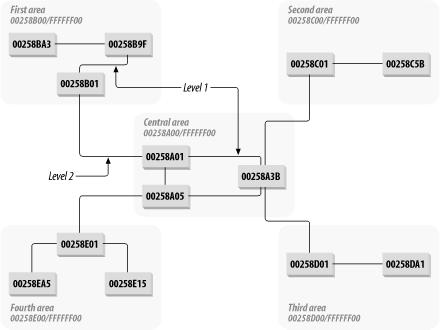
Figure 7-1. A hierarchical NLSP network design
IPX has dynamic routing protocols that are in many ways similar to those that I already discussed for IP. They fall into the same general categories of Distance Vector and Link State protocols, and they apply many of the same loop-avoidance mechanisms. The basic goals are the same—to find the best multihop path to a particular destination automatically, to converge quickly after topology changes, and to eliminate loops.
The services or applications that any particular server has to offer are described by Service Advertisement Protocol (SAP) packets that are sent around the network. End-user workstations receive these SAP broadcast packets and use them to build a list of all available services on the network.
Running parallel to these Service Advertisements is a routing protocol called Routing Information Protocol (RIP). IPX RIP shares several similarities to IP RIP. Both are Distance Vector algorithms. However, while IPX RIP keeps track of the number of hops to a destination, it doesn't use the information in exactly the same way as IP RIP. Both protocols use the hop count metric to avoid loops. In the case of IPX RIP, the actual routing decisions are made according to which route has a shorter time delay to reach the destination.
Time delay is measured in ticks. The length of a tick is selected so that there are 65,535 ticks in an hour (65,535 is the largest number that can be expressed in 16 bits). Thus, there are roughly 18.2 ticks in a second, each one being about 55 milliseconds long. RIP makes its routing decisions based on this time delay and uses the hop count only as a "tie breaker" when two paths have the same net time delay.
RIP routing updates are made on a schedule. Each RIP packet can contain up to 50 routing table entries, and each device attempts to pass its entire routing table along to all of its neighbors. The exception to this situation is the fact that IPX RIP employs a Split Horizon algorithm that does not pass routing information back to the device from which it was originally learned. At each successive hop, the devices increment the hop counts indicated in the received routing table. They also add to the time delay a new delay that is measured by the network-interface card.
The SAP protocol carries information about what devices support what application services. This information does not change as frequently as routing information. Generally, if a server is available, then all of the services it offers are also available. Thus, SAP generally works as a query and response.
When a new workstation appears on a network, it sends out a general query looking for information about what servers are available on the network and what services they support. When a new server appears on the network, its neighbors ask it what services are available on the network. When a server stops responding to queries, its services are eventually flushed from the SAP tables of other devices on the network.
Since NetWare is intended to operate across large network environments, a user on a remote LAN segment must be able to get information about the services supported by central servers in the computer room. To make this possible, SAP information is relayed around the entire network from router to router. In this way, every device is able to see a list of available services anywhere in the network.
This SAP information includes some routing information. It is not sufficient to say only that a server named ACCOUNTING supports a database application. The network has to know where that ACCOUNTING server is. However, although these SAP packets include routing information, this information is not used to route the packets. The information used to route packets comes from RIP. Therefore, one of the most confusing problems in an IPX network comes when the RIP and SAP information is inconsistent.
This is particularly true when filtering either RIP or SAP. This filtering is often done to control the size of the routing and service tables on routers and servers. Also, because RIP periodically updates all of its neighbors with its entire routing table, network engineers often want to filter RIP to control bandwidth. Later in this chapter, I explain why too much SAP on a large network is a potentially greater problem. Thus, SAP filtering is usually more restrictive than RIP filtering.
Unless properly controlled, RIP and SAP traffic can cause serious congestion problems, particularly on low-speed WAN links. RIP and SAP, however, are distinct protocols, so they must be filtered separately.
It is not uncommon to wind up with inconsistent filters. Then the network can get into a situation in which an end-user workstation sees that a server called ACCOUNTING offers a database service, but cannot reach that server. Conversely, if the RIP but not the SAP is present, then the user will not even see this service, but might connect to other services on the same LAN segment, or even the same server. This is one of the most common network problems on a large IPX network.
An up-to-date list of registered Novell SAP numbers can be found online at http://www.iana.org/assignments/novell-sap-numbers/.
Cisco's EIGRP protocol is capable of supporting IPX, as well as IP (it also can distribute AppleTalk routing information). EIGRP distributes both route and service information. That is, it replaces both RIP and SAP. If a network uses EIGRP, it is important to disable IPX RIP and SAP on all router-to-router links.
However, on the router-to-server links, RIP and SAP must be enabled. Because RIP and EIGRP calculate metrics differently, routing tables can become terribly confused if both protocols are present between two adjacent routers. Always take care to disable or filter out the one that is not in use.
EIGRP can provide several important efficiencies over standard RIP and SAP. First, it supports a much larger network radius. A RIP network can have at most 15 hops between any two networks. This is for exactly the same reason that the IP RIP maximum size is 15 hops. The maximum size of an EIGRP network depends on the architecture. Usually one encounters problems due to too many devices before exhausting the theoretical maximum number of hops.
IPX EIGRP works essentially the same way as IP EIGRP. The main conceptual difference is that IPX EIGRP must carry SAP information, as well as routing information. Again, these updates are performed separately and can be filtered separately. Thus, the network actually still has the same potential problems with route and SAP information being inconsistent. This situation is almost impossible to avoid.
The chief advantage of using EIGRP over RIP and SAP is its bandwidth economy. EIGRP only distributes changes to its tables, rather than sending the entire table periodically. If there are no updates, then neighboring routers only exchange HELLO packets. Conversely, RIP and SAP must periodically distribute their entire tables to ensure consistency.
Another potential advantage of using EIGRP is the availability of equal-cost multipath routing. This routing represents a significant advantage in IP networks. However, I usually try to vary routing costs so that one path is absolutely preferred in IPX. This is because some IPX applications do a poor job of recovering when packets are delivered out of order.
In general, when one has equal-cost multipath routing, the routers distribute the packets among all possible paths. This means that two successive packets will take different paths through the network. It is possible that they will arrive in inverted order. For a well-behaved application this rarely presents a problem. But some IPX applications do not cope well with packet-sequence errors.
It should be noted that some IP applications also suffer from this malady, but the IP world has had equal-cost multipath routing for a long time. Consequently, natural selection has eliminated most of these unfit applications. However, in the IPX universe, equal-cost multipath routing has been introduced relatively recently. Therefore, many legacy IPX applications behave poorly in this environment.
Novell also has created a more efficient routing protocol to overcome some deficiencies of RIP and SAP. This protocol, called Novell Link State Protocol (NLSP), is derived from the OSI Intermediate System to Intermediate System protocol (IS-IS). IS-IS is not discussed in this book, but NLSP shares many similarities with OSPF, so I discuss it by analogy with OSPF.
As a replacement for RIP, NLSP carries all of the routing information for an IPX network. As a replacement for SAP, it also carries service advertisements. However, NLSP does not completely replace RIP and SAP. End stations still require these protocols to find their servers.
The usual mode of operation for NLSP is to run RIP and SAP on the local segments. Then the servers on these local segments speak NLSP back to the router (or routers) that provide network connectivity to this segment. Router-to-router communication then uses NLSP for the main infrastructure of the network.
NLSP works best when all servers and routers in the IPX network use NLSP and only the end station-to-server communication uses RIP and SAP.
Like OSPF, NLSP is organized hierarchically into an Autonomous System (AS) that holds several areas. Each AS has an associated NLSP System ID number that is common throughout the network. Areas in NLSP serve the same functions as they do in OSPF. They allow network address summarization, which in turn results in efficient routing. They allow the Link State database to be broken up.
All routers and servers in any particular NLSP area share a common Link State database that is updated by flooding incremental changes, exactly as in OSPF. However, like OSPF, routers and servers in one area do not see the Link State information for routers and servers in a different area.
NLSP areas are defined according to the IPX summary addresses for the enclosed networks. To use NLSP effectively, it is important to use areas for exactly the same reasons as in OSPF. As in OSPF, effective summarization is important for areas to work properly. However, unlike OSPF, areas do not function at all if the enclosed networks cannot be summarized.
An NLSP area is specified by an IPX network and mask that together summarize all IPX network addresses in the area. For example, one could specify an area with the address 00258A00 and mask FFFFFF00. Then this area would include the networks 00258A00, 00258A01, and so forth up to 00258AFF.
As with IP address masks, you can use masks that break the range at any bit. So another valid area could be 030AC000 with a mask of FFFFE000. In this case, the range included in this area is 030AC000 to 030AC1FF. Writing these pairs out in binary, as in Table 7-1, helps to show how they work.
|
Address / Mask |
||||
|---|---|---|---|---|
|
Hx |
00258A00 / FFFFFF00 |
|||
|
Binary network |
00000000 (00) |
00100101 (25) |
10001010 (8A) |
00000000 (00) |
|
Binary mask |
11111111 (FF) |
11111111 (FF) |
11111111 (FF) |
00000000 (00) |
|
Allowed range |
00000000 (00) only |
0010101 (25) only |
10001010 (8A) only |
00000000 to 11111111 (00) to (FF) |
|
Hex |
030AC000 / FFFFE000 |
|||
|
Binary network |
00000011 (03) |
00001010 (0A) |
11000000 (C0) |
00000000 (00) |
|
Binary mask |
11111111 (FF) |
11111111 (FF) |
11111110 (FE) |
00000000 (00) |
|
Allowed range |
00000011 (03) only |
00001010 (0A) only |
11000000 and 11000001 (C0) and (C1) |
00000000 to 11111111 (00) to (FF) |
This summarization property of areas has important design implications. It means that designers must be extremely careful about how they allocate their IPX network numbers. Most IPX networks that were initially implemented with RIP never had any requirement for this sort of summarization. Consequently, for many organizations, the conversion from RIP and SAP to NLSP requires that all servers be readdressed.
The language of NLSP diverges somewhat from OSPF. NLSP defines three different levels of routing. Level 1 routing occurs within an area, Level 2 routing occurs between areas, and Level 3 routing occurs between ASes.
OSPF requires that an Area 0 must sit at the center of the AS. Then all other areas are connected to this area directly by means of Area Border Routers. NLSP does not have this restriction. It is possible to construct NLSP areas in somewhat arbitrary configurations, with Level 2 routing taking place between them. However, the OSPF architectural model is good and should be followed in NLSP as well.
It might seem tempting to designate the central area with a network number and mask pair of 00000000 and 00000000 by analogy with OSPF's Area 0. In this way, the central area would effectively include all possible IPX network numbers. But including these numbers is not a good idea because it implies that the central area actually encloses all other areas, which is not possible. The central area is just another area, similar to all of the others. It contains a group of routers and servers that communicate using Level 1 routing. It also communicates to the other areas using Level 2 routing. Thus, the central area must have a summary address of its own that is distinct from every other area.
Figure 7-1 shows how one might use NLSP to build a hierarchical network. Note that in this picture only one connection exists between each "leaf" area and the central area. This arrangement is only to make the picture easier to read. As with OSPF, these key links should always be made redundant. In fact, NLSP supports an equal-cost multipath mode just as OSPF does. The same basic design principles for redundancy apply to both.
In an IPX network of any size, it is important to limit the number of entries in the Service Advertisement table. This limitation is not merely for bandwidth reasons. Using NLSP or EIGRP makes it possible to drastically reduce the bandwidth taken to distribute this information.
The problem with a large IPX network is simply the size of the table. It is not uncommon for a large IPX network with hundreds of servers to have thousands or tens of thousands of advertised services. This is because every network-attached printer must send a SAP. Similarly, every Windows NT workstation running IPX sends out at least one SAP by default unless SAP is disabled, and every server generally runs several services besides simple file sharing, remote console, and directory services.
The table size for large networks adds up to a huge amount of information that must be distributed to every IPX router and server in the network. Each one of these devices is responsible for redistributing this information to every device downstream from it. In many cases, it represents more information than the routers can reliably handle. They start to run out of memory, and, worse, they start to run out of the CPU power required to process the data.
The vast majority of these advertised services originate with end devices such as workstations and printers. They are not required anywhere but in their originating segment. Thus, it is critically important for network stability that the routers must filter out all nonessential SAP information and prevent it from crossing the network.
The most appropriate place to do this filtering is usually on the router that connects the LAN Access segment to the network Distribution Level. Since a good network avoids using servers of any type as routers—preferring real routers—filtering on the servers isn't necessary. Rather, it all must be done on the routers.