Figure 7-2. IPX network design with RIP and SAP accumulation zone
There are a few basic design strategies that can make an IPX network more efficient and reliable. Some of these strategies, like special addressing schemes, are analogous to good design principles that I have already discussed for IP networks. Others, such as those having to do with minimizing SAP traffic, are specific to IPX.
As discussed earlier in the section on NLSP, IPX route summarization can present a problem for many networks. However, there is a relatively tidy solution to this problem for networks that run IP and IPX in parallel. If the IP network runs OSPF and the IP addressing scheme has been properly constructed to allow area route summarization, then it is possible to derive IPX addresses from IP addresses.
You can derive these addresses easily. IP and IPX addresses contain the same number of bytes, and they both summarize from the left. Thus, you can do a decimal-to-hexadecimal conversion of the IP address to get the IPX network number.
For example, if the IP address of a file server is 10.1.21.15, then you can convert the four bytes to hexadecimal notation as 0A01150F. This is the address of the file server itself, so you can use this address for the IPX Internal Network Number. The External Network Number is effectively the address of the LAN segment.
In this case, the subnet's address is 10.1.21.0, so the IPX External Network Number would be 0A011500. If there was a second file server on this segment with an IP address of 10.1.21.16, then its IPX Internal Network Number would simply be 0A011510, and it would have the same External Network Number as the first server.
Now, if you have built your OSPF areas properly, you should be able to summarize all addresses inside of an area. If the area containing this example server's LAN is summarized as 10.1.0.0/16, then the NLSP area will become 0A010000 with a mask of FFFF0000. Everything maps perfectly between the two protocols if you choose to number your servers in this way.
If the IPX network does not use NLSP, then there are essentially no restrictions on how the IPX network numbers are allocated. In many networks, IPX network numbers are also randomly distributed throughout the network.
This random distribution is a poor strategy, however. It makes sense to use IPX network numbers that correspond to IP addresses for several reasons. First, most modern networks using IPX also use IP, so there is a natural convergence between the two. Second, if one day the network is converted to NLSP, there is no need to readdress every device. Third, if a simple rule gives the correlation between the IP and IPX addresses, then troubleshooting is much simpler.
This last point deserves extra comment. It is relatively common to build IPX networks that also run IP, so it is natural to bind the IP protocol to an interface on the server. When troubleshooting network problems, it is often useful to send test packets to see whether point A can reach server B.
However, IPX does not have a universally standard equivalent to the IP PING utility. IPX PING does exist, but there are several different standards, and they do not work together. Furthermore, for a server to respond to an IPX PING request, it must have the appropriate NetWare Loadable Module (NLM) loaded. Therefore, there are many reasons why an IPX PING test might not work, even though nothing is wrong with the network.
However, all IP devices should support ICMP ping (firewalls are a notable exception to this rule). If a network administrator is concerned about network connectivity between two segments, using an IP ping test can be useful, even though this is a different protocol. If an IP ping works, but there is no IPX connectivity, then the administrator can focus on IPX issues immediately. If neither work, then it is more likely that the problem is with physical connectivity.
Networks should always be designed as easy to manage, and troubleshooting is an important part of management. Anything you can do to make troubleshooting easier will give you a more reliable network in the long run.
In a large IPX network the routers are likely to have to employ significant amounts of route and SAP filtering. This filtering works in two directions. From the edges of the network into the Core, the network should prevent unnecessary SAP information from causing bandwidth or memory problems. From the Core out to the edges, it should distribute only the required routes and SAPs.
In most cases, it is not necessary for users in one department to see the local server for another department. They both may require access to a central server that handles global authentication, however.
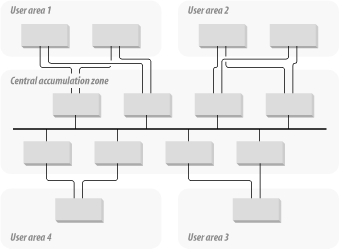
To handle this situation, a designer can create a RIP and SAP Accumulation Zone somewhere in the Core of the network. An example of this configuration is shown in Figure 7-2. This figure shows four different user area groups. These groups may be NLSP areas, or there may be some other functional organization. Routers in each user area have redundant connections to a pair of Core routers. These connections provide extra fault tolerance.
The user-area routers distribute RIP and SAP information inward to this redundant pair of routers. In the center of the picture is an Ethernet segment that I call the Accumulation Zone. Each router that is connected to this Accumulation Zone shares all of the RIP and SAP information that it receives with this segment. Note that this information need not be collected using either the RIP or SAP protocols. This model works equally well for any dynamic routing protocol.
Then RIP and SAP information is distributed back out to the user areas by the Accumulation Zone routers. Note that none of these routers actually needs to have the entire route or SAP tables. Rather, they can all just dump their tables onto this central segment for others to use as required. They can also take in only those routes and SAPs that they themselves require.
The advantage to this approach is that a central point in the network has all the RIP and SAP information that anybody could ever need. At the same time, though, keeping track of this information doesn't overwhelm any device.
Suppose there is a sudden requirement for a user in one user area to have access to a particular server in another area. Then you can simply allow its Accumulation Zone routers to receive and distribute this information to that user's own server. This provides maximum flexibility to managing the IPX network. At the same time, it avoids the most serious problems with having to support a large route or SAP table.
I conclude this section with a brief discussion of other basic things you can do to improve efficiency in an IPX network.
I already mentioned the need to keep the number of SAPs to a bare minimum. This information can be gathered in an Accumulation Zone, as mentioned earlier. However, in a large IPX network, it can easily overwhelm the memory and bandwidth resources of the network devices to maintain all of it. Thus, the first thing to do is to create a thorough list of filters to restrict what routes and services are advertised.
Another aspect of the same issue is limiting the amount of server-to-server traffic. Usually this sort of traffic is not necessary. You often need to allow communication between user-area servers and central servers. However, you should try to keep this traffic flow in a star format as much as possible.
Finally, in any large IPX network, it is critical to avoid using RIP and SAP protocols. These protocols work well in small- to medium-sized networks. But remember that routers and servers must all take part in the routing protocols. Suppose, for example, that two servers communicate via RIP, but are separated by three routers. Then the internal network numbers of these servers are, in fact, five hops apart, so an IPX network is usually somewhat larger than it appears on the surface.
In even a moderate-sized network, it is not difficult to find distances that are greater than 15 hops, which is too large for RIP to handle. As I already mentioned, RIP and SAP scale rather poorly for bandwidth usage. It is a good idea to try to move away from these protocols in any large-scale IPX network.
It is possible to make an IPX network appear smaller than it is, however, by tunneling the IPX traffic inside of IP. For example, suppose that getting from a user-area router to the central Accumulation Zone requires several router-to-router hops. You can make it require a single hop by configuring an IPX tunnel between the Accumulation Zone router and the last user-area router before the server.
Even in this case, however, you should avoid using RIP and SAP. Although this design avoids the hop-count problem, you still have to be concerned about the bandwidth-usage problem with these protocols.