Figure 9-1. Managing a LAN-extension network
A number of design decisions can make network management more difficult. This doesn't necessarily mean that you should avoid these features, but it does mean that you need to be aware of their implications. It usually also means that you need to devise ways of working around the management problems that you create.
For example, sometimes parts of the network are hidden from a protocol, as in a tunnel, for example. If an IP tunnel passes through a number of devices, then it becomes impossible to see the intermediate devices in-band. If there is a problem in an intermediate device, and if there is no external way to observe that device, then it is impossible to tell which intermediate device has a problem, much less what the problem is.
In the example of tunnel-hiding intermediate devices, the most obvious workaround is to provide out-of-band access. This may mean something as simple as IP addressing in a different range. Or, it may require something as complex as putting modems on serial ports for the inaccessible devices.
Besides architectural features, certain network applications and protocols can create management problems. Again, I don't necessarily advise avoiding them, but the designer should be aware of the problems and provide alternatives.
Dynamic Host Configuration Protocol (DHCP) is a system that allows end devices to learn network information automatically. In its minimal form, DHCP allows end devices to acquire IP addresses dynamically, while learning the correct netmask and default gateway. However, other important pieces of network information can also be conveyed by DHCP. For example, DHCP can tell the end device about its time zone, as well as the addresses for time servers (NTP), name servers (DNS), log servers, printers, and cookie servers. It can specify various network parameters such as timer values and MTU values. Literally dozens of different kinds of information can be conveyed by DHCP. It even has some open fields that convey special vendor-specific application parameters. For all of these reasons, DHCP can greatly assist in the management of end devices. The device can be set up anywhere in the network, and it will automatically discover the correct DHCP server and learn everything it needs to know to use the network.
One problem with DHCP, however, comes from its ability to assign addresses out of a pool. The first device to be turned on in the morning gets the first address, the second device gets the second address, and so on. This is by no means the only way to configure a DHCP server. It can also be set up to look for the end device's MAC address and give out a unique predetermined set of parameters that will always be associated with this device. But a simple dynamic assignment from a pool of addresses is frequently used because it is easy to implement. The problem with doing this is that there is often no easy way to determine which device has a particular IP address. This situation can be corrected by linking the DHCP server to the DNS server. When the DHCP server gives out a particular IP address, it informs the DNS server to which device it assigned this address. Then there is a simple association between the device's name and address.
However, even with a linking between DNS and DHCP, it can be difficult to do some types of fault isolation when IP addresses are assigned from a dynamic pool. In particular, when looking at historical records correlating IP addresses with actual devices can be difficult. This correlation becomes a problem when, for example, a server records in its logs that it has had network problems associated with a particular IP address. It can be extremely difficult to reconstruct which actual device this was. The only solution is to ensure that the DHCP server keeps a reliable record of historical data. It must be possible to determine which end device had a particular IP address at a particular point in time. This data has to be reliable at least as far back in history as any other logging information.
When DHCP is configured to give addresses from a pool as they are required, it often creates confusion on network-management servers, even if there is a good link between DNS and DHCP systems. These servers tend to maintain large databases of every device in the network. This information is usually discovered automatically by periodically polling ranges of IP addresses. If a particular IP address is associated with a particular DNS name when the device is discovered, the network-management software records that association permanently in its database. Then, at some later time, it may record an error associated with that IP address. However, it will often report this error as being associated with the previous DNS name, which is no longer accurate.
Some network-management software provides methods to work around this problem. It is possible simply to provide a mechanism to look up the names dynamically each time they are required, for example. However, remember that this is not usually the default configuration and that there is potential for confusion.
This first problem can be mitigated somewhat by setting the DHCP lease time to be extremely long. This setting allows each device to receive the same IP address each time it reboots. If the lease time is sufficiently long, the addresses become effectively static.
Another problem with using DHCP is its actual operation in a large network. In many networks, it is common practice to tie a particular end device's configuration information to its MAC address. This method is useful, but it means that this information must be maintained carefully. If the Network Interface Card (NIC) in the end device is changed because of a hardware problem, then the DHCP database must be updated. Similarly, if this end device is moved to another location, the DHCP database has to reflect this new information as well.
These situations are not really problems, but rather facts of life in this sort of implementation. However, they do represent a significant amount of work that is required each time maintenance work is done on an end device.
Some types of architecture can result in network-management challenges. By architectural problems I do not necessarily mean that these architectural features are bad. In fact, some of these features, such as firewalls and VLAN trunks, are extremely useful. We would not want to do without them. When we use them, though, we have to ensure that there are ways around the management difficulties. This section discusses some of these problems and suggests some solutions.
Most modern LANs use VLANs and trunks. There are too many advantages to these features to avoid them. However, you should be careful about how you monitor trunks. A trunk link that contains many different VLANs treats all of these VLANs as a single stream of traffic. Consequently, if there is a physical failure, it takes out everything. However, there are two basic ways to implement the Spanning Tree protocol in a VLAN trunk. In the most common configuration, the whole trunk is replaced by a redundant trunk in case of a failure. But some vendors have features that allow Spanning Tree to operate on each VLAN separately. The principal advantage to this approach is that the backup link is configured to take some of the load during normal operation. However, determining which VLANs are using which trunks can be very difficult. Thus, if a problem involves a few VLANs is discovered, it might take a long time to determine that all affected VLANs happen to traverse the same trunk at one point in the network.
Conversely, the design could employ a system in which each trunk has a backup that is unused except when the primary fails. In this case there is the danger of suffering a secondary trunk failure and not noticing the failure because it has not affected any production traffic.
The best way around both of these problems is simply to provide the network-management system with a detailed view of the VLAN and trunk status for every switch. Furthermore, since most problems that occur will be physical problems of some sort, it is important to maintain physical monitoring of all trunk ports on the switch. This monitoring is particularly critical for trunk backup ports because they do not pass traffic. Thus, you have to rely on the switch to tell you when there is a problem.
For all higher-layer problems, it is useful to have protocol analyzers available to monitor the flow of traffic through the trunks. These devices are usually too expensive to deploy on every trunk. It is often possible to set up a system to allow probes to be patched manually into the required location quickly.
In general, there are several issues to consider when managing VLAN structures. Some hardware vendors provide useful software that allow the manipulation and configuration of VLANs. Individual ports can be readily moved from one VLAN to another. This movement is useful, but configuration management is only part of what the network managers need to do. They also need to do fault and performance management on all switches and trunks.
This management requires a system that allows you to readily determine where a given end device MAC address is connected. If you look in the MAC address tables of the switches, every switch that supports the right VLAN knows about the device. But if you have to locate it by following trunks from one switch to the next, it can be extremely time consuming. Some software can make this easy, but it shouldn't be asssumed.
There also needs to be a method for monitoring trunk traffic. This means both the gross trunk utilization and the per-VLAN portions of that overall utilization. The total trunk utilization is important because it indicates when it is time to upgrade the trunks. It also shows where trunk congestion occurs in the network. The network manager also needs to know exactly how much of each trunk's capacity is consumed by each VLAN. Knowing this shows which groups of users are actually causing the congestion problems. Then you can decide if, for example, they should be moved onto a new trunk of their own to prevent their traffic from interfering with other user groups.
This per-VLAN utilization is somewhat harder to determine. A good protocol analyzer can do it, and some switches include sufficiently powerful probes to do this sort of analysis.
LAN extension is a general term for providing a Layer 2 LAN protocol over a larger distance. This provision might be handled with dark fiber and a few transceivers and repeaters. Or, it could be implemented using a LAN bridge through some wide-area technology such as an ATM network.
The reason why LAN extension represents a management problem is that the actual inner workings are usually hidden from view. For example, one particularly common implementation of a LAN extension is to use RFC 1483 bridging. This simple protocol allows encapsulation of all Layer 2 information in ATM. The customer of this sort of service sees only a LAN port on either end of an ATM PVC link, which makes it possible to deliver what looks like a Fast Ethernet connection between two different cities, for example. The problem is that there is no easy way to determine if a problem exists in this link. All internal workings of the ATM network are hidden from view. All the customer's network-management software can see is an Ethernet port on either end of the link.
Ethernet link always remains up because the Ethernet signaling is provided by a port on an ATM/Ethernet switch that is physically located on the customer premises. Thus, there is no way to receive a physical indication of a failure.
The only way to work around this management problem is to configure the network management software to poll through the LAN extension links periodically. Doing this configuration requires a detailed understanding of the PVC structure within the ATM network.
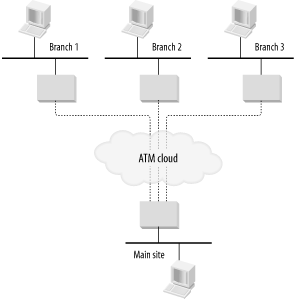
Figure 9-1 shows an example ATM LAN-extension configuration. In this example, one central site talks to each of three different branch sites. To the device shown in the main site, all three remote devices appear to be simply on the same Ethernet segment.
Now suppose that you suffer a failure in the ATM cloud that knocks out the PVC to Branch 1. The other two devices look fine, but you have lost contact with the first device. Most critically for network management, however, the server has not received a trap of any kind for this failure. In fact, it is almost impossible to issue a trap on this sort of failure. The only way to verify that the link is still available is to continuously poll through that link to the other side. This polling can be either SNMP or ping. Of course, even with this sort of active polling through the links, the only indication of trouble is a complete loss of the remote site. Many things could cause such a failure; power or cabling problems within the remote site can cause the same symptoms.
The best you can do is to detect that there has been some sort of problem. More troubleshooting is needed before you can conclude that there was a PVC failure in the ATM cloud.
Another common feature in networks—one that I have advocated earlier in this book—is filtering. You can filter traffic, or you can filter routing information. In IPX, you can also filter SAP information.
Filtering represents serious potential problems for network management. In particular, if there are traffic filters, you should be sure that the network-management traffic is still allowed to pass.
There are cases in which stringent filters have been implemented for security reasons. For example, an application vendor might need to place a semitrusted server on the inside of a customer network to deliver the service. The customer might react to this situation by placing the server behind a router with strict filtering to allow only the desired application to pass through. The problem is that, at some point, there will be a problem and somebody will need to troubleshoot. If the router filters out all traffic except application traffic and the application is not working, then the network engineer is left with no way of testing. Is the server hung? Is the application broken? Or, is there perhaps a problem with its network connection? There has to be a way to verify network connectivity to the server, and this usually means ping.
For this reason, wherever traffic filters are employed, simple ICMP (ping) packets should be permitted along with the application. This way, the network-management system can at least determine if there is basic connectivity. What you lose in security, you more than make up for in the reliability that comes from swift problem analysis.
In IPX networks, SAP information is frequently filtered separately from route information. This filtering can cause a relatively common problem. It is possible for the route and SAP filters to be different in a subtle way. Either the SAP or the route is visible, but not both. When both are not visible, the network-management staff must be able to track the flow of routing and SAP information through the network. Remember to follow the whole round trip. SAP information flows from the server out to the end devices. If the end device can see the server in its server list, then the SAP must have arrived safely. There is generally no need in general for workstations to send SAP information back to the server.
Then you have to follow the routing information. Routes must exist on the workstation end that points to the server; routes must exist on the server end that point to the workstation.
The most extreme form of filtering is a firewall. A firewall is always called for in any location where devices on one network must communicate with devices on another untrusted network. In general, no routing information flows through firewalls. They are usually configured only with static routes. If any dynamic routing capabilities are available within a firewall, they should be restricted to BGP-4.
It can be extremely difficult to manage devices on the other side of a firewall. The typical configuration involves putting a network-management server inside of the firewall and the device to be managed on the outside of the firewall.
Firewalls are generally set up to allow just about anything to pass from the inside to the outside, but they strictly block inbound traffic. If you ping the device on the inside from the outside, you generally get no response. If you instead ping something on the outside from the inside, it usually works because the firewall knows to expect the returning ping response.
Let's look at this process in a little more detail. The network-management server sends out some kind of poll packet. For the time being, suppose that it is a ping request packet. This packet is received by the firewall. Most firewalls translate the IP source address of outbound packets. Instead of having the real network-management server's IP address, the packet has the firewall's external address when it is sent along. The external device receives this poll packet and responds. It creates a ping response packet and sends it to the firewall's IP address. The firewall has been waiting for this particular device to respond. It remembers that it passed through a ping request for this device that originated with the network-management server. Thus, it changes the destination address in the packet to the network management server's IP address and delivers the packet. If the external device had sent this packet without being prompted, the firewall would not know how to forward it internally, so it would simply drop it.
Now suppose the network manager needs something more sophisticated than ping. The firewall can be configured to pass SNMP packets, so the same pattern follows. The network-management server sends a packet. The source address is translated and the packet is delivered to the external device. The external device responds and sends the packet back to the firewall, which forwards it back to the server. Everything works well. But what about traps? SNMP traps are a critical part of the whole network-management system, but these traps are never prompted by a request. So how does the firewall know where to forward the inbound packets?
Many firewalls have the ability to define special inbound addresses. In effect, the outside of the firewall appears to have several different IP addresses. One of these addresses is configured to correspond to the network-management server. As long as the external device forwards its trap packets to this special address on the outside of the firewall, it is possible to deliver the addresses.
Alternatively, it is possible on many firewalls to deliver unexpected inbound packets based on their port number. SNMP has a well-known UDP port number of 161 for polls and poll responses, and 162 for traps. It is easy to ensure that all inbound SNMP traffic is forwarded to the network-management server.
Another interesting problem occurs when managing networks through firewalls. Sometimes the address translation works in the other direction. That is, the network-management server sees translated addresses for everything inside the managed cloud. Some network address-translation devices are capable of doing this kind of wholesale address translation, giving every device a new unique address.
This configuration especially appears in cases in which an external network-management service provider is used. The internal network may contain sensitive information and therefore require protection from the service provider by means of a firewall. The firewall may be configured to pass only SNMP and ICMP packets (and perhaps telnet, FTP, and TFTP for configuration-management purposes) and to translate all IP addresses in the internal network.
This address translation may be used for a good reason. If the network-management service provider manages two large networks, there is a good chance that both of them use the common unregistered 10.0.0.0 address range. If the service provider wants to see both networks properly, they have to do some address translation.
This configuration leads to serious complications, however. Many types of SNMP packets include IP addresses in their data segments. An IP address is just one of many pieces of management information that could be sent. However, this means that the address in the payload of the packet is different from the address in the header of the packet because of address translation. This difference causes serious confusion in many cases. There is no clean workaround. The best way to handle this situation is simply to avoid it. The network-management service provider is advised to maintain a separate, disconnected management server for each client.
In some cases, such as when managing sections of the public Internet, there may be security concerns about allowing SNMP through the firewall. In fact, there are security concerns about using SNMP at all in such hostile environments. Most frequently, the devices that are connected directly to the public Internet have SNMP disabled.
Disabling SNMP presents a serious management problem, however. How can the network manager monitor a device that doesn't use SNMP? As it turns out, a lot of devices, particularly in legacy networks, do not use SNMP. In all of these cases, it is necessary to use out-of-band management techniques. Some of these techniques are discussed later in this chapter.
Redundancy is one of the most important features of a robust network design. It is also one of the most dangerous because it makes it possible to get away with extremely poor network-management procedures. Suppose, for example, that you have a large network in which every trunk is redundant. If you have a trunk failure anywhere in the network, you suffer no noticeable application failure. This is a good thing, but that broken trunk now needs to be fixed. If you have another failure in the same area, you could have a severe outage. However, if you do not manage the network carefully, you might have missed the failure. After all, the phones didn't ring.
There have been many cases of networks running for years on a backup link because nobody noticed that the primary had failed.
Just as serious, and even less likely to be noticed, is a failure of a redundant backup when the primary was still working properly. Some network managers rely on interface up and down traps that indicate that the backup link or device was activated. This is certainly a good way of telling that the primary has failed, but there is no change of state if the redundant backup systems fail first.
Both of these scenarios reinforce the same point. All systems and links, even redundant backups, should be monitored constantly.
Constant monitoring can be particularly difficult in the case of links that are protected by Spanning Tree. Spanning Tree disables links that are in the backup state. It isn't possible to just ping through these links to see if they are operational. The Spanning Tree protocol does keep track of the status of its disabled links, however. There is an SNMP MIB extension specifically for monitoring Spanning Tree.
The MIB extension is called the dot1dStp (for 802.1d Spanning Tree Protocol) defined if RFC 1286. It contains specific entries describing the state of every port, dot1dStpPortState. The values that each port can have correspond to the various allowed states: disabled(1), blocking(2), listening(3), learning(4), forwarding(5), and broken(6). Using this SNMP MIB extension should provide all of the necessary information about the health of all redundant Spanning Tree links.
The ideal management technique for these links is to configure automated periodic polling for the states of all Spanning Tree ports using this special dot1dStpPortState variable. This information, combined with the traps generated by Link State changes, give a good picture of all primary and backup links.
There are several tunneling protocols. Some, like DLSw, are used to tunnel foreign protocols through IP networks. There are also several ways of tunneling IP in IP.
There are many reasons for tunneling IP in IP. Usually, they have to do with needing to pass transparently through sections of the network that are either externally controlled or lacking in some important feature. A common example of the missing feature problem is a legacy IP network that does not support the required dynamic routing protocol. Similarly, a device might need to take part in multicast applications. If it is located behind network devices that do not support multicasting, then it might be necessary to pass a tunnel through these devices to reach the multicast-enabled portion of the network.
It is also relatively common to use tunnels to hide the network structure of a foreign network that traffic must pass through. For example, it may be necessary to interconnect two buildings by means of a network operated by a telephone company. If the telephone company's network is essentially an IP network, this company might deliver the service as a tunnel to hide their internal network structure.
Another common type of tunnel is the ubiquitous VPN. In this case, an organization extends its private internal network to include a group of devices, or perhaps a single device, on the public Internet. VPN tunnels usually have the additional feature of being encrypted as they pass through the foreign network.
To the network manager, however, tunnels represent a difficult problem. If a failure or congestion occurs anywhere in the hidden region, the only symptoms are either interrupted or degraded service.
It is not possible to narrow down the problem any further than this unless there is another way to see the actual network devices that the tunnel passes through. If the tunnel passes through a foreign network that is managed by another organization, then you can simply pass the problem over to them. For tunnels that pass through internal pieces of network, it is necessary to have an out-of-band management system of some kind.
Out-of-band management means simply that user data and management data take different paths. There are many ways to accomplish this. Usually, when people use this term, they mean that the device is managed through a serial port. But it is useful to consider a much broader definition.
Devices are managed out-of-band for three main reasons:
Many Layer 1 and 2 devices are incapable of seeing Layer 3 addressing.
Some data streams contain untrusted data, so the devices should not be managed in-band for security reasons.
Some networks contain tunnels that hide the intermediate devices. These devices must be managed from outside of the tunnel.
First, let's look at the simplest type of out-of-band management. Transceivers, modems, and CSU/DSU type devices are almost impossible to manage in band. This is because these devices function at the physical layer. They do not even see the Layer 3 signaling that would allow them to send and receive SNMP packets. They could be given this capability, but it would require that they look at all frames that pass through them. That generally means that a faster CPU is needed. It can also introduce serious latency problems.
However, many of these types of devices can be managed through a serial port. In fact, in many cases, there is full SNMP (and even RMON, in some cases) support by means of a SLIP or PPP connection through an RS-232 serial port.
Not all lower-layer devices must be managed out-of-band. Many Ethernet and Token Ring hubs are managed in-band, for example. These Layer 2 devices are typically managed by a special purpose management card. This card is connected to the network as if it were an external device, but it lives inside the hub's chassis. In this way, the card can monitor the functioning of the hub without interfering with it.
Security presents another common reason for out-of-band management. The classic example is a router that is connected directly to the Internet. It is dangerous to allow such devices to respond to SNMP gets and sets. The security within SNMP is too simplistic to prevent a dedicated saboteur from modifying the configuration.
Many small organizations with only one router on the public Internet can get away with SNMP management of the device. They can apply access-list restrictions that drop all SNMP packets coming from or going to the Internet. Many organizations also prevent ICMP packets, but these restrictions would not be applied to the internal network. These devices can then be safely managed in-band through the port that faces the private network.
However, this strategy does not work for any organization with several devices connected directly to the untrusted network. If there are several such devices, then it is possible that the topology has become complex, with multiple different paths to the Internet. This complexity makes a simple path-based restriction impractical. Also, if several different devices are all connected directly to the untrusted network, it is possible to compromise one device and then use it as a base. From this base, the other devices can be compromised more easily. Thus, for all but the simplest connections, security restrictions mean that devices directly connected to the Internet should be managed out-of-band.
It can be useful to think of a special variety of management that is only partly out-of-band. This is the case for any tunnel that contains IP traffic. The tunneled traffic does not see any of the intermediate devices. However, these hidden devices can be managed using IP and SNMP through the same physical ports that contain the tunneled data.
For management purposes, there are effectively two types of tunnels. The tunnel can pass through a section of network that has directly accessible IP addressing. Or, the tunnel might pass through devices that cannot be reached in-band from the network-management server.
In the first case, a tunnel might pass through a group of legacy devices. This could be necessary because the legacy devices do not support the preferred dynamic routing protocol, such as OSPF. Or, it may be necessary because they do not support some key part of the IP protocol that is required for the data stream. This might be the case if there are MTU restrictions on the application, or if there are special QoS or multicast requirements. Or, maybe the tunnel is there to trick the routing protocol into thinking that a device is in a different part of the network, such as a different OSPF area. However, in these cases, the tunnel passes through devices that are managed in-band. They are part of the same IP-address range and the same Autonomous System (AS). In effect, these devices are managed out-of-band from the tunnels, but through the same physical interfaces that tunnels use. In this case, the management is essentially in-band.
There are also times when a tunnel passes through a different AS. The devices in the other AS could even be part of a distinct group of IP addresses that the network cannot route to directly. This is where the line between in-band and out-of-band becomes rather blurred.
This construction is relatively common when a network vendor uses an IP-based network to carry the traffic of several different customers. They can get excellent fault tolerance through their networks by using dynamic IP-routing techniques, but they must prevent the different customer data streams from seeing one another. This prevention is easily done by simply passing tunnels through the vendor's network Core. The vendor places a router on each of the customer's premises and terminates the tunnels on these routers. Thus, no customer is able to see any of the Core devices directly, nor even the IP-address range used in it. In fact, the IP-address range in the vendor's Core can overlap with one or more different customer-address ranges without conflict. Everybody can use 10.0.0.0 internally, for example, without causing routing problems.
In this case, however, the customer would not do out-of-band management on the vendor's network. It should be managed by the vendor. I mention this configuration, though, because sometimes an organization must be this sort of vendor to itself. This happens in particular during mergers of large corporations.
In effect, all of these different options come down to management through either a LAN port or through a serial port. Management through a LAN port effectively becomes the same as regular in-band management. The only difference is that it might be necessary to engineer some sort of back-door path to the managed LAN port. However, management through a serial port always requires some sort of special engineering. Serial-port management is usually done in one of two ways. In some cases, a higher-layer protocol can run through the serial port using SLIP or PPP. In most cases, there is only a console application available through this port.
If SLIP or PPP options are available, they can make management of these devices much easier. I recommend using it wherever possible.
Figure 9-2 shows one common configuration for out-of-band management using a SLIP link.[1] The managed device is not specified, although it could be a CSU, a microwave transmitter, or any other lower-layer device that does not see Layer 3 packets directly.
[1] The example indicates the use of SLIP on the serial link, but any other serial protocol, such as PPP or HDLC, would work in exactly the same way. I specifically mention SLIP because it is common for this type of application.
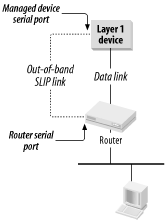
In this case, a low-speed serial port on the router is configured for SLIP. A serial cable is then connected to the management port on the device. As anybody who has set up such a link will attest, there are many ways to misconfigure such a setup. Usually, SLIP links assume asynchronous serial connections. Conversely, most router serial ports are synchronous by default. Thus, the router's port must be configured to operate asynchronously.
SLIP creates a point-to-point IP link over the serial line. Therefore, both ends must have IP addresses and the managed device must have its default gateway configured to point to the router's address on this link. Usually, the managed device will not run nor need to run any dynamic routing protocols, so ensure that these are turned off on the router for this port. However, the router needs to distribute the route to this device into the dynamic routing protocol so that the management server knows how to reach it.
In many cases, the managed device uses the same physical serial port for SLIP that it uses for regular console connections. It is important to ensure that the port is configured for SLIP rather than console mode before connecting. This configuration usually just involves connecting a terminal to the console and switching the mode, then disconnecting the terminal and connecting the router in its place.
With any serial connection, make sure that the DTE and DCE relationships are made correctly. This relationship is not just the physical pins on one end the cable being male and female on the other. It also specifies which pins are used for sending and receiving. The relationship becomes more involved for synchronous connections, in which you also have to worry about which device provides the clock signal. In most cases, the manufacturer assumes that the device is talking to a modem. Modems are always DCE, so the serial interface on the device is almost always DTE. Thus, the router must be configured to be DCE.
Once this has all been done properly, it should be possible to do SNMP management of the device. It will have an IP address, and it should respond to ping and SNMP polling. Some of these devices also support telnet to allow a remote-console connection.
For SNMP management, remember to set up the network-management station as the SNMP on the device. This usually does not restrict polling, but rather specifies where the device will send traps when it sees important error conditions. In general, it is a bad idea to specify a large number of trap recipients. One or two should be sufficient.
If too many trap recipients are specified, then each time the device encounters a serious problem, it has to send trap packets to all the devices. Over a slow serial line, sending these packets can take a relatively long time, perhaps as long as a second or more. In a disaster situation, this is a very long time, and it may mean that the device is unable to send the trap to every recipient. It may also mean that the device's CPU is temporarily overloaded by creating and sending traps, which could worsen disaster situation.
For devices that do not support SLIP or PPP, remote out-of-band management can become messy. Somehow, there has to be a console connection between the device's console serial port and the network-management server. If there are more than a few of these devices or if they are physically remote, it is not practical to use direct serial cables. Thus, you have to come up with other methods for making these connections. Once you have these physical connections, you need to have a way to use them automatically. As I said earlier in this chapter, all network monitoring should be automated, and it should have a way to report problems to humans for investigation.
Some network-management software provides the ability to build arbitrary scripts for managing nonstandard devices. If there is a way to connect physically to a device, the software has a way to ask that device about its health. In most cases, the network manager would then automate this script to run every few minutes. If there are no problems, the result is simply recorded in a log. If the device reports an error condition of some kind, it can trigger an alarm to allow a human to investigate.
This fact alone indicates why having hardware standards is so important. If you have a thousand identical devices that you have to manage this way, you can do it all with the same script. You can also afford to take the time to make this script robust and useful. However, if you have a thousand different devices from different hardware vendors, coming up with a thousand such scripts is impractical.
Physically, there are two main ways to create these out-of-band physical connections. For remote locations, the best method is simply to attach a modem to the console port. This attachment allows the device to be contacted for maintenance even if the primary network is down. It is also problematic because the server cannot do a frequent poll of the device's health.
Doing regular polling of serially managed devices requires a way to get this serial data into the network's data stream. A convenient device for doing this is called an inverse terminal server. An inverse terminal server is in many ways very similar to a normal terminal server. In fact, many commercial terminal servers are able to function as inverse terminal servers as well. Some low-speed multiport routers can also be used for this purpose.
A terminal server has a LAN port and one or more serial ports. They were once extremely common, as they provided a way to connect dumb terminals to the network. Each terminal would connect to a serial port on the terminal server. Then, from the terminal server, the user could use a text-communication protocol, such as telnet, to connect to the application server.
An inverse terminal server is similar, except that it makes connections from the network to the serially connected devices, rather than the other way around. Usually, this server works by making a telnet connection to the IP address of the terminal server, but on a special high-numbered TCP port that specifies a particular serial port uniquely.
As Figure 9-3 shows, you can use an inverse terminal server to manage a number of different devices through out-of-band serial connections.
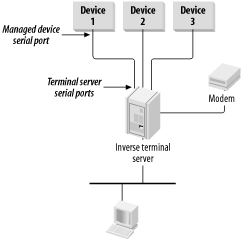
The network-management server is configured to telnet to the appropriate set of IP address and TCP ports that represent a particular device. It then runs a script that queries the device about its health.
As noted previously, when connecting a serial console port to a router, you have to be careful to configure the DCE and DTE relationships properly. However, unlike the SLIP example, in the case of text-based console ports, there is no common standard for the gender of the console connection.
In some cases, the console port is DCE; in other cases, it is DTE. There are even pathological examples in which the gender of the cable does not match the Layer 1 signaling on the port. For example, it may be a female (DCE) connector physically, but with DTE pin arrangement. In this case, it is necessary to use a null-modem adapter with the cable to convert DCE to DTE instead of just swapping female to male connectors.
In other cases, you need to convert the gender, as well as the DCE/DTE relationship. There are no set rules to make this conversion. Therefore, it is usually a good idea to have a supply of gender-changer plugs and null-modem adapters on hand. To make matters worse, some devices require special cables because they use extra or nonstandard RS-232 signaling. Others do not use RS-232 standards. Consult the documentation of the device being connected.
With many inverse terminal server devices, it is possible to also run SLIP or PPP on the various serial ports. In this way, you can combine several console ports on one inverse terminal server. Since a network-management failure never affects service, it is not necessary to build redundancy. This permits the inverse terminal server to act as a router for several very slow links. The network-management server can then do direct SNMP polling to the out-of-band devices. Of course, if you can do SLIP or text-based console connections through an inverse terminal server, you can do a combination of the two. This configuration can provide a useful way of managing a group of these devices. For example, several CSU devices, firewalls, and other hard-to-manage devices may exist in the same computer equipment room. By running serial cables to a common inverse terminal server, it is possible to provide convenient secure management to all of them at once.
The advantages of remote modem access can be combined with the ability to do periodic polling out-of-band. Most inverse terminal servers provide the ability to connect a modem to one of the ports, as shown in Figure 9-3. This connection allows periodic polling of the console ports of the various serially attached devices through the network. If a serious network failure leaves this part of the network unreachable, the network manager can still get to it by dialing to the modem.
With SLIP-type connectison on an inverse terminal server, you will definitely have a DCE/DTE issue with the ports. As I said earlier, usually the SLIP port on the managed device expects to talk to a modem, so it is usually DTE for the modem's DCE. Those ports on the inverse terminal server connecting to SLIP managed devices will likely be configured as DCE. However, the port that connects to the modem have to be DTE. As always, have a handful of gender changers and null-modem adapters on hand whenever setting up this sort of configuration.
One final issue should be mentioned when connecting modems or terminal servers to a console port. This connection can represent a serious security problem on many devices. Most pieces of network equipment provide the ability to override the software configuration from the console during the boot sequence. This override is frequently called password recovery.
Password recovery means that an intruder can take advantage of a power failure to take control of a network device. From there, it might be possible to gain control of other network devices, perhaps even the Core of the network. Gaining control of these devices is a lot of work, requiring a skilled attacker, but it is possible. For this reason, some network-equipment vendors (particularly Cisco) actually include two serial ports, one called Console and the other Auxiliary. The Console port, but not the Auxiliary port, can be used for password recovery. In this case, it is safest to connect any out-of-band management equipment to the Auxiliary port.