
We've developed an extensible package that lets power users define their own views of the data. Now they want to print it, and for people who don't use the program (i.e., senior management), the quality of the printed output is critical.
There are many different options for printing on Windows. We start by reviewing some common business needs and output formats. We then go on to look at three completely different techniques for printing: automating Word, using Windows graphics functions, and finally direct generation of Portable Document Format (PDF) files from Python.
Doubletalk's obvious goal is to produce a complete set of management accounts. These will almost certainly include company logos, repeating page headers and footers, several different text styles, and charts and tables.
It would be highly desirable to view the output onscreen and keep it in files. This makes for a faster development cycle than running off to the printer and means you can email a draft to the marketing department for approval or email the output to your customers.
Most important, it should be possible for users (sophisticated ones, at least) to customize the reports. Everyone in business needs custom reports. Companies who buy large client/server systems often have to invest time and training in learning to use a report-design tool. Systems that don't allow custom reporting either fail to give their customers what they need, or (with better marketing) generate large revenues for the consulting divisions of their software houses to do things the customer could have expected for free.
If we can find a general solution that works from Python, the users are automatically in charge of the system and can write their own report scripts. This is a compelling selling point for a commercial application.
There are several different document models you might wish to support. They all end up as ink on paper, but suggest different APIs and tools for the people writing the reports:
Graphics programming model
The report designer writes programs to precisely position every element on the page.
Word-processor model
Elements flow down the page and onto the next. There may be some sort of header and footer than can change from section to section. Tables need to be broken intelligently, with repeating page headers and footers.
Spreadsheet model
A grid underlies the page, and this can produce sophisticated table effects. However, it starts to cause problems if you want more than one table on a page with different column structures.
Database form model
The same form is repeated many times with varying data, possibly covering an invoice run, a mailmerge, or bank statements for customers. Forms can exceed one page and include master-detail records and group headers and footers.
Desktop-publishing model
This is the most sophisticated document model in common use: the user specifies certain page templates and may have many pages of a given template. Within pages, there are frames within which objects can flow, and frames can be linked to successors.
You need to keep your options open; don't expect all these to be provided, but look for technologies that can be adapted to a different model for a different project.
We've been involved with several different reporting systems over the last few years, and all have had their shortcomings. It is instructive to run through some of their lessons.
Project A involved a database of packaging designs, which could be understood only with diagrams showing the box designs laid out flat and semifolded. Report-
ing was left until the last minute because the developers were not really interested; when time and budget pressures arose, customers got something very unsatisfactory thrown together with a database reporting tool. They were told that the tools just did not support the graphics and layout they really wanted. This situation is all too common.
Project B involved extracting database data to produce 100-page medical statistical analyses; the reports were examples of a word-processor model and could include numerous multipage tables with precise formatting. A collection of scripts assembled chunks of rich text format (RTF) to build the document, inserting them into Word. It became clear that Python was the right tool to extract and organize all the data; however, RTF is complex to work with and isn't really a page-description language.
Project C was a scientific application that captured and analyzed data from a device and produced a family of reports; including charts and statistical tables. The reports needed to be viewed onscreen and printable. They were written using Windows graphics calls. Previewing accurately is a pain in the neck to implement at first, but worth it afterwards. It soon became clear that you could share subroutines to produce all the common elements; thus, one routine did the customer logo on all pages, and the same table routine could be used throughout. Changes to a common element would be applied across the whole family of reports with accuracy. It became clear that writing graphics code was a powerful approach, well suited to object-oriented development and reuse.
Project D involved a family of database reports produced using a graphic report writer (similar to the Report function in Access). A team of developers put these together. Although layout was initially easy, making a global change to all the reports was a nightmare. Furthermore, it became hard to know if calculations were done in the database or the report formulae themselves, leading to maintenance problems. Worst of all, testing involved going directly to the printer; there was no way to capture the output and email it to a colleague for scrutiny.
Project E used a dedicated scripting language that could import fixed-width and delimited text files and that output in PostScript. This was suited to high volumes of data, allowed code sharing between reports, and generally worked extremely well. The language used did not allow any kind of object-oriented programming, however, which made it hard to build higher-level abstractions.
Looking at all these experiences, the ideal solution would seem to have the following characteristics (apart from being written in Python):
� The Python script acquires the data from whatever sources it needs (databases, object servers, flat files) and validates it.
� The Python script uses a library to generate a suitable output format, preferably with all the right layout capabilities.
� The report library allows users to reuse elements of reports, building up their own reusable functions and objects over time.
Now let's look at some of the possible output formats and APIs:
Word documents
Most Windows desktops run Word, and a free Word viewer is available. It's easy to automate Word and pump data into it, with good control over page appearance. As we will see, you can do a lot of work with templates, separating the programming from the graphic design. Unlike all other solutions discussed, Word handles document flow for you. It isn't at all portable, but Word documents allow the user to customize the output by hand if needed.
Windows Graphical Device Interface (GDI)
Windows provides a wide range of graphics functions that can output to a screen or to a printer. Essentially the same code can be aimed at both. This needs to be initiated differently for a multipage report as opposed to a single view on screen. GDI calls involve drawing on the page at precise locations; there is no concept of document flow.
PostScript
PostScript is a page-description language with advanced capabilities. It is the language of desktop publishing and has defined an imaging model that most other graphics systems try to follow. PostScript files can be sent directly to a wide variety of printers and viewed with free software on most platforms. PostScript is quite readable and easy to generate. This is a multiplatform solution, but it isn't commonly used as an output format on Windows. PostScript can be viewed with GhostView, a popular Open Source package, or converted to PDF with Adobe's Distiller product.
Portable Document Format (PDF)
PDF is an evolution of PostScript aimed at online viewing; conceptually, it's PostScript broken into page-sized chunks, with compression and various internal optimizations for rapid viewing. Acrobat Reader is freely and widely available for Windows and other systems, and allows people to view and print PDF files. PostScript Level 3 allows PDF documents to be sent direct to PostScript printers. PDF is much more complex than PostScript, but end users never need to look at the internals.
Excel documents
For invoices and other business forms and some financial reports, Excel offers a natural model. As we've seen, data can be pumped into it fast, and excellent charts can be generated in Excel itself. Care must be taken over the page size and zoom to get a consistent look across multipage documents, and there is little to help you with page breaking. Excel is highly useful if users want to play with the numbers themselves.
HTML
HTML is ubiquitous, and there are great tools for generating it from Python. The latest web browsers do a good job of printing it. However, it doesn't let you control page breaking or specify headers and footers, and there are no guarantees about how a web browser will print a page. As we will see later in this chapter, there are ways to incorporate HTML into your reports in other systems, which is an easy way to meet part of our requirements.
SGML and XML
SGML (Standard Generalized Markup Language) is a large and complex language used for marking up text in the publishing industry. It is well suited for the layout of a book, but not for precise graphics work. It has enormous capabilities but is quite specialized, and viewers are not widely available.
XML (Extensible Markup Language) was derived from SGML and is touted by many as the Next Big Thing on the Web—a possible successor to HTML and a foundation for electronic commerce. Python offers superb tools for working with XML data structures. It is a family of languages rather than a single one and doesn't necessarily have anything to do with page layout. The general concept is to describe the data (''this is a new customer header record'') and not the appearance ("this is 18 point Helvetica Bold"). Our feeling about XML is that (like Python data structures) it's a great way to move data from place to place, but it doesn't solve the problem of how to format it.* However, once we have a useful Python printing tool, it could be put to work with some kind of style-sheet language to format and print XML data.
In general, these formats/APIs fall into three camps:
� Windows GDI is a C-level graphics API involving precise drawing on the page.
| * There is a web standard known as Document Style and Semantics Specification Language (DSSL) that provides a standard way to describe documents. There is also a transformation language based on Scheme that accepts arbitrary XML documents and applies formatting rules to them. However, this language is limited to a flow model, and tools are not yet widely available for working with it. |
� Word and Excel are applications you can automate through COM to generate the right documents. Naturally, they have to be present to create and to view the documents.
� The others, including PostScript and PDF, are file formats. You can write pure Python class libraries to generate files in those formats. Like the Windows API (which borrowed heavily from PostScript), they offer precise page-layout control.
Let's begin by automating Microsoft Word. Later in the chapter, we discuss Windows GDI, PostScript, and PDF, with a view to a unified API for all three. We haven't done a full set of management accounts for each, but we take them far enough that you can figure it out yourself.
As noted previously, Word is an appealing alternative for many reasons. It has a powerful printing and formatting engine. It's on a lot of desktops; indeed it may be a standard throughout your company. A free Word viewer is also available from Microsoft. Finally, it's possible to post-process a document written in Word; you can generate a set of management accounts or a stack of letters, and users can add annotations as they wish.
As discussed with Excel, there are two options: use Python to take control of Word, or have Word VB grab data from Python and format it. In Chapter 9, Integration with Excel, we mentioned some guidelines for choosing which application was on top. We've shown Python automating Word for the following reasons:
� There is a good chance that report production would be an automated step in the middle of the night; people won't be using Word as an interactive query engine in the same way as Excel.
� Python excels at formatting text and getting data into the right shape.
� The Word document model is easy to automate. We'll be adding chunks to the end of a document, and the details can be wrapped easily in reusable Python code.
� Reports change and evolve rapidly. It's easier to change a generic Python script than customize a Python COM server with new special-purpose methods.
However, there's absolutely no technical barrier to doing it the other way around, and that may work for you in some circumstances.
As with Excel, make sure you have the Word VB reference installed to document the object model, and install MakePy support for the Word object model.
Let's start with the simplest possible example:
from win32com.client import Dispatch
MYDIR = 'c:\\data\\project\\oreilly\\examples\\ch12_print'
def simple():
myWord = Dispatch('Word.Application')
myWord.Visible = 1 # comment out for production
myDoc = myWord.Documents.Add()
myRange = myDoc.Range(0,0)
myRange.InsertBefore('Hello from Python!')
# uncomment these for a full script
#myDoc.SaveAs(MYDIR + '\\python01.doc')
#myDoc.PrintOut()
#myDoc.Close()
When you execute this function, Word starts, and your message is displayed. We've commented out the lines at the bottom, but you can choose to print, save, or close the document. It's fun to arrange the Python console and Word side-by-side and watch your text appearing, and a great way to learn the Word object model.
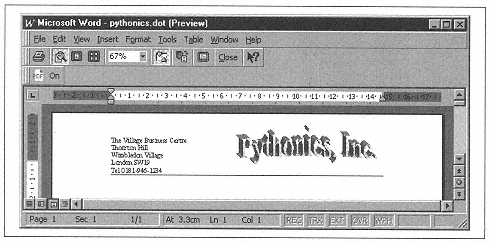
You could hand-build a document and automate all the formatting, but that would be tedious.-Far better to use a Word template and just put in what you need from your Python code. For the next example, we've created a template called Pythonics.dot. This has a fancy header, page numbers, and borders. It could also contain section headings, a table of contents, standard text, or whatever you want. Using a template is a huge leap forward in productivity. Figure 10-1 shows ours.
More important, a template allows you to separate the software development from the page layout. An artistically challenged developer could provide a basic template with the required elements, and turn it over to the marketing department to define the styles and boilerplate text. If she also delivers a Python test script containing example data, the marketing person can regularly test whether the program still runs while he is modifying the template.
To create a document based on a template, you need to modify only one line:
>>> myDoc = myWord.Documents.Add(template=MYDIR + '\\pythonics.dot')
Note the use of keyword arguments. Many of the Office functions (like Documents.Add) take literally dozens of arguments, and entering them every time
 |
||||
| Figure 10-1. A Word template |
||||
would be tedious. Fortunately, Python also supports named arguments. However, you need to watch the case: most Word arguments have initial capitals.
Word offers too many choices for building a document: you can loop over a document's contents, search for elements such as words or paragraphs, and select any portion of the text to work with. We'll assume you want to build a document in order from beginning to end.
Let's start with a Python class to help automate the production of documents. First we'll construct an object that has a pointer to a Word document, then add the desired methods one at a time. The class is called WordWrap and can be found in the module easyword.py. Here are some of its methods:
class WordWrap:
"""Wrapper around Word 8 documents to make them easy to build.
Has variables for the Applications, Document and Selection;
most methods add things at the end of the document"""
def __init__(self, templatefile=None):
self.wordApp = Dispatch('Word.Application')
if templatefile == None:
self.wordDoc = self.wordApp.Documents.Add()
else:
self.wordDoc = self.wordApp.Documents.Add(Template=templatefile)
#set up the selection
self.wordDoc.Range(0,0) .Select()
self.wordSel = self.wordApp.Selection
#fetch the styles in the document - see below
self.getStyleDictionary()
def show(self):
# convenience when developing
self.wordApp.Visible = 1
def saveAs(self, filename):
self.wordDoc.SaveAs(filename)
def printout(self):
self.wordDoc.PrintOut()
def selectEnd(self):
# ensures insertion point is at the end of the document
self.wordSel.Collapse(0)
# 0 is the constant wdCollapseEnd; don't want to depend
# on makepy support.
def addText(self, text):
self.wordSel.InsertAfter(text)
self.selectEnd()
You work with the Selection object, which provides several methods for inserting text. When you call Selection.InsertAfter(text), the selection expands to include whatever you add; it also provides a Collapse method that can take various parameters; the one you need, wdCollapseEnd, happens to have a value of zero, and collapses the Selection to an insertion point at the end of whatever you've just inserted. If you are using MakePy, you can access the constant by name; since this is the only constant we'll use in this application, we looked up the value and used it directly to produce a script that works on all PythonWin installations.
You can explicitly format text with precise font names and sizes by assigning them to the many properties of the Selection object, but it is less work and a better design to use predefined styles. It's far easier to change a style than to adjust 20 different reporting scripts.
The first thing to do is add a paragraph in a named style. Word has constants for all the standard styles. If you used MakePy to build the support for Word, you could access the built-in styles like this:
>>> from win32com.client import constants
>>> mySelection.Style = constants.wdStyleHeading1
>>>
Note that we set the Style property of the currentRange to the correct style constant. This doesn't work if youuse dynamic dispatch, or if you have your own custom template withstyles that aren't built into Word. However, you can query a
document at runtime. The following method gets and keeps a list of all styles actually present in a document:
def getStyleList(self):
# returns a dictionary of the styles in a document
self.styles = []
stylecount = self.wordDoc.Styles.Count
for i in range(1, stylecount + 1):
styleObject = self.wordDoc.Styles(i)
self.styles.append(styleObject.NameLocal)
The Style property of a Range or Selection in Word accepts either a constant or a string value, so you might as well use the names. Here's a useful method:
def addStyledPara(self, text, stylename):
if text[-1] <> '\n':
text = text + '\n'
Let's try:
>>> import easyword
>>> w = easyword.WordWrap()
>>> w.show()
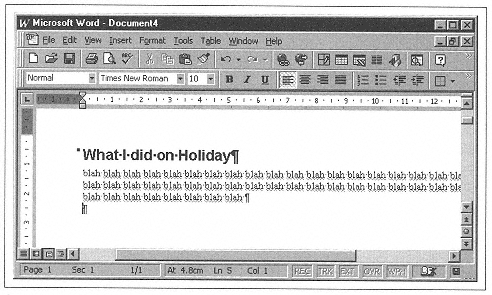
>>> w.addStyledPara('What I did on Holiday', 'Heading 1')
>>> w.addStyledPara('blah' * 50, 'Normal')
>>>
This should give you something that looks like Figure 10-2
 |
||||
| Figure 10-2. Inserting paragraphs with styles |
||||
Our wrapper class and Word's style features combine to make it easy to build a document.
Word tables are sophisticated object hierarchies in their own right, and you can manipulate them to any level of detail. However, there's also an AutoFormat option for tables that works in a similar way to styles. Here's the full declaration:
Table.AutoFormat(Format, ApplyBorders, ApplyShading, ApplyFont, ApplyColor,
ApplyHeadingRows, ApplyLastRow, ApplyFirstColumn, ApplyLastColumn, AutoFit)
All you have to do is insert a block of tab-delimited text with the table contents, and call the method to convert text to a table, then call the table's AutoFormat method. Fortunately, almost all the arguments are optional:
def addTable(self, table, styleid=None):
# Takes a 'list of lists' of data.
# first we format the text. You might want to preformat
# numbers with the right decimal places etc. first.
textlines = []
for row in table:
textrow = map(str, row) #convert to strings
textline = string.join(textrow, '\t')
textlines.append(textline)
text = string.join(textlines, '\n')
# add the text, which remains selected
self.wordSel.InsertAfter(text)
#convert to a table
wordTable = self.wordSel.ConvertToTable(Separator='\t')
#and format
if styleid:
wordTable.AutoFormat(Format=styleid)
Unfortunately, to specify a style, you need to supply a numeric format constant instead of a name. If you are using MakePy, this is easy; an alternate approach is to use Word's VB editor to look up the constants. Be warned: some constants vary across different language editions of Word.
Tables can be accessed through the Document.Tables collection.
Adding a chart proved quite a challenge. There's a promising-sounding Microsoft Chart COM library, but it turned out not to allow automation in the same way as Word and Excel. Finally we decided to just make up an Excel chart, which is probably easier for users as well. A spreadsheet and chart can be easily designed by hand, and you can update the numbers, recalculate, and save using the tools in
Chapter 9. However, the problem remained of how to add a new object and position it correctly within the document. The problem took us several hours to solve and into some dark and surprising corners of Word's object model. Since the same techniques apply to positioning any OLE object or even a bitmap from a file, it's worth going over the objects in question.
A little reading of the Word help file turned up the Shapes collection, which claims to represent all the nontext objects in the document: OLE objects, WordArt, graphic files, text boxes, and Word drawing objects. The collection has a number of Add methods, including one called AddOLEObject. AddOLEObject has a multitude of arguments, but allows you to specify a class and a file; thus Document.Shapes. Add(ClassType=�Excel.Chart�,FileName=�mychart.xls�) inserts the chart somewhere in the document and creates a new Shape object to refer to it. The Shapes collection lives somewhere called the drawing layer, which floats above each page and isn't part of the document. The Shape object has an Anchor property that should be set to a valid range in the document, and it's then constrained to stay on the same page as the first paragraph in that range. You then have to choose a coordinate system with the RelativeHorizontalPosition and RelativeVerticalPosition properties, which say whether the location is measured relative to the current page, column or paragraph. Finally, you set the Left and Top properties to define the location in the given coordinate system.
We managed to write some VBA code to position charts using these objects and properties, but found the behavior inconsistent. If you've ever struggled to position a screen shot in a document while it jumps around at random, imagine what it is like doing it in code from another application! With a large shape, Word would decide that the initial location or page was impossible before you had finished setting properties and give different behavior from Python and from VBA.*
Finally we discovered the InlineShapes collection (not a name you would look for) that filled the bill. An InlineShape is conceptually part of the document; put it between two paragraphs, and it stays between them forever. The arguments to its constructor didn't work as advertised; the shapes always seemed to appear at the beginning of the document, but it was possible to cut and paste them into position. The following code finally did the job:
def addInlineExcelChart(self, filename, caption=",
height=216, width=432):
# adds a chart inline within the text, caption below.
# add an InlineShape to the InlineShapes collection
#- could appear anywhere
| * We did get to the bottom of this. Word is badly behaved in its use of two COM variant types that are used to denote empty and missing arguments. This explained a number of other obscure COM bugs. The fix is complex, so we've stuck with our simple workaround. |
shape = self.wordDoc.InlineShapes.AddOLEObject(
ClassType='Excel.Chart',
FileName=filename
)
# set height and width in points
shape.Height = height
shape.Width = width
# put it where we want
shape.Range.Cut()
self.wordSel.InsertAfter('chart will replace this')
self.wordSel.Range.Paste() # goes in selection
self.addStyledPara(caption, 'Normal')
The same routine can be easily adapted to place bitmaps. If you have a simpler solution, drop us a line!
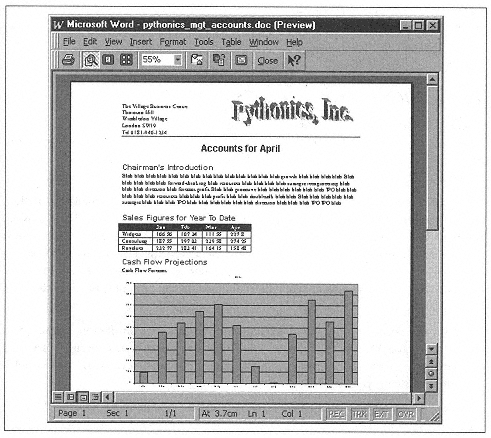
Now we can build a set of management accounts. The example applications include a Word template, an Excel spreadsheet with a prebuilt chart, and a test routine in easyword.py. Thanks to helper methods, this is simple:
def test():
outfilename = MYDIR + '\\pythonics_mgt_accounts.doc'
w = WordWrap(MYDIR + '\\pythonics.dot')
w.show() # leave on screen for fun
w. addStyledPara('Accounts for April', 'Title')
#first some text
w.addStyledPara("Chairman's Introduction", 'Heading 1')
w.addStyledPara(randomText(), 'Normal')
# now a table sections
w.addStyledPara("Sales Figure s for Year To Date", 'Heading 1')
data = randomData()
w.addTable(data, 37) # style wdTableStyleProfessional
w.addText('\n\n')
# finally a chart, on the first page of a ready-made spreadsheet
w.addStyledPara("Cash Flow Projections", 'Heading 1')
w.addInlineExcelChart(MYDIR + '\\wordchart.xls', 'Cash Flow Forecast')
w.saveAs(outfilename)
print 'saved in', outfilename
This runs visibly for fun, but would be much faster if kept off-screen. It produces the document in Figure 10-3.
 |
||||
| Figure 10-3. The finished document |
||||
Word can import and export HTML. The following line inserts an entire file into the current document:
>>> wordSelection.InsertFile(MYDIR + '\\tutorial.html')
>>>
Furthermore, some experiments revealed that you don't even need a full HTML document, just tagged text saved with the extension HTML.
So if you want an easy way to pump large amounts of text into a Word document, generate the HTML and insert it. Python has an excellent package, HTMLgen, for generating sophisticated markup from code. Word can import HTML tables with reasonable success, and all of the standard HTML styles are marked as styles in Word.
These days there is a need to produce both printed and online versions of documents. If you write code to generate the HTML, and then import it into a smart Word template with the right corporate header and footer, you have a complete solution.
There is another approach for incorporating Word. You can use Python as the COM server and Word as the client. We discussed the pros and cons of this approach with Excel at the end of Chapter 9; the same design considerations apply.
Using Word as a client, use Visual Basic for Applications to initialize a Python server and fetch the data. The most natural way to package this is to build a Word template that includes the code and the desired document elements. When a new document is created from the template, it connects to the Doubletalk COM server we built earlier, instructs it to load the data, fetches the tables of information it needs, and uses VBA code to place the data into the document. This approach has two advantages:
� VBA offers nice editing features like drop-down auto-completion, helping you to learn the Word object model quickly. Debugging is also easier (assuming you have separately tested your Python server, and the Word object model is what is giving you trouble).
� You can safely tie functions in your template to regions of text or tables in your template without needing to be too generic. Data preparation is Python's job; formatting is Word's
Please note: Word is hard to work with. Even if you plan to write a controlling program in Python, you should sort the code you need in VBA and check that it all runs first to save time. The manuals and the product itself are buggy in places. It is also somewhat unstable during development; if you make lots of COM calls that cause errors, it tends to crash frequently. Once the code is correct, it seems to keep working without problems. Some other Python users have worked with very large documents and reported stability problems in making thousands of COM calls in a row while creating large documents.
However, we do expect this situation to improve; Word 8.0 is the first version with VBA, whereas people have been automating Excel in real-time systems for years. Furthermore, we expect Word to handle XML in the future, which will allow more options for pumping in lots of data quickly.
In conclusion, you have the technology to do almost anything with Word. However, it's a heavyweight solution. Whether it's the right format for you depends on several factors:
� Word documents are the output format you want.
� Your users have Word.
� Your reports fit a word-processor flow model.
� Whether it's important to protect the integrity of a finished report or let users tweak it afterwards.
The next technique to look at is Windows printing. We start off with a minimal example, then discuss the principles behind it. Start by typing the following at a Python console:
>>> import win32ui
>>> dc = win32ui.CreateDC()
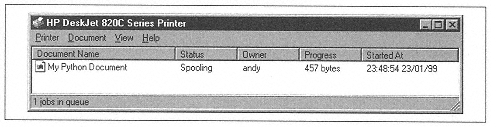
>>> dc.CreatePrinterDC()
>>> dc.StartDoc('My Python Document')
>>>
At this point, you'll see a printer icon in the System Tray. Double-click, and you see Figure 10-4.
 |
||||
| Figure 10-4. The Windows print queue |
||||
Now we'll print a few words and draw a line on the page:
>>> dc.StartPage()
>>> dc.TextOut(100,100, 'Python Prints!')
>>> dc.MoveTo(100, 102)
(0, 0)
>>> dc.LineTo(200, 102)
>>> dc.EndPage()
>>>
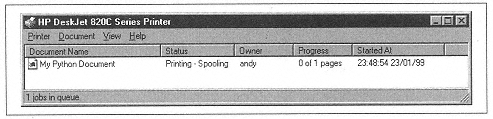
As soon as you type EndPage, your page should begin to print on your default printer. The Status column in the Printer window changes to look like Figure 10-5.
 |
||||
| Figure 10-5. Document printing, while still being written |
||||
Finally, tell Windows you've finished printing:
>>> dc.EndDoc()
>>>
Hopefully, a few seconds later you will have a page with the words Python Prints near the top left and a horizontal line just above it.
If you've ever done any Windows graphics programming, this will be familiar. The variable dc is an instance of the Python class PyCDC, which is a wrapper around a Windows Device Context. The Device Context provides methods such as MoveTo, LineTo, and TextOut. Device Contexts are associated with windows on the screen as well as with printers; the graphics code is identical, although the way you start and finish differs: windows don't have pages, for example.
In Chapter 20, GUI Development, we cover PythonWin development in some detail, and the example application involves graphics calls of this kind.
There is, however, one significant problem with your printout: the line on your page is probably rather tiny. The coordinates used were pixels. On the screen, you typically get about 100 pixels per inch; if you'd written the previous code for a window, the text would be an inch down from the top left of the window and about as long as the words. On a typical HPDeskJet printer, which has a resolution of 300 dots per inch, the line is just a sixth of an inch long; yet the text is still a sensible size (it will, in fact, be in the default font for your printer, typically 10-point Courier).
For printed reports, you need precise control of text and graphics; numbers need to appear in the columns designed for them. There are several ways to get this. We will use the simplest, and choose a ready-made mapping mode, one of several coordinate systems Windows offers, based on twips. A twip is a twentieth of a point; thus there are 1440 twips per inch. Windows can draw only in integer units, so you need something fairly fine-grained such as twips. (Windows also provides metric and imperial scales, or lets you define your own.) In this coordinate system, the point (0, 0) represents the top left corner of the page, and y increases upwards; so to move down the page, you need negative values of y.
To set up the scale, you need just one line:
dc.SetMapMode(win32con.MM_TWIPS)
To test it, we'll write a little function to draw a six-inch ruler. If it's right, you can call this function after setting the mapping mode and take out a real ruler and check it. Here's the ruler function and a revised script:
import win32ui
import win32con
INCH = 1440
def HorizontalRuler(dc, x, y):
# draws a six-inch ruler, if we've got our scaling right!
# horizontal line
dc.MoveTo(x,y)
dc.LineTo(x + (6*INCH), y)
for i in range(7):
dc.MoveTo(x,y)
dc.LineTo(x, y-INCH/2)
x = x + INCH
def print_it():
dc = win32ui.CreateDC()
dc.CreatePrinterDC() # ties it to your default printer
dc.StartDoc('My Python Document')
dc.StartPage()
dc.SetMapMode(win32con.MM_TWIPS)
# text - near the top left corner somewhere
dc.TextOut(INCH,-INCH, 'Hello, World') # 1inch in, 8 up
HorizontalRuler(dc, INCH, - INCH * 1.5)
dc.EndPage()
dc.EndDoc()
print 'sent to printer'
del dc
We've seen how to control precise page layout and also seen a reusable function that does something to a Windows device context. This is a first step in building your own graphics library. As everyone who's ever read a textbook on object-oriented programming knows, the natural approach is to make a class hierarchy of objects that can draw on the device context. Having shown you the basics, we'll move on, and return to the class library later.
While working on this book, we tried to create a printing system that could handle multiple formats, including Windows and PDF. At the same time, several people in the Python newsgroup felt that it was a real pity everyone was using platform-specific code to draw charts and diagrams, and that it should be possible to come up with a common API that covered several output formats. A team of four—Joe Strout, Magnus Hetland, Perry Stoll, and Andy Robinson—developed a common API during the spring of 1999, and a number of backends and a test suite are available at press time. This has produced some powerful printing solutions, which we explore here.
The API is known as Plug-In Drawing, Does Little Else (PIDDLE) and is available from http://www.strout.net/python/piddle/. The package includes the basic API, test patterns, and as many backends as are deemed stable. The basic API defines classes to represent fonts and colors, and a base class called Canvas, which exposes several drawing methods. The base canvas doesn't produce any output and exists to define an interface; specific backends implement a canvas to draw on the relevant device or file format.
Let's quickly run through the main features of the PIDDLE API.
At the time of writing, backends are available for PDF, the Python Imaging Library (which lets you draw into BMPs, JPEGs, and a host of other image formats—useful for web graphics), OpenGL, Macintosh QuickDraw, PostScript, Adobe Illustrator, Tkinter, wxPython, and PythonWin. Not all of these implement all features correctly, but things are evolving rapidly. When you get to Chapter 20, bear in mind that one Python graphics library can draw to all the GUI toolkits we cover.
Each platform has a different font mechanism. PIDDLE defines a Font class to rise above this. A Font instance has attributes face, size, bold, italic, and underline. A standard set of font names are provided, and each backend is responsible for finding the best local equivalent.
Color class instances are created with red, green, and blue levels between zero and one. The module creates a large number of colors based on the HTML standard, so the word red may be used to refer to a ready-made Color object.
The PostScript default scale of 72 units per inch is used, but with the origin at the top left of the page and y increasing downwards.
The Canvas class provides drawing methods and overall management functions. The graphics functions provided (we will skip the arguments) are drawLine, drawLines, drawString, drawCurve (which draws a Bezier curve), drawRect, drawRoundRect, drawEllipse, drawArc, drawPolygon, and drawFigure (which can manage an arbitrary sequence of line, arc, and curve segments). Each method accepts optional line and fill colors and may be used to draw an outline or a filled shape.
At any time the Canvas has a current font, line width, line color, and fill color. Methods use the defaults unless alternatives are supplied as arguments. Thus drawLine(10,10,20,20) uses the current settings; drawLine(10,10,20,20, width=5, color=silver) does what it says but leaves the current settings unchanged.
The drawString method is extremely versatile. It allows angled text (which forced some people to work hard at rotating bitmaps for their platforms, but they managed it), control of color, and printing of blocks of text with embedded new-lines. A stringWidth method allows string widths to be measured, making it feasible to align and wrap text accurately.
PIDDLE can use the Python Imaging Library to handle image data; bitmaps in many formats can be loaded, and either placed at their natural size or stretched to fit a desired rectangle.
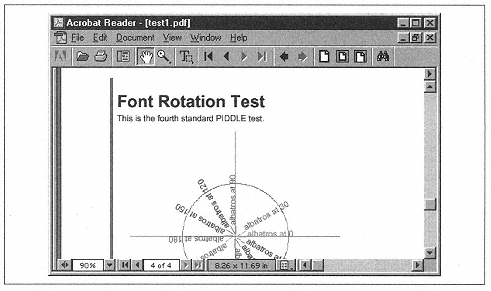
As with all good Python packages, a test framework is provided that runs a group of standard test patterns against the bundled backends. Figure 10-6 shows a standard test pattern.
 |
||||
| Figure 10-6. A PIDDLE test pattern |
||||
A special canvas called VCRCanvas works as a recorder: when you execute graphics commands, it saves them for replay later. They are saved as text holding executable Python code. This makes it possible for a specialized graphics package to save a chart in a file, and for any other canvas to replay that file in the absence of the original package.
Having discussed the base API, we now tackle two key output formats: PostScript and PDF.
The PostScript language is the world's most famous page description language. It was developed by Adobe Systems in 1985 as a language for printer drivers and was perhaps the key technology in the desktop publishing revolution. It consists of commands for describing the printed page, including both text and graphics. A text file of these commands is sent to a PostScript printer, which prints them. Post-
Script has some features other page description languages lack. For example, a font is a collection of subroutines to draw arbitrary curves and shapes; there's no difference in the way text and graphics are handled. This contrasts with Windows, where you can perform arbitrary scaling and translation of the lines in a chart, while watching all the labels stay right where they are in the same point size.*
This section is relevant only if you are aiming at a fairly high-end printer. However, it's worth understanding something about PostScript since it's the base for PDF, which is relevant to everyone.
PostScript printers used to be quite specialized; however, as power has increased, more printers are offering PostScript compliance, e.g., the LaserJet 5 series. PostScript printers are the standard for high-volume/high-quality printers.
PostScript is generally produced by printer drivers or by graphics packages such as Illustrator, though masochists can do it by hand. PostScript is usually drawn on the printer. However, the public-domain package, GhostView, is available for rendering PostScript files on Windows and other platforms. GhostView lets you print to any printer, doing the best job it can with the local print technology. It also makes it possible to test Python code for generating PostScript without having a dedicated printer on hand.
Let's have a quick look at a chunk of PostScript:
% Example PostScript file - this is a comment
72 720 moveto
72 72 lineto
/Helvetica findfont 24 scalefont setfont
80 720 moveto
('Hello World') show
showpage
Comments begin with %. Lines 2 and 3 find a font and specify a size. The coordinate system uses 72 points per inch and starts at the bottom left of the screen or page; thus, the commands draw a line one inch from the left of the page, running for most of its height, and the string ''Hello World'' near the top left corner.
As you can see, PostScript is fairly readable; it's thus extremely easy to build a Python library to spit out chunks of PostScript. Furthermore, this can be done at very high speed; Python excels at text substitutions. That is what the piddlePS module does; when you make a call such as drawLine (10,10,50,100, width=5), piddlePS does some testing to see what needs changing, then substitutes the numbers into a template string and adds them to an output queue. Here is how it was implemented:
| * Of course, it is possible to do zoomable views in Windows, but it isn't easy. NT is beginning to approach PostScript in this regard with its World Transforms, but these are not in Windows 95 and thus have not been widely used. |
def drawLine(self, x1, y1, x2, y2, color=None, width=None):
self._updateLineColor(color)
self._updateLineWidth(width)
if self._currentColor != transparent:
self.code.append('%s %s neg moveto %s %s neg lineto stroke' %
(x1, y1, x2, y2))
PostScript offers many capabilities beyond the scope of this chapter. Specifically, it's a full-blown language, and you can write subroutines to align text, wrap paragraphs, or even draw charts. Another key ability is coordinate transformations; you can write a routine to draw a shape, then translate, rotate, and scale space to redraw it again elsewhere. The PostScript imaging model has been used or copied in most vector graphic formats since it was developed.
PDF is a recent evolution of PostScript. Whereas PostScript was intended to be consumed by printers, PDF is designed for both online viewing and printing. It allows for features such as clickable links, clickable tables of contents, and sounds. It is intended as a final form for documents. You could possibly edit PDF if you had a few months to spare, but it isn't easy. It also remedies some basic problems with PostScript. (PostScript contains arbitrary subroutines that might generate pages in a loop or subject to conditions; so the only way to look at page 499 of a 500-page document, or even to know that there are 500 pages, is to execute the code and render it all.)
For the average developer, PDF is compelling because the Acrobat Reader is freely and widely available on almost all platforms. This means you can produce a document that can be emailed, stored on the Web, downloaded, and printed at leisure by your users, on almost any platform. Furthermore, all they get is the document, not any attached spreadsheets or data they shouldn't, and you can be confident it won't be tampered with. For this reason, many companies are looking at PDF as a format for much of their documentation.
PDF documents are generally created in two ways, both of which involve buying Adobe Acrobat. This includes PDFWriter, a printer driver that lets you print any document to a PDF file; and Distiller, which turns PostScript files into PDF files. These are excellent tools that fulfill many business needs.
PDF is a published specification, and in the last two years, a C library and a Perl library have been written to generate PDF directly. This was too much of a challenge to resist, so we have done one in Python, too.
Technically, PDF is a complex language. The specification is 400 pages long. If you don't want to know the details, skip to the section "Putting It Together: A High-Volume Invoicing System." If you do, it'd be a good idea to open one of the sample PDF files provided with this chapter; unlike most you will find on the Web, they are uncompressed and numbered in a sensible order. We've provided a brief roadmap to the PDF format as we feel that it offers many benefits, and you might want to add your own extensions in the future.
The outer layer of the PDF format provides overall document structure, specifying pages, fonts used, and advanced features such as tables of contents, special effects, and so on. Each page is a separate object and contains a stream of page-marking operators; basically, highly abbreviated PostScript commands. The snippet of PostScript you saw earlier would end up like this:
72 720 m
72 72 l
/F5 24 Tf 42 TL
80 720 Td
('Hello World') Tj
Unfortunately this code, which can at least be decoded given time and you know where to look, can be compressed in a binary form and is buried inside an outer layer that's quite complex. The outer layer consists of a series of numbered objects (don't you love that word?) including pages, outlines, clickable links, font resources, and many other elements. These are delimited by the keywords obj and endobj and numbered within the file. Here's a Catalog object, which sits at the top of PDF's object model:
1 0 obj
<
/Type /Catalog
/Pages 3 0 R
/Outlines 2 0 R
>>
Every object is a dictionary of keys and values. The Catalog is at position 1 in the file. It has a Pages collection, found at location 3 in the file. The Pages collection might contain individual Page objects, or perhaps other Pages collections with subranges of the document. These form a balanced tree, so that an application like Acrobat Reader can locate the drawing code for page 3,724 in a 5,000 page document in one second flat.
Once you get to a Page object, you'll find a declaration of the resources needed to draw the page, which includes a list of fonts used and might include graphics function sets to load into memory and a reference to a Contents object. A simple page and its associated small Contents object might look like this:
20 0 obj
<
/Type /Page
/Parent 3 0 R
/Resources
<
/Font <
/F1 5 0 R % list of font declarations
/F2 6 0 R % - font objects are described elsewhere
/F3 7 0 R % in the file
/F4 8 0 R
/F5 9 0 R
>>
/ProcSet 3 0 R % reference to the sets of PostScript
>> % drawing procedures to be loaded for page
/MediaBox [0 0 612 792] % page in points - 8.5x11 US paper
/Contents 21 0 R % reference to next object
>>
endobj
21 0 obj % beginning of contents object
< /Length 413 >> % predeclare the stream length
stream
% line 2 units wide from 72, 72 to 72, 720
q 2 w 72 72 m 72 720 l S Q
BT % begin text mode
/F6 48 Tf 80 672 Td 48 TL % set font, position and size (48 pt)
(PDFgen) Tj T* % display a line of text
/F5 24 Tf24_TL % smaller font
80 640 Td % set text origin
(Automatic PDF Generation) Tj T* % more text
ET % end text mode
endstream
endobj
Lurking near the bottom, between the stream and endstream keywords in the Contents object, you finally get to the page-marking operators. Note also that the length of the stream of contents operators is predeclared to allow it to be read quickly.
Finally, typically at the end of the document, you find an index section that looks like this:
xref
0 24
0000000000 65535 f
0000000017 00000 n
0000000089 00000 n
0000000141 00000 n
<lines deleted to save space>
0000005167 00000 n
trailer
< /Size 24 /Root 1 0 R /Info 19 0 R>>
startxref
7164
%%EOF
When Acrobat Reader opens a file, it looks in the last few bytes for the keyword trailer. The trailer object on the following line tells us that there are 24 objects in the file; that the root is object number 1; and that information such as the document author and date are available at object number 19. It then tells us that the cross-reference table is found starting at byte 7164 in the file. The cross-reference table itself (beginning at xref in the first line) shows the positions of the objects; thus object 1, the root, is at byte 17 in the file, and object 24 is at byte 5167.
This mechanism makes it possible to parse and process PDF documents quickly, but it made developing a PDF generator harder. With HTML or PostScript, you get instant gratification each time you output a well-formed chunk of code, and you can start in a small way; with PDF, you can't even look at it until you have correctly indexed the whole thing.
The PDFgen.py module wraps and hides most of this from the user and constructs a well-formed document. Many advanced features are missing, but the documents do open cleanly. The module does this by having Python classes that mirror the PDF ones and by building up a list of objects in memory. When it writes the file, each returns a text representation of itself for the file, and the PDFDocument class measures the length of this. The module is thus able to build a valid index at the end. What it doesn't do is the drawing. The module presumes that something else feeds it a complete contents stream for each page. This is where the PIDDLE interface comes in.
We won't go further into the implementation of the outer layer of the PDF library here. Instead we'll look at a few details of the current frontend.
Once the PIDDLE API was stable, it was fairly straightforward to implement a PDFCanvas object to provide a simple API. Let's take a quick look at some of the methods of the PDFCanvas class and how they hook up with the backend:
def __init__(self, filename):
Canvas.__init__(self)
self.filename = filename
self.code = [] # list of strings to join later
self.doc = pdfgen.PDFDocument()
self.pageNumber = 1 # keep a count
# various settings omitted
When it starts up, the PDFCanvas instance creates a PDFDocument instance. This is the class that manages the overall document structure. It also creates an empty list, self.code, to hold strings of page-marking operators. The various drawing methods add the right operators to the list in the same way the PostScript snippets did earlier. If you compare the methods and output with the PostScript PSCanvas, it's easy to see the correspondence.
When you ask for a new page with the showPage() method, this happens:
def showPage(self):
page = pdfgen.PDFPage()
stream = string.join([self.preamble] + self.code, '\n')
#print stream
page.setStream(stream)
self.doc.addPage(page)
self.pageNumber = self.pageNumber + 1
self.code = [] # ready for more�
First, create a PDFgen object called PDFPage, which is responsible for generating the output later. Then make a big string of page-marking operators by joining a standard preamble (which does some work to set up coordinate systems, default fonts, and so forth) and the list of accumulated operators. This is stored in the PDFPage, which is then added to the PDFDocument. PDFgen takes care of the rest when asked to save itself to disk. Finally, the page number is incremented, and the list of strings is emptied, ready for some more output.
Rather than repeating the management accounts we did in Word, we'll discuss a different situation. Imagine that Pythonics is now doing a large volume of consulting work and needs to bill customers by the hour on a weekly basis. An internal database keeps track of who works for how many hours on which project. At the end of each week, we need to raise correct invoices and simultaneously enter them into our accounts system. Although starting small, we'd like a system that will scale up in the future.
We've built a tab-delimited text file called invoicing.dat that contains a list of the fields for each invoice; basically, the customer details, date, invoice number, number of hours worked, hourly rate, and so on. In a real application, this data might come from database queries, flat files, or already be available as an object model in memory. The script to generate the invoices is 200 lines long and is mostly graphics code; we'll show some excerpts. First, the main loop:
def run()
import os
invoices = acquireData() # parse the data file
print 'loaded data'
for invoice in invoices:
printInvoice(invoice)
print 'Done'
We'll skip the data acquisition. Note also that in a real financial application, you'd extract transaction objects from your invoice objects and save them in a BookSet at the point of printing.
For each invoice, construct a PDFCanvas, call various drawing subroutines, and save it with an appropriate filename. In this case, the filename encodes the invoice number and client name:
def printInvoice(inv):
#first see what to call it
filename = 'INVOICE_%d_%s.PDF' % (inv.InvoiceID, inv.ClientID)
canv = pdfcanvas.PDFCanvas(filename)
#make up the standard fonts we need and attach to the canvas
canv.standardFont = pdfcanvas.Font(face='Helvetica',size=12)
canv.boldFont = pdfcanvas.Font(face='Helvetica',bold=1, size=12)
#now all the static repeated elements
drawHeader(canv, filename)
drawOwnAddress(canv)
# now all the data elements
drawGrid(canv, inv)
drawCustomerAddress(canv, inv)
drawInvoiceDetails(canv, inv)
#save
canv.flush()
Here's one of the drawing functions, drawOwnAddress(). It's passed the canvas to draw on and the invoice; it does what you'd expect:
def drawOwnAddress(canv):
address = ['Village Business Centre',
'Thornton Hill',
'Wimbledon Village',
'London SW19 8PY',
'Tel +44-181-123-4567']
fnt = Font(face='Helvetica',size=12,italic=1)
canv.drawStrings(address, INCH, INCH * 1.5, fnt)
Other methods draw tables, format the numbers, and output them in the right places using methods of the PDFCanvas. Users don't need to worry about the details of the file format.
In practice, you'd use a standard script handler so that the script could be run with a double-click. Here it's run interactively. Running the script generates one file for each customer, at a rate of several files per second:
>>> invoicing.run()
loaded data
saved INVOICE_199904001_MEGAWAD.PDF
saved INVOICE_199904002_MEGAWAD.PDF
saved INVOICE_199904003_MEGAWAD.PDF
saved INVOICE_199904004_NOSHCO.PDF
Done
>>>
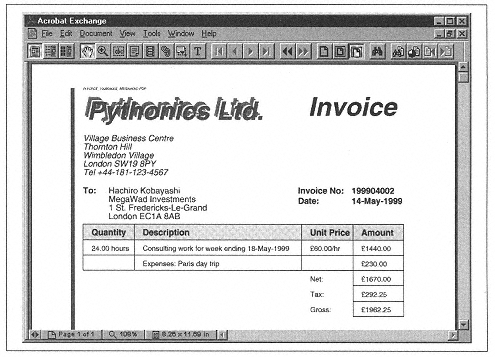
Figure 10-7 shows the output.
 |
||||
| Figure 10-7. PDF invoices generated from Python |
||||
Now, let's look at the benefits of this architecture from a business perspective:
� The report took only about two hours to assemble, including data acquisition.
� You have a simple script that can be run with a double-click or scheduled to go off at night: no need to launch applications manually.
� The output is filed with the correct names in an immutable format. If a dispute or problem arises in the future, you can instantly find the file and see exactly what was sent.
� The entries have been made in the accounts system at the same time. It's easy to add further steps to the logic, such as emailing invoices to suppliers.
� The system is fast and light; it runs well with tens of thousands of pages and can be moved from a desktop PC to a Unix server with no modifications.
� It's easy to customize. You don't need a lot of Python, and there is a simple drawing API. Power users could learn to customize it or write their own reports easily.
� Data can be acquired from anything with Python: files, databases, spread-sheets, or other Python applications. You aren't tied to a database engine.
There are several more techniques and improvements we haven't added, but that could be easily accomplished if the need arose. This is Open Source, so if they sound useful, they probably will be done by somebody by the time you read this.
Object-oriented graphics and page layout API
The PIDDLE team is working on the "next layer up," which will hopefully be available by the time this book is printed. This consists of two ideas. First of all, frames identify regions on the page into which drawing may take place; users may specify one main frame per page, or as many as they wish. Second, we create a hierarchy of drawable objects, allowing a high level of reuse. These objects know their size and can wrap themselves to fit a frame if needed. They can be "poured into" a frame until it fills. A Table object might be initialized with an array of data and draw default table cells by itself; named styles allow quick and easy formatting of large tables. A Paragraph object, again tied to a list of styles, allows rapid formatting of text. Individual PIDDLE drawings can also constitute drawable objects and define their own coordinate systems for their contents.
Volume optimizations
The example script runs at about four pages per second, a lot faster than any printer, but nowhere near the speed limit. A large amount of processing is going into generating a text stream, which is almost the same for each page. You can generate the page once and substitute variables using Python's dictionary-substitution facility. This lets you generate documents as fast as the disk can write; however, it's applicable only for simple one-record-per-page forms.
PDF provides a similar trick: you can create something called a PDF form, which is a content stream that can be reused within a document. The reusable parts of the page can be placed in a form and stored once, and only the numbers and text that change need to print. This reduces the size of a huge invoice print run by 90% or more and leads to faster printing on the right printers.
Imported graphics
A large number of graphics packages work with PostScript. You can design pages or graphic elements in a tool such as Adobe Illustrator. These elements can be distilled and the PDF page-marking operators lifted out into a library, with some parsing tools that would be straightforward to write in Python. This library combines the freedom of visual design tools with the discipline and speed of report programs.
Onscreen views
The testing cycle was pretty fast—run a script, load the document to Acrobat in less than two seconds. However, the PIDDLE API is not platform-specific. You can use it to provide a printing engine for graphical applications; the same code that drew charts on the screen using a Windows or Tkinter backend generates a PDF report for free.
Plotting
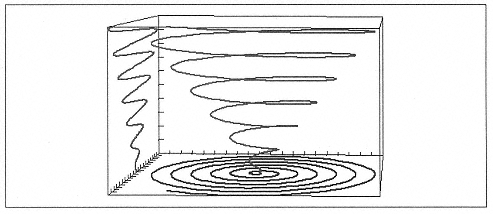
As discussed earlier, a key motivation for PIDDLE was to create plotting libraries that were not tied to one backend. The Graphite package (www.strout.net/python.graphite/) was developed alongside PIDDLE and is already capable of a wide range of plot types. Given Python's strong presence in the scientific world, we expect exciting developments here. Figure 10-8 is a sample from Graphite.
 |
||||
| Figure 10-8. 3D plot from the Graphite library |
||||
Web and print versions
One key application area is on the Web. Python web applications can produce both bitmaps and print-ready documents on the fly from a web server.
Python supports many possible solutions for printing. We have looked at three: automating Word, using Windows graphics calls from PythonWin, and directly generating PDF documents. The recent evolution of a standard graphics API for Python with a variety of backends should provide more output formats in the future. The PDFgen/PIDDLE solution is lightweight (under 50 KB of code and font data), multiplatform, and scalable to large print runs; it follows the architecture of many high-volume corporate reporting systems, but with a much nicer language.
Returning to Doubletalk, our users already had an extensible application that allowed them to create their own views of the data. They are now in a position to create their own reports easily with no limits on graphical capabilities—whether as a back office job in itself, from another application, or on the Web—and to store electronic copies where they want.
Writing Word Macros by Steven Roman (O'Reilly) shows how to use VBA to automate many tasks in Word.
Word 97 Annoyances by Leonhard, Hudspeth, and Lee (O'Reilly) is a great guide to how Word works and how to live with it.
The Adobe PDF Specification (Version 1.3) is available from http://partners.adobe.com/asn/developer/PDFS/TN/PDFSPEC.PDF (5.5MB, 518 pages).
PIDDLE can be found at http://www.strout.net/python/piddle/. Graphite is at http://www.strout.net/python/graphite/. The PDFgen package (also available in the PIDDLE distribution) is found at http://www.robonal.demon.co.uk/pdfgen/index.html.