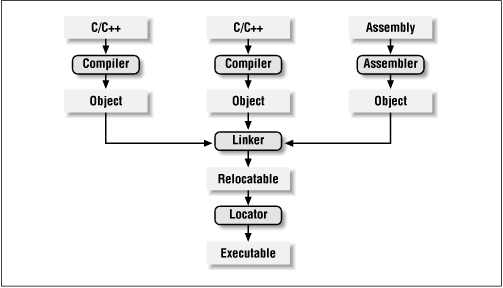
Figure 3-1. The embedded software development process
I consider that the golden rule requires that if I like a program I must share it with other people who like it. Software sellers want to divide the users and conquer them, making each user agree not to share with others. I refuse to break solidarity with other users in this way. I cannot in good conscience sign a nondisclosure agreement or a software license agreement. So that I can continue to use computers without dishonor, I have decided to put together a sufficient body of free software so that I will be able to get along without any software that is not free.
—Richard Stallman, Founder of the GNU Project, The GNU Manifesto
In this chapter, we'll examine the steps involved in preparing your software for execution on an embedded system. We'll also discuss the associated development tools and see how to build the Blinking LED program shown in Chapter 2. But before we get started, I want to make it clear that embedded systems programming is not substantially different from the programming you've done before. The only thing that has really changed is that each target hardware platform is unique. Unfortunately, that one difference leads to a lot of additional software complexity, and it's also the reason you'll need to be more aware of the software build process than ever before.
There are a lot of things that software development tools can do automatically when the target platform is well defined.[1] This automation is possible because the tools can exploit features of the hardware and operating system on which your program will execute. For example, if all of your programs will be executed on IBM-compatible PCs running DOS, your compiler can automate—and, therefore, hide from your view—certain aspects of the software build process. Embedded software development tools, on the other hand, can rarely make assumptions about the target platform. Instead, the user must provide some of his own knowledge of the system to the tools by giving them more explicit instructions.
The process of converting the source code representation of your embedded software into an executable binary image involves three distinct steps. First, each of the source files must be compiled or assembled into an object file. Second, all of the object files that result from the first step must be linked together to produce a single object file, called the relocatable program. Finally, physical memory addresses must be assigned to the relative offsets within the relocatable program in a process called relocation. The result of this third step is a file that contains an executable binary image that is ready to be run on the embedded system.
The embedded software development process just described is illustrated in Figure 3-1. In this figure, the three steps are shown from top to bottom, with the tools that perform them shown in boxes that have rounded corners. Each of these development tools takes one or more files as input and produces a single output file. More specific information about these tools and the files they produce is provided in the sections that follow.
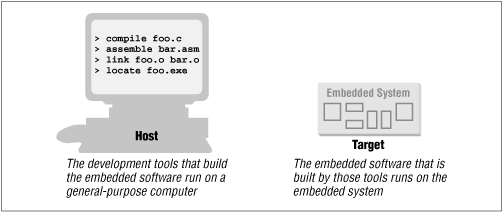
Each of the steps of the embedded software build process is a transformation performed by software running on a general-purpose computer. To distinguish this development computer (usually a PC or Unix workstation) from the target embedded system, it is referred to as the host computer. In other words, the compiler, assembler, linker, and locator are all pieces of software that run on a host computer, rather than on the embedded system itself. Yet, despite the fact that they run on some other computer platform, these tools combine their efforts to produce an executable binary image that will execute properly only on the target embedded system. This split of responsibilities is shown in Figure 3-2.
In this chapter and the next I'll be using the GNU tools (compiler, assembler, linker, and debugger) as examples. These tools are extremely popular with embedded software developers because they are freely available (even the source code is free) and support many of the most popular embedded processors. I will use features of these specific tools as illustrations for the general concepts discussed. Once understood, these same basic concepts can be applied to any equivalent development tool.
The job of a compiler is mainly to translate programs written in some human-readable language into an equivalent set of opcodes for a particular processor. In that sense, an assembler is also a compiler (you might call it an "assembly language compiler") but one that performs a much simpler one-to-one translation from one line of human-readable mnemonics to the equivalent opcode. Everything in this section applies equally to compilers and assemblers. Together these tools make up the first step of the embedded software build process.
Of course, each processor has its own unique machine language, so you need to choose a compiler that is capable of producing programs for your specific target processor. In the embedded systems case, this compiler almost always runs on the host computer. It simply doesn't make sense to execute the compiler on the embedded system itself. A compiler such as this—that runs on one computer platform and produces code for another—is called a cross-compiler. The use of a cross-compiler is one of the defining features of embedded software development.
The GNU C/C++ compiler ( gcc ) and assembler (as ) can be configured as either native compilers or cross-compilers. As cross-compilers these tools support an impressive set of host-target combinations. Table 3-1 lists some of the most popular of the supported hosts and targets. Of course, the selections of host platform and target processor are independent; these tools can be configured for any combination.
|
Host Platforms |
Target Processors |
|---|---|
|
DEC Alpha Digital Unix HP 9000/700 HP-UX IBM Power PC AIX IBM RS6000 AIX SGI Iris IRIX Sun SPARC Solaris Sun SPARC SunOS X86 Windows 95/NT X86 Red Hat Linux
|
AMD/Intel x86 (32-bit only) Fujitsu SPARClite Hitachi H8/300, H8/300H, H8/S Hitachi SH IBM/Motorola PowerPC Intel i960 MIPS R3xxx, R4xx0 Mitsubishi D10V, M32R/D Motorola 68k Sun SPARC, MicroSPARC Toshiba TX39 |
Regardless of the input language (C/C++, assembly, or any other), the output of the cross-compiler will be an object file. This is a specially formatted binary file that contains the set of instructions and data resulting from the language translation process. Although parts of this file contain executable code, the object file is not intended to be executed directly. In fact, the internal structure of an object file emphasizes the incompleteness of the larger program.
The contents of an object file can be thought of as a very large, flexible data structure. The structure of the file is usually defined by a standard format like the Common Object File Format (COFF) or Extended Linker Format (ELF). If you'll be using more than one compiler (i.e., you'll be writing parts of your program in different source languages), you need to make sure that each is capable of producing object files in the same format. Although many compilers (particularly those that run on Unix platforms) support standard object file formats like COFF and ELF ( gcc supports both), there are also some others that produce object files only in proprietary formats. If you're using one of the compilers in the latter group, you might find that you need to buy all of your other development tools from the same vendor.
Most object files begin with a header that describes the sections that follow. Each of these sections contains one or more blocks of code or data that originated within the original source file. However, these blocks have been regrouped by the compiler into related sections. For example, all of the code blocks are collected into a section called text, initialized global variables (and their initial values) into a section called data, and uninitialized global variables into a section called bss.
There is also usually a symbol table somewhere in the object file that contains the names and locations of all the variables and functions referenced within the source file. Parts of this table may be incomplete, however, because not all of the variables and functions are always defined in the same file. These are the symbols that refer to variables and functions defined in other source files. And it is up to the linker to resolve such unresolved references.
All of the object files resulting from step one must be combined in a special way before the program can be executed. The object files themselves are individually incomplete, most notably in that some of the internal variable and function references have not yet been resolved. The job of the linker is to combine these object files and, in the process, to resolve all of the unresolved symbols.
The output of the linker is a new object file that contains all of the code and data from the input object files and is in the same object file format. It does this by merging the text, data, and bss sections of the input files. So, when the linker is finished executing, all of the machine language code from all of the input object files will be in the text section of the new file, and all of the initialized and uninitialized variables will reside in the new data and bss sections, respectively.
While the linker is in the process of merging the section contents, it is also on the lookout for unresolved symbols. For example, if one object file contains an unresolved reference to a variable named foo and a variable with that same name is declared in one of the other object files, the linker will match them up. The unresolved reference will be replaced with a reference to the actual variable. In other words, if foo is located at offset 14 of the output data section, its entry in the symbol table will now contain that address.
The GNU linker (ld ) runs on all of the same host platforms as the GNU compiler. It is essentially a command-line tool that takes the names of all the object files to be linked together as arguments. For embedded development, a special object file that contains the compiled startup code must also be included within this list. (See Startup Code later in this chapter.) The GNU linker also has a scripting language that can be used to exercise tighter control over the object file that is output.
Startup CodeOne of the things that traditional software development tools do automatically is to insert startup code. Startup code is a small block of assembly language code that prepares the way for the execution of software written in a high-level language. Each high-level language has its own set of expectations about the runtime environment. For example, C and C++ both utilize an implicit stack. Space for the stack has to be allocated and initialized before software written in either language can be properly executed. That is just one of the responsibilities assigned to startup code for C/C++ programs. Most cross-compilers for embedded systems include an assembly language file called startup.asm, crt0.s (short for C runtime), or something similar. The location and contents of this file are usually described in the documentation supplied with the compiler. Startup code for C/C++ programs usually consists of the following actions, performed in the order described:
Typically, the startup code will also include a few instructions after the call to main. These instructions will be executed only in the event that the high-level language program exits (i.e., the call to main returns). Depending on the nature of the embedded system, you might want to use these instructions to halt the processor, reset the entire system, or transfer control to a debugging tool. Because the startup code is not inserted automatically, the programmer must usually assemble it himself and include the resulting object file among the list of input files to the linker. He might even need to give the linker a special command-line option to prevent it from inserting the usual startup code. Working startup code for a variety of target processors can be found in a GNU package called libgloss. |
If the same symbol is declared in more than one object file, the linker is unable to proceed. It will likely appeal to the programmer—by displaying an error message—and exit. However, if a symbol reference instead remains unresolved after all of the object files have been merged, the linker will try to resolve the reference on its own. The reference might be to a function that is part of the standard library, so the linker will open each of the libraries described to it on the command line (in the order provided) and examine their symbol tables. If it finds a function with that name, the reference will be resolved by including the associated code and data sections within the output object file.[2]
Unfortunately, the standard library routines often require some changes before they can be used in an embedded program. The problem here is that the standard libraries provided with most software development tool suites arrive only in object form. So you only rarely have access to the library source code to make the necessary changes yourself. Thankfully, a company called Cygnus has created a freeware version of the standard C library for use in embedded systems. This package is called newlib. You need only download the source code for this library from the Cygnus web site, implement a few target-specific functions, and compile the whole lot. The library can then be linked with your embedded software to resolve any previously unresolved standard library calls.
After merging all of the code and data sections and resolving all of the symbol references, the linker produces a special "relocatable" copy of the program. In other words, the program is complete except for one thing: no memory addresses have yet been assigned to the code and data sections within. If you weren't working on an embedded system, you'd be finished building your software now.
But embedded programmers aren't generally finished with the build process at this point. Even if your embedded system includes an operating system, you'll probably still need an absolutely located binary image. In fact, if there is an operating system, the code and data of which it consists are most likely within the relocatable program too. The entire embedded application—including the operating system—is almost always statically linked together and executed as a single binary image.
The tool that performs the conversion from relocatable program to executable binary image is called a locator. It takes responsibility for the easiest step of the three. In fact, you will have to do most of the work in this step yourself, by providing information about the memory on the target board as input to the locator. The locator will use this information to assign physical memory addresses to each of the code and data sections within the relocatable program. It will then produce an output file that contains a binary memory image that can be loaded into the target ROM.
In many cases, the locator is a separate development tool. However, in the case of the GNU tools, this functionality is built right into the linker. Try not to be confused by this one particular implementation. Whether you are writing software for a general-purpose computer or an embedded system, at some point the sections of your relocatable program must have actual addresses assigned to them. In the first case, the operating system does it for you at load time. In the second, you must perform the step with a special tool. This is true even if the locator is a part of the linker, as it is in the case of ld.
The memory information required by the GNU linker can be passed to it in the form of a linker script. Such scripts are sometimes used to control the exact order of the code and data sections within the relocatable program. But here, we want to do more than just control the order; we also want to establish the location of each section in memory.
What follows is an example of a linker script for a hypothetical embedded target that has 512 KB each of RAM and ROM:
MEMORY
{
ram : ORIGIN = 0x00000, LENGTH = 512K
rom : ORIGIN = 0x80000, LENGTH = 512K
}
SECTIONS
{
data ram : /* Initialized data. */
{
_DataStart = . ;
*(.data)
_DataEnd = . ;
} >rom
bss : /* Uninitialized data. */
{
_BssStart = . ;
*(.bss)
_BssEnd = . ;
}
_BottomOfHeap = . ; /* The heap starts here. */
_TopOfStack = 0x80000; /* The stack ends here. */
text rom : /* The actual instructions. */
{
*(.text)
}
}
This script informs the GNU linker's built-in locator about the memory on the target board and instructs it to locate the data and bss sections in RAM (starting at address 0x00000) and the text section in ROM (starting at 0x80000). However, the initial values of the variables in the data segment will be made a part of the ROM image by the addition of >rom at the end of that section's definition.
All of the names that begin with underscores (_TopOfStack, for example) are variables that can be referenced from within your source code. The linker will use these symbols to resolve references in the input object files. So, for example, there might be a part of the embedded software (usually within the startup code) that copies the initial values of the initialized variables from ROM to the data section in RAM. The start and stop addresses for this operation can be established symbolically, by referring to the integer variables _DataStart and _DataEnd .
The result of this final step of the build process is an absolutely located binary image that can be downloaded to the embedded system or programmed into a read-only memory device. In the previous example, this memory image would be exactly 1 MB in size. However, because the initial values for the initialized data section are stored in ROM, the lower 512 kilobytes of this image will contain only zeros, so only the upper half of this image is significant. You'll see how to download and execute such memory images in the next chapter.
Unfortunately, because we're using the Arcom board as our reference platform, we won't be able to use the GNU tools to build the examples. Instead we'll be using Borland's C++ Compiler and Turbo Assembler. These tools can be run on any DOS or Windows-based PC.[3] If you have an Arcom board to experiment with, this would be a good time to set it up and install the Borland development tools on your host computer. (See Appendix A for ordering information). I used version 3.1 of the compiler, running on a Windows 95-based PC. However, any version of the Borland tools that can produce code for the 80186 processor will do.
As I have implemented it, the Blinking LED example consists of three source modules: led.c, blink.c, and startup.asm. The first step in the build process is to compile these two files. The command-line options we'll need are -c for "compile, but don't link," -v for "include symbolic debugging information in the output," -ml for "use the large memory model," and -1 for "the target is an 80186 processor." Here are the actual commands:
bcc -c -v -ml -1 led.c bcc -c -v -ml -1 blink.c
Of course, these commands will work only if the bcc.exe program is in your PATH and the two source files are in the current directory. In other words, you should be in the Chapter2 subdirectory. The result of each of these commands is the creation of an object file that has the same prefix as the .c file and the extension .obj. So if all goes well, there will now be two additional files—led.obj and blink.obj —in the working directory.
Although it would appear that there are only these two object files to be linked together in our example, there are actually three. That's because we must also include some startup code for the C program. (See Startup Code earlier in this chapter.) Example startup code for the Arcom board is provided in the file startup.asm, which is included in the Chapter3 subdirectory. To assemble this code into an object file, change to that directory and issue the following command:
tasm /mx startup.asm
The result should be the file startup.obj in that directory. The command that's actually used to link the three object files together is shown here. Beware that the order of the object files on the command line does matter in this case: the startup code must be placed first for proper linkage.
tlink /m /v /s ..\Chapter3\startup.obj led.obj blink.obj, blink.exe, blink.map
As a result of the tlink command, Borland's Turbo Linker will produce two new files: blink.exe and blink.map in the working directory. The first file contains the relocatable program and the second contains a human-readable program map. If you have never seen such a map file before, be sure to take a look at this one before reading on. It provides information similar to the contents of the linker script described earlier. However, these are results and, therefore, include the lengths of the sections and the names and locations of the public symbols found in the relocatable program.
One more tool must be used to make the Blinking LED program executable: a locator. The locating tool we'll be using is provided by Arcom, as part of the SourceVIEW development and debugging package included with the board. Because this tool is designed for this one particular embedded platform, it does not have as many options as a more general locator.[4]
In fact, there are just three parameters: the name of the relocatable binary image, the starting address of the ROM (in hexadecimal) and the total size of the destination RAM (in kilobytes):
tcrom blink.exe C000 128 SourceVIEW Borland C ROM Relocator v1.06 Copyright (c) Arcom Control Systems Ltd 1994 Relocating code to ROM segment C000H, data to RAM segment 100H Changing target RAM size to 128 Kbytes Opening 'blink.exe'... Startup stack at 0102:0402 PSP Program size 550H bytes (2K) Target RAM size 20000H bytes (128K) Target data size 20H bytes (1K) Creating 'blink.rom'... ROM image size 550H bytes (2K)
The tcrom locator massages the contents of the relocatable input file—assigning base addresses to each section—and outputs the file blink.rom. This file contains an absolutely located binary image that is ready to be loaded directly into ROM. But rather than load it into the ROM with a device programmer, we'll create a special ASCII version of the binary image that can be downloaded to the ROM over a serial port. For this we will use a utility provided by Arcom, called bin2hex. Here is the syntax of the command:
bin2hex blink.rom /A=1000
This extra step creates a new file, called blink.hex, that contains exactly the same information as blink.rom, but in an ASCII representation called Intel Hex Format.
[1] Used this way, the term "target platform" is best understood to include not only the hardware but also the operating system that forms the basic runtime environment for your software. If no operating system is present—as is sometimes the case in an embedded system—the target platform is simply the processor on which your program will be run.
[2] Beware that I am only talking about static linking here. In non-embedded environments, dynamic linking of libraries is very common. In that case, the code and data associated with the library routine are not inserted into the program directly.
[3] It is interesting to note that Borland's C++ compiler was not specifically designed for use by embedded software developers. It was instead designed to produce DOS and Windows-based programs for PCs that had 80x86 processors. However, the inclusion of certain command-line options allows us to specify a particular 80x86 processor—the 80186, for example—and, thus, use this tool as a cross-compiler for embedded systems like the Arcom board.
[4] However, being free, it is also a lot cheaper than a more general locator.