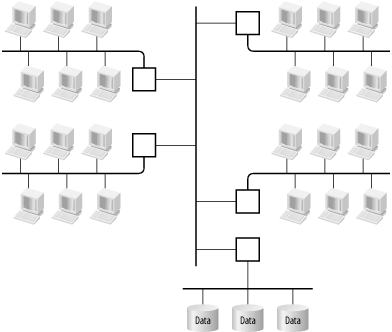
The network backbone concept also works well in more peer-to-peer networks where there is no central computer room, but there is communication among the various user LANs. Figure 3-8 shows a simple example of a traditional network backbone design. In the early days of LAN design there was no such thing as the collapsed backbone—it was itself just some sort of LAN.
The various user LANs connect to some sort of shared medium that physically runs between the separate areas. This medium could be some flavor of Ethernet, in which case the little boxes making these connections could be bridges, switches, or repeaters of some kind. Or the backbone could be a completely distinct network technology such as ATM or FDDI, in which case the little boxes must be capable of interconnecting and converting between these different network types.
Figure 3-9 shows the same diagram with a collapsed backbone. Here, some sort of central router or switch has long-haul connections to the various user areas. Typically, these connections would be fiber connections. Note that there is still a backbone, exactly the same as in the previous diagram, but here the backbone is contained inside the central concentrator device.
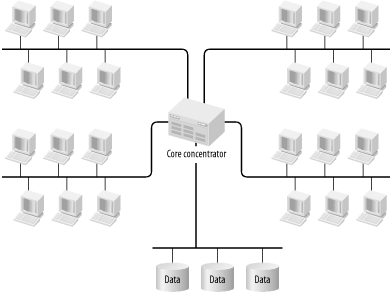
The two diagrams look essentially similar, but there is a huge potential performance advantage to the collapsed backbone design. The advantage exists because the central concentrator device is able to switch packets between its ports directly through its own high-speed backplane. In most cases, this means that the aggregate throughput of the network is over an order of magnitude higher.
The essential problem is that all network segments must share the bandwidth of the backbone for all traffic crossing it. But how much traffic is that? If the separate segments are relatively autonomous, with their own file and application servers, there may be very little reason to send a packet through the backbone. But, in most large LAN environments, at least one central computer room contains the most heavily used servers. If everybody shares these servers, then they also share the backbone. Where will the bottleneck occur?
In the diagram shown, bottleneck is actually a bit of a moot point because there is only one central server segment. If all traffic crossing the backbone goes either to or from that one segment, then it's fairly clear that all you need to do is control backbone contention a little bit better than on the server segment and the bottleneck will happen in the computer room. But this is not the usual case. Drawing the central server segment with all of those servers directly connected to a Fast Ethernet switch at full duplex would be more realistic. With just three such servers (as in the drawing), the peak theoretical loading on the backbone will be 600Mbps (100Mbps for Fast Ethernet times two for full duplex times three servers).
Clearly that number is a maximum theoretical burst. In the following section I will discuss how to appropriately size such trunk connections. The important point here is that it is very easy to get into situations in which backbone contention is a serious issue.
This is where the collapsed backbone concept shows its strength. If that central concentrator is any commonly available Fast Ethernet switch from any vendor, it will have well over 1000Mbps of aggregate throughput. The backplane of the switch has become the backbone of the network, which provides an extremely cost effective way of achieving high throughput on a network backbone. The other wonderful advantage to this design is that it will generally have significantly lower latency from end to end because the network can take advantage of the high-speed port-to-port packet switching functions of the central switch.
In Figure 3-8, each user segment connects to the backbone via some sort of Access device. The device may be an Ethernet repeater, a bridge, or perhaps even a router. The important thing is that any packet passing from one segment to another must pass through one of these devices to get onto the backbone and through another to get off. With the collapsed backbone design, there is only one hop. The extra latency may or may not be an issue, depending on the other network tolerances, but it is worth noting that each extra hop takes its toll.
The biggest problem with this collapsed backbone design should already be clear. The central collapse point is also a single point of failure for the entire network. Figure 3-10 shows the easiest way around this problem, but forces me to be more specific about what protocols and technology the example network uses.
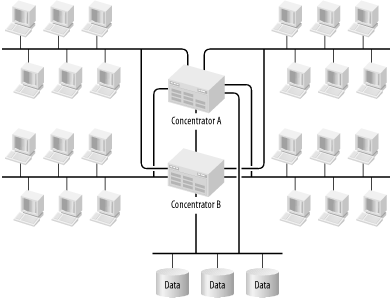
The most common way to collapse a LAN backbone is through a layer 2 Ethernet switch. So let's suppose that each user segment is either Ethernet or Fast Ethernet (or perhaps a combination of the two). The central device is a multiport Fast Ethernet switch with an aggregate backplane speed of, say, 1Gbps (this number is much lower than what is currently available in backbone switches from any of the major vendors, but it's high enough for the example). Each user LAN segment connects to these central switches using two fiber optic Fast Ethernet connections, one to each switch.
Then the two switches can be configured to use the Spanning Tree protocol. This configuration allows one switch to act as primary and the other as backup. On a port-by-port basis, it is able to ensure that each user LAN segment is connected to only one of the two switches at a time. Note that a switch-to-switch connection is indicated in the diagram as well. This connection is provided in case LAN segment 1 is active on Switch A and segment 2 is active on Switch B. If this happens, there needs to be a way to cross over from one switch to the other.
There are several important redundancy considerations. First, it may seem more complicated to use port-by-port redundancy rather than redundancy from one whole switch to the other. After all, it means that there will probably be complicated switch-to-switch communication, and seems to require the switch-to-switch link that wasn't previously required. But this is actually an important advantage. It means that the switch can suffer a failure affecting any one port without having to flip the entire backbone of the network from one switch to the other. There are a lot of ways to suffer a single port failure. One could lose one of the fiber transceivers, or have a cut in one of our fiber bundles, or even have a hardware failure in one port or one card of a switch. So minimizing the impact to the rest of the network when this happens will result in a more stable network.
This example specified Ethernet and Spanning Tree, but there are other possibilities. If all LAN segments used Token Ring, for example, you could use two central Token Ring switches and the Token Ring flavor of Spanning Tree. Exactly the same comments would apply.
Alternatively, for an IP network you could have done exactly the same thing at Layer 3 by using two central routers. In this case, you could use the Cisco proprietary HSRP protocol or the RFC 2338 standard VRRP protocol. These protocols allow two routers to own this address, but only one is active at a time. The result provides exactly the same port-by-port redundancy and collapsed backbone properties using routers instead of switches.
The alternative to the Collapsed Backbone architecture is a Distributed Backbone. Later in this chapter, I describe the concept of hierarchical network design. At that point, the implementation of distributed backbone structures will become clearer. For now, I need to discuss some general principles.
A Distributed Backbone just indicates more than one collapse point. It literally distributes the backbone functions across a number of devices. In a network of any size, it would be extremely unusual to have a true single collapsed backbone. A large network with a single collapsed backbone would have a terrible single point of failure. It would also probably suffer from serious congestion problems if all inter-segment traffic had to cross through one point. Even if that collapse point had extremely high capacity, it would probably be difficult to get a high enough port density for it to be useful in a large network.
All practical large-scale networks use some sort of distributed backbone. Moving the backbone functions outside of a single chassis introduces two main problems: trunk capacity and fault tolerance.
Suppose you want to distribute your backbone-switching functions among two or more large switches. The central question is how much capacity should you provide to the trunk? By a trunk I mean any high-speed connection that carries traffic for many end-device segments. In this book, I often use the term trunk to refer specifically to a connection that carries several VLANs. I want to consider the more general case here.
A naïve approach would be simply to add up the total burst capacity of all segments feeding this trunk. If you had, for example, 5 Fast Ethernet (100Mbps half-duplex) LAN segments flowing into one trunk, then you would need 500Mbps of trunk capacity. But this scenerio presents a serious problem. How do you practically and inexpensively get this much bandwidth? Do you really have to go to a Gigabit Ethernet or an ATM just because you're trying to run a few trunks? Even load sharing isn't much of an option because you would need as many Fast Ethernet trunks as you have segments, so why use trunks at all in that case?
Needless to say, this approach is not very useful. You have two options for more efficient ways to think about trunk sizing. You could either develop some generally useful rules of thumb, or you could give up completely and just keep throwing bandwidth at it until the congestion goes away. You could actually take a rigorous approach to this second idea by using simulation tools. In the end, you will always have to monitor your trunks for congestion and increase their capacity when you start to get into trouble. A few good rules would give a useful starting point. Trunks should have more capacity than the average utilization. The only question is how much of a peak can the network deal with. Congestion on these trunk links is not a disaster in itself. Later in this book I talk about prioritization schemes to ensure that the important data gets through no matter how heavy the flow is. But there needs to be enough capacity for the normal peak periods, and this capacity needs to be balanced against cost because the higher speed technologies are significantly more expensive to implement.
The key to this discussion is the fact that all end segments are not statistically expected to peak at once. Most of the time, there will be an average load associated with all of them. Every once in a while, one or (at most) two experience a burst to full capacity. The basic rule for sizing trunks is to make sure that they have enough capacity for two end (shared) segments to peak at the same time plus 25% of capacity for all the remaining end segments. If the trunk has full-duplex transmission, consider the directions separately.
For an example, look at Figure 3-8. A central trunk connects four user segments with a server segment. First assume that this is a half-duplex trunk and that all end segments are 10Mbps Ethernet segments. Then the rule says to allow for two times 10Mbps plus 25% of three times 10Mbps, which works out to be 27.5Mbps. It would be completely safe to use a Fast Ethernet trunk in this case.
If the trunk technology is capable of full-duplex transmission, then you need to consider the two directions separately. Suppose that all traffic is between the users and the servers, with little or no user segment to user segment communication. This situation will help to establish the directions. For the user-to-server direction, there are four 10Mbps Ethernet segments. If two of these segments burst to capacity at the same time, the other two reach 25% of their capacity, and the trunk load will be 25Mbps in this direction. In the other direction, there is only one segment, so if it bursts to capacity, then it will have only 10Mbps in the return direction. As a side benefit, this activity shows that upgrading the server segment to full-duplex Fast Ethernet doesn't force an upgrade on the full-duplex Fast Ethernet backbone.
But this rule doesn't work very well for LANs that have every PC connected to a full-duplex Fast Ethernet port of its own. The rule allows two PCs to burst simultaneously and add 25Mbps to the trunk for every other PC on the network. 50 PCs connected in this way would need a full-duplex trunk with 1.4Gbps in either direction. This doesn't make much sense.
Individual workstations do not behave like nice statistical collections of workstations. The problem is not in assuming that two will burst simultaneously, but rather in the 25% of capacity for the rest. When workstations are connected to a switch like this, the typical utilization per port looks like silence interspersed with short hard bursts. A completely different sort of rule is necessary to express this sort of behavior.
A simple way to say it is that some smal percentage of the workstations will operate at capacity, while the rest do nothing. The actual percentage value unfortunately changes radically depending on the organization and even on the department. A graphic design group that spends its time sending large graphic image files might have a relatively high number. A group that only uses the network for printing the occasional one-page document will have a much smaller number. A general rule requires a reasonable mid-point number that is useful for Distribution trunks in a large network. A fairly safe number for this purpose is 5%. This percentage may be a little on the high side for many networks, so you can consider reducing it to 2.5%. Bear in mind that the smaller this number is, the less capacity for expansion allowed in your network.
Consider another example to demonstrate this rule. Suppose the end-segments in the network shown in Figure 3-8 have switched full-duplex Fast Ethernet to every desk. Suppose that 25 workstations are in each of the four groups. Then, for the user to server traffic, the trunk should allow for 5% of these 4 x 25 = 100 workstations to burst to their full 100Mbps capacity simultaneously. Thus, the trunk will operate at 500Mbps in at least this direction. Gigabit Ethernet or ATM can achieve these bandwidths, as can various vendor-proprietary Ethernet multiplexing technologies.
But wait, there's a twist in this example. So far, the discussion has assumed that all traffic is between the users and the servers. So what good does it do if the network can burst to 500Mbps on the trunk for traffic destined for the server segment, if the server segment can't deal with this much traffic? If 5 or more servers are all connected similarly to full-duplex Fast Ethernet switch ports, then this is possible. But the burst would have to be conveniently balanced among these servers. In this case, because traffic patterns are known very precisely, it is possible to reduce the trunk capacity to save money. The point is that this rule is just a starting point. You should always re-evaluate according to your own network conditions. Also note that the rule doesn't apply at all on the server side because you should always expect the servers to work the network very hard.
A trunk, like any other part of the network, can fail. If it happens to carry all traffic from some part of the network at the time, though, it could be disastrous. Since trunk failures are potentially serious, it is always wise to include some sort of redundancy in every trunk. In fact, in most organizations I have seen personally, trunk failure is more common than hardware failure on key network equipment. This information is anecdotal, and I have no statistics on it, but it makes sense that delicate strands of optical fiber stretching long distances might be more vulnerable than a tank-like Ethernet switch chassis. If that switch is located in a locked room while the fiber has to run through a conduit shared with other building tenants, there's an even stronger reason to worry about the fiber. In some cases, it is physically damaged while technicians are doing other work. But even if fiber is never touched and the conduit remains sealed forever, eventually it degrades due to a host of environmental hazards, such as background radiation.
All of this information is intended to scare the reader into worrying about trunk failures. In most network designs, the trunks are the first things I would want to provide redundancy for. There are many ways to do so. The actual redundancy mechanism depends on trunk type. If the trunk is itself a multiplexed collection of links (like Cisco's EtherChannel or Nortel's MultiLink Trunking), then redundancy is inherent in the design. In this case, it would be wise to employ an N+1 redundancy system. This means that the trunk capacity should be sized as discussed in the previous section, and then increased by one extra link. This way, there is still sufficient capacity if any one link fails.
However, if a single fiber pair carries the trunk, then the only useful way to add redundancy is by running a second full-capacity trunk link. Since one of the main concerns is environmental or physical damage to the fiber, putting this second link through a different conduit makes sense.
The only remaining question is whether to make the backup trunk link a hot standby or to have it actively share the load with the primary link. And the answer, unfortunately, depends on what you can get with the technology you're using. In general, if you can do it, load sharing is better for two reasons:
In case you inadvertently underestimate your trunk capacity requirements, or in case those requirements grow over time, load sharing gives you extra bandwidth all the time.
If the primary can fail, so can the backup. The difference is that you notice when the primary fails, and you don't necessarily know when the backup fails. If traffic goes through it all the time, then you'll usually know pretty quickly that you've had a failure of your backup link.
In the discussion of backbone designs, I mentioned that the same general design topologies are applicable to both Layer 2 and Layer 3 implementations. Thus, at many points the designer can choose to either bridge or route. There are philosophical reasons for choosing one or the other in many cases, but there are also several practical reasons for favoring either switching (bridging) or routing implementations.
The old rule for designing large-scale LANs was "bridge on campus, route off campus." There were good reasons for this rule, but many of these reasons are less relevant today than they once were. Figure 3-11 shows an example of a LAN designed using this rule. It consists of a number of separate Ethernet-based work groups, all interconnected via an FDDI ring. I don't call this an "old-style" design to disparage it. In its day, this was cutting-edge technology. Although I modify the basic rule later in this chapter, the general design concept points out some important principles of network design that are still applicable.
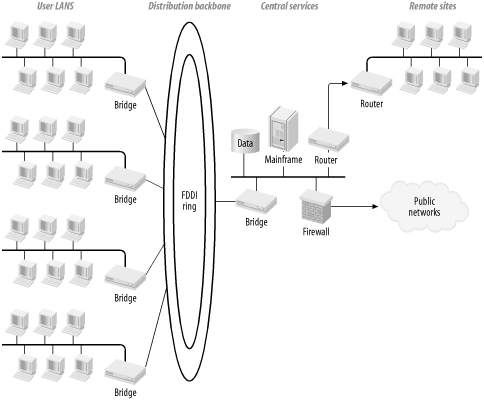
Suppose that the network protocol in this diagram was TCP/IP. The entire campus, then, would have been addressed from the same large address range, such as a Class B or Class A. In fact, because all of these segments were bridged together, there would have been no technical requirement to break down the user segments into their own specific address ranges. The whole campus looked like one gigantic common flat network at the IP layer.
In practice, however, most network administrators would have broken down their larger address range into subranges, and allocated these subranges to different user LAN segments. This allocation would be done purely for administrative reasons and to make troubleshooting easier.
In this old-style design, if someone on one of the user LAN segments wants to access the central database, they first look up the IP address (probably using DNS). They then send out an ARP (Address Resolution Protocol) packet to find the Ethernet MAC address associated with this IP address. This ARP packet goes out through the bridge and onto the FDDI backbone ring. Every other bridge on the ring forwards this packet onto its local segment. Eventually, the packet reaches the database server, which responds appropriately.
This approach immediately points out one of the important limitations of this design principle. Broadcast packets (like the ARP packet in the example) are sent to every distant corner of the network. This may be fine if there is very little broadcast traffic, but some broadcasts, like ARP, are a Core part of the network protocol. Every station sends broadcasts. There are necessarily limits to how big one can make a bridged network before routine broadcast traffic starts to choke off production application traffic.
This model does a nice job of segregating the regular application traffic, though. Suppose a user on the left side of the picture talks to a server on the right with regular unicast packets. Each packet on both sides of the conversation contains the Ethernet MAC address of the destination device. All bridges are smart enough to keep track of the MAC addresses on each port. So, a packet heading for the database server enters the FDDI ring because the user's local bridge knows to find that MAC via the ring. Then every other bridge on the ring simply leaves the packet alone until it reaches the one that has that MAC address on its LAN segment. Thus, normal application traffic takes an efficient direct route.
Now consider traffic destined for the remote site shown on the far right-hand side of the picture. Two rules of networks are almost immutable. The first is that bandwidth costs money; the second is that distance costs money. From these two rules, it is safe to conclude that high bandwidth over long distances costs a lot of money. Whatever technology is used to connect to the remote site, it almost certainly has much lower bandwidth than any LAN element.
This point is important because the rule was "bridge on campus, route off campus." In other words, it says that you should bridge where bandwidth is cheap and route where it's expensive. Bridging allows all broadcast chatter to go everywhere throughout the bridged area. You simply want to avoid letting this chatter tie up your expensive WAN links. On the LAN, where bandwidth is cheaper, you will want to use the fastest, cheapest, most reliable technology that you can get away with. At least in earlier times, that meant bridging.
A bridge is generally going to be faster than a router because the decisions it makes are much simpler. The manipulations it does to packets as they pass through it are much simpler as well. In the example, these bridges interconnect Ethernet and FDDI segments, so the Layer 2 information in the packets needs to be rewritten. This is a simpler change, though, than what a router needs to do with the same packet.
This old rule has merit, but it needs to be modernized. It is still a good idea to keep broadcast traffic off of the WAN, for exactly the same reasons that it was important 10 to 15 years ago. However, two current trends in networking are leading network designers away from universally bridging throughout a campus. First, many more devices are being connected to the network than there ever were in the past. Second, certain changes in network technology have changed the way things scale.
Let me explain what I mean by this second point. In the old-style network of Figure 3-11, user workstations were connected to shared 10Mbps Ethernet segments. All segments were interconnected via a 100Mbps FDDI ring. If you have a dozen active devices sharing a 10Mbps Ethernet segment, the collision overhead limits the total throughput on the segment to somewhere between 3 and 5Mbps in practice. So each of these dozen devices can use a steady state bandwidth of a few hundred kbps and a burst capacity of a fewMbps.
Today it is common to connect end devices directly to 100Mbps Fast Ethernet switch ports, and backbone speeds are several Gbps. Thus, each station has access to a steady state bandwidth of 100Mbps sending and receiving simultaneously. Each station is therefore able to use 200Mbps of backbone capacity, with the lack of local contention increasing the tendency for routine traffic to burst from very low to very high instantaneous loads. This is almost a factor of 1000 higher than in the older style of network, but our backbone speed has only increased by a factor of between 10 and 100.
In other words, each station is now able to make a much larger impact on the functioning of the network as a whole. This is why traffic prioritization and shaping (flattening out the bursts) have become so much more critical in network design. If more cars are on the road, there is a limit to how much the flow rate can be improved by just increasing the number of lanes. New methods of traffic control are needed as well.