| CONTENTS |
So far in this book, we've used Python in the system programming, GUI development, and Internet scripting domains -- three of Python's most common applications. In the next three chapters, we're going to take a quick look at other major Python programming topics: persistent data, data structure techniques, and text and language processing tools. None of these are covered exhaustively (each could easily fill a book alone), but we'll sample Python in action in these domains and highlight their core concepts. If any of these chapters spark your interest, additional resources are readily available in the Python world.
In this chapter, our focus is on persistent data -- the kind that outlives a program that creates it. That's not true by default for objects a script constructs; things like lists, dictionaries, and even class instance objects live in your computer's memory and are lost as soon as the script ends. To make data longer-lived, we need to do something special. In Python programming, there are at least five traditional ways to save information between program executions:
Flat files: storing text and bytes
DBM keyed files: keyed access to strings
Pickled objects: serializing objects to byte streams
Shelve files: storing pickled objects in DBM keyed files
Database systems: full-blown SQL and object database systems
We studied Python's simple (or "flat") file interfaces in earnest in Chapter 2, and have been using them ever since. Python provides standard access to both the stdio filesystem (through the built-in open function), as well as lower-level descriptor-based files (with the built-in os module). For simple data storage tasks, these are all that many scripts need. To save for use in a future program run, simply write data out to a newly opened file on your computer and read it back from that file later. As we've seen, for more advanced tasks, Python also supports other file-like interfaces such as pipes, fifos, and sockets.
Since we've already explored flat files, I won't say more about them here. The rest of this chapter introduces the remaining topics on the list earlier in this section. At the end, we'll also meet a GUI program for browsing the contents of things like shelves and DBM files. Before that, though, we need to learn what manner of beast these are.
Flat files are handy for simple persistence tasks, but are generally geared towards a sequential processing mode. Although it is possible to jump around to arbitrary locations with seek calls, flat files don't provide much structure to data beyond the notion of bytes and text lines.
DBM files, a standard tool in the Python library for database management, improve on that by providing key-based access to stored text strings. They implement a random-access, single-key view on stored data. For instance, information related to objects can be stored in a DBM file using a unique key per object and later can be fetched back directly with the same key. DBM files are implemented by a variety of underlying modules (including one coded in Python), but if you have Python, you have a DBM.
Although DBM filesystems have to do a bit of work to map chunks of stored data to keys for fast retrieval (technically, they generally use a technique called hashing to store data in files), your scripts don't need to care about the action going on behind the scenes. In fact, DBM is one of the easiest ways to save information in Python -- DBM files behave so much like in-memory dictionaries that you may forget you're actually dealing with a file. For instance, given a DBM file object:
Indexing by key fetches data from the file.
Assigning to an index stores data in the file.
DBM file objects also support common dictionary methods such as keys-list fetches and tests, and key deletions. The DBM library itself is hidden behind this simple model. Since it is so simple, let's jump right into an interactive example that creates a DBM file and shows how the interface works:
% python
>>> import anydbm # get interface: dbm, gdbm, ndbm,..
>>> file = anydbm.open('movie', 'c') # make a dbm file called 'movie'
>>> file['Batman'] = 'Pow!' # store a string under key 'Batman'
>>> file.keys( ) # get the file's key directory
['Batman']
>>> file['Batman'] # fetch value for key 'Batman'
'Pow!'
>>> who = ['Robin', 'Cat-woman', 'Joker']
>>> what = ['Bang!', 'Splat!', 'Wham!']
>>> for i in range(len(who)):
... file[who[i]] = what[i] # add 3 more "records"
...
>>> file.keys( )
['Joker', 'Robin', 'Cat-woman', 'Batman']
>>> len(file), file.has_key('Robin'), file['Joker']
(4, 1, 'Wham!')
>>> file.close( ) # close sometimes required
Internally, importing anydbm automatically loads whatever DBM interface is available in your Python interpreter, and opening the new DBM file creates one or more external files with names that start with the string "movie" (more on the details in a moment). But after the import and open, a DBM file is virtually indistinguishable from a dictionary. In effect, the object called file here can be thought of as a dictionary mapped to an external file called movie.
Unlike normal dictionaries, though, the contents of file are retained between Python program runs. If we come back later and restart Python, our dictionary is still available. DBM files are like dictionaries that must be opened:
% python
>>> import anydbm
>>> file = anydbm.open('movie', 'c') # open existing dbm file
>>> file['Batman']
'Pow!'
>>> file.keys( ) # keys gives an index list
['Joker', 'Robin', 'Cat-woman', 'Batman']
>>> for key in file.keys( ): print key, file[key]
...
Joker Wham!
Robin Bang!
Cat-woman Splat!
Batman Pow!
>>> file['Batman'] = 'Ka-Boom!' # change Batman slot
>>> del file['Robin'] # delete the Robin entry
>>> file.close( ) # close it after changes
Apart from having to import the interface and open and close the DBM file, Python programs don't have to know anything about DBM itself. DBM modules achieve this integration by overloading the indexing operations and routing them to more primitive library tools. But you'd never know that from looking at this Python code -- DBM files look like normal Python dictionaries, stored on external files. Changes made to them are retained indefinitely:
% python
>>> import anydbm # open dbm file again
>>> file = anydbm.open('movie', 'c')
>>> for key in file.keys( ): print key, file[key]
...
Joker Wham!
Cat-woman Splat!
Batman Ka-Boom!
As you can see, this is about as simple as it can be. Table 16-1 lists the most commonly used DBM file operations. Once such a file is opened, it is processed just as though it were an in-memory Python dictionary. Items are fetched by indexing the file object by key and stored by assigning to a key.
|
Python Code |
Action |
Description |
|---|---|---|
|
import anydbm |
Import |
Get dbm, gdbm ,... whatever is installed |
|
file = anydbm.open('filename', 'c') |
Open[1] |
Create or open an existing DBM file |
|
file['key'] = 'value' |
Store |
Create or change the entry for key |
|
value = file['key'] |
Fetch |
Load the value for entry key |
|
count = len(file) |
Size |
Return the number of entries stored |
|
index = file.keys( ) |
Index |
Fetch the stored keys list |
|
found = file. has_key('key') |
Query |
See if there's an entry for key |
|
del file['key'] |
Delete |
Remove the entry for key |
|
file.close( ) |
Close |
Manual close, not always needed |
Despite the dictionary-like interface, DBM files really do map to one or more external files. For instance, the underlying gdbm interface writes two files, movie.dir and movie.pag, when a GDBM file called movie is made. If your Python was built with a different underlying keyed-file interface, different external files might show up on your computer.
Technically, module anydbm is really an interface to whatever DBM-like filesystem you have available in your Python. When creating a new file, anydbm today tries to load the dbhash, gdbm , and dbm keyed-file interface modules; Pythons without any of these automatically fall back on an all-Python implementation called dumbdbm. When opening an already-existing DBM file, anydbm tries to determine the system that created it with the whichdb module instead. You normally don't need to care about any of this, though (unless you delete the files your DBM creates).
Note that DBM files may or may not need to be explicitly closed, per the last entry in Table 16-1. Some DBM files don't require a close call, but some depend on it to flush changes out to disk. On such systems, your file may be corrupted if you omit the close call. Unfortunately, the default DBM on the 1.5.2 Windows Python port, dbhash (a.k.a., bsddb), is one of the DBM systems that requires a close call to avoid data loss. As a rule of thumb, always close your DBM files explicitly after making changes and before your program exits, to avoid potential problems. This rule extends by proxy to shelves, a topic we'll meet later in this chapter.
Probably the biggest limitation of DBM keyed files is in what they can store: data stored under a key must be a simple text string. If you want to store Python objects in a DBM file, you can sometimes manually convert them to and from strings on writes and reads (e.g., with str and eval calls), but this only takes you so far. For arbitrarily complex Python objects like class instances, you need something more. Class instance objects, for example, cannot be later recreated from their standard string representations.
The Python pickle module, a standard part of the Python system, provides the conversion step needed. It converts Python in-memory objects to and from a single linear string format, suitable for storing in flat files, shipping across network sockets, and so on. This conversion from object to string is often called serialization -- arbitrary data structures in memory are mapped to a serial string form. The string representation used for objects is also sometimes referred to as a byte-stream, due to its linear format.
Pickling may sound complicated the first time you encounter it, but the good news is that Python hides all the complexity of object-to-string conversion. In fact, the pickle module's interfaces are incredibly simple to use. The following list describes a few details of this interface.
Make a new pickler for pickling to an open output file object file.
Write an object onto the pickler's file/stream.
Same as the last two calls combined: pickle an object onto an open file.
Make an unpickler for unpickling from an open input file object file.
Read an object from the unpickler's file/stream.
Same as the last two calls combined: unpickle an object from an open file.
Return the pickled representation of object as a character string.
Read an object from a character string instead of a file.
Pickler and Unpickler are exported classes. In all of these, file is either an open file object or any object that implements the same attributes as file objects:
Pickler calls the file's write method with a string argument.
Unpickler calls the file's read method with a byte count, and readline without arguments.
Any object that provides these attributes can be passed in to the "file" parameters. In particular, file can be an instance of a Python class that provides the read/write methods. This lets you map pickled streams to in-memory objects, for arbitrary use. It also lets you ship Python objects across a network, by providing sockets wrapped to look like files in pickle calls at the sender and unpickle calls at the receiver (see Making Sockets Look Like Files in Chapter 10, for more details).
In more typical use, to pickle an object to a flat file, we just open the file in write-mode, and call the dump function; to unpickle, reopen and call load:
% python
>>> import pickle
>>> table = {'a': [1, 2, 3], 'b': ['spam', 'eggs'], 'c':{'name':'bob'}}
>>> mydb = open('dbase', 'w')
>>> pickle.dump(table, mydb)
% python
>>> import pickle
>>> mydb = open('dbase', 'r')
>>> table = pickle.load(mydb)
>>> table
{'b': ['spam', 'eggs'], 'a': [1, 2, 3], 'c': {'name': 'bob'}}
To make this process simpler still, the module in Example 16-1 wraps pickling and unpickling calls in functions that also open the files where the serialized form of the object is stored.
import pickle
def saveDbase(filename, object):
file = open(filename, 'w')
pickle.dump(object, file) # pickle to file
file.close( ) # any file-like object will do
def loadDbase(filename):
file = open(filename, 'r')
object = pickle.load(file) # unpickle from file
file.close( ) # recreates object in memory
return object
To store and fetch now, simply call these module functions:
C:\...\PP2E\Dbase>python
>>> from filepickle import *
>>> L = [0]
>>> D = {'x':0, 'y':L}
>>> table = {'A':L, 'B':D} # L appears twice
>>> saveDbase('myfile', table) # serialize to file
C:\...\PP2E\Dbase>python
>>> from filepickle import *
>>> table = loadDbase('myfile') # reload/unpickle
>>> table
{'B': {'x': 0, 'y': [0]}, 'A': [0]}
>>> table['A'][0] = 1
>>> saveDbase('myfile', table)
C:\...\PP2E\Dbase>python
>>> from filepickle import *
>>> print loadDbase('myfile') # both L's updated as expected
{'B': {'x': 0, 'y': [1]}, 'A': [1]}
Python can pickle just about anything, except compiled code objects, instances of classes that do not follow importability rules we'll meet later, and instances of some built-in and user-defined types that are coded in C or depend upon transient operating system states (e.g., open file objects cannot be pickled). A PicklingError is raised if an object cannot be pickled.
Refer to Python's library manual for more information on the pickler. And while you are flipping (or clicking) through that manual, be sure to also see the entries for the cPickle module -- a reimplementation of pickle coded in C for faster performance. Also check out marshal, a module that serializes an object, too, but can only handle simple object types. If available in your Python, the shelve module automatically chooses the cPickle module for faster serialization, not pickle. I haven't explained shelve yet, but I will now.
Pickling allows you to store arbitrary objects on files and file-like objects, but it's still a fairly unstructured medium; it doesn't directly support easy access to members of collections of pickled objects. Higher-level structures can be added, but they are not inherent:
You can sometimes craft your own higher-level pickle file organizations with the underlying filesystem (e.g., you can store each pickled object in a file whose name uniquely identifies the object), but such an organization is not part of pickling itself and must be manually managed.
You can also store arbitrarily large dictionaries in a pickled file and index them by key after they are loaded back into memory; but this will load the entire dictionary all at once when unpickled, not just the entry you are interested in.
Shelves provide some structure to collections of pickled objects. They are a type of file that stores arbitrary Python objects by key for later retrieval, and they are a standard part of the Python system. Really, they are not much of a new topic -- shelves are simply a combination of DBM files and object pickling:
To store an in-memory object by key, the shelve module first serializes the object to a string with the pickle module, and then it stores that string in a DBM file by key with the anydbm module.
To fetch an object back by key, the shelve module first loads the object's serialized string by key from a DBM file with the anydbm module, and then converts it back to the original in-memory object with the pickle module.
Because shelve uses pickle internally, it can store any object that pickle can: strings, numbers, lists, dictionaries, cyclic objects, class instances, and more.
In other words, shelve is just a go-between; it serializes and deserializes objects so that they can be placed in DBM files. The net effect is that shelves let you store nearly arbitrary Python objects on a file by key, and fetch them back later with the same key. Your scripts never see all this interfacing, though. Like DBM files, shelves provide an interface that looks like a dictionary that must be opened. To gain access to a shelve, import the module and open your file:
import shelve
dbase = shelve.open("mydbase")
Internally, Python opens a DBM file with name mydbase, or creates it if it does not yet exist. Assigning to a shelve key stores an object:
dbase['key'] = object
Internally, this assignment converts the object to a serialized byte-stream and stores it by key on a DBM file. Indexing a shelve fetches a stored object:
value = dbase['key']
Internally, this index operation loads a string by key from a DBM file and unpickles it into an in-memory object that is the same as the object originally stored. Most dictionary operations are supported here, too:
len(dbase) # number of items stored dbase.keys( ) # stored item key index
And except for a few fine points, that's really all there is to using a shelve. Shelves are processed with normal Python dictionary syntax, so there is no new database API to learn. Moreover, objects stored and fetched from shelves are normal Python objects; they do not need to be instances of special classes or types to be stored away. That is, Python's persistence system is external to the persistent objects themselves. Table 16-2 summarizes these and other commonly used shelve operations.
|
Python Code |
Action |
Description |
|---|---|---|
|
import shelve |
Import |
Get dbm, gdbm ,... whatever is installed |
|
file = shelve.open('filename') |
Open |
Create or open an existing DBM file |
|
file['key'] = anyvalue |
Store |
Create or change the entry for key |
|
value = file['key'] |
Fetch |
Load the value for entry key |
|
count = len(file) |
Size |
Return the number of entries stored |
|
index = file.keys( ) |
Index |
Fetch the stored keys list |
|
found = file. has_key('key') |
Query |
See if there's an entry for key |
|
del file['key'] |
Delete |
Remove the entry for key |
|
file.close( ) |
Close |
Manual close, not always needed |
Because shelves export a dictionary-like interface, too, this table is almost identical to the DBM operation table. Here, though, the module name anydbm is replaced by shelve, open calls do not require a second c argument, and stored values can be nearly arbitrary kinds of objects, not just strings. You still should close shelves explicitly after making changes to be safe, though; shelves use anydbm internally and some underlying DBMs require closes to avoid data loss or damage.
Let's run an interactive session to experiment with shelve interfaces:
% python
>>> import shelve
>>> dbase = shelve.open("mydbase")
>>> object1 = ['The', 'bright', ('side', 'of'), ['life']]
>>> object2 = {'name': 'Brian', 'age': 33, 'motto': object1}
>>> dbase['brian'] = object2
>>> dbase['knight'] = {'name': 'Knight', 'motto': 'Ni!'}
>>> dbase.close( )
Here, we open a shelve and store two fairly complex dictionary and list data structures away permanently by simply assigning them to shelve keys. Because shelve uses pickle internally, almost anything goes here -- the trees of nested objects are automatically serialized into strings for storage. To fetch them back, just reopen the shelve and index:
% python
>>> import shelve
>>> dbase = shelve.open("mydbase")
>>> len(dbase) # entries
2
>>> dbase.keys( ) # index
['knight', 'brian']
>>> dbase['knight'] # fetch
{'motto': 'Ni!', 'name': 'Knight'}
>>> for row in dbase.keys( ):
... print row, '=>'
... for field in dbase[row].keys( ):
... print ' ', field, '=', dbase[row][field]
...
knight =>
motto = Ni!
name = Knight
brian =>
motto = ['The', 'bright', ('side', 'of'), ['life']]
age = 33
name = Brian
The nested loops at the end of this session step through nested dictionaries -- the outer scans the shelve, and the inner scans the objects stored in the shelve. The crucial point to notice is that we're using normal Python syntax both to store and to fetch these persistent objects as well as to process them after loading.
One of the more useful kinds of objects to store in a shelve is a class instance. Because its attributes record state and its inherited methods define behavior, persistent class objects effectively serve the roles of both database records and database-processing programs. For instance, consider the simple class shown in Example 16-2, which is used to model people.
# a person object: fields + behavior
class Person:
def __init__(self, name, job, pay=0):
self.name = name
self.job = job
self.pay = pay # real instance data
def tax(self):
return self.pay * 0.25 # computed on call
def info(self):
return self.name, self.job, self.pay, self.tax( )
We can make some persistent objects from this class by simply creating instances as usual, and storing them by key on an opened shelve:
C:\...\PP2E\Dbase>python
>>> from person import Person
>>> bob = Person('bob', 'psychologist', 70000)
>>> emily = Person('emily', 'teacher', 40000)
>>>
>>> import shelve
>>> dbase = shelve.open('cast') # make new shelve
>>> for obj in (bob, emily): # store objects
>>> dbase[obj.name] = obj # use name for key
>>> dbase.close( ) # need for bsddb
When we come back and fetch these objects in a later Python session or script, they are recreated in memory as they were when they were stored:
C:\...\PP2E\Dbase>python
>>> import shelve
>>> dbase = shelve.open('cast') # reopen shelve
>>>
>>> dbase.keys( ) # both objects are here
['emily', 'bob']
>>> print dbase['emily']
<person.Person instance at 799940>
>>>
>>> print dbase['bob'].tax( ) # call: bob's tax
17500.0
Notice that calling Bob's tax method works even though we didn't import the Person class here. Python is smart enough to link this object back to its original class when unpickled, such that all the original methods are available through fetched objects.
Technically, Python reimports a class to recreate its stored instances as they are fetched and unpickled. Here's how this works:
When Python pickles a class instance to store it in a shelve, it saves the instance's attributes plus a reference to the instance's class. Really, Python serializes and stores the instance's __dict__ attribute dictionary along with source file information for the class's module.
When Python unpickles a class instance fetched from a shelve, it recreates the instance object in memory by reimporting the class and assigning the saved attribute dictionary to a new empty instance of the class.
The key point in this is that the class itself is not stored with its instances, but is instead reimported later when instances are fetched. The upshot is that by modifying external classes in module files, we can change the way stored objects' data is interpreted and used without actually having to change those stored objects. It's as if the class is a program that processes stored records.
To illustrate, suppose the Person class from the previous section was changed to the source code in Example 16-3.
# a person object: fields + behavior
# change: the tax method is now a computed attribute
class Person:
def __init__(self, name, job, pay=0):
self.name = name
self.job = job
self.pay = pay # real instance data
def __getattr__(self, attr): # on person.attr
if attr == 'tax':
return self.pay * 0.30 # computed on access
else:
raise AttributeError # other unknown names
def info(self):
return self.name, self.job, self.pay, self.tax
This revision has a new tax rate (30%), introduces a __getattr__ qualification overload method, and deletes the original tax method. Tax attribute references are intercepted and computed when accessed:
C:\...\PP2E\Dbase>python
>>> import shelve
>>> dbase = shelve.open('cast') # reopen shelve
>>>
>>> print dbase.keys( ) # both objects are here
['emily', 'bob']
>>> print dbase['emily']
<person.Person instance at 79aea0>
>>>
>>> print dbase['bob'].tax # no need to call tax( )
21000.0
Because the class has changed, tax is now simply qualified, not called. In addition, because the tax rate was changed in the class, Bob pays more this time around. Of course, this example is artificial, but when used well, this separation of classes and persistent instances can eliminate many traditional database update programs -- in most cases, you can simply change the class, not each stored instance, for new behavior.
Although shelves are generally straightforward to use, there are a few rough edges worth knowing about.
First of all, although they can store arbitrary objects, keys must still be strings. The following fails, unless you convert the integer 42 to string "42" manually first:
dbase[42] = value # fails, but str(42) will work
This is different from in-memory dictionaries, which allow any immutable object to be used as a key, and derives from the shelve's use of DBM files internally.
Although the shelve module is smart enough to detect multiple occurrences of a nested object and recreate only one copy when fetched, this only holds true within a given slot:
dbase[key] = [object, object] # okay: only one copy stored and fetched dbase[key1] = object dbase[key2] = object # bad?: two copies of object in the shelve
When key1 and key2 are fetched, they reference independent copies of the original shared object; if that object is mutable, changes from one won't be reflected in the other. This really stems from the fact the each key assignment runs an independent pickle operation -- the pickler detects repeated objects but only within each pickle call. This may or may not be a concern in your practice and can be avoided with extra support logic, but an object can be duplicated if it spans keys.
Because objects fetched from a shelve don't know that they came from a shelve, operations that change components of a fetched object only change the in-memory copy, not the data on a shelve:
dbase[key].attr = value # shelve unchanged
To really change an object stored on a shelve, fetch it into memory, change its parts, and then write it back to the shelve as a whole by key assignment:
object = dbase[key] # fetch it object.attr = value # modify it dbase[key] = object # store back-shelve changed
As we learned near the end of Chapter 14, the shelve module does not currently support simultaneous updates. Simultaneous readers are okay, but writers must be given exclusive access to the shelve. You can trash a shelve if multiple processes write to it at the same time, and this is a common potential in things like CGI server-side scripts. If your shelves may be hit by multiple processes, be sure to wrap updates in calls to the fcntl.flock built-in we explored in Chapter 14.
In addition to these shelve constraints, storing class instances in a shelve adds a set of additional rules you need to be aware of. Really, these are imposed by the pickle module, not shelve, so be sure to follow these if you store class objects with pickle directly, too.
The Python pickler stores instance attributes only when pickling an instance object, and reimports the class later to recreate the instance. Because of that, the classes of stored objects must be importable when objects are unpickled -- they must be coded unnested at the top level of a module file visible on PYTHONPATH. Further, they must be associated with a real module when instances are pickled, not a top-level script (with module name __main__ ), and you need to be careful about moving class modules after instances are stored. When an instance is unpickled, Python must find its class's module on PYTHONPATH using the original module name (including any package path prefixes), and fetch the class from that module using the original class name. If the module or class has been moved or renamed, it might not be found.
Although Python lets you change a class while instances of it are stored on a shelve, those changes must be backwards-compatible with the objects already stored. For instance, you cannot change the class to expect an attribute not associated with already-stored persistent instances unless you first manually update those stored instances or provide extra conversion protocols on the class.
In a prior Python release, persistent object classes also had to either use constructors with no arguments, or they had to provide defaults for all constructor arguments (much like the notion of a C++ copy constructor). This constraint was dropped as of Python 1.5.2 -- classes with non-defaulted constructor arguments now work fine in the pickling system.[2]
In addition to the above constraints, keep in mind that files created by an underlying DBM system are not necessarily compatible with all possible DBM implementations. For instance, a file generated by gdbm may not be readable by a Python with another DBM module installed, unless you explicitly import gdbm instead of anydbm (assuming it's installed at all). If DBM file portability is a concern, make sure that all the Pythons that will read your data use compatible DBM modules.
Finally, although shelves store objects persistently, they are not really object-oriented database systems (OODBs). Such systems also implement features like object decomposition and delayed ("lazy") component fetches, based on generated object IDs: parts of larger objects are loaded into memory only as they are accessed. It's possible to extend shelves to support such features, but you don't need to -- the Zope system described in Chapter 15, includes an implementation of a more complete OODB system. It is constructed on top of Python's built-in persistence support, but offers additional features for advanced data stores. See the previous chapter for information and links.
Shelves are a powerful tool; they allow scripts to throw Python objects on a keyed-access file and load them back later in a single step. They aren't quite a full-blown database system, though; objects (records) are accessed with a single key, and there is no notion of SQL queries. It's as if shelves were a database with a single index and no other query-processing support.
Although it's possible to build a multiple-index interface to store data with multiple shelves, it's not a trivial task and requires manually coded extensions (see the dbaseindexed module in the PyErrata system near the end of Chapter 14 for a prototype of this concept).
For industrial-strength persistence needs, Python also supports relational database systems. Today, there are freely available interfaces that let Python scripts utilize all common database systems, both free and commercial: Oracle, Sybase, Informix, mSql, MySql, Interbase, Postgres, ODBC, and more. In addition, the Python community has defined a database API specification that works portably with a variety of underlying database packages. Scripts written for this API can be migrated to different database vendor packages with minimal or no source code changes.
Unlike all the persistence topics presented in this chapter and book so far, though, SQL databases are optional extensions that are not part of Python itself, and you need to know SQL to make the most sense of their interfaces. Because I don't have space to teach SQL in this text, this section instead gives a brief overview of the API; please consult other SQL references and the database API resources mentioned in the next section for more details.
The good news is that you can access SQL databases from Python, through a straightforward and portable model. The Python database API specification defines an interface for communicating with underlying database systems from Python scripts. Vendor-specific database interfaces for Python may or may not conform to this API completely, but all database extensions for Python seem minor variations on a theme. SQL databases in Python are grounded on a few concepts:
Connection objects represent a connection to a database, are the interface to rollback and commit operations, and generate cursor objects.
Cursor objects represent a single SQL statement submitted as a string, and can be used to step through SQL statement results.
Query results of SQL select statements are returned to scripts as Python lists of Python tuples, representing database tables of rows. Within these row tuples, field values are normal Python objects such as strings, integers, and floats, or special types (e.g., [('bob',38), ('emily',37)]).
Beyond this, the API defines a standard set of database exception types, special database type object constructors (e.g., nulls and dates), and informational calls.
For instance, to establish a database connection under the Python API-compliant Oracle interface available from Digital Creations, install the extension and then run a line of this form:
connobj = Connect("user/password@system")
The string argument's contents may vary per database and vendor, but they generally contain what you provide to log in to your database system. Once you have a connection object, there a variety of things you can do with it, including:
connobj.close( ) close connection now (not at object __del__ time) connobj.commit( ) commit any pending transactions to the database connobj.rollback( ) roll database back to start of pending transactions connobj.getSource(proc) fetch stored procedure's code
But one of the most useful things to do with a connection object is to generate a cursor object:
cursobj = connobj.cursor( ) return a new cursor object for running SQL
Cursor objects have a set of methods, too (e.g., close to close the cursor before its destructor runs), but the most important may be this one:
cursobj.execute(sqlstring [, parm, parm,...]) run SQL query or command string
The execute method can be used to run a variety of SQL statement strings:
DDL definition statements (e.g., CREATE TABLE)
DML modification statements (e.g., UPDATE or INSERT)
DQL query statements (e.g., SELECT)
For DML statements, execute returns the number of rows effected. For DQL query statements, a None is returned and you must call one of the fetch methods to complete the operation:
tuple = cursobj.fetchone( ) fetch next row of a query result
listoftuple = cursobj.fetchmany([size]) fetch next set of rows of query result
listoftuple = cursobj.fetchall( ) fetch all remaining rows of the result
And once you've received fetch method results, table information is processed using normal Python list and tuple object operations (e.g., you can step through the tuples in a fetchall result list with a simple for loop). Most Python database interfaces also allow you to provide values to be passed to SQL statement strings, by providing targets and a tuple of parameters. For instance:
query = 'SELECT name, shoesize FROM spam WHERE job = ? AND age = ?' cursobj.execute(query, (value1, value2)) results = cursobj.fetchall( ) for row in results: ...
In this event, the database interface utilizes prepared statements (an optimization and convenience) and correctly passes the parameters to the database regardless of their Python types. The notation used to code targets in the query string may vary in some database interfaces (e.g., ":p1" and ":p2", rather than "?" and "?"); in any event, this is not the same as Python's "%" string formatting operator.
Finally, if your database supports stored procedures, you can generally call them with the callproc method, or by passing an SQL CALL or EXEC statement string to the execute method; use a fetch variant to retrieve its results.
There is more to database interfaces than the basics just mentioned, but additional API documentation is readily available on the Web. Perhaps the best resource for information about database extensions today is the home page of the Python database special interest group (SIG). Go to http://www.python.org, click on the SIGs link near the top, and navigate to the database group's page (or go straight to http://www.python.org/sigs/db-sig, the page's current address at the time of writing). There, you'll find API documentation, links to database vendor-specific extension modules, and more.
While you're at python.org, be sure to also explore the Gadfly database package -- a Python-specific SQL-based database extension, which sports wide portability, socket connections for client/server modes, and more. Gadfly loads data into memory, so it is currently somewhat limited in scope. On the other hand, it is ideal for prototyping database applications -- you can postpone cutting a check to a vendor until it's time to scale up for deployment. Moreover, Gadfly is suitable by itself for a variety of applications -- not every system needs large data stores, but many can benefit from the power of SQL.
Rather than going into additional database interface details that are freely available at python.org, I'm going to close out this chapter by showing you one way to combine the GUI technology we met earlier in the text with the persistence techniques introduced in this chapter. This section presents PyForm,a Tkinter GUI designed to let you browse and edit tables of records:
Tables browsed are shelves, DBM files, in-memory dictionaries, or any other object that looks and feels like a dictionary.
Records within tables browsed can be class instances, simple dictionaries, strings, or any other object that can be translated to and from a dictionary.
Although this example is about GUIs and persistence, it also illustrates Python design techniques. To keep its implementation both simple and type-independent, the PyForm GUI is coded to expect tables to look like dictionaries of dictionaries. To support a variety of table and record types, PyForm relies on separate wrapper classes to translate tables and records to the expected protocol:
At the top table level, the translation is easy -- shelves, DBM files, and in-memory dictionaries all have the same key-based interface.
At the nested record level, the GUI is coded to assume that stored items have a dictionary-like interface, too, but classes intercept dictionary operations to make records compatible with the PyForm protocol. Records stored as strings are converted to and from the dictionary objects on fetches and stores; records stored as class instances are translated to and from attribute dictionaries. More specialized translations can be added in new table wrapper classes.
The net effect is that PyForm can be used to browse and edit a wide variety of table types, despite its dictionary interface expectations. When PyForm browses shelves and DBM files, table changes made within the GUI are persistent -- they are saved in the underlying files. When used to browse a shelve of class instances, PyForm essentially becomes a GUI frontend to a simple object database, one built using standard Python persistence tools.
Before we get to the GUI, though, let's see why you'd want one in the first place. To experiment with shelves in general, I first coded a canned test data file. The script in Example 16-4 hardcodes a dictionary used to populate databases (cast), as well as a class used to populate shelves of class instances (Actor).
# definitions for testing shelves, dbm, and formgui
cast = {
'rob': {'name': ('Rob', 'P'), 'job': 'writer', 'spouse': 'Laura'},
'buddy': {'name': ('Buddy', 'S'), 'job': 'writer', 'spouse': 'Pickles'},
'sally': {'name': ('Sally', 'R'), 'job': 'writer'},
'laura': {'name': ('Laura', 'P'), 'spouse': 'Rob', 'kids':1},
'milly': {'name': ('Milly', '?'), 'spouse': 'Jerry', 'kids':2},
'mel': {'name': ('Mel', 'C'), 'job': 'producer'},
'alan': {'name': ('Alan', 'B'), 'job': 'comedian'}
}
class Actor: # unnested file-level class
def __init__(self, name=( ), job=''): # no need for arg defaults,
self.name = name # for new pickler or formgui
self.job = job
def __setattr__(self, attr, value): # on setattr( ): validate
if attr == 'kids' and value > 10: # but set it regardless
print 'validation error: kids =', value
if attr == 'name' and type(value) != type(( )):
print 'validation error: name type =', type(value)
self.__dict__[attr] = value # don't trigger __setattr__
The cast object here is intended to represent a table of records (it's really a dictionary of dictionaries when written out in Python syntax like this). Now, given this test data, it's easy to populate a shelve with cast dictionaries. Simply open a shelve and copy over cast, key for key, as shown in Example 16-5.
import shelve
from testdata import cast
db = shelve.open('data/castfile') # create a new shelve
for key in cast.keys( ):
db[key] = cast[key] # store dictionaries in shelve
Once you've done that, it's almost as easy to verify your work with a script that prints the contents of the shelve, as shown in Example 16-6.
import shelve
db = shelve.open('data/castfile') # reopen shelve
for key in db.keys( ): # show each key,value
print key, db[key]
Here are these two scripts in action, populating and displaying a shelve of dictionaries:
C:\...\PP2E\Dbase>python castinit.py
C:\...\PP2E\Dbase>python castdump.py
alan {'job': 'comedian', 'name': ('Alan', 'B')}
mel {'job': 'producer', 'name': ('Mel', 'C')}
buddy {'spouse': 'Pickles', 'job': 'writer', 'name': ('Buddy', 'S')}
sally {'job': 'writer', 'name': ('Sally', 'R')}
rob {'spouse': 'Laura', 'job': 'writer', 'name': ('Rob', 'P')}
milly {'spouse': 'Jerry', 'name': ('Milly', '?'), 'kids': 2}
laura {'spouse': 'Rob', 'name': ('Laura', 'P'), 'kids': 1}
So far, so good. But here is where you reach the limitations of manual shelve processing: to modify a shelve, you need much more general tools. You could write little Python scripts that each perform very specific updates. Or you might even get by for awhile typing such update commands by hand in the interactive interpreter:
>>> import shelve
>>> db = shelve.open('data/castfile')
>>> rec = db['rob']
>>> rec['job'] = 'hacker'
>>> db['rob'] = rec
For all but the most trivial databases, though, this will get tedious in a hurry -- especially for a system's end users. What you'd really like is a GUI that lets you view and edit shelves arbitrarily, and can be started up easily from other programs and scripts, as shown in Example 16-7.
import shelve
from TableBrowser.formgui import FormGui # after initcast
db = shelve.open('data/castfile') # reopen shelve file
FormGui(db).mainloop( ) # browse existing shelve-of-dicts
To make this particular script work, we need to move on to the next section.
The path traced in the last section really is what led me to write PyForm, a GUI tool for editing arbitrary tables of records. When those tables are shelves and DBM files, the data PyForm displays is persistent; it lives beyond the GUI's lifetime. Because of that, PyForm can be seen as a simple database browser.
We've already met all the GUI interfaces PyForm uses earlier in this book, so I won't go into all of its implementation details here (see the chapters in Part II, for background details). Before we see the code at all, though, let's see what it does. Figure 16-1 shows PyForm in action on Windows, browsing a shelve of persistent instance objects, created from the testdata module's Actor class. It looks slightly different but works the same on Linux and Macs.
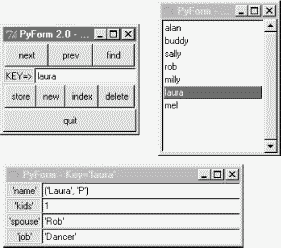
PyForm uses a three-window interface to the table being browsed; all windows are packed for proper window expansion and clipping, as set by the rules we studied earlier in this book. The window in the upper left of Figure 16-1 is the main window, created when PyForm starts; it has buttons for navigating through a table, finding items by key, and updating, creating, and deleting records (more useful when browsing tables that persist between runs). The table (dictionary) key of the record currently displayed shows up in the input field in the middle of this window.
The "index" button pops up the listbox window in the upper right, and selecting a record in either window at the top creates the form window at the bottom. The form window is used both to display a record and to edit it -- if you change field values and press "store," the record is updated. Pressing "new" clears the form for input of new values (fill in the "Key=>" field and press "store" to save the new record).
Field values are typed with Python syntax, so strings are quoted (more on this later). When browsing a table with records that contain different sets of field names, PyForm erases and redraws the form window for new field sets as new records are selected; to avoid seeing the window recreated, use the same format for all records within a given table.
On to the code. The first thing I did when writing PyForm was to code utility functions to hide some of the details of widget creation. By making a few simplifying assumptions (e.g., packing protocol), the module in Example 16-8 helps keep some GUI coding details out of the rest of the PyForm implementation.
# added extras for entry width, calcgui font/color
from Tkinter import *
def frame(root, side, **extras):
widget = Frame(root)
widget.pack(side=side, expand=YES, fill=BOTH)
if extras: apply(widget.config, ( ), extras)
return widget
def label(root, side, text, **extras):
widget = Label(root, text=text, relief=RIDGE)
widget.pack(side=side, expand=YES, fill=BOTH)
if extras: apply(widget.config, ( ), extras)
return widget
def button(root, side, text, command, **extras):
widget = Button(root, text=text, command=command)
widget.pack(side=side, expand=YES, fill=BOTH)
if extras: apply(widget.config, ( ), extras)
return widget
def entry(root, side, linkvar, **extras):
widget = Entry(root, relief=SUNKEN, textvariable=linkvar)
widget.pack(side=side, expand=YES, fill=BOTH)
if extras: apply(widget.config, ( ), extras)
return widget
Armed with this utility module, the file in Example 16-9 implements the rest of the PyForm GUI. It uses the GuiMixin module we wrote in Chapter 9, for simple access to standard popup dialogs. It's also coded as a class that can be specialized in subclasses, or attached to a larger GUI. I run PyForm as a standalone program. Attaching its FormGui class really attaches its main window only, but it can be used to provide a pre-coded table browser widget for other GUIs.
This file's FormGui class creates the GUI shown in Figure 16-1, and responds to user interaction in all three of the interface's windows. Because we've already covered all the GUI tools that PyForm uses, you should study this module's source code listing for additional implementation details. Notice, though, that this file knows almost nothing about the table being browsed, other than that it looks and feels like a dictionary of dictionaries. To understand how PyForm supports browsing things like shelves of class instances, you will need to look elsewhere (or at least wait for the next module).
#!/usr/local/bin/python
#############################################################################
# PyForm: a persistent table viewer GUI. Uses guimixin for std dialogs.
# Assumes the browsed table has a dictionary-of-dictionary interface, and
# relies on table wrapper classes to convert other structures as needed.
# Store an initial record with dbinit script to start a dbase from scratch.
# Caveat: doesn't do object method calls, shows complex field values poorly.
#############################################################################
from Tkinter import * # Tk widgets
from guitools import frame, label, button, entry # widget builders
from PP2E.Gui.Tools.guimixin import GuiMixin # common methods
class FormGui(GuiMixin, Frame):
def __init__(self, mapping): # an extended frame
Frame.__init__(self) # on default top-level
self.pack(expand=YES, fill=BOTH) # all parts expandable
self.master.title('PyForm 2.0 - Table browser')
self.master.iconname("PyForm")
self.makeMainBox( )
self.table = mapping # a dict, dbm, shelve, Table,..
self.index = mapping.keys( ) # list of table keys
self.cursor = -1 # current index position
self.currslots = [] # current form's (key,text)s
self.currform = None # current form window
self.listbox = None # index listbox window
def makeMainBox(self):
frm = frame(self, TOP)
frm.config(bd=2)
button(frm, LEFT, 'next', self.onNext) # next in list
button(frm, LEFT, 'prev', self.onPrev) # backup in list
button(frm, LEFT, 'find', self.onFind) # find from key
frm = frame(self, TOP)
self.keytext = StringVar( ) # current record's key
label(frm, LEFT, 'KEY=>') # change before 'find'
entry(frm, LEFT, self.keytext)
frm = frame(self, TOP)
frm.config(bd=2)
button(frm, LEFT, 'store', self.onStore) # updated entry data
button(frm, LEFT, 'new', self.onNew) # clear fields
button(frm, LEFT, 'index', self.onMakeList) # show key list
button(frm, LEFT, 'delete', self.onDelete) # show key list
button(self, BOTTOM,'quit', self.quit) # from guimixin
def onPrev(self):
if self.cursor <= 0:
self.infobox('Backup', "Front of table")
else:
self.cursor = self.cursor - 1
self.display( )
def onNext(self):
if self.cursor >= len(self.index)-1:
self.infobox('Advance', "End of table")
else:
self.cursor = self.cursor + 1
self.display( )
def sameKeys(self, record): # can we reuse the same form?
keys1 = record.keys( )
keys2 = map(lambda x:x[0], self.currslots)
keys1.sort(); keys2.sort( ) # keys list order differs
return keys1 == keys2 # if insertion-order differs
def display(self):
key = self.index[self.cursor] # show record at index cursor
self.keytext.set(key) # change key in main box
record = self.table[key] # in dict, dbm, shelf, class
if self.sameKeys(record):
self.currform.title('PyForm - Key=' + `key`)
for (field, text) in self.currslots:
text.set(`record[field]`) # same fields? reuse form
else: # expr `x` works like repr(x)
if self.currform:
self.currform.destroy( ) # different fields?
new = Toplevel( ) # replace current box
new.title('PyForm - Key=' + `key`) # new resizable window
new.iconname("pform")
left = frame(new, LEFT)
right = frame(new, RIGHT)
self.currslots = [] # list of (field, entry)
for field in record.keys( ):
label(left, TOP, `field`) # key,value to strings
text = StringVar( ) # we could sort keys here
text.set( `record[field]` )
entry(right, TOP, text, width=40)
self.currslots.append((field, text))
self.currform = new
new.protocol('WM_DELETE_WINDOW', lambda:0) # ignore destroy's
self.selectlist( ) # update listbox
def onStore(self):
if not self.currform: return
key = self.keytext.get( )
if key in self.index: # change existing record
record = self.table[key] # not: self.table[key][field]=
else:
record = {} # create a new record
self.index.append(key) # add to index and listbox
if self.listbox:
self.listbox.insert(END, key) # or at len(self.index)-1
for (field, text) in self.currslots:
try: # fill out dictionary rec
record[field] = eval(text.get( )) # convert back from string
except:
self.errorbox('Bad data: "%s" = "%s"' % (field, text.get( )))
record[field] = None
self.table[key] = record # add to dict, dbm, shelf,...
self.onFind(key) # readback: set cursor,listbox
def onNew(self):
if not self.currform: return # clear input form and key
self.keytext.set('?%d' % len(self.index)) # default key unless typed
for (field, text) in self.currslots: # clear key/fields for entry
text.set('')
self.currform.title('Key: ?')
def onFind(self, key=None):
target = key or self.keytext.get( ) # passed in, or entered
try:
self.cursor = self.index.index(target) # find label in keys list
self.display( )
except:
self.infobox('Not found', "Key doesn't exist", 'info')
def onDelete(self):
if not self.currform or not self.index: return
currkey = self.index[self.cursor]
del self.table[currkey] # table, index, listbox
del self.index[self.cursor:self.cursor+1] # like "list[i:i+1] = []"
if self.listbox:
self.listbox.delete(self.cursor) # delete from listbox
if self.cursor < len(self.index):
self.display( ) # show next record if any
elif self.cursor > 0:
self.cursor = self.cursor-1 # show prior if delete end
self.display( )
else: # leave box if delete last
self.onNew( )
def onList(self,evnt):
if not self.index: return # on listbox double-click
index = self.listbox.curselection( ) # fetch selected key text
label = self.listbox.get(index) # or use listbox.get(ACTIVE)
self.onFind(label) # and call method here
def onMakeList(self):
if self.listbox: return # already up?
new = Toplevel( ) # new resizable window
new.title("PyForm - Key Index") # select keys from a listbox
new.iconname("pindex")
frm = frame(new, TOP)
scroll = Scrollbar(frm)
list = Listbox(frm, bg='white')
scroll.config(command=list.yview, relief=SUNKEN)
list.config(yscrollcommand=scroll.set, relief=SUNKEN)
scroll.pack(side=RIGHT, fill=BOTH)
list.pack(side=LEFT, expand=YES, fill=BOTH) # pack last, clip first
for key in self.index: # add to list-box
list.insert(END, key) # or: sort list first
list.config(selectmode=SINGLE, setgrid=1) # select,resize modes
list.bind('<Double-1>', self.onList) # on double-clicks
self.listbox = list
if self.index and self.cursor >= 0: # highlight position
self.selectlist( )
new.protocol('WM_DELETE_WINDOW', lambda:0) # ignore destroy's
def selectlist(self): # listbox tracks cursor
if self.listbox:
self.listbox.select_clear(0, self.listbox.size( ))
self.listbox.select_set(self.cursor)
if __name__ == '__main__':
from PP2E.Dbase.testdata import cast # self-test code
for k in cast.keys( ): print k, cast[k] # view in-memory dict-of-dicts
FormGui(cast).mainloop( )
for k in cast.keys( ): print k, cast[k] # show modified table on exit
The file's self-test code starts up the PyForm GUI to browse the in-memory dictionary of dictionaries called cast in the testdata module listed earlier. To start PyForm, you simply make and run the FormGui class object this file defines, passing in the table to be browsed. Here are the messages that show up in stdout after running this file and editing a few entries displayed in the GUI; the dictionary is displayed on GUI startup and exit:
C:\...\PP2E\Dbase\TableBrowser>python formgui.py
alan {'job': 'comedian', 'name': ('Alan', 'B')}
sally {'job': 'writer', 'name': ('Sally', 'R')}
rob {'spouse': 'Laura', 'job': 'writer', 'name': ('Rob', 'P')}
mel {'job': 'producer', 'name': ('Mel', 'C')}
milly {'spouse': 'Jerry', 'name': ('Milly', '?'), 'kids': 2}
buddy {'spouse': 'Pickles', 'job': 'writer', 'name': ('Buddy', 'S')}
laura {'spouse': 'Rob', 'name': ('Laura', 'P'), 'kids': 1}
alan {'job': 'comedian', 'name': ('Alan', 'B')}
jerry {'spouse': 'Milly', 'name': 'Jerry', 'kids': 0}
sally {'job': 'writer', 'name': ('Sally', 'R')}
rob {'spouse': 'Laura', 'job': 'writer', 'name': ('Rob', 'P')}
mel {'job': 'producer', 'name': ('Mel', 'C')}
milly {'spouse': 'Jerry', 'name': ('Milly', '?'), 'kids': 2}
buddy {'spouse': 'Pickles', 'job': 'writer', 'name': ('Buddy', 'S')}
laura {'name': ('Laura', 'P'), 'kids': 3, 'spouse': 'bob'}
The last line (in bold) represents a change made in the GUI. Since this is an in-memory table, changes made in the GUI are not retained (dictionaries are not persistent by themselves). To see how to use the PyForm GUI on persistent stores like DBM files and shelves, we need to move on to the next topic.
The following file defines generic classes that "wrap" (interface with) various kinds of tables for use in PyForm. It's what makes PyForm useful for a variety of table types.
The prior module was coded to handle GUI chores, and assumes that tables expose a dictionary-of-dictionaries interface. Conversely, this next module knows nothing about the GUI, but provides the translations necessary to browse non-dictionary objects in PyForm. In fact, this module doesn't even import Tkinter at all -- it strictly deals in object protocol conversions and nothing else. Because PyForm's implementation is divided into functionally distinct modules like this, it's easier to focus on each module's task in isolation.
Here is the hook between the two modules: for special kinds of tables, PyForm's FormGui is passed an instance of the Table class coded here. The Table class intercepts table index fetch and assignment operations, and uses an embedded record wrapper class to convert records to and from dictionary format as needed.
For example, because DBM files can store only strings, Table converts real dictionaries to and from their printable string representation on table stores and fetches. For class instances, Table extracts the object's __dict__ attribute dictionary on fetches, and copies a dictionary's fields to attributes of a newly generated class instance on stores.[3] The end result is that the GUI thinks the table is all dictionaries, even if it is really something very different here.
While you study this module's listing, shown in Example 16-10, notice that there is nothing here about the record formats of any particular database. In fact, there was none in the GUI-related formgui module either. Because neither module cares about the structure of fields used for database records, both can be used to browse arbitrary records.
#############################################################################
# PyForm table wrapper classes and tests
# Because PyForm assumes a dictionary-of-dictionary interface, this module
# converts strings and class instance records to and from dicts. PyForm
# contains the table mapping--Table is not a PyForm subclass. Note that
# some of the wrapper classes may be useful outside PyForm--DmbOfString can
# wrap a dbm containing arbitrary datatypes. Run the dbinit scripts to
# start a new database from scratch, and run the dbview script to browse
# a database other than the one tested here. No longer requires classes to
# have defaults in constructor args, and auto picks up record class from the
# first one fetched if not passed in to class-record wrapper. Caveat: still
# assumes that all instances in a table are instances of the same class.
############################################################################
#############################################################################
# records within tables
#############################################################################
class DictionaryRecord:
def todict(self, value):
return value # to dictionary: no need to convert
def fromdict(self, value):
return value # from dictionary: no need to convert
class StringRecord:
def todict(self, value):
return eval(value) # convert string to dictionary (or any)
def fromdict(self, value):
return str(value) # convert dictionary (or any) to string
class InstanceRecord:
def __init__(self, Class=None): # need class object to make instances
self.Class = Class
def todict(self, value): # convert instance to attr dictionary
if not self.Class: # get class from obj if not yet known
self.Class = value.__class__
return value.__dict__
def fromdict(self, value): # convert attr dictionary to instance
try:
class Dummy: pass # try what new pickle does
instance = Dummy( ) # fails in restricted mode
instance.__class__ = self.Class
except: # else call class, no args
instance = self.Class( ) # init args need defaults
for attr in value.keys( ):
setattr(instance, attr, value[attr]) # set instance attributes
return instance # may run Class.__setattr__
#############################################################################
# table containing records
#############################################################################
class Table:
def __init__(self, mapping, converter): # table object, record converter
self.table = mapping # wrap arbitrary table mapping
self.record = converter # wrap arbitrary record types
def storeItems(self, items): # initialize from dictionary
for key in items.keys( ): # do __setitem__ to xlate, store
self[key] = items[key]
def printItems(self): # print wrapped mapping
for key in self.keys( ): # do self.keys to get table keys
print key, self[key] # do __getitem__ to fetch, xlate
def __getitem__(self, key): # on tbl[key] index fetch
rawval = self.table[key] # fetch from table mapping
return self.record.todict(rawval) # translate to dictionary
def __setitem__(self, key, value): # on tbl[key]=val index assign
rawval = self.record.fromdict(value) # translate from dictionary
self.table[key] = rawval # store in table mapping
def __delitem__(self, key): # delete from table mapping
del self.table[key]
def keys(self): # get table mapping keys index
return self.table.keys( )
def close(self):
if hasattr(self.table, 'close'): # call table close if has one
self.table.close( ) # may need for shelves, dbm
#############################################################################
# table/record combinations
#############################################################################
import shelve, anydbm
def ShelveOfInstance(filename, Class=None):
return Table(shelve.open(filename), InstanceRecord(Class))
def ShelveOfDictionary(filename):
return Table(shelve.open(filename), DictionaryRecord( ))
def ShelveOfString(filename):
return Table(shelve.open(filename), StringRecord( ))
def DbmOfString(filename):
return Table(anydbm.open(filename, 'c'), StringRecord( ))
def DictOfInstance(dict, Class=None):
return Table(dict, InstanceRecord(Class))
def DictOfDictionary(dict):
return Table(dict, DictionaryRecord( ))
def DictOfString(filename):
return Table(dict, StringRecord( ))
ObjectOfInstance = DictOfInstance # other mapping objects
ObjectOfDictionary = DictOfDictionary # classes that look like dicts
ObjectOfString = DictOfString
#############################################################################
# test common applications
#############################################################################
if __name__ == '__main__':
from sys import argv
from formgui import FormGui # get dict-based gui
from PP2E.Dbase.testdata import Actor, cast # get class, dict-of-dicts
TestType = 'shelve' # shelve, dbm, dict
TestInit = 0 # init file on startup?
TestFile = '../data/shelve1' # external filename
if len(argv) > 1: TestType = argv[1]
if len(argv) > 2: TestInit = int(argv[2])
if len(argv) > 3: TestFile = argv[3]
if TestType == 'shelve': # python formtbl.py shelve?
print 'shelve-of-instance test'
table = ShelveOfInstance(TestFile, Actor) # wrap shelf in Table object
if TestInit:
table.storeItems(cast) # python formtbl.py shelve 1
FormGui(table).mainloop( )
table.close( )
ShelveOfInstance(TestFile).printItems( ) # class picked up on fetch
elif TestType == 'dbm': # python formtbl.py dbm
print 'dbm-of-dictstring test'
table = DbmOfString(TestFile) # wrap dbm in Table object
if TestInit:
table.storeItems(cast) # python formtbl.py dbm 1
FormGui(table).mainloop( )
table.close( )
DbmOfString(TestFile).printItems( ) # dump new table contents
Besides the Table and record-wrapper classes, the module defines generator functions (e.g., ShelveOfInstance) that create a Table for all reasonable table and record combinations. Not all combinations are valid; DBM files, for example, can only contain dictionaries coded as strings, because class instances don't easily map to the string value format expected by DBM. However, these classes are flexible enough to allow additional Table configurations to be introduced.
The only thing that is GUI-related about this file at all is its self-test code at the end. When run as a script, this module starts a PyForm GUI to browse and edit either a shelve of persistent Actor class instances or a DBM file of dictionaries, by passing in the right kind of Table object. The GUI looks like the one we saw in Figure 16-1 earlier; when run without arguments, the self-test code lets you browse a shelve of class instances:
C:\...\PP2E\Dbase\TableBrowser>python formtable.py shelve-of-instance test ...display of contents on exit...
Because PyForm displays a shelve this time, any changes you make are retained after the GUI exits. To reinitialize the shelve from the cast dictionary in testdata, pass a second argument of "1" ("0" means don't reinitialize the shelve). To override the script's default shelve filename, pass a different name as a third argument:
C:\...\PP2E\Dbase\TableBrowser>python formtable.py shelve 1 C:\...\PP2E\Dbase\TableBrowser>python formtable.py shelve 0 ../data/shelve1
To instead test PyForm on a DBM file of dictionaries mapped to strings, pass a dbm in the first command-line argument; the next two arguments work the same:
C:\...\PP2E\Dbase\TableBrowser>python formtable.py dbm 1 ..\data\dbm1 dbm-of-dictstring test ...display of contents on exit...
Finally, because these self-tests ultimately process concrete shelve and DBM files, you can manually open and inspect their contents using normal library calls. Here is what they look like when opened in an interactive session:
C:\...\PP2E\Dbase\data>ls
dbm1 myfile shelve1
C:\...\PP2E\Dbase\data>python
>>> import shelve
>>> db = shelve.open('shelve1')
>>> db.keys( )
['alan', 'buddy', 'sally', 'rob', 'milly', 'laura', 'mel']
>>> db['laura']
<PP2E.Dbase.testdata.Actor instance at 799850>
>>> import anydbm
>>> db = anydbm.open('dbm1')
>>> db.keys( )
['alan', 'mel', 'buddy', 'sally', 'rob', 'milly', 'laura']
>>> db['laura']
"{'name': ('Laura', 'P'), 'kids': 2, 'spouse': 'Rob'}"
The shelve file contains real Actor class instance objects, and the DBM file holds dictionaries converted to strings. Both formats are retained in these files between GUI runs and are converted back to dictionaries for later redisplay.[4]
The formtable module's self-test code proves that it works, but it is limited to canned test case files and classes. What about using PyForm for other kinds of databases that store more useful kinds of data?
Luckily, both the formgui and formtable modules are written to be generic -- they are independent of a particular database's record format. Because of that, it's easy to point PyForm to databases of your own; simply import and run the FormGui object with the (possibly wrapped) table you wish to browse.
The required startup calls are not too complex, and you could type them at the interactive prompt every time you want to browse a database; but it's usually easier to store them in scripts so they can be reused. The script in Example 16-11, for example, can be run to open PyForm on any shelve containing records stored in class instance or dictionary format.
##################################################################
# view any existing shelve directly; this is more general than a
# "formtable.py shelve 1 filename" cmdline--only works for Actor;
# pass in a filename (and mode) to use this to browse any shelve:
# formtable auto picks up class from the first instance fetched;
# run dbinit1 to (re)initialize dbase shelve with a template.
##################################################################
from sys import argv
from formtable import *
from formgui import FormGui
mode = 'class'
file = '../data/mydbase-' + mode
if len(argv) > 1: file = argv[1] # dbview.py file? mode??
if len(argv) > 2: mode = argv[2]
if mode == 'dict':
table = ShelveOfDictionary(file) # view dictionaries
else:
table = ShelveOfInstance(file) # view class objects
FormGui(table).mainloop( )
table.close( ) # close needed for some dbm
The only catch here is that PyForm doesn't handle completely empty tables very well; there is no way to add new records within the GUI unless a record is already present. That is, PyForm has no record layout design tool; its "new" button simply clears an existing input form.
Because of that, to start a new database from scratch, you need to add an initial record that gives PyForm the field layout. Again, this requires only a few lines of code that could be typed interactively, but why not instead put it in generalized scripts for reuse? The file in Example 16-12, shows one way to go about initializing a PyForm database with a first empty record.
######################################################################
# store a first record in a new shelve to give initial fields list;
# PyForm GUI requires an existing record before you can more records;
# delete the '?' key template record after real records are added;
# change mode, file, template to use this for other kinds of data;
# if you populate shelves from other data files you don't need this;
# see dbinit2 for object-based version, and dbview to browse shelves.
######################################################################
import os
from sys import argv
mode = 'class'
file = '../data/mydbase-' + mode
if len(argv) > 1: file = argv[1] # dbinit1.py file? mode??
if len(argv) > 2: mode = argv[2]
try:
os.remove(file) # delete if present
except: pass
if mode == 'dict':
template = {'name': None, 'age': None, 'job': None} # start dict shelve
else:
from PP2E.Dbase.person import Person # one arg defaulted
template = Person(None, None) # start object shelve
import shelve
dbase = shelve.open(file) # create it now
dbase['?empty?'] = template
dbase.close( )
Now, simply change some of this script's settings or pass in command-line arguments to generate a new shelve-based database for use in PyForm. You can substitute any fields list or class name in this script to maintain a simple object database with PyForm that keeps track of real-world information (we'll see two such databases in action in a moment). The empty record shows up with key "?empty?" when you first browse the database with dbview; replace it with a first real record using the PyForm "store" key, and you are in business. As long as you don't change the database's shelve outside of the GUI, all its records will have the same fields format, as defined in the initialization script.
But notice that the dbinit1 script goes straight to the shelve file to store the first record; that's fine today, but might break if PyForm is ever changed to do something more custom with its stored data representation. Perhaps a better way to populate tables outside the GUI is to use the Table wrapper classes it employs. The following alternative script, for instance, initializes a PyForm database with generated Table objects, not direct shelve operations (see Example 16-13).
#################################################################
# this works too--based on Table objects not manual shelve ops;
# store a first record in shelve, as required by PyForm GUI.
#################################################################
from formtable import *
import sys, os
mode = 'dict'
file = '../data/mydbase-' + mode
if len(sys.argv) > 1: file = sys.argv[1]
if len(sys.argv) > 2: mode = sys.argv[2]
try:
os.remove(file)
except: pass
if mode == 'dict':
table = ShelveOfDictionary(file)
template = {'name': None, 'shoesize': None, 'language': 'Python'}
else:
from PP2E.Dbase.person import Person
table = ShelveOfInstance(file, Person)
template = Person(None, None).__dict__
table.storeItems({'?empty?': template})
table.close( )
Let's put these scripts to work to initialize and edit a couple of custom databases. Figure 16-2 shows one being browsed after initializing the database with a script, and adding a handful of real records within the GUI.
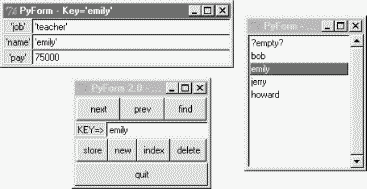
The listbox here shows the record I added to the shelve within the GUI. I ran the following commands to initialize the database with a starter record and open it in PyForm to add records (that is, Person class instances):
C:\...\PP2E\Dbase\TableBrowser>python dbinit1.py C:\...\PP2E\Dbase\TableBrowser>python dbview.py
You can tweak the class name or fields dictionary in the dbinit scripts to initialize records for any sort of database you care to maintain with PyForm; use dictionaries if you don't want to represent persistent objects with classes (but classes let you add other sorts of behavior as methods not visible under PyForm). Be sure to use a distinct filename for each database; the initial "?empty?" record can be deleted as soon as you add a real entry (later, simply select an entry from the listbox and press "new" to clear the form for input of a new record's values).
The data displayed in the GUI represents a true shelve of persistent Person class instance objects -- changes and additions made in the GUI will be retained for the next time you view this shelve with PyForm. If you like to type, though, you can still open the shelve directly to check PyForm's work:
C:\...\PP2E\Dbase\data>ls
mydbase-class myfile shelve1
C:\...\PP2E\Dbase\data>python
>>> import shelve
>>> db = shelve.open('mydbase-class')
>>> db.keys( )
['emily', 'jerry', '?empty?', 'bob', 'howard']
>>> db['bob']
<PP2E.Dbase.person.Person instance at 798d70>
>>> db['emily'].job
'teacher'
>>> db['bob'].tax
30000.0
Notice that "bob" is an instance of the Person class we met earlier in this chapter (see the shelve section). Assuming that the person module is still the version that introduced a __getattr__ method, asking for a shelved object's tax attribute computes a value on the fly, because this really invokes a class method. Also note that this works even though Person was never imported here -- Python loads the class internally when recreating its shelved instances.
You can just as easily base a PyForm-compatible database on an internal dictionary structure, instead of classes. Figure 16-3 shows one being browsed, after being initialized with a script and populated with the GUI.
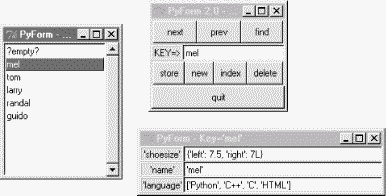
Besides its different internal format, this database has a different record structure (its record's field names differ from the last example), and it is stored in a shelve file of its own. Here are the commands I used to initialize and edit this database:
C:\...\PP2E\Dbase\TableBrowser>python dbinit2.py ../data/mydbase-dict dict C:\...\PP2E\Dbase\TableBrowser>python dbview.py ../data/mydbase-dict dict
After adding a few records (that is, dictionaries) to the shelve, you can either view them again in PyForm or open the shelve manually to verify PyForm's work:
C:\...\PP2E\Dbase\data>ls
mydbase-class mydbase-dict myfile shelve1
C:\...\PP2E\Dbase\data>python
>>> db = shelve.open('mydbase-dict')
>>> db.keys( )
['tom', 'guido', '?empty?', 'larry', 'randal', 'mel']
>>> db['guido']
{'shoesize': 42, 'name': 'benevolent dictator', 'language': 'Python'}
>>> db['mel']['shoesize']
{'left': 7.5, 'right': 7L}
This time, shelve entries are really dictionaries, not instances of a class or converted strings. PyForm doesn't care, though -- because all tables are wrapped to conform to PyForm's interface, both formats look the same when browsed in the GUI.
Notice that the "shoe size" and "language" fields in this screen shot really are a dictionary and list. You can type any Python expression syntax into this GUI's form fields to give values (that's why strings are quoted there). PyForm uses the Python backquotes expression to convert value objects for display (`x` is like repr(x), which is like str(x), but quotes are added around strings). To convert from a string back to value objects, PyForm uses the Python eval function to parse and evaluate the code typed in fields. The key entry/display field in the main window does not add or accept quotes around the key string, because keys must still be strings in things like shelves (even though fields can be arbitrary types).
|
Although PyForm expects to find a dictionary-of-dictionary interface (protocol) in the tables it browses, a surprising number of objects fit this mold because dictionaries are so pervasive in Python object internals. In fact, PyForm can be used to browse things that have nothing to do with the notion of database tables of records at all, as long as they can be made to conform to the protocol.
For instance, the Python sys.modules table we met in Chapter 2 is a built-in dictionary of loaded module objects. With an appropriate wrapper class to make modules look like dictionaries, there's no reason we can't browse the in-memory sys.modules with PyForm too, as shown in Example 16-14.
# view the sys.modules table in FormGui
class modrec:
def todict(self, value):
return value.__dict__ # not dir(value): need dict
def fromdict(self, value):
assert 0, 'Module updates not supported'
import sys
from formgui import FormGui
from formtable import Table
FormGui(Table(sys.modules, modrec())).mainloop( )
This script defines a class to pull out a module's __dict__ attribute dictionary (formtable's InstanceRecord won't do, because it also looks for a __class__ ). The rest of it simply passes sys.modules to PyForm (FormGui) wrapped in a Table object; the result appears in Figure 16-4.
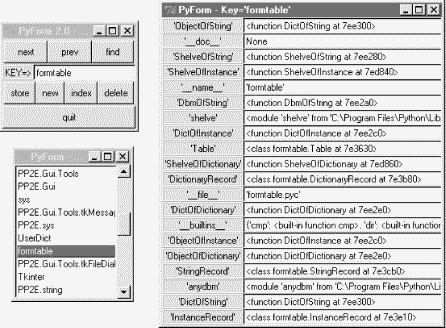
With similar record and table wrappers, all sorts of objects could be viewed in PyForm. As usual in Python, all that matters is that they provide a compatible interface.
Although the sys.modules viewer script works, it also highlights a few limitations of PyForm's current design:
PyForm is set up to handle a two-dimensional table/record mapping structure only. You can't descend further into fields shown in the form, large data structures in fields print as long strings, and complex objects like nested modules, classes, and functions that contain attributes of their own simply show their default print representation. We could add object viewers to inspect nested objects interactively, but they might be complex to code.
PyForm is not equipped to handle a large number of record fields -- if you select the os module's entry in the index listbox in Figure 16-4, you'll get a huge form that is likely too big to even fit on your screen (the os module has lots and lots of attributes; it goes off my screen after about 40). We could fix this with a scrollbar, but it's unlikely that records in the databases that PyForm was designed to view will have many dozens of fields.
PyForm displays record attribute values, but does not support calling method functions of objects being browsed, and cannot display dynamically computed attributes (e.g., the tax attribute in Person objects).
PyForm currently assumes all instances in a table are of the same class, even though that's not a requirement for shelves in general.
In other words, there is room for improvement if you care to experiment. There are other coding styles you might wish to explore, as well. For instance, PyForm current overloads table index fetch and assignment, and the GUI uses dictionaries to represent records internally. It would be almost as easy to overload record field index fetch and assignment instead, and add a Table method for creating a new empty record. In this scheme, records held in PyForm would be whatever object the table stores (not dictionaries), and each field fetch or assignment in PyForm would be routed back to record wrapper classes. The downside of this approach is that PyForm could not browse any object unless it is wrapped in a Table. Raw dictionaries would not work, because they have no method for making new empties. Moreover, DBM files that map whole records to strings might need extra logic to handle field-at-a-time requests.
On the other hand, extensions in this domain are somewhat open-ended, so we'll leave them as suggested exercises. PyForm was never meant to be a general Python object viewer. But as a simple GUI interface to tables of persistent objects, it meets its design goals as planned. Python's shelves and classes make such systems both easy to code and powerful to use. Complex data can be stored and fetched in a single step, and augmented with methods that provide dynamic record behavior. As an added bonus, by programming such programs in Python and Tkinter, they are automatically portable among all major GUI platforms. When you mix Python persistence and GUIs, you get a lot of features "for free."
[1] In Python versions 1.5.2 and later, be sure to pass a string c as a second argument when calling anydbm.open, to force Python to create the file if it does not yet exist, and simply open it otherwise. This used to be the default behavior but is no longer. You do not need the c argument when opening shelves discussed ahead -- they still use an "open or create" mode by default if passed no open mode argument. Other open mode strings can be passed to anydbm (e.g., n to always create the file, and r for read only -- the new default); see the library reference manuals for more details.
[2] Subtle thing: internally, Python now avoids calling the class to recreate a pickled instance and instead simply makes a class object generically, inserts instance attributes, and sets the instance's __class__ pointer to the original class directly. This avoids the need for defaults, but it also means that the class __init__ constructors are no longer called as objects are unpickled, unless you provide extra methods to force the call. See the library manual for more details, and see the pickle module's source code (pickle.py in the source library) if you're curious about how this works. Better yet, see the formtable module listed ahead in this chapter -- it does something very similar with __class__ links to build an instance object from a class and dictionary of attributes, without calling the class's __init__ constructor. This makes constructor argument defaults unnecessary in classes used for records browsed by PyForm, but it's the same idea.
[3] Subtle thing revisited: like the new pickle module, PyForm tries to generate a new class instance on store operations by simply setting a generic instance object's __class__ pointer to the original class; only if this fails does PyForm fall back on calling the class with no arguments (in which case the class must have defaults for any constructor arguments other than "self"). Assignment to __class__ can fail in restricted execution mode. See class InstanceRecord in the source listing for further details.
[4] Note that DBM files of dictionaries use str and eval to convert to and from strings, but could also simply store the pickled representations of record dictionaries in DBM files instead using pickle. But since this is exactly what a shelve of dictionaries does, the str/eval scheme was chosen for illustration purposes here instead. Suggested exercise: add a new PickleRecord record class based upon the pickle module's loads and dumps functions described earlier in this chapter, and compare its performance to StringRecord. See also the pickle file database structure in Chapter 14; its directory scheme with one flat-file per record could be used to implement a "table" here, too, with appropriate Table subclassing.
| CONTENTS |
