Figure 3-12. Hierarchical network-design concept
What's really valuable about the old-style design shown in Figure 3-11 is that it leads to the useful and practical concept of hierarchical network design. Figure 3-12 and Figure 3-13 show what a hierarchical network design is and how it works. At this point, however, whether this network is basically bridged or routed is still questionable.
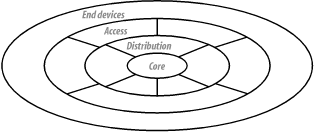
Figure 3-12 is a conceptual drawing of the hierarchical design model. There are three main levels, the Core, Distribution, and Access. These terms are widely used. End stations are connected at the Access level. You will sometimes see a drawing like this in which central servers are connected at the Core. If end node devices are connected at the Core, then the model is not strictly hierarchical. It may be some sort of hybrid. Or, more likely, the diagram could be an application-oriented diagram rather than a network diagram.
Figure 3-12 shows how connections are made. End devices connect at the outside edges of the diagram. They are connected to the Access Level of the network. This level exists primarily to give a place for these end devices to connect to the network. At the center of the diagram is the Core Level, which performs the main traffic switching functions, directing packets from one part of the network to another. The Distribution Level exists to connect the Access and Core Levels.
The name "Distribution Level" is appropriate for a couple of reasons. First, this level is what allows the network to spread out the distributed backbone. Second, the Distribution Level distributes data from the Core out to the Access Levels of the network.
The basic idea is to separate the different functions of the network and hopefully make them more efficient. What does a network do? It directs traffic (Core), it conveys packets from one place to another (Distribution), and it provides connection points for end devices (Access). In a small network these functions could all be performed in one box, or even a simple piece of wire. But the larger the network, the more these component functions have to be separated for efficiency.
There are usually important cost advantages to using a hierarchical model. For example, the Access Level needs to give a high port density with a low cost per port. At the Core Level, it is more important to have high throughput devices with a few high-speed ports. Expecting one type of device to fill both of these categories isn't always reasonable.
Figure 3-13 shows a more specific example of how to think about hierarchical design models. In the middle is the Distribution Level, which carries traffic between the various Access groups and the Core. Two new ideas here were not shown in Figure 3-12. The first is the addition of some redundancy; the second is the implication that not all traffic needs to cross the Core.
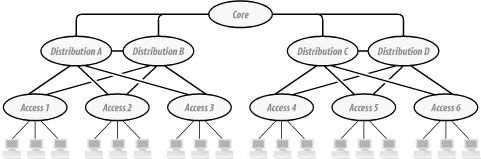
Each of the Access Level devices is connected to two devices at the Distribution Level. This connection immediately improves the network throughput and reliability. Doing this has effectively eliminated the Distribution Level devices as single points of failure. For example, if Distribution "cloud" A broke then all three of the Access groups using it can switch over to Distribution "cloud" B transparently.
I am deliberately leaving the contents of these clouds vague for the moment. Notice that I have included a connection between Distribution clouds A and B so that the Core connection for either can break and traffic will simply shift over to the other.
Now consider the traffic patterns. Suppose an end device connected to Access cloud 1 wants to talk to another end device in the same cloud. There is no need for the packets to even reach the Distribution Level. Similarly, if that same device wants to talk to an end node connected to Access cloud 2, it doesn't need to use the Core. The packets just go through Distribution clouds A and B to get from Access cloud 1 to Access cloud 2. It needs to cross the Core only when the packet needs to go further afield, to another Access cloud that is not connected to the same Distribution cloud.
This principle is important because, if used carefully, it can drastically reduce the amount of traffic that needs to cross the Core. Because everybody shares the Core, the design principle needs to be used as efficiently as possible.
Recall the 80/20 rule that I mentioned earlier in this chapter. This rule is particularly applicable to the Distribution Level. If certain groups of users tend to use the same resources, then it makes sense to group them together with these resources. It's best to group into the same VLAN. But putting them into the same Distribution groups also saves traffic through the Core. In most large companies, separate business divisions have their own applications and their own servers. Try to consider these relationships when deciding how to divide your Distribution and Access groups.
To look more deeply into the various clouds shown in Figure 3-13, I need to first tell you where the network routes and where it uses bridging or switching.
Relaxing the "bridge on campus, route off campus" rule opens up the question of where to use routers. Designers could use them at every level of the LAN, including the Access Level, if they wanted to. Or, they could use them just at the Distribution Level and use switches in the Core and Access Levels. How do they decide what's right?
Well, you need to start by remembering what routers do. A router is a device that connects two or more different Layer 3 addressing regions. So, by the same token, routers break up Layer 2 broadcast domains. A router is also a convenient place to implement filtering, since it has to look much further into the packet than a switch does.
There are also negative aspects of routers. Every packet passing through a router has to be examined in much more detail than the same packet passing through a switch. The Layer 2 MAC addresses and framing have to be rewritten for every packet. Thus, latency through a router is necessarily going to be higher than through a switch.
Furthermore, Layer 3 dynamic routing protocols such as OSPF, RIP, and EIGRP must all be considered every time a router is installed. The designer has to ensure that the dynamic routing protocol will be stable and will converge quickly and accurately whenever the state of a network connection changes. The more routers in a network, the more difficult this process becomes.
Because of these negative aspects of routing, I would happily bridge the whole LAN if I could get away with it, but I've already discussed the inherent problems in this strategy. What else can be done?
When the requirements include filtering for security, the answer is easy; use a router. If a sensitive part of the network needs to be separated from the rest (for example, the Payroll Department or the Corporate Finance Department of a brokerage company), the designer should make sure that it's behind a router.
For the rest of the network, the routers are used only for breaking up broadcast domains. The improved congestion control properties from installing routers have to be balanced against the extra latency that they introduce. At the same time, you have to be careful of how you implement your dynamic routing protocols.
One way of implementing a router into the Core of a network is to use a so-called one-armed router. This picturesque term refers to a router that connects to several logical networks via a single physical interface. One clever modern way of accomplishing this feat is by making the router a card in a Layer 2 switch. This card, called a Layer 3 switch, then makes a single physical connection to the shared backplane of the switch. This backplane is generally an extremely high-speed proprietary medium. Attaching the router directly to it resolves several problems simultaneously.
First, you don't need to pay a huge amount of money to install a super high-speed network media module in the switch just to run the connection out to an external router. Instead, you can bring the router directly to the backplane of the switch. Second, the high bandwidth available on the backplane drastically reduces congestion problems that often plague one-armed router constructions. Third, because the Layer 3 switch module only has to form packets for the proprietary backplane of the switch, it is able to drastically reduce overhead required when routing between different media types. It only needs to know one Layer 2 protocol, which is the proprietary protocol used internally on the backplane.
It is possible to make a one-armed router act as a Layer 3 switch and achieve many of the same benefits. The single port on the router can be configured to support several VLANs, looking like a trunk connection to the switch. If this router-to-switch connection is sufficiently fast, such as a Gigabit or ATM link, then it is almost the same as a Layer 3 switch. Specifically, it has the benefit of being able to flip packets between different VLANs all using the same Layer 2 protocol.
This construction can be a useful way of getting the benefits of a Layer 3 switch when using equipment that doesn't support integrated Layer 3 switching, or for which the performance of these switches is poor. However, I would expect to see better performance from an integrated Layer 3 switch that is able to access the higher capacity backplane directly.
Using a construction in which several different Layer 3 networks converge on a single point makes sense. In a network like the one in Figure 3-11, putting a one-armed router on the FDDI backbone would have been fairly common. Then the various bridged Ethernet segments shown could be on different IP subnets. The FDDI interface on the router would also have an address from each of the various subnets. Although this scenerio was not uncommon, there are several deficiencies in a network built this way.
Network designers put routers into networks to separate broadcast domains. If they are just going to bridge everything together and have a single one-armed router in the middle, then they haven't separated the broadcast domains. Furthermore, they've made the network one step worse because they have introduced a new, artificial single point of failure for the entire network.
The same criticism is not necessarily true for Layer 3 switches, though. If the network consists of many VLANs, then the trunks between the switches ensure that all VLANs are visible on the backplane of the switch. Thus, the Layer 3 switch will not only route, but will also flip the packets between the various VLANs. This step can be done very efficiently, and the problem of failure to segregate the broadcast domains largely disappears (however, as I will discuss later in this chapter, it is possible to make bad design decisions for the VLAN structure that will negate this advantage).
The question remains, where should you use these sorts of devices? One obvious answer is the Core Level of the network. At the Core you have the greatest need for speed, and the greatest potential number of converging VLANs. But this second point is only true if you have no (or few) routers in the Access and Distribution Levels of the network. Figure 3-14 shows a hierarchical LAN design in which all VLANs converge on the Core of the network. In the two Core switches at the center, a pair of Layer 3 switches handles all routing for the network. Everything is redundant at the Core and Distribution Levels.
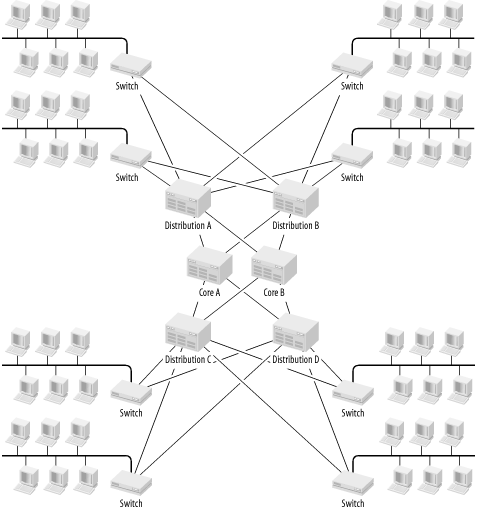
In this picture, there are four Access switches for each pair of Distribution switches. A total of four user LANs converge on the Core switches from above, and another four converge from below. Now the designer has to make important decisions about how to handle the VLAN trunks, which affect how routing is handled in the Core. There are many options. One option is to simply make everything one large VLAN, in which case there is no need to route anything. Or, one could make several small VLANs, all of which are visible everywhere in the network. Once again, this means that there is very little advantage to having the routers because all (bridged) VLANs must send their local traffic through the entire network anyway.
Always bear in mind that one of the key points in putting in routers is to limit the chances of broadcast traffic from one part of the network causing congestion someplace else. A VLAN is a broadcast domain, so you might think that making lots of VLANs results in small broadcast domains and eliminates your broadcast problems. This is only partially true, however. Remember that each trunk probably contains several VLANs. If an Access Level trunk circuit holds all VLANs for the entire network, it has to carry all of the broadcast packets. The effect is the same as if you had done no VLAN segregation at all, only with more inherent latency.
In Figure 3-14, I assume that I have been able to reduce the traffic so that the upper two Distribution switches carry completely different VLANs than the lower two. The only way to get between them is through the Layer 3 switches contained in the two Core switches. These Layer 3 switches also have to handle the inter-VLAN routing within each of these two groups of VLANs. Figure 3-15 shows the same picture at the Network Layer. In this case, it is easy to see the pivotal role played by the Layer 3 switch. For symmetry, I have shown four VLANs for both the upper and lower pair of Distribution switches (see Figure 3-14). However, as I will discuss later in this chapter, there is no need for the VLANs to correspond to the physical Access switches.
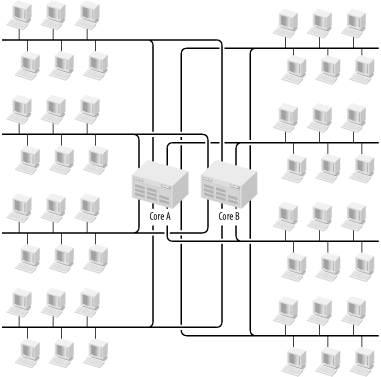
The important thing to note from Figure 3-15 is that a total of eight VLANs converge on the redundant pair of Layer 3 switches. It is not possible for traffic to cross from any VLAN to another without passing through one of them. Obviously, redundancy is an important concern, as I will discuss in a moment. But there's another important feature. Because all off-segment traffic for each segment must pass through these devices, they tend to become serious network bottlenecks if congestion is not controlled carefully. The fact that they are connected directly to the backplane of the two Core switches starts to look like a necessity. This relatively small example collapses eight separate full-duplex 100Mbps feeds from the various Access switches.
Another key feature shown in Figure 3-14 is redundancy. The two Core switches are completely redundant. If all of the traffic aggregates onto a single router that handles the whole enterprise, then that's one colossal single point of failure. With some manufacturers, you have the option of putting a redundant Layer 3 switch module in the same chassis. This option is certainly an improvement, as I showed in the previous chapter. It's still necessary to do all of the MTBF calculations to figure out how much of an improvement it gives, though, and to show how the result compares with having a completely separate chassis plugged into different power circuits.
Unfortunately, I can't do this calculation for every possible switch type because vendors implement new switches with awe-inspiring regularity. You need to watch out for devices with which the failure of some other component, such as a controller module, affects functioning of the Layer 3 switch module or its redundancy options. Every switch seems to do these things differently.
The bottom line is that, to achieve good redundancy with a single chassis device, there can be no single points of failure within the device. Typical MTBF values for the chassis of most switches is sufficiently long not to be a serious concern. If you are going to implement a single-chassis solution, however, it has to have redundant Layer 3 switch modules, redundant power (N+1 redundancy is usually sufficient), and redundant connections to all Distribution Level devices. It may also require redundant CPU modules, but in some designs the CPU module is used only for reconfiguring otherwise autonomous media modules. Be careful, though, because such a design might mean that redundancy of Layer 3 switch modules will not work in the event of a CPU module failure. In this case, the net MTBF needs to be calculated. Even in this case, I am talking about a multiple failure situation (CPU module plus one of the Layer 3 switch modules), for which the aggregate MTBF should still be quite high.
The other solution, which is conceptually simpler, is to use two separate chassis, as shown in Figure 3-14 and Figure 3-15. However, in this case you have to use a router redundancy protocol to allow one of these devices to take over for the other. In the most common (and most stable) configuration, end devices send all of their off-segment traffic to a default gateway. In the one-armed router model, this default gateway is the same physical device for all of the segments. To make the module in the second switch chassis become the active default gateway for all segments, it has to somehow adopt the same IP address.
This adoption is most easily accomplished by means of either the Cisco proprietary HSRP protocol or the open standard VRRP protocol.
When two or more routers or Layer 3 switches function between the same set of LAN segments, it is common to implement an additional segment just for the routers. This construction is shown in Figure 3-16.
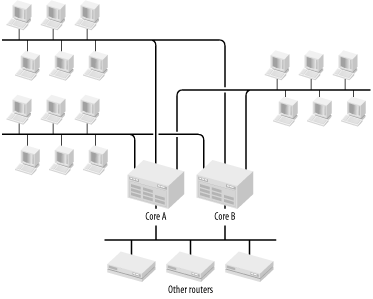
The diagram shows three user LAN segments connecting to the two routers called Core A and Core B. These two routers also interconnect using the special router-to-router segment. If other routers are in this location, then they would be connected here as well. These other devices might be WAN routers or other special function routers like tunnel termination points for X.25 or SDLC sessions, for example.
The router-to-router segment serves two main purposes. First, and most obvious, if special function routers are at this location, it provides a place to connect them where they will not suffer interference from user LAN traffic. In many cases, these legacy protocols exist because the applications using them are extremely critical to business. Routine word processing and low priority LAN traffic should not be allowed to disrupt the more important tunneled traffic, so it needs to go on its own segment. And, conversely, end-user devices don't need to see dynamic routing traffic.
To see the second reason, however, suppose that these other devices are not present and the network consists of the two Core routers and three user segments. Now suppose the first Ethernet connection on Core A breaks. HSRP or VRRP kicks in promptly, making Core B the default gateway for this segment. Core A is still the default gateway for the other two segments, though. Now consider the flow of traffic between Segment 1 and Segment 2.
A user on Segment 1 sends a packet to its default gateway, Core B. Core B forwards this packet out its port for Segment 2 and the user on this segment receives it. The response, however, takes a very different route. This packet goes to the default gateway for Segment 2, which is Core A, but Core A doesn't have an active port on Segment 1 because it's broken. It has to somehow send this packet over to Core B. I'll presume for the moment that there is a good dynamic routing protocol, so the two routers know how to get to one another and know which ports are functioning properly.
Core A sends the packet through one of the user LAN segments over to the Core B router. From there, it is sent out and received by the right user. So, there are two possibilities in this case. Either the packet was forwarded back out on Segment 2 to get over to the other router, or it was sent across on segment three. If it went via Segment 2, then that packet had to appear on this LAN segment twice, which could have a serious affect on overall congestion. If it went via segment three, then it potentially causes congestion on a completely unrelated user segment where it has no business being. This could be a security issue, but it is more likely just a congestion problem.
The easiest way around this sort of problem is to implement a special router-to-router segment. The routing protocols must then be carefully adjusted so that this segment is always preferred whenever one router needs to access the other.
Some network designers consider this problem aesthetic and ignore it. If all router ports are connected to high-bandwidth full-duplex switch ports, then the problem is much less dangerous. Another thing to remember is how VLAN trunks might be loaded in failure situations. For example, if the router-to-router segment is carried in the same physical trunk as the user segments, then it doesn't prevent congestion.
As long as I'm talking about router redundancy, I need to mention a special side topic because it can be quite dangerous. On the surface it sounds like putting those two routers in different physical locations would be a good idea. For example, they might be in different rooms, on different floors, or even in different buildings. This arrangement could save the network in the case of a fire or large-scale power problem. But it could also make some simpler types of problems much worse.
To see why, look at Figure 3-16 and suppose that the left half of the picture including router Core A and two user segments are all in one building and everything else is in another building. Now, suppose that you have a relatively simple and common problem—a fiber cut between the two buildings. I'll go one step further and assume that both routers have some other form of connection back to a central network. Perhaps this is actually part of the Distribution level of a larger network, for example. The problem still exists without this added twist, but I think this example makes it a little easier to see it.
When the fiber was cut, VRRP or HSRP kicked in and made sure that all three segments still have a default gateway, so all inbound traffic from the user LAN segments will be delivered properly. The problem is with the return path. Look at the ports for LAN segment number 1. Both routers Core A and Core B have valid connections to this segment, but only one of them actually contains the particular user expecting this packet. Which one is right?
In many cases, if the central router has two paths available with the same cost, it just alternates packets between the two. The first one gets to the correct destination. The second one goes to the other router—the one that has a valid connection to the segment that has the right IP address but just doesn't have this user on it because the connection between the two sides is broken. So the packet is just tossed off into the ether and lost forever.
Different routers implement this in different ways. For example, some routers work based on flows. A flow is a single session. This concept is important to Quality of Service, so it is discussed in detail in Chapter 8. In this case, the router handles each flow separately, routing all packets belonging to a particular session through the same path.
This just means that some sessions will work and others will try to follow the path that is broken. Also, for applications that do not use a Layer 4 connection, such as those built using UDP, it is not possible to divide applications into unique flows. In these cases, some of the packets will be randomly lost.
This will happen for all of the user segments. So a measure that was intended to give better reliability in a rare failure mode has actually reduced the reliability in a more common failure mode.
If you really want to use physical diversity in this way, it has to be combined with path redundancy. Instead of running all of your LAN segments through the same fiber conduit so they could all break together, you could have another fiber conduit. In this second conduit, you would run redundant connections for all segments. Then, to complete the picture, you would use Layer 2 switches with Spanning Tree to switch to the backup fiber in case the primary breaks.
Figure 3-17 shows how this concept might work. In this figure, I've only drawn one of the segments for simplicity. The thick dashed lines represent the backup fiber pairs, which go through the second conduit. For symmetry, I've also included a backup connection from Switch A to the user segment, even though this segment is within the same building. The connection between Switch A and Switch B is required for Spanning Tree to work properly, as I discussed earlier in this chapter.
The Core A and Core B routers are assumed to be directly connected to their respective switches, so you don't need to worry about extra redundancy in these connections. Spanning Tree is configured on Switches A and B so that when the primary fiber stops working, the secondary one is automatically engaged. The same procedure would be followed on all other segments, including the router-to-router segment, if applicable.
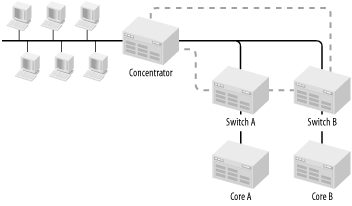
In this picture the local floor connection is shown as a concentrator. The actual technology is irrelevant, however. It could be a hub, or a switch, or even a piece of 10Base2 cable connected to the fiber pairs by means of transceivers.
There are three reasons why you might want to implement filtering on a router:
Security
Clean up for ill-behaved applications
Policy-based routing
If you really want hard security on an IP network, you should probably be looking at a proper firewall rather than a router. But, in many cases, you just want a little security. In an IPX network, a router may be the only practical option for implementing security precautions.
You can do several different types of security-based filtering on a router:
Filtering based on source or destination IP address
Filtering based on UDP or TCP port number
Filtering based on who started the session
Filtering based on full IPX address or the external network number
The decision about which combination of these different filters to use depends on what you're trying to accomplish. So, I want to look at some different examples and see how different filter rules might apply.
It is fairly common, particularly in financial companies, to have an external information vendor such as a news or stock quote service. The vendor's service involves putting a box on the client's internal LAN to allow them to access real-time information. The security problem is obvious: the external vendor theoretically has full access to the client LAN. Since financial companies usually have strict rules about access to their internal networks, they need to provide a mechanism that allows the information vendor's box to see only the genuine application data that it is supposed to see.
Assume that the vendor's special application server is hidden on a special segment behind a router. Now what sorts of filters can be implemented on this router?
The first type of filter, based on source or destination address, is probably not going to be useful here. There could be many internal users of this service, and you don't want to have to rewrite your filter rules every time somebody new wants access. It doesn't do any good to filter based on the address of the server because that's the only device on the special segment anyway.
The second type of filter, based on TCP or UDP port number, on the other hand, should be quite useful here. Since the application probably uses a designated port number (or perhaps a range), this could be a good way to identify the application packets.
The third type of filter is only useful if the application is TCP-based. If it is UDP-based, then the router cannot discern a session, so it can't tell who started the conversation. If it is TCP-based, and if the application starts with the user logging in (which is common), then this filter will help you to prevent the vendor's box from being used to initiate an attack on the client LAN.
What you really want is to combine the second and third filter types. You can do this on a Cisco router just adding the "established" keyword to an Access list for the required TCP port number.
The other example concerns the IPX filter. It's fairly common to have a special Novell server for sensitive data like personnel and payroll records, or other secret information. The payroll server makes a good example. The company might have this server on the Human Resources segment and use standard Novell authentication systems to ensure that only authorized people can see secret files.
But the organization may be concerned that these measures are not sufficient to prevent people from trying to give themselves a special pay bonus. To help prevent this, you can keep this server on a special segment and configure the router to disallow any access from off-segment. The trouble is that members of the Human Resources staff still need to get to the other corporate Novell servers. The CEO or other high-ranking corporate officials that it is supposed to seemight need access to the Human Resources server. So you can build a special filter that allows only the CEO's full IPX address (which includes the workstation's MAC address) to connect to the full IPX network number (including internal and external network numbers) of the server. Then you can allow all other internal network numbers to leave the segment. Consult your router vendor's documentation for information about constructing IPX filters.
Some applications do not behave in a friendly manner on a large network. An application might try to do any number of unfriendly things. For example, it might try to register with a server on the Internet. Or, it might send out SNMP packets to try and figure out the topology of the network. Sometimes a server tries to probe the client to see what other applications or protocols it supports. From there, the list branches out to the truly bizarre forms of bad behavior that I'd rather not list for fear of giving somebody ideas.
The trouble with most of these forms of bad behavior is that, if you have several hundred workstations all connecting simultaneously, it can cause a lot of irrelevant chatter on your network. If you don't have the spare capacity, this chatter can be dangerous. The SNMP example is particularly bad because a number of applications seem to think that they should have the right to poll every router on the network. In general, you don't want your servers to know or care what the underlying network structure looks like. It can actually become a dangerous problem because SNMP queries on network gear often use excessive CPU and memory resources on the devices. If several servers try to gather the same information at the same time, it can seriously hamper network performance. I have seen this problem cripple the Core of a mission-critical network during the start-of-day peak.
If you suspect that you have a problem like this, you need to use a protocol analyzer to get a good picture of what the unwanted information looks like. You also need to prove experimentally that this information is really unwanted. Some applications may just work in mysterious ways.
Once you have established what the unwanted data looks like and where it's coming from, then you can start to filter it out. Usually, it's best to put the filters close to the offending server (hopefully it's the server and not the client that is to blame) to help contain the unwanted traffic.
Policy-based routing is a Cisco term. Some other vendors' routers have similar capabilities, but I have to admit I learned this stuff first while using Cisco gear, so I still think in Cisco terms. This term means that the router is able to make routing or prioritization decisions based on whether a particular packet matches predefined characteristics. Perhaps it is a source or destination IP address, or perhaps a TCP, a UDP port number, or a packet size. By whatever mechanism, you define rules for what happens when the router receives packets of this type.
The rule may specify that you tag the packet with a special priority code so that every other device in the network will know that this packet is important and will forward it first (or last, or whatever). Or, the rule may be that certain types of packets use the high-speed trunk, while others use the low-speed trunk.
This last case, in which a routing decision is made based on the policy, is what gives the concept its name. It warrants special comment, though. In general, it is extremely dangerous to do this kind of thing for three reasons. First, it can interfere with redundancy mechanisms. Second, it makes troubleshooting unnecessarily difficult. (The low-priority ping packet gets through, but the application doesn't work. Is it the server or the high-priority trunk that's down?) Third, it has a nasty tendency to run up the CPU on your router (although this tendency is less likely in IOS Version 12 and higher because of support for FastSwitching of policy-based routing). Yes, it will work, but it's an extremely bad idea in most real world networks. Having said this, however, using the same feature to tag packets for priority works extremely well.
One final comment on filtering on a router: it's important to watch your CPU utilization. Modern routers tend to try to offload most routing decisions onto hardware associated with the port itself, so most packets never have to hit the CPU. This situation results in much faster and more efficient routers. But, depending on the router and the specific type of filter you are implementing, you may be forcing a lot of the processing back to the CPU. The result could be that your powerful expensive router is no longer able to handle even modest traffic volumes. So, when implementing filters, always take care to understand what it will do to the processing flow through the router. Often the best way to do this is simply to mock up the change in a lab and see what happens to your CPU statistics.
In a LAN, every connection that isn't routed must be either bridged or repeated. I won't discuss repeaters much in this book. In modern LAN technology, there is rarely a good reason to use them. In nearly all cases, a switch is a better choice, both for cost and functionality. For that matter, conventional bridges are also increasingly rare, having been replaced by switches.
Of course, these comments are mostly semantics. People still use hubs. And what is a hub but a multi-port repeater? People still use switches, which are really multi-port bridges.
If you are dealing with a portion of a LAN that is all logically connected at Layer 3, then you have two main choices for our Layer 2. You can use a hub or a switch. This is true regardless of whether the LAN technology used at Layer 2 is Ethernet, Fast Ethernet, or Token Ring. It is also true for Gigabit Ethernet, although in this case I question the usefulness of Gigabit Ethernet hubs, preferring switches in all cases. Fortunately, it appears that the market agrees with me, as I am not aware of any major network hardware vendor who has implemented the hub part of the Gigabit Ethernet specification.
So I'll start by discussing where to use hubs and where to use switches in an Ethernet or Token Ring environment.
Switches have three main advantages over hubs:
Higher throughput
The ability to communicate at full-duplex (Ethernet)
Better control over multicast traffic
There are two disadvantages to weigh against these advantages:
Switches are more expensive
It is much easier to use diagnostic tools such as protocol analyzers on a hub than a switch
A hub (sometimes called Media Attachment Unit [MAU] in Token Ring literature) is basically a way of sharing the network's Layer 2 medium. This sharing necessarily has overhead. In Ethernet, the overhead comes in the form of collisions. In Token Ring, it appears as token passing latency. In both cases, the system for deciding who gets to speak next takes a toll.
If you replace the hub with a switch instead, then this overhead essentially disappears. There are only two devices on the segment (or ring)—the end device and the switch itself. If it is a Token Ring switch, then every end device gets, in effect, its own token. There is never any waiting for the token, so each device can use the entire 16Mbps capacity of the ring.
If it is an Ethernet switch, on the other hand, the only times you should expect to see collisions are when both the switch and the end device try to talk at once. Even this small collision rate can be eliminated if you go to full-duplex Ethernet. On a large shared Ethernet segment, you can only practically achieve between 30% and 50% of the capacity because of the collision overhead. On a half-duplex switch this jumps well over 90% of capacity for every device and 100% for full-duplex switching. Thus, the net throughput of a switch is considerably higher than a hub with the same number of ports, for both Token Ring and Ethernet.
Most Fast Ethernet and many Token Ring switches can operate in a full-duplex mode. This means that they can send and receive simultaneously without collisions. Obviously this mode only works when a single end device is attached to each switch port. You can't have a full-duplex connection to a hub. Using a full-duplex switch has the effect of theoretically more than doubling the throughput to each device. It more than doubles because a half-duplex port still loses some capacity due to collisions. This advantage is most significant on servers, where it is not unusual to have a high volume of traffic both sending and receiving.
Broadcasts are an integral part of many network protocols including TCP/IP and IPX. However, having too many broadcasts on a network can cause serious problems. The most obvious problem is simply bandwidth utilization. However, it is important to remember that broadcasts are delivered to every end device. Because these broadcast packets are addressed generically, the network interface cards of these end devices cannot tell whether they are important. So they are all passed up the protocol stack to be examined by the main CPU of the end device. Having a lot of broadcasts on a LAN segment can cause CPU loading problems on end devices, even when they are not actively using the network. Thus, broadcasts must be controlled.
A bridge or switch is supposed to forward broadcasts. This is, in fact, one of the most fundamental differences between bridging and routing. Forwarding broadcasts allows devices that are part of the same Layer 3 network to communicate easily. All global information on the network is shared.
A hub can't stop a broadcast without breaking the Layer 2 protocol. Those broadcast packets have to circulate, and stopping one would also throw a wrench into the congestion control mechanism (token passing or collisions). A switch or bridge, however, can choose which packets it forwards.
Normally, the way a switch or bridge makes this decision is by looking at its MAC address table. If the packet has a destination MAC address that the switch knows is on a particular port, then it sends the packet out that port. If the packet has an unknown destination address or if it has a broadcast or multicast destination address, then the switch needs to send it out to every port.
If the network is very large, then the number of packets that need to go out every port can become a problem. Usually, in most networks, the broadcast volume is a relatively small fraction of the total number of packets. Pathological conditions called "broadcast storms" (see the discussion in the previous chapter) can make this broadcast volume suddenly high, though. If these conditions occur frequently, then serious performance problems may occur on the network.
Controlling broadcasts is one of the main reasons why network designers have historically gone from bridged to routed networks. With many modern switches, it is possible to push this decision further because of broadcast control mechanisms available on these devices. Usually, the broadcast control mechanism works by simply monitoring how frequently broadcast packets are seen on a port or on the switch as a whole. When the broadcast volume rises above this high-water mark, the switch starts to throw away broadcast packets.
Clearly, this threshold level has to be high enough that the network rarely loses an important broadcast packet (such as an ARP packet). It also has to be low enough so it doesn't interfere with the normal functioning of the network.
This way of treating broadcast storms is reasonably effective. It doesn't prevent them, of course; there will still be storms of packets. But this kind of simple measure ensures that they don't represent a serious traffic performance problem on the network.
There is an interesting trade-off in the place where the decision is made to start throwing away packets. If the decision is made on a whole switch that happens to be in a broadcast-heavy network, then throttling for broadcast storms can actually interfere with normal network operation. On the other hand, just looking at the per-port broadcast volumes ignores the possibility that the storm has been caused by the interaction between several different devices.
One of the most difficult types of broadcast storms to control starts with a single device sending out a broadcast packet. Then one or more other devices on the network receive this packet and respond to it by either sending out a new broadcast (such as an ARP for the originator's IP address) or forwarding the original broadcast back onto the network. A good example is the old RWHO protocol, which broadcasts periodically.
Some IP stack implementations like to send an ARP packet in response to a broadcast packet from an unknown source. This way, they are able to keep a more complete ARP cache. A large number of different devices that respond like this simultaneously, can choke the network for an instant. RWHO is still run on many network print servers by default for historical reasons (although I will never understand why it is still needed). This problem is actually rather common, and it can be extremely serious if the timeout in the ARP cache is shorter than the interval between RWHO broadcasts.
In this case, the per-port monitoring is not effective at stopping the storm. The storm originates with a single broadcast packet, which is the one that really should be stopped, but it is the response that causes the problem, and that response comes from everywhere.
The moral of this story is that just because you implement broadcast storm controls on your switches doesn't mean that you won't have broadcast storms. However, if you have such controls in place, you will be able to prevent this storm from migrating to another switch. The second switch will see an incoming storm on its trunk port and will block it. The problem is at least partially contained.
Redundancy in bridged networks is important for exactly the same reasons as in routed networks. The only differences are in the methods and protocols for redundancy. Just as in the router case, the first step is to install a second switch that is capable of taking over if the first fails. Thus, it needs an automatic mechanism for this to work effectively.
The most commonly employed fault recovery mechanism in bridged networks is the Spanning Tree protocol. The other type of fault recovery system that I mentioned earlier in the case of trunks is a multiplexed arrangement of individual connections. That type of system works well for trunks, but is very difficult to use to make the switches themselves redundant. It is difficult because the individual connection lines must connect between two specific endpoints. If you have a Distribution level switch connecting to a Core switch, you can use this type of system.
For good redundancy, you should have the Distribution switches connected to two Core switches. If the multiplexed bundle of links is split between two switches, then the packets can be sent in two different ways. Some trunk mechanisms treat the bundle in parallel and break up each packet into small fragments, which are each sent through different links and reassembled at the other side. Other multilink solutions, such as Cisco's Fast EtherChannel, ensure that each packet is sent through a single link intact. In this case, the extra capacity is achieved by distributing packets among the various links in the bundle.
In any case, splitting one bundle among two different switches makes it much harder for the switches to effectively manage the bandwidth. It is generally simplest to think of the bundle as a single logical trunk and connect it between the two end point switches. Just avoid splitting the bundles.
Most organizations do little or no filtering on their switches. For most networks, this is the right amount. It is generally much easier to filter on routers than switches. However, in some cases it is more effective to filter on the switches. In general, the same reasons for filtering on routers also apply here:
Security
Cleaning up for ill-behaved applications
The other reason I listed in the router case, policy-based routing, could theoretically apply here as well. But that sort of facility should be used sparingly at best, and where it is used, routers are a more natural place for it, so I do not include it here.
Security filtering is usually handled on switches in two ways. Many vendors offer some sort of port-level security, in which only a specified MAC address is permitted to connect to a particular port. The second type of security filtering typically restricts packets according to their contents, usually allowing only packets with certain source MAC addresses to communicate with sensitive devices.
Port-level MAC address security features allow the switch (or hub, since this feature is also available on some hubs) to lock out any devices except the one specified. If a particular workstation is supposed to be connected to a particular port, then only that workstation will function on that port. If another device is connected, it will have a different MAC address and the switch (or hub) will disable the port, requiring manual intervention.
This sort of feature is provided to prevent people from putting unauthorized equipment on the network. It is not perfect because many types of devices can use a manually configured MAC address instead of their burned-in-address (BIA). But it is a useful measure if this sort of problem is a concern. Note, however, that there is significant administrative overhead comes in maintaining the table of which MAC addresses are permitted on which ports throughout a large network. Generally, I wouldn't use this feature unless a compelling security concern warranted it.
In the second type of security filtering, you instruct the switch to look at the packet before transmitting it. If a sensitive server, for example, is only permitted to communicate with a small list of other MAC addresses, then this information could be programmed into the switch. Not all switches allow this sort of functionality, and it can be difficult to maintain such a switch. Once again, this feature should only be used if there is a strong overriding security concern.
I have already talked about certain broadcast storm problems. These problems are commonly handled with a simple volume filter. In some cases, it may be worthwhile to use a more specific filter. For example, I was once responsible for a network that suffered from the RWHO problem mentioned earlier. I was able to write a special purpose filter to restrict these packets on the switch. As for the security-based filtering, it was also a huge administrative problem. This sort of filtering should be used sparingly, and only where absolutely necessary. Bear in mind that switch manufacturers know this, so they tend not to provide extensive filtering capabilities.
Now that I have discussed how not to use VLANs, I'd like to turn to more positive matters. VLANs are typically used in bridged sections of a LAN, but they give two important advantages over older bridging techniques. First, they allow much more efficient use of trunk links. The ability to combine several segments into one trunk without having to first bridge these segments together allows you to use far fewer physical resources (ports and fiber or copper connections). Second, a VLAN-based architecture built on top of a rational hierarchical structure allows great flexibility in expanding or modifying the network without having to fundamentally change the Core.
Here are a few good ways of employing VLANs in a hierarchical network design. Figure 3-18 shows a rather typical VLAN topology. In this picture, several different segments are visible on the various Access Level switches. These VLANs are collected on the two redundant Distribution Level switches. At the Core, two redundant routers handle the VLAN to VLAN routing.
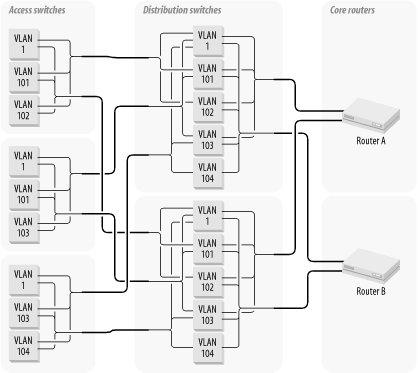
Although this diagram is a vastly simplified version of what you might find in a real large-scale LAN, it demonstrates some important features for VLAN topologies. First consider the trunk design.
Each Access Level switch has two trunk connections to redundant Distribution switches. This switch provides excellent fault tolerance. For the purposes of this discussion, let's assume that the trunks are configured so that only one trunk is active at a time. The primary trunk must fail completely before the secondary trunk becomes active. This fault tolerance scheme is fairly typical for trunks. Each Access switch has two trunk connections to provide complete redundancy. Notice that if you had to run a separate link for every VLAN, you would need six links for redundant connections to each Access switch. Worse still, if you added another VLAN on this Access switch, you would need two more ports and two more fiber connections. With the design shown in Figure 3-18 you can keep adding more VLANs to the existing trunks until you start to get congestion problems.
Figure 3-18 has five different VLANs. VLAN 1, the management VLAN, is present on all switches. I will talk about network management considerations in more detail later in this book, but for now I will just point out that separating your management traffic from your business traffic is a good idea. With this sort of VLAN structure, putting the management segment for all switches on the same VLAN is very convenient. In any case, one can generally expect management traffic requirements to be much smaller than for business application traffic.
VLAN 1 is used for network management because some low-end switches require their management IP address to be associated with VLAN 1. Since the VLAN naming convention is globally relevant over large portions of the network, it's a good idea to use VLAN 1 for management on all switches just in case it's required on a device somewhere in the region.
The other four VLANs are all user segments of various types. I have arbitrarily put two such user segments on each Access switch. The actual number of VLANs you should support on each Access switch depends on geography and port density. In general, it is a good idea to keep it fairly low for efficiency on your trunks.
Notice no user VLANs appears on all Access switches. VLAN 101 appears on the first two switches, but is not present on the third. Similarly, VLAN 102 is only configured on the first switch. This configuration is important because of the way it affects trunk utilization. The trunks serving the first Access switch carry no broadcast traffic from VLAN 103 or 104, so that spaghetti VLANs can be avoided. If I had not done this, I would have quickly wound up with Spaghetti VLANs. Remember that one of the main reasons for segregating our traffic is to break up the broadcast traffic. If all VLANs are present on all switches, then all broadcasts traverse all trunks. In such a network, the only benefit to using VLANs is that the end devices don't see as many broadcast packets. VLANs can provide much greater benefits if they are used more carefully, though. Network designers use VLANs for efficiency, so they should not throw that efficiency away on a Spaghetti VLAN topology.
The Distribution switches collect all VLANs. In general, this sort of two-point redundancy is a good idea at the Distribution Level, but there will usually be several pairs of Distribution switches collecting VLANs for large groups of Access switches. For example, this diagram might just show the first two Distribution switches, which collect the first 4 user VLANs (plus the management VLAN) for the first 12 Access switches (of which I have shown only 3). Then the next pair of Distribution switches might collect the next 6 user VLANs for the next 8 Access switches, and so forth. Each group of switches will have a VLAN 1 for management. This VLAN 1 may or may not be the same VLAN 1 throughout the network, but it can be simpler to handle routing if it is.
The previous example had the routers at the Core. This location turns out to be one of the most natural places for them in a VLAN-based network design. Suppose, for example, that you wanted to put your routers at the Access Level. Then you necessarily route between user VLANs, so it becomes harder to bridge different user segments via VLANs. The same is true to a lesser extent if you wanted to put the routers at the Distribution Level.
It's more difficult, but possible, to have the same VLAN existing on two different sides of a router. Figure 3-19 shows one way to accomplish this feat. This picture shows three switches interconnected by three different routers. Switch A holds VLAN 102, Switch B holds VLAN 103, and Switch C holds VLAN 104. VLAN 102 has IP address 10.1.102.0, VLAN 103 has 10.1.103.0, and VLAN 104 has 10.1.104.0. So, as long as the three routers know how to route to these three IP addresses, everything will work fine.
But there is a problem with VLAN 101. This VLAN, which has IP address 10.1.101.0, is present behind all routers. So if a device on VLAN 101 on Switch A wants to communicate with another device on VLAN 101 on Switch B, the packet will hit Router A and won't know where to forward this packet. After all, the IP address range 10.1.101.0 is directly connected to one of its Ethernet ports. The IP address range is broken up behind different routers. Even the VLAN tagging information present on the other three VLANs disappears as soon as it hits the routers.
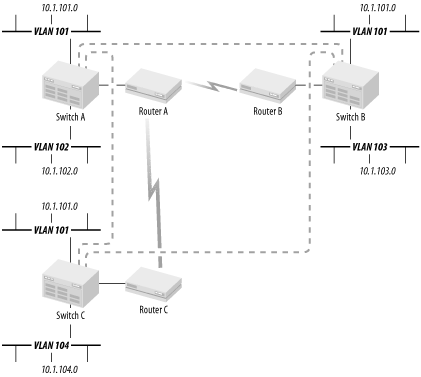
Routers are Layer 3 devices and they forward packets based on Layer 3 protocol information. VLAN information is fundamentally a Layer 2 concept. Thus, the only way to get around this problem is to configure a bridge or a tunnel that emulates Layer 2 between the various routers or switches (it could be done either as a router-to-router tunnel, or a switch-to-switch, or even switch-to-router bridge group). Then, when the device on VLAN 101 on Switch A sends a packet to the device on VLAN 101 on Switch B, the packet enters the tunnel and is transmitted to both Switch B and Switch C automatically. In short, the network has to bypass the routers.
There are many problems with this sort of solution. It is inherently more complicated because of the extra step of setting up tunnels or bridge groups. The designer has to be extremely careful that whatever fault tolerance systems he has in place supports the tunnel or bridge group transparently. As I have mentioned previously, having an IP subnet broken across two routers is disastrous.
There is also potentially much extra traffic crossing these links. Suppose a device on Switch C, VLAN 104, wants to communicate with a device on Switch A, VLAN 101. The packet first goes to Router C, where it is forwarded to the local Switch C instance of VLAN 101. Then the switch bridges the packet over to Switch A. This packet passes through Router C twice.
Now suppose a device on VLAN 101 on Switch A sends out a broadcast packet to every other device on VLAN 101. This packet has to be duplicated and sent out to both Switches B and C (hopefully they will be configured to not reforward the packet again or it will cause a mess), again passing through the local router twice. The network in this simple picture has effectively doubled whatever broadcast congestion problems it might have otherwise had.
Now suppose that a device on any of these VLAN 101 segments wants to send out a packet to a VLAN 102 device. The destination is not on the local segment, so the source device must send this packet to the default router. But there are three routers on this segment—which one is the default? In fact, it could be any of them, so a device on Switch A may need to send its packets to Router B, which then forwards the packet back to Router A to be delivered to VLAN 102. The backward path is just as convoluted.
The other problem with this configuration is that it makes network management difficult. Suppose there is a problem in the IP address range 10.1.101.0. The engineer trying to solve the problem still doesn't have any idea where that device is. There could be a problem with any of the three routers or with any of the three switches, and it could affect devices in one of the other locations.
The network designer should try to avoid this situation whenever possible. A good rule is to never try to split a VLAN across a router. It can be done, but the potential for serious problems is far too high. There is, however, one important case when it is unavoidable: when some external network vendor provides the intermediate routed network. The two sides of the same VLAN could be in different buildings on the opposite sides of a city, for example. If the link supplied by the network vendor is provided through a routed network, then there may be no other option but to use such an approach.
So far I've talked about trunk links like they had some sort of magical properties, but there is really nothing particularly special about them. A trunk can be any sort of physical medium. Generally, it should support relatively high bandwidth to be effective, but the actual medium could be just about anything. The most common technology used in trunks is Fast Ethernet, although Gigabit Ethernet is increasingly popular. ATM links are also used frequently. FDDI used to be fairly common, but it is being replaced as a trunk technology because Fast and Gigabit Ethernet systems are cheaper and faster.
What makes a trunk link special is the fact that it carries several distinct VLANs simultaneously. This is done by an extremely simple technique. Each packet crossing through the trunk looks exactly like a normal packet, but it has a couple of extra bytes called the VLAN tag, added to the Layer 2 header information. The tag's precise format and contents depend on the specific trunk protocol.
Trunks are useful because they allow the network designer to economize greatly on switch-to-switch links. If you had to carry three different VLANs (a modest and reasonable number) from an Access switch to a pair of redundant Distribution switches without using trunks, you would need at least six links. But if you did use trunks, you could achieve full redundancy with only two links. Better still, if you suddenly had to set up a new VLAN on that Access switch, you could do it all in software. There is no need to run another pair of uplink fibers to the Distribution switches.
To work as a trunk connecting two switches, both ends must know that the link in question is intended to be a trunk. They must also agree on the trunk protocol (which specifies the VLAN tagging format). This protocol usually has to be configured manually. But then, by default, most switches treat this link as a common trunk for all the VLANs this switch knows about. Some switches allow you to separately specify which VLANs use which trunks. In some ways, this specification is contrary to the spirit of trunks. But it can be a simple method for balancing the loading of your trunks, and in particular a method to divide up the broadcast traffic.
Generally, the trunks connect Access Level switches to Distribution Level switches in hierarchical network designs. Then there may or may not be further trunks connecting Distribution to Core Levels, depending on where the routers are. Extending trunks between two Access Level devices is not usually recommended; one usually wants to keep the relationship between the different levels as clear and clean as possible. Access devices that act as Distribution devices can make troubleshooting network problems difficult.
There is an IEEE standard trunk protocol, called 802.1Q. Because this standard was developed and released in 1998, after the requirement for such a protocol appeared, a handful of vendor-proprietary trunk protocols also exist. One of the most common is Cisco's ISL protocol, but several other proprietary trunk protocols are on the market.
ISL and 802.1Q share many similarities. Both protocols feature a generic VLAN header that can support several different standard LAN types. A trunk can contain many different VLANs, each of which can run many different Layer 3 protocols.
Other proprietary trunk protocols have other nice features as well. The Cabletron SmartTrunk system was relatively popular at one time because of its automated fault-recovery and load-sharing properties.
However, I recommend using the open standard wherever possible. All major manufacturers now implement 802.1Q, so there is very little reason to use the proprietary trunk solutions any longer, and I don't recommend doing so. The unique nature of trunking makes it one of the most important areas for using open standards.
Most networks have distinctly different requirements at their Access Level than in the Core or Distribution Levels. Consequently, it is quite likely that the switches at these different levels could come from different vendors. Since the hierarchical design model has most of its trunks running between these different levels and only a small number within a level, there is a good chance that you will have to connect a trunk between switches made by different vendors.
The difference between a regular Ethernet frame and an 802.1Q tagged frame is shown in Figure 3-20. Four extra octets (8-bit bytes) are added to the frame just before the length/type field. To ensure that this tagged frame isn't mistaken for a normal Ethernet frame, the "tag type" field is always the easily identified sequence "81-00" (that is, the first byte is 81 in hex and the second is 00 in hex). Then the remaining two bytes specify the VLAN information. For compactness, these two bytes are broken down into three fields of different bit lengths.
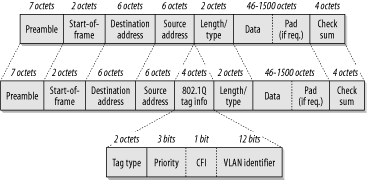
The priority field is a three-bit number, also called "Class of Service" in some literature. Because it has three bits, this field can have values from 0 to 7. I will talk more about prioritization later in this book. But for now it's important only to note that Class of Service is a MAC-level priority, so it is not the same thing as the higher layer QoS concepts such as the TOS (Type of Service) or DSCP (Distributed Services Control Point) fields in the IP packet header. Putting this new Class of Service field in Layer 2 makes it easier for Layer 2 devices such as switches to use it.
Also note that the priority field is independent from the VLAN identifier field. It is possible to classify priorities on a trunk so that one VLAN has precedence over another and that a particular application on one VLAN has precedence over another application on a different VLAN. This concept will be important when you start to encounter congestion on your trunks.
The one-bit CFI field is the "Canonical Format Indicator." This field is set to 1 if a RIF (Routing Information Field) is in the Data segment of the frame, and 0 if there isn't. A RIF is a piece of information that allows a device to request a particular path through a bridged network. The CFI field makes it easier for switching devices to deal with RIF data by saving them the time of looking for this data when it isn't present.
And then comes the 12-bit VLAN identifier field. Having 12 bits, it could theoretically handle up to 4,094 different VLANs (since there is no VLAN zero and VLAN 4,095 is reserved). But I urge caution in configuring VLAN numbers greater than 1000 because of intervendor compatibility problems. The problem is that some switch vendors implement VLANs internally using their own native proprietary systems and then merely translate to 802.1Q. Some of these internal schemes have trouble with VLAN numbers greater than 1000. Worse still, some early VLAN schemes could only support a few hundred VLAN numbers, so don't assume that it will work until you've tried it.
Always remember that if you share VLAN numbers across a large Distribution Area, every switch in this area must agree on VLAN numbers. This is rarely a serious problem because a Distribution Area containing more than a few hundred VLANs would suffer from serious efficiency problems anyway.
All of our discussion of trunks so far in this chapter has assumed that you will run redundant trunk links everywhere, but, in fact, there are two different ways to handle trunk redundancy. You can use Spanning Tree to keep one entire trunk dormant until there is a failure on its partner. Or, you can run both trunks simultaneously and consider all of the individual VLANs running through them to be distinct virtual links. Then you can run Spanning Tree separately for each VLAN.
In fact, it is not possible to run Spanning Tree separately for each VLAN when using 802.1Q, but it is possible with other trunk protocols, such as Cisco's ISL.
The per-VLAN option is considerably more complex, but it can sometimes be useful. Consider, for example, the network shown in Figure 3-18. The first Access switch has trunk connections to both Distribution switches. Suppose the upstream connections to VLAN 101 on the first Distribution switch were to break. In this case, you would want to use the second trunk, which goes to the second Distribution switch.
This scenario is actually relatively easy to get around. All you need is a trunk link between the Distribution switches. Then the first Distribution switch acquires its lost connection to VLAN 101 via the second Distribution switch through this trunk link.
In fact, it is extremely difficult to come up with examples where this is not the case. In general, since I always prefer simplicity to complexity, I prefer to use Spanning Tree on whole trunks rather than more individual VLANs within a trunk. Further, because many switches do not support running Spanning Tree for individual VLANs, compatibility helps to dictate the best methods as well.
However, this example brings up an important issue. If you run Spanning Tree on the individual VLANs in a network, you should not run it on the trunk as a whole. Conversely, if you run it on the trunk, you should disable it on the individual VLANs. It is very easy to generate serious loop problems by using a mixture of the two approaches.
When considering trunk redundancy, it is important to think through what will happen when a trunk breaks. A good hierarchical design with Spanning Tree should have very few problems recovering from a fault. One thing to beware of is a failure that breaks a Layer 3 network.
Figure 3-21 shows a network that has two routers for redundancy. These networks both serve the same IP subnet and the same IPX network. Assume that they have an automated system for IP redundancy such as VRRP or HSRP. No such system is required for IPX, so if the primary router on the segment fails, the other one will take over.
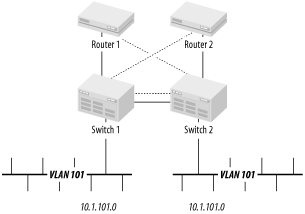
The same VLAN, number 101, which has IP address 10.1.101.0, exists on both switches. Then, for diversity, the first router connects to the first switch and the second router connects to the second switch.
This design is seriously flawed. Consider what happens when the trunk connecting the two switches fails. Suddenly two distinct unconnected LAN segments have the same IP address range and the same IPX network number. Now both routers provide valid routes to these networks. Thus, no communication will work properly to either segment. This is almost exactly the same problem I described earlier with two routers on the same LAN segment, but here you can see that it happens with VLANs as well.
How does one resolve this problem? A couple of different approaches are available. One method connects both routers to both switches, as shown by the addition of the dashed lines in Figure 3-21. This solution is not always practical, depending on the capabilities of the routers, since it implies that both routers have multiple interfaces on the same network.
In fact, the simplest solution is to just run a second trunk between the two switches, as shown with the dotted line. Then you can simply rely on Spanning Tree to activate this link if the primary fails. Furthermore, if you suffer a complete failure of one entire switch, then you lose half of your workstations, but at least the other half continues to work. A failure of one router allows the other to take over transparently, so this is the most acceptable solution.
However, in a good hierarchical design, this sort of problem is less likely to arise because each Access switch connects to two different Distribution switches. Thus, the network would need to have multiple simultaneous trunk failures to get into this sort of problem.
Some types of servers support VLAN trunks directly so that you can have a single server with simultaneous presence on several different VLANs, as shown in Figure 3-22.
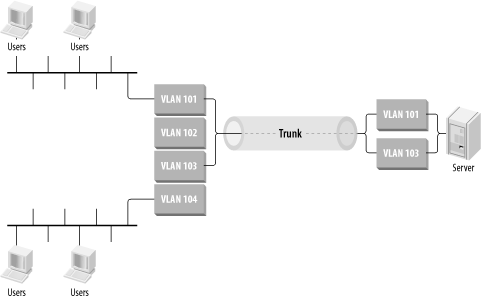
This is certainly an interesting thing to do, but it's important to understand why you would want to do this before trying it. There are different ways to achieve similar results. For example, many servers support multiple network interface cards (NIC). Installing two NICs in a server and connecting them to different VLANs via different switch ports has the benefit of simpler configurations on both the switch and the server and provides higher net throughput. Alternatively, if you can't afford to use multiple physical ports for whatever reason, then you could just as easily put the server behind a router and let the traffic route to all of the different user segments.
However, this strategy is cost-effective in some cases. For example, if the trunk connection is a Gigabit Ethernet link, it might be significantly less expensive than deploying a router solution, as routers with high-speed interfaces tend to be very expensive. At the same time, Gigabit Ethernet ports on switches can be costly. This strategy may be a convenient way of deploying a server for multiple user VLANs.
However, this method does not scale very well. If there will be many such servers, it would likely be less expensive in the long run to build a specialized high-speed server segment behind a router. Because it is a trunk link, the different VLANs will also compete with one another for server bandwidth on this link.
In previous chapters I made the point that only network devices should perform network functions. Therefore, I don't like connecting an end device to multiple VLANs, whether it is through a single port or through multiple ports. An end device should have a single connection to the network unless there is a compelling reason to do something more complicated.
One of the key concepts in building a VLAN-based network is the VLAN Distribution Area. Many networks have only one VLAN Distribution Area, but having only one in extremely large networks is not practical. It may be useful to break up the Distribution Areas of a network to improve efficiency. Figure 3-23 shows what I mean by a Distribution Area. This example is unrealistically symmetrical but the symmetry is not relevant to the concept.
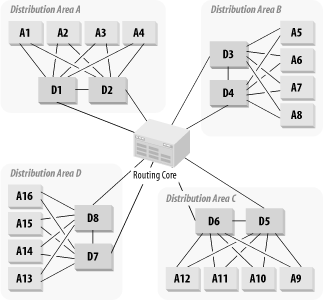
In this diagram, four Access switches are connected to each pair of Distribution switches; Access switches A1, A2, A3 and A4 all connect to Distribution switches D1 and D2. Similarly, the next four Access switches connect to the next two Distribution switches, and so on. The central routing Core of the network allows the VLANs that appear on these various switches to connect to one another.
The four VLAN Distribution Areas in this picture are arbitrarily named A, B, C, and D. There is really no need to name your Distribution Areas, but it might help to rationalize the scheme if you do so. The essential idea is that the VLAN scheme is broken up so that there is no connection between the VLANs of different areas.
Why would you want to break up the scheme this way? Well, there are two main advantages to this approach. First, you may need to reuse certain VLAN numbers. This might happen because certain VLAN numbers such as VLAN 1, which is often reserved for network management purposes, are special. Or, it may happen simply because of limitations on VLAN numbering schemes on some hardware. For example, some types of switches only allow VLAN numbers up to 1000 or 1005, despite the theoretical limit of 4094 in 802.1Q.
The second and more compelling reason for breaking up your VLAN Distribution Areas is to simplify your Spanning Tree configuration. The network shown in Figure 3-23 has four different Root Bridges. All traffic has to pass through the Root Bridge in Spanning Tree networks. This situation can result in wildly inefficient traffic patterns. Breaking up your hierarchical design, as in this example, allows you to control your traffic patterns so that all packets between Core and Access Levels take the most direct path.
The disadvantage to building a network this way is that it makes it harder to share VLANs throughout the larger network. For example, since no trunks exist between Distribution Areas A and B, sharing VLANs between these areas is not possible. It is critically important that you thoroughly understand what VLANs need to go where when constructing a VLAN Distribution system.
In most cases, it is best to build these Distribution Areas geographically. It is quite rare to find an organization that does not physically group employees performing related tasks. If there is a need for easy information sharing over the network, then chances are that this need exists for physical proximity as well. This is not true universally, of course, but most organizations attempt to group themselves this way. A logical way to build Distribution Areas would be to build on a campus LAN, or by groups of floors in a large building.
The other nice feature about using Distribution Areas in this way is that it tends to prevent propagation of the VLAN Spaghetti problem. It tends to force the network to use both a reasonable number of VLANs in an area as well as prevent too much geographical spreading of VLANs.
Although technical and theoretical limitations on how many VLANs one can define in a VLAN Distribution Area exist, practical limitations are considerably lower. The Distribution switches have to see all of these VLANs, as do the routers that allow VLAN-to-VLAN connections. If the connection to the router is done by means of trunk connections, then the router has to have a logical interface for every VLAN.
Every additional VLAN in a Distribution Area requires additional CPU and memory resources in the Distribution (and possibly also the Core) Level of the network. Since every vendor implements these features differently, establishing solid rules for the maximum number of VLANs in a VLAN Distribution Area is not possible. A dozen VLANs are not likely to cause any problems, but a thousand is probably a bad idea. The two places you need to be concerned about are the routers that handle VLAN-to-VLAN connections and the Distribution switches (particularly the Root Bridge) that have to handle all the individual VLANs.
On Cisco routers, the usual rule for a safe upper limit to the number of logical interfaces is somewhere between 50 and 200, depending on the type of router and the amount of processing required. If the router (or Layer 3 switch) has to do a lot of filtering or has to look at more than just the destination address of each packet, then the number of VLANs should be reduced radically.
Remember that these numbers, while just general orders of magnitude, are for the entire router. If the router is used to interconnect several different Distribution Areas, then the number of VLANs in each area should be kept low to allow the router to function effectively.
The same arguments apply to the switches themselves. If the Distribution switches act strictly as switches, without needing to do any filtering, prioritization or other CPU intensive activities, they should be able to handle more VLANs. The more additional work the switch needs to do, the fewer VLANs it should have to carry.
In many cases, the governing factor for how many VLANs to allow in a Distribution Area is actually the backplane bandwidth of the Root Bridge (which should be the primary Distribution switch for the area) and the aggregate downstream bandwidth used by the trunks to the Access switches. There is a single Root Bridge through which all off-segment packets for a VLAN must pass.
Earlier in this chapter, I said that a good rule for trunk aggregation is to assume that 5% of the devices on the network will burst simultaneously. If you apply this limit to the backplane of the Root Bridge, then you should get an extreme upper limit to how many devices should be supported by a single Distribution Area, independent of the number of VLANs used.
Typical modern switch backplane speeds are between 10 and 50Gbps. If all workstations are connected to Fast Ethernet ports, then this switch can support somewhere between 10,000 (for the 10Gbps backplane) and 50,000 (for the 50Gbps backplane) workstations. Because the aggregate backplane speed includes all possible directions, I have included a factor of 2 to account for both sending and receiving by the bursting workstations.
Clearly, these numbers are vast overestimates for several reasons. First, these nominal aggregate backplane speeds are measured under optimal conditions and ideal traffic flow patterns that are almost certainly not realized in a live network. Second, this switch may have to do a lot of work filtering, tagging, and prioritizing traffic, as well as its primary switching functions. So it probably doesn't have the CPU capacity to handle this much traffic, even if its backplane does. Third, you should always keep a little bit of power in reserve for those rare moments when the network is abnormally busy. Fourth, related to the third point, you should always allow room for growth.
A reasonably safe hands-waving estimate for the maximum number of workstations that should go into a Distribution Area is somewhere on the order of 1000. If every VLAN supports 50 workstations, it would probably be a good idea to keep the number of VLANs in each Distribution Area at around 20.
As the backplane speeds of these switches increases, generally so do the attachments speeds of devices. The reader may have access to switches with backplane speeds of several hundred Gbps that were not available when this book was written. If the reader also has a number of devices connected using Gigabit (or the emerging 10Gbps Ethernet Standard), then the factors still come out about the same.
![]()