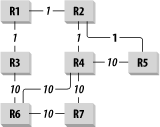
Figure 6-7. A simple OSPF network
Open Shortest Path First (OSPF) uses a Link State Algorithm for finding the best paths through a network. This is a completely different way of looking at dynamic routing than with the Distance Vector protocols discussed earlier. Version 2 of OSPF is the most recent. It is defined in RFC 2328.
Routers running OSPF don't exchange routing tables with one another. Instead, they exchange information about which networks they connect to and the states of these links. This state primarily means whether it is up or down, but it also includes information about its type of interface. Every router in the OSPF area (a term that I define shortly) carries an identical copy of this Link State database. The database of links in the network is then used to create a shortest-path tree, from which the routing table is calculated.
A simple example should help to explain these concepts. Figure 6-7 shows a simple network that runs OSPF. For now I avoid any questions of media type and IP addressing. These are all point-to-point links. Arbitrary cost is indicated beside each link in the diagram. Some of the links are faster than others. I use a cost of 1 for allfast links and 10 for the slow ones.
Table 6-3 shows the Link State information for this network.
|
R1 |
R2 |
R3 |
R4 |
R5 |
R6 |
R7 |
|
|---|---|---|---|---|---|---|---|
|
R1 |
1 |
1 |
|||||
|
R2 |
1 |
1 |
1 |
||||
|
R3 |
1 |
10 |
|||||
|
R4 |
1 |
10 |
10 |
10 |
|||
|
R5 |
1 |
10 |
|||||
|
R6 |
10 |
10 |
10 |
||||
|
R7 |
10 |
10 |
Now OSPF uses this Link State information to construct a shortest-path tree. Even though the Link State information is identical on every router, each one has its own unique shortest-path tree. Figure 6-8 shows the shortest-path tree for Router R6. At first glance it looks like just a redrawing of the same network diagram from Figure 6-8, but it is actually somewhat different.
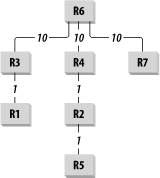
In particular, although there is a connection from R4 to R7, R6 would never use this link because it has its own links to each of these destinations. Also, the shortest path from R6 to R5 in terms of number of hops goes R6—R4—R5. But the link from R4—R5 is slower than the apparently longer path from R4—R2—R5. Since the shortest-path tree only cares about the links the network will actually use, it shows this more circuitous (but nonetheless shorter in terms of cost) path.
Every router in the network builds its own shortest-path tree and uses this information to construct its routing tables. Each entry in the routing table indicates the next hop, exactly as it did for the other routing protocols mentioned earlier.
The preceding example was deliberately constructed so that there one would be only one best path to each destination. In any real network this is rarely the case. OSPF provides a mechanism called equal-cost multipath. This means that the tree-building algorithm actually discovers and uses these alternate paths. This makes the picture harder to draw, but it works the same way conceptually.
Different vendors have different ways of dealing with equal-cost multipath routing. In most cases there is a configurable maximum number of paths that will be considered. If there are four equal-cost paths to a destination, the router might only use the first two that it discover. Usually this does not cause any problems, but it could result in routing tables that do not look as expected. Consult your router vendor's documentation for details on how it handles equal-cost multipath routing.
OSPF requires that every router in a grouping have the same Link State database. Scaling efficiency dictates that these groupings shouldn't contain more than about 50 routers. This number is far too small to support most large networks. So clearly there must be a mechanism for subdividing OSPF ASes.
This AS has the same meaning as it did for the discussions of RIP, IGRP, and EIGRP. It is a large administrative grouping of routers that all share routing information using a single IGP.
An area is simply a group of routers that all share the same Link State database. The process by which all routers in an area learn the Link State database from one another is called flooding.
When a new router connects to the network, it first attempts to establish neighbor relationships with every other router that it can see directly. Most of these neighbors will then become adjacent, meaning that they directly exchange Link State information with one another. There are exceptions where routers that are neighbors do not become adjacent, but I discuss this later.
Then the new router sends its current Link State to all of its adjacent neighbors. This Link State information is contained in a Link State Advertisement (LSA). Since every router taking part in this OSPF area needs to see the same Link State database, the neighbors proceed to pass this information along to all of their adjacent neighbors. These neighbors in turn send the new information to their neighbors and so on until every router in the area has updated its database. Meanwhile, the new router also receives the current Link State database from its neighbors. Very quickly every router in the area obtains the new database. They then must recalculate their shortest-path trees and the resulting routing tables.
The fact that every router in an area must have an identical copy of the Link State database poses an important scaling problem with OSPF. The more routers there are in the area, the more different links each router has, and the more memory the Link State database will consume. This is actually the smaller problem, though. A more serious scaling problem comes from the difficulty in calculating the shortest-path tree as the area becomes more and more complicated.
The usual rule of thumb is that no area should contain more than 50 routers. In a simple network design where every router's shortest-path tree is easily calculated, this number can be pushed up. This is particularly true if the routers are all configured with faster processors and extra memory.
However, it is a good idea to keep OSPF areas small and simple. This helps ensure that the network can respond quickly and accurately to topology changes.
In general, routers that are neighbors are also adjacent. But there are places where this is not the case. The exceptions happen for broadcast media like Ethernet segments and Token Rings, as well as for Nonbroadcast Multiple Access (NBMA) media. ATM and Frame Relay networks can be implemented as NBMA, as can some types of wireless networks.
If a broadcast medium such as an Ethernet segment contains several routers, then every router is a neighbor to every other router. This effectively forms a mesh of relationships. As I mentioned earlier in this book, meshes do not scale well. So OSPF allows routers on broadcast and NBMA networks to simplify their relationships by electing a Designated Router (DR) for the segment. They also elect a Backup Designated Router (BDR) to take over if the DR fails. Then every other router on the segment becomes adjacent to only the DR and BDR. This changes the mesh into a star.
The DR handles all flooding of Link State information for the segment. This router does not take on any special role in routing, however. The DR function is only used to make exchange of Link State data more efficient.
If the DR becomes unreachable for any reason, then the BDR automatically takes over for it and becomes the new DR. It remains in this role until it also fails. So in many networks the DR is just the router that has been up the longest. But this is not always desirable. For administrative reasons, sometimes a network designer wants to restrict which routers take on these functions. In this case, it is possible to set an OSPF priority on every router connected to the broadcast or NBMA medium to control the election process.
The router with the highest priority is elected as the DR, and the second highest becomes BDR. However, this election only happens if there is no DR, either because it's a new network or because the DR has failed.
Frequently there are routers that the network engineer does not want as DR for the segment. In this case the priority is simply set to zero.
OSPF allows the designer to break up the AS into a number of smaller areas. Between these areas are Area Border Routers (ABR). An ABR controls the flow of routing information between the different areas, while maintaining distinct Link State databases for each.
There are two main types of areas and a number of subcategories. The main distinction is whether an area is capable of acting as a Transit area.
A Transit area carries traffic that originates in a different area (or a different AS) and is destined for still another area. These external destinations may be other areas, or they may even be other ASes, perhaps running different routing protocols. Conversely, a non-Transit area is one that can only carry traffic that either originates or terminates in that area.
The main reason for this distinction has to do with how external routes are summarized. If an area uses summary and default routes for everything external, then other areas can't use it to get to external or other areas. It simply doesn't have sufficient information to allow this kind of flow-through. So a Transit-capable area is one that does little or no summarization.
There are three common options for how this summarization can be done. They are called Stub, Not-So-Stubby, and Totally Stub.
A Stub area is one that uses a summary route for everything outside of the AS. If the whole network is contained in one AS, perhaps with a single default route to the Internet, then a Stub area provides very little benefit. However, Stub areas can be quite efficient in networks that have a large number of external routes.
If any of the routers in the area connect to a different AS, then the area cannot be Stub. However, it is possible to use a Not-So-Stubby Area (NSSA) for this purpose.
NSSA are defined in RFC 1587. This option allows for the summarization of some external routes but not others. If there is a router internal to the NSSA that connects to the external AS, then those external routes are not summarized. Any external routes that originate in a different area are summarized.
Finally, a Totally Stub area summarizes everything from outside of the area. So even routes that are internal to the AS but originates in a different area appear only as summary routes. This can be useful for portions of a network where routers have limited resources. It is also useful when a large number of the links in the area are slow or have high latencies. In these cases the area cannot transmit large amounts of routing information. So it makes sense to summarize everything from outside of the area.
Not all vendors implement Totally Stub areas. This feature originated with Cisco and is not included in any of the RFC documents that define the OSPF standard. Some other vendors have also implemented Totally Stub areas, however. As with all nonstandard options, it should be used with caution. All of the routers in any given area must agree on the type of area. So if some routers are not capable of operating in a particular mode, they may be unable to participate in the area.
NSSA and Stub areas, on the other hand, are implemented by nearly every router vendor.
Route summarization in this discussion is similar to how it was used with EIGRP. In a normal non-Stub area, OSPF distributes routing information on every individual subnet, including those in external regions of the network. A summary reduces this information to a small number of routes that describe large ranges of addresses.
For this to work, it must be possible to reach every valid address in this range through a single Access point. In the case of summary routes for networks outside of the AS, the destination must point to the Autonomous System Boundary Router (ASBR). For summary routes of networks in other areas (or where the ASBR is in another area), every router in the area will simply direct traffic to the Area Border Router (ABR).
Because it is a Classless routing protocol, OSPF uses a system of the longest possible match when looking at summary routes. Suppose a packet has a destination of 10.2.3.5. The router forwarding this packet will look in its routing table to see how to deal with it. It might have a default route of 0.0.0.0, which it will use as a catch-all in case it can't find a better match. It might also have a summary route for 10.0.0.0/8. Again, if it can't find a better match, it will use this one. If there are several possible matches, the router will always use the one with the longest mask, which will be the most specific route. In this example, if there is a route for 10.2.3.4/30, this will be better than any either 10.0.0.0/8 or 0.0.0.0/0.
Note also that the ABR routers summarize in both directions. The routes from outside of the area are summarized when they are distributed into the area. Similarly, the internal area routes are summarized when the ABR presents them to the rest of the network. So if an area has a summary route of 10.1.4.0/22, then it is up to the ABR to distribute this summary information to the neighboring area. If it is summarizing this way, then it does not distribute any of the specific routes for this area.
Just as ASes are defined by numbers, areas also have numeric identifiers. Every AS must have at least one Transit-capable area called area 0.
Areas are sometimes called by a single number, and sometimes by numbers written out in the same format as IP addresses. So Area 0 is sometimes written as 0.0.0.0. It is usually a good idea to have the default route for an AS connected to Area 0.0.0.0. But this has nothing to do with this naming convention. In fact, the numerical identifiers for areas (except for Area 0) are completely arbitrary. Since every area must connect directly to Area 0, and only to Area 0, there need not be any relationship between the names of different areas.
However, it can make administration and troubleshooting simpler if areas have meaningful names. Some organizations make their area names identical to the summary of networks inside the area. So, if an area can be summarized with the route 10.1.16.0/22, then the area might be called 10.1.16.0.
Other organizations choose their area designations to represent administrative information. For example, they might have a group of areas belonging to each of several different divisions of the organization. One of these divisions—Engineering, for example—might be called 5.1.10.0. Then the Engineering OSPF areas would be called 5.1.10.1, 5.1.10.2, and so forth. Meanwhile, the Marketing division might have 10.2.5.1, 10.2.5.2, and so forth.
The numbers are completely arbitrary, so it is up to the network designer to come up with a scheme that is meaningful to the organization.
Every AS must have an Area 0. Every other area in the AS must connect directly to Area 0 and no other area. In other words, every OSPF AS is a star configuration. So OSPF lends itself well to hierarchical network design.
The routers that connect one area to another Area Border Routers (ABR). Every ABR straddles the line between Area 0 and at least one other area. Figure 6-9 shows an example of how this works.
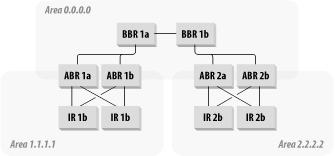
There are three areas in this picture. Area 0.0.0.0 is called the backbone or Core area. There are six routers in this area. Four of these routers are ABRs, and the other two are purely internal. Routers that are purely internal to Area 0 are called backbone routers, so I have named them BBR 1a and BBR 1b.
There are two other areas indicated in this picture, Area 1.1.1.1 and Area 2.2.2.2. Each of these areas connects to the backbone area through a redundant pair of ABR routers. Each area also contains two other routers. Routers in nonbackbone areas that are not ABRs are called Internal Routers (IR). Most of the routers in the network will wind up being IRs.
This figure shows multiple ABRs connecting to each area. This is important because it affects how summarization is done. Suppose Area 1.1.1.1 is a Stub area. Then all of the IR routers inside this area will see two types of routes. Any route that originates inside the AS will be a full route with no summarization. But every route from other ASes will be summarized into a default route such as 172.16.0.0/14 or 0.0.0.0/0.
This summary route will then be distributed by Link State flooding to every router in the area. In the example, both of the internal routers in this area are directly attached to both of the ABRs. So they will see equal-cost multipath routes for these summary routes.
Suppose Area 2.2.2.2 is not a Stub area. Then every router in this area will see all of the full routes originating with every router in the network. They will only see the Link State database for routers in their own area, but they will see routes for everything else.
Figure 6-9 showed two ABR routers for each area. This was done to remove the single point of failure that a single ABR would represent. But it presents a special problem for OSPF to deal with. The two ABR routers must present the same information to the Core. To ensure that they are in synch, it is important to always mesh the ABRs in any one area. The same issues will be even more applicable when talking about ASBRs later in this chapter. This is because ASBRs ensure that summary routes are correct for an entire AS. ABRs only have to summarize an area, but they still need to keep the routing information up-to-date.
In many networks there is an additional reason for meshing the ABRs for any given area. It is common for every IR in an area to have connections to a pair of ABRs. Then if one of these links fails, the second ABR will take over all of the traffic. However, if the ABRs summarize the area routes when passing them to the Core, then the Core does not need to know about this failure inside the area. So, if traffic from the Core to the IR used the ABR with the failed link, the ABR-to-ABR link provides a new path to the IR. Otherwise, every little change in a remote area will cause changes in the routing tables of the backbone. The backbone area should see only routing changes that result from serious problems.
This diagram shows a pair of ABR routers that connect Area 0 to each of the non-Core areas. In fact, if the ABR routers have relatively powerful processors and lots of memory, they act as ABR for a number of non-Core areas.
One could, for example, have a single ABR router with three high-speed interfaces. The first interface connects to Area 0, the second interface connects to Area 1.1.1.1, and the third to Area 2.2.2.2. This router then acts as ABR to both areas. There need be no particular relationship between Area 1.1.1.1 and Area 2.2.2.2 in this case. The point is just to economize on the number of ABR routers required.
There are no theoretical limits on how many areas an ABR can support. But there are relatively strict practical limits imposed by CPU performance and memory capacity. Most modern routers can readily handle two areas plus Area 0. Some powerful devices can be ABR for 4 or 5 areas with relative ease. Ask your hardware vendor for guidance before attempting to support multiple areas through a single ABR router. It may require a memory or CPU upgrade.
So far, the benefits to summarization have concerned efficient use of resources. But summarization has another key benefit. If you don't summarize, then you must propagate every route through the network. In particular, if the ABRs don't summarize into Area 0, then they must propagate every individual route into Area 0. This is usually not a problem, but every time a link changes state, the route flaps—that is, a Link State advertisement is flooded through the area. When this information crosses into another area, such as Area 0, it also has to update the routing tables in this area.
Normally, this is not a problem. But suppose the circuit that connects a number of routers to an ABR is faulty. Every time this circuit goes up and down, the ABR must send out Link State advertisements for all of the routes that have changed state. If it happens too frequently, it can cause stability problems in the network Core. So summarization is not just a resource issue; it is also a stability issue.
I have one final comment on OSPF Area structures. In vendor documentation and even in the OSPF RFC, you frequently read about Virtual Links. These are effectively routing tunnels that allow physically remote routers to become adjacent neighbors. This is sometimes used when a router needs to be in one area, but is physically located in another.
For example, a network might consist of a chain of four areas in a row. The first area is Area 1, the second is Area 0, and the last two are Areas 2 and 3. Area 0 connects Areas 1 and 2 properly, but there is a problem in getting to Area 3. One solution is to configure a virtual link from Area 0 to the router that connects Areas 2 and 3 together. Then this router becomes an ABR for both of these areas.
It should now be clear that needing to use virtual links is a symptom of a bad design. It is far too easy for a virtual link to break and partition an area. When the area that breaks is Area 0, this is disastrous. I strongly caution against using virtual links. They may make otherwise impossible configurations possible, but they will never make a network stable.
Just as with RIP and EIGRP, it is possible to join OSPF Autonomous Systems. This could happen because two otherwise separate networks need to talk to one another. Or it could be that one AS has to be divided into two or more pieces. Routers that connect one AS to another are called Autonomous System Boundary Routers (ASBR).
Technically, an ASBR can be placed in any non-Stub Area or in any NSSA. However, in a hierarchical design it is usually preferable to place the ASBR routers in Area 0. In principle, routers from anywhere in the AS will want to connect to the ASBR and the network beyond it.
However, if the ASBR is in one of the non-Core areas, then traffic from a different area must travel a potentially large distance to get to the ASBR. This tends to be rather inefficient. Also, if there are multiple ASBR routers connecting to several different ASes, all via different areas, then it can be very difficult to know which default 0.0.0.0/0 route is the best one. However, if the ASBR routers are all located in Area 0, it becomes much easier to keep tight control over external routing.
Finally, if the designer is building a hierarchical network design, then it should be hierarchical at all levels, not just within the OSPF AS. So this concept leads to the idea of a central EGP Core that interconnects a number of IGP ASes. In this view the most natural place to connect the OSPF and EGP clouds is in the Core of the OSPF AS, Area 0.
The one important exception to this is using static routes or a foreign routing protocol such as RIP to accommodate network gear that doesn't support OSPF. It is not uncommon to encounter legacy equipment in outlying portions of the network. In this case it is essentially unavoidable: you need to have an ASBR in an area other than Area 0.
It is important to make sure that this area is a Transit Area. It can be either a non-Stub Area or NSSA. The choice between these two options depends mainly on how much other routing information comes from outside of the AS. If the AS has very few external routes, then a non-Stub Area is simpler and therefore preferable. But if there are many external routes, then an NSSA should use router resources more efficiently.
Strictly speaking, since OSPF is an IGP, you should interconnect ASes using an EGP such as BGP. It is possible to use another IGP for this purpose, however. IGRP and RIP actually work relatively well for this purpose. However, it is usually not a good idea to interconnect two ASes running the same IGP without some other protocol in the middle. This is essentially to control the flow of IGP information.
I mentioned previously that it is a bad idea to connect two EIGRP ASes directly. OSPF behaves somewhat better in this regard. But it is still good practice to use a foreign protocol in the middle to help control how routes are distributed between the ASes.
There are two reasons for splitting up an OSPF AS. First, it might have grown so large that it no longer converges quickly after a link failure. This is relatively rare, however. More frequently a designer might want to split up an AS to help isolate regions of instability. Whenever a link fails, the route associated with this link must be updated throughout the AS. If the ABR routers for the area containing the failed link give Area 0 summary rather than detailed routing information, then there is nothing to update. But if every route is listed in detail, then this detailed information must be rigorously updated whenever it changes.
Now consider an AS that contains a mixture of LAN and WAN areas. Suppose that a WAN area contains a Frame Relay cloud with a single circuit supporting hundreds of remote sites. If this circuit fails, the ABR for this area must update Area 0 with all of these individual routing updates. When the circuit comes back up, all of the routes must be updated again.
If this happens frequently, it can make the routers in Area 0 extremely busy recalculating their routing tables. That can result in Area 0 itself becoming unstable. So some network designers like to separate their WAN components into one or more distinct ASes that are separate from the more stable LAN components.
The simplest example of redistributing other routing information into OSPF is the use of static routes. This is effectively the same as redistributing from one AS into another. Every route that does not come from within the AS and is not generated by the standard Link State advertisements is considered an external route and is tagged as such.
When an external route is injected by an ASBR, a cost is associated with it. This need not be a real indication of the number of hops or the speed of links on the outside of the ASBR. In fact, you only need to be careful with the costs of external routes when there are two or more different ASBRs offering connections to the same network. In this case, OSPF adds its own internal costs to each hop through the network.
To reliably control which external path is used in this scenario, all ASBR routers that connect to the external network should be located together in Area 0. Then if one ASBR is preferred, it injects the route with the best cost. If this is not done—for example, if two ASBR routers with the same external routing information are located in different Areas—then predicting which one will be used is difficult. Some routers may use one, and others may use the other ASBR. This may be desired. But it is simpler and easier to maintain if all ASBR routers are located in Area 0.
In fact, OSPF uses two different types of external routes. An arbitrary router inside an AS looking at a Type 1 external route sees a metric equal to the cost for that route at the ASBR, plus the cost required to get to the ASBR. For Type 2 external routes, on the other hand, the internal portion of the cost is ignored.
If there are two ASBR routers injecting the same Type 1 route with the same metric, then each internal router chooses the closer ASBR. But if it is a Type 2 route, then it always picks the same ASBR, regardless of which one is closer. The ASBR it picks will be the one with the best external cost. If the metrics for two Type 2 routes are equal, then the internal distance is used to break the tie.
Where both Type 1 and Type 2 routes exist for a particular network, the internal routers will always select the Type 1 route.
A special case is the injection of an external route that overlaps with address range of the AS. This is generally dangerous. But there are times when a static route must be used because OSPF is not naturally aware of the route. This might happen, for example, if there is foreign equipment in the network that does not run OSPF.
OSPF will always use the most specific route first. So, ven if there is a lower cost route that includes the subnet mentioned in the static route, the specific route will be used. For example, suppose a route to 192.168.5.0/24 is distributed through the normal Link State process. This could be distributed either as a summary route or as a normal route. Suppose there is one particular host, 192.168.5.16/32, that is connected differently, perhaps through a PPP or SLIP connection directly to a router port. Then this router could inject this host route (a host route has a mask of 255.255.255.255) with the appropriate metric for this medium. OSPF would then use this host route properly for this specific device and the network route for everything else in the segment. This should work even if the host route has a higher cost than the network route.
OSPF relies on route summarization to work efficiently. Unlike EIGRP, which allows route summarization at any point, OSPF only summarizes at ABR and ASBR routers. So where EIGRP can benefit from highly sophisticated addressing schemes that summarize on many levels, OSPF can use somewhat simpler IP addressing schemes.
Each AS must be completely summarized by a simple network/mask combination. As mentioned previously, it is always possible to inject external routes that overlap with the internal range. But this should be avoided because it is confusing. If multiple ASes are used, they should all have their own clearly summarized ranges. Then, each area within each AS should be composed strictly of a summarized subgroup from the AS address range.
For example, suppose you have a network with two ASes. The first uses the range 10.1.0.0/16, and the second uses 10.2.0.0/16. This will make it easy for the ASBR routers to summarize the links that connect them. Then the areas within the first AS may have address ranges that look like 10.1.0.0/22, 10.1.4.0/22, 10.1.8.0/21, 10.1.16.0/21, and so forth. Note that these ranges are not all the same size. There is no reason to restrict areas to summarize the same way as one another.
If you fail to create clearly summarized address ranges at the ASBR and ABR boundaries, OSPF has to work much harder than it would otherwise. This is extremely inefficient. It is also very difficult for human engineers to diagnose problems when there is no simple and clear pattern to the IP addresses.
Earlier in this chapter I indicated that the OSPF cost values are arbitrary. They are used to select the best paths through a network. So, in general, faster links will be configured to have lower costs. In fact, if you assume the same latency for every type of link (which is not true in reality), then you can define the cost to be inversely proportional to the bandwidth.
This leads to one of the most popular methods for setting OSPF costs. You can take a reference bandwidth as the fastest link in the network and make its cost 1. Then every slower link has a cost that is just the reference bandwidth divided by the slower link's bandwidth. If your reference bandwidth is a Gigabit Ethernet link in the network's Core, then every Fast Ethernet (100Mbps) link will have a cost of 10, 10Mbps Ethernet links will have 100, and a T1 (1.544Mbps) will cost 6476.
This is a relatively good system, but it has one critical flaw that makes it unworkable in many networks. The maximum value for an OSPF cost is 65,535. In fact, it is important to avoid coming anywhere close to this value because a path that includes such a link plus any number of faster links could easily have a total cost greater than the maximum. When this happens the entire path becomes unusable. This is effectively the same problem as when a RIP metric exceeds 15.
The problem is that many networks include too large a range of bandwidths. Suppose, for example, that the fastest link in the network is a Gigabit Ethernet link, and the slowest is a 9.6kbps dialup line. If the Gigabit link has a cost of 1, this implies that the 9.6kbps line must have a cost of 104,166, which is considerably larger than 65,535. This problem becomes worse in a network with a 10Gbps link in its Core, because then even relatively common 56kbps circuits have excessively high costs.
Let's revisit the reasoning behind this standard linear rule to adapt it to these real networks. The range of bandwidths available forces many network designers to use a non-linear rule. Certainly, the faster links must have lower costs than slower ones. But do links that are one-tenth as fast really need to bear a cost that is 10 times as high? This would make the net cost of a path passing through nine Fast Ethernet links better than the cost of a single 10Mbps Ethernet link. Is this realistic?
The main problem is what nonlinear method to use to include the bandwidth factor. What it really comes down to is deciding how many hops through high-speed links equals one slow hop.
Clearly, an important factor is the latency of each of these links. The latency for a short 10Mbps Ethernet is roughly governed by the length of time required to wait for carrier and inject the packet. Time of flight to the farthest part of the segment is less than the time to transmit the entire packet (or else the segment will suffer from late-collision problems). The same is true for 100Mbps Ethernet, but because the carrier frequency for 100Mbps Ethernet is 10 times as fast, the latency should be roughly one-tenth as long.
Adding more hops to the path also increases the latency because each router in the path takes some time to process the packets. In the case of Ethernet and Fast Ethernet, the amount of work is almost exactly the same. So assume that each router adds roughly the same additional latency as a Fast Ethernet segment does. Then passing through N Fast Ethernet hops will add N link delays plus N-1 router delays, for a total of 2N-1. This implies that the break-even point based on latency alone will be when 2N-1 = 10, or N = 5.
Now consider how the bandwidth should scale neglecting latency effects. Nominally, if a link is 10 times as fast, then an application can send 10 times as much data through it. But this assumes that this application is the only one using this link. In fact, the faster links usually aggregate traffic from a number of slower links. The amount of competition for the bandwidth on some remote link depends on the network design and traffic patterns. Generally speaking, these links have some constant utilization for which many devices compete, plus excess capacity that they can use fairly freely.
Putting these factors together suggests a simple formula with the cost inversely proportional to the square root of the nominal bandwidth. Note that a great deal of hand waving went into finding an appropriate formula. It is balanced so that a Fast Ethernet link is roughly three times as good as a 10Mbps Ethernet link. Similarly, Gigabit Ethernet links are roughly three times as good as Fast Ethernet. This simple rule scales the same way throughout the entire range. Best of all, it results in usable cost numbers for the slowest links in a network, as shown in Table 6-4.
|
Medium |
Nominal bandwidth |
Cost in 1/bandwidth model |
Cost in 1/square root model |
|---|---|---|---|
|
9.6kbps line |
9.6kbps |
1,041,666[1] |
1020 |
|
56kbps line |
56kbps |
178,571[1] |
422 |
|
64kbps line |
64kbps |
156,250[1] |
395 |
|
T1 Circuit |
1.544Mbps |
6,476 |
80 |
|
E1 Circuit |
2.048Mbps |
4,882 |
69 |
|
T3 Circuit |
45Mbps |
222 |
14 |
|
Ethernet |
10Mbps |
1,000 |
31 |
|
Fast Ethernet |
100Mbps |
100 |
10 |
|
Gigabit Ethernet |
1Gbps |
10 |
3 |
|
10 Gigabit Ethernet |
10Gbps |
1 |
1 |
|
4Mbps Token Ring |
4Mbps |
2,500 |
50 |
|
16Mbps Token Ring |
16Mbps |
625 |
25 |
[1] These costs are all higher than the maximum cost value of 65,535, and they would be adjusted in practice.
Table 6-4 also includes the costs that result from using the more common model in which cost is inversely proportional to bandwidth. In both cases I adjusted the costs so that the fastest link, the 10Gigabit Ethernet, has a cost of 1.
Both of these models are just basic suggestions for starting points. The network designer should carefully consider the OSPF costs of every link in the network to ensure that they are appropriate. Poor choices of values can lead to serious traffic routing problems. But, as with all network design problems, simple consistent rules will usually result in a more stable network.
It is particularly important to include room for growth. If there is even a remote chance that your network will one day include Core links that are faster than the 10 Gigabit Ethernet speed suggested in this table, make sure to scale all of the cost values up accordingly. Then the new fastest link will have a cost of 1, and all of the other links will be correspondingly more expensive. Making this change after a network is built can be time consuming and highly disruptive.
There is an interesting exception to the preceding comments. OSPF areas are configured so that only Area 0 carries traffic from one area to another. If a packet starts in any area besides Area 0 and then leaves that area, then it cannot return to the area in which it started. If it then passes into another area, then it must have its ultimate destination in that area. So the problem of selecting the best path breaks up into components. First, OSPF needs to find the best path through the originating area. If the destination is in the same area, then it needs the best path to the destination. But if the destination is in some other area, then all it cares about is finding the best path to Area 0.
Once the packet is in Area, 0 OSPF needs to find the best path within this area. It may terminate in Area 0, or it may lead to an ABR for another area. Finally, in the destination area it needs to find the best path to the final device. But the point is that the protocol does not need to know the entire path from end to end unless the path is contained entirely in one area. It just needs the best path to the next ABR.
Consequently, it doesn't matter if you use different costing rules in different areas. For example, Area 0, being the Core of the network, might contain several 10 Gigabit Ethernet links. But it is unlikely that this area will contain anything slower than a T1 circuit. So you can use one set of costs appropriate to this range of bandwidths. Similarly, a destination area might contain a number of remote WAN sites connected via 56kbps circuits. But as long as the fastest links in this area are 100Mbps Fast Ethernet, you can use a consistent set of costs based on 100Mbps bandwidth. However, as with all aspects of network design, it is preferable to have a single common rule that applies everywhere. So this exception is best used only as an interim measure while readjusting metrics throughout an AS.