
Python can connect to a wide variety of databases using the various integration technologies we've studied. Once you've made a connection, Python's lists and dictionaries make data manipulation simple and compact, and its object model makes it easy to build object layers on top of databases.
We begin by surveying the various libraries available for connecting to a relational database and executing queries. In the second half of the chapter, we build some sample applications that demonstrate Python's abilities to manipulate data in sophisticated ways. We presume a knowledge of basic SQL and familiarity with the concepts of relational databases.
Nowhere in the computing world do acronyms fly so thick and so fast as with databases (GBFLAs stands for Great Big Five-Letter Acronyms). Microsoft has produced a bewildering array of data-access APIs over the years. For most applications, these will be the primary means of getting at your data. We'll run through the common ones and try to put them in context. If you are an experienced Windows database developer, you may wish to skip ahead to the section, "Getting at Your Data," later in this chapter.
Vendors of client/server systems such as Oracle and Sybase generally provide a CD of client software to be installed on any PC that needs to connect to one of their servers. This software often includes a tool to keep track of the various data-
base servers on the network, a custom network protocol on top of TCP/IP, various administrative applications, command-line SQL clients, and various programming interfaces to the database.
At the lowest level, C libraries and/or preprocessors are included to allow C programs to execute queries against a database. Python modules have been written around these libraries for (at least) Oracle, Sybase, Informix, Solid, MySQL, and Interbase.
Proprietary APIs often give the fastest connections and allow access to proprietary features of a particular database. However, SQL is supposed to be a standard, and users want the freedom to switch databases without unreasonable pain, so Microsoft has been working on standard interfaces to databases for many years.
Open Database Connectivity (ODBC) is a standardized API that provides universal database access and is available on all Windows systems.* It consists of a DLL that exposes standard functions to connect to and query databases, and a piece of software to manage connections. Each database vendor still has to provide the necessary software to connect to their own database, as well as an ODBC driver that allows it to fit into the ODBC framework. Click Start ® Settings ® Control Panel ® 32-bit ODBC to see the ODBC Data Source Administrator (see Figure 13-1).
Each machine provides a list of named data sources; these can be configured for a single user or available to the whole system. Clicking Add or Configure leads to a set of dialogs specific to the database vendor; for example, for a local Microsoft Access database you essentially just select the file to use. Once a data source has been defined, any of your programs can connect to that data source by name using ODBC.
This architecture has some enormous benefits. With care, it's possible to start prototyping with a data source named ''Accounts'' on a local Access database, and then switch to using (for example) a remote Oracle server with the same structure just by changing the configuration.
Because the capabilities of databases vary so widely, the ODBC API offers a wide range of functions at three levels of compliance. Level 1 compliance is the absolute minimum and is used for things like providing SQL access to text files; Level 2 is generally regarded as the minimum feature set for anything that is sold as a relational database.
| * Formally speaking, it implements the ANSI SQL Part III specification for a Call Level Interface to relational databases. In other words, it's not just Microsoft; it's an approved ANSI standard. | ||||
 |
||||
| Figure 13-1. ODBC Data Source Administrator |
||||
ODBC will be our main tool for working with databases on Windows. We'll go through some examples later.
Microsoft Access is the world's most popular desktop relational database, used extensively for individual and small business systems. Although it can be used on a network, it isn't a proper client/server system. If five users share a database across a network, there are five separate applications all opening and closing the same data file. Access doesn't scale up to high volumes of users.
From the beginning, Access was split into a GUI (what you see when you start Access) and an engine called Jet. The Data Access Object (DAO) hierarchy was an object hierarchy for getting at the Jet engine; it contained objects to represent databases, tables, relationships between tables, fields, and queries. It was originally accessible only from Access and Visual Basic. The ability to rapidly build database applications was one of the key factors in Visual Basic 3's huge popularity. With the arrival of Office 95, the DAO hierarchy became a full-fledged set of COM servers, allowing any COM-enabled language to open databases.
The popularity of this development model rapidly led to a demand to connect the same applications to client/server databases, and the DAO hierarchy was extended allowing it to use ODBC connections under the hood as well as Access databases.
DAO now provides a comprehensive COM interface to a wide range of databases. It is available on all Windows systems with Office 95 or 97.
Remote Data Objects (RDO) is another COM object hierarchy, layered on top of ODBC instead of the Jet engine. When you use DAO to get at an ODBC database, you are actually using RDO objects. RDO is popular among corporate developers because it offers support for features such as prepared statements and calling stored procedures. The most visible manifestation of RDO is the Remote Data Control in Visual Basic, which helped to remedy the truly appalling performance of the Data Control when operating on remote databases.* RDO is stable and works well, but is not as popular as DAO. It is unlikely to be developed further.
OLEDB (which probably stands for Object Linking and Embedding Database, but as far as we can tell has never been written out in full before now) is intended as a successor to ODBC. ODBC allowed connection to relational databases; OLEDB extends this to allow querying of arbitrary data providers such as hierarchical file-systems, mailboxes in Microsoft Exchange, text files, and nonrelational mainframes. It contains functionality to let you determine the capabilities of a provider at runtime. Many database vendors have now written OLEDB providers, and it can work through ODBC for those that have not. OLEDB consists of a wide range of low-level COM interfaces, and OLEDB programming is usually done by people writing database drivers; Microsoft provides an easy-to-use layer above it, as we will see next.
By now you should be sufficiently attuned to Microsoft terminology to realize that terms using Active are (a) invented by their marketing department and devoid of precise technical meanings and (b) probably something to do with COM. ActiveX Data Objects (ADO) is not a new technology, but simply an easy-to-use COM object hierarchy on top of OLEDB. It is bundled with Visual Basic and Visual C++ 5.0 and higher; look in the MakePy window for Microsoft ActiveX Data Objects Library 2.0. It looks superficially similar to DAO and RDO but offers vastly greater
| * The Data Control allows you to build a database form by setting a few properties and linking text boxes to database fields. It queries the database at runtime about the kinds of fields available in the tables to which it's bound; this works fine with Jet, which has the information readily available, but generates unbelievable traffic over a client/server connection. We've watched it by logging ODBC calls, and each data control makes a separate connection; one application might have 10 or 12 database connections open. | ||||
capabilities under the hood and is thoroughly geared to the needs of client/server systems. Microsoft has stated that they will put no effort into further enhancements of RDO, DAO, and ODBC (although they are committed to supporting ODBC for the long haul), so ADO sounds like the COM interface of the future. Here are some of the enhancements offered:
� A programmer can trap events before or after commands are executed.
� A command object wraps stored procedures and simplifies setting parameters.
� ADO exposes objects that wrap up the data definition language of a data store, meaning you can write code to create and modify tables and indexes, which works against a variety of underlying databases, even nonrelational ones.
� ADO supports hierarchical recordsets, which consist of prejoined master and detail recordsets.
� Disconnected recordsets and batch updates are perhaps the most exciting features. An application for a salesman with a laptop could connect to a database before going to fetch a recordset. The recordset can be kept open after the connection to the database is closed and saved to and from files on disk. On return, it can be resynchronized with the database. ADO takes care of the persistence and of keeping track of what has changed.
The last three features will probably be exciting for Visual Basic developers, since that language doesn't let you get hold of data as directly as Python; database data generally lives in a recordset throughout the life of a program, and so, is less relevant to us. Experienced SQL developers prefer to write their own CREATE TABLE statements by hand and are quite happy without an object layer in the way. Hierarchical data shaping and persistence are simple in Python, as you will see shortly.
ODBC is our preferred interface technology. It is widely supported, here for the long haul, and offers all the features serious database developers require. There is an ODBC module included in the PythonWin distribution, and two enhanced ones available for download, which we examine next. As you will see, these provide the fastest and simplest ways of getting data out of a database and into Python variables. DAO is of interest because it is a standard part of Office and in such wide use; it may be relevant if you are dealing specifically with Access databases. However, ADO seems set to take over and offers significant benefits, as well as a fairly straightforward transition from DAO. We show some examples of all three in the next section, but we'll concentrate mainly on ODBC for our more advanced examples.
Python has its own database API. This is intended so that people writing wrappers around ODBC and vendor-specific database drivers should expose the same database API to Python. The Database Special Interest Group (DB-SIG) maintains the database API, and has a mailing list and archives relating to it at http://www.python.org/sigs/db-sig/.
Version 2.0 of this standard has just been released; we include a full copy in Appendix C, The Python Database API Version 2.0. The various ODBC modules we demonstrate in this chapter conform closely to the standard, so we will confine ourselves here to a brief discussion of what it encompasses:
Connection objects
Connection objects manage a connection to the database. They can be opened and closed, and can commit and roll back transactions. They may offer methods or properties to set global aspects of the connection, such as transaction behavior. Everything else is done through cursor objects.
Cursor objects
These manage the context of a single statement. Users ask the connection objects to create cursors, and assign an SQL statement to the cursor. The cursor handles control of execution and of iteration through the result set. It also defines a standard format for descriptive information about the fields in the result set. Cursors provide support for parameterized queries and prepared statements.
Standard information provided
A database connection or module should be able to return information about its capabilities. These include:
— The API level to which it conforms: level 2 offers many more features than level 1. See Appendix C for details.
— The parameter style to use for arguments to prepared statements; a question mark is the most common.
— Information about how safe the module is to use with threads.
Standard errors
A standard set of exceptions is defined for database work, helping users to distinguish between SQL syntax errors, integrity warnings in the database, invalid SQL, and so on.
Standard data types
Databases have special types to represent null, dates and times, binary objects, and row IDs. Each DB-API-compliant module may create its own objects to handle these, but the constructor for them is defined. Thus, calling mymodule.
Date(1999,12,31) should return a valid Date object suitable for insertion in the database, even if the implementation of the Date object varies from one database module to another.
The Python DB-API is simple and straightforward, yet offers the features needed for high-performance database development.
Because it's just been released, adherence to the new Version 2.0 database API isn't perfect, so we'll briefly note the differences from the 1.0 specification. Version 1.0 offered the same connection and cursor objects, but defined a shared helper module named DBI (presumably short for Database Independence) that offered standard Date and RAW types. It also did not define the standard exceptions and driver information features.
As we noted earlier, there are many Python interface modules available; generally, one for each database vendor. We will concentrate exclusively on the ODBC modules, because ODBC drivers are available for virtually all database servers.
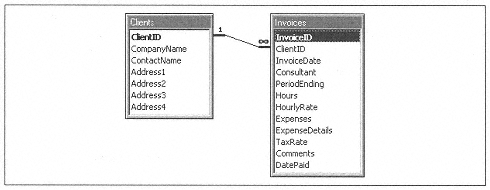
In this section we show how to execute SQL queries and fetch data using ODBC, DAO, and ADO. First, you need a database. The examples for this chapter include an Access database called pydbdemos.mdb. You could as easily use any database you can access, of course modifying the SQL statements as needed. The sample database consists of a list of clients and invoices, with the structure shown in Figure 13-2.
 |
||||
| Figure 13-2. Structure of PYDBDEMOS database |
||||
If you wish to use the sample database, you need to configure an ODBC data source as follows:
1. Click on Start ® Settings ® Control Panel ® 32-bit ODBC ® User (or system) DSN ® Add.
2. Select Microsoft Access Driver from the list of drivers.
3. Enter the name PYDBDEMOS in the box for Data Source Name.
4. Click the Select button and locate the file pydbdemos.mdb.
5. Click OK. The new data source should now be visible in the list.
6. Click OK to close the ODBC Data Source Administrator. Some versions of Windows contain a bug that causes an error message at this point. Ignore any messages; your data source is registered correctly.
Since Access isn't a server, we have worked with Sybase SQL Anywhere for some of the advanced examples. This is an excellent commercial database engine costing little more than Access and part of a range of products ranging from embedded database engines to enterprise servers. We've kept the Sybase examples to a minimum to illustrate the principles, and you certainly don't need a client/server system to follow this chapter. If you are working from home and want to experiment with the techniques used in large-scale database development, you'll find that most commercial database vendors are generous with extended evaluation copies and cut-down developer editions; their business model is to charge for connections to servers, and it's in their interest to encourage developers to try them.
PythonWin includes an ODBC module that is mature and stable, but no longer being developed and only Level 1.0-compliant. However, it has the advantage of being small, light, and present in every PythonWin distribution. It depends on the DBI module that defines certain data types (such as dates) and must be imported first: more on this later. It consists of two extension files in the win32 subdirectory, odbc.pyd and dbi.pyd. Here's how we fetch some data:
>>> import dbi #database independence utilities
>>> import odbc #the ODBC module itself
>>> from pprint import pprint #pretty-print function
>>> myconn = odbc.odbc('PYDBDEMOS')
>>> mycursor = myconn.cursor()
>>> mycursor.execute('SELECT ClientID, CompanyName, Address1 FROM Clients')
>>> mydata = mycursor.fetchall()
>>> mycursor.close() #close cursor when done
>>> myconn.close() #close database when done
>>> pprint(mydata)
[('MEGAWAD', 'MegaWad Investments', '1 St. Fredericks-Le-Grand'),
('NOSHCO', 'NoshCo Supermarkets', '17 Merton Road'),
('GRQ', 'GRQ Recruitment', None)]
>>>
The fetchall() method converts the entire result set to a list of tuples of Python variables in one call.
The connection object is constructed with an ODBC connection string. It can be as simple as the data source name or can include a username and password; a real-world connection string might looks like this:
DSN=MYDATABASE; UID=MYUSER; PWD=MYPASSWORD
If you attempt to connect to a secure database without a password, the database driver pops up a login dialog. Access has a default user ID, Admin, and an empty password unless you enable security.
The cursor object managers a query. Once the query has been executed, you can use it to get information about the underlying fields. In the previous example you closed the cursor, but if it was still open, you could do this:
>>> pprint(mycursor.description)
[('clientid', 'STRING', 10, 10, 0, 0, 1),
('companyname', 'STRING', 50, 50, 0, 0, 1),
('address1', 'STRING', 50, 50, 0, 0, 1)]
>>>
The seven elements are: name, type_code, display_size, internal_size, precision, scale, and null_ok. Not all databases (or ODBC drivers, or Python interfaces) provide this information, but all the ones we have looked at manage the field name correctly.
Cursors also control how the information is retrieved. Some queries return large sets of data, and it is inefficient to always send all of them across a network to a client. We used the fetchall() method to ask for every row of data. There are also fetchone() and fetchmany() methods, which retrieve either one row or a block of rows, moving forward though the result set; they both return None when they reach the end. Cursors have a property arraysize you can set to determine the number of rows retrieved by a call to fetchmany().
Cursors can also execute UPDATE and INSERT statements or SQL Data Definition Language statements, such as CREATE TABLE. The call to execute() returns the number of rows affected:
>>> mycursor = myconn.cursor()
>>> mycursor.execute('UPDATE Invoices SET Hours=42 \
WHERE InvoiceID=199904001')
1
>>>
However, at this point we reach a major limitation with the PythonWin ODBC module: it doesn't support prepared statements (at least not on any of the data-
base we tested against). If you don't know what this means, rest assured, all will be revealed at considerable length in the following sections.
For the most part, ordinary Python variables are exactly what one needs to hold database values; they can hold integers, floating-point numbers, or strings (including strings of large binary data). The previous console session included the statement import dbi at the beginning. This statement must be executed prior to import odbc. This module defines a date type to use when working with databases, as well as the standard data types used by the ODBC API. Let's try a query that returns some dates and play with them. Assume the connection is still open:
>>> mycursor = myconn.cursor()
>>> mycursor.execute('SELECT ClientID, InvoiceDate, Consultant, \
Hours FROM Invoices')
>>> mydata = mycursor.fetchall()
>>> pprint(mydata)
[('MEGAWAD', <DbiDate object at 10f0dc0>, 'Joe Hacker', 40L),
('MEGAWAD', <DbiDate object at 10f0c40>, 'Arthur Suit', 24L),
('MEGAWAD', <DbiDate object at 10f1ed0>, 'Joe Hacker', 57L),
('NOSHCO', <DbiDate object at 10f1e00>, 'Tim Trainee', 18L)]
>>> dateobj = mydata[0][1] # grab the date from the first row
>>> dateobj
<DbiDate object at 10f0dc0>
>>> int(dateobj)
924044400
>>> str(dateobj)
'Wed Apr 14 00:00:00 1999'
>>> print dateobj
Wed Apr 14 00:00:00 1999
>>>
Dates are returned as DbiDate objects. These can be treated as integers or floating point numbers, in which case you get the number of seconds since January 1, 1970 (the Python and Unix time system), or as strings, in which case you get a printable representation.
When modifying or inserting rows in a database, the syntax and format options may vary from vendor to vendor. However, there is also a standard ODBC syntax for embedding dates in SQL strings that should always work. That syntax uses the format {d �yyyy-mm-dd�}. With Microsoft databases you can also use either a string enclosed with hashes, or a Microsoft date serial number,* which is based on the number of days since 1900:
>>> mycursor.execute('UPDATE Invoices SET InvoiceDate={d '1999-04-15' }
WHERE InvoiceID=199904001') # preferred
1
| * This is the system used in COM dates as seen in Chapter 9, Integration with Excel. | ||||
>>> mycursor.execute('UPDATE Invoices SET InvoiceDate=36265 WHERE
InvoiceID=199904001')
1
>>> mycursor.execute('UPDATE Invoices SET InvoiceDate=#15-Apr-99# WHERE
InvoiceID=199904001')
1
>>>
The ODBC module distributed with PythonWin is a minimal implementation, and conforms to Version 1.0 of the Python Database API. It's stable and works well, but is unlikely to be developed further. Then again, neither is ODBC!*
If you work extensively with databases, check out Marc-André Lemburg's mxODBC extension package, available from http://starship.python.net/crew/lemburg/. One of its many features is an enhanced set of date and time types to save you from worrying about Microsoft and Unix date systems. These are available as a separate package, mxDateTime, which can be used in nondatabase applications. mxODBC also runs on Unix. mxODBC has some licensing restrictions; check the web site for the latest details.
mxDateTime and mxODBC are both shipped as packages that should be unzipped somewhere on the Python path** The latter creates a directory and package named—you guessed it—ODBC. There is a naming collision with the old ODBC module, which lives in �Python\win32\odbc.pyd; we suggest renaming this to something else, such as win32odbc.pyd, so that you can still access the old module if you want to (note, however, that you need to rename the module back to the original odbc.pyd before it can be used again). It contains a number of subpackages aimed at other platforms; the functionality we want is in the module ODBC.Windows. Let's give it a try:
>>> import ODBC.Windows
>>> conn = ODBC.Windows.Connect('PYDBDEMOS')
>>> cursor = conn.cursor()
>>> cursor.execute('SELECT InvoiceID, ClientID, InvoiceDate FROM Invoices')
>>> from pprint import pprint
>>> pprint(cursor.description)
(('InvoiceID', 4, None, None, 10, 0, 1),
('ClientID', 12, None, None, 10, 0, 1),
('InvoiceDate', 11, None, None, 19, 0, 1))
>>> data = cursor.fetchall()
>>> pprint(data)
| * Microsoft is committed to extending ODBC as needed to comply with developments such as SQL3, without breaking existing code. | ||||
** There are plans to merge the two into one package in the near future. At the time of this writing, the current versions are 1.1.1 for mxODBC and 1.3.0 for mxDateTime.
[(199904001, 'MEGAWAD', 1999-04-15 00:00:00.00),
(199904002, 'MEGAWAD', 1999-04-14 00:00:00.00),
(199904003, 'MEGAWAD', 1999-04-21 00:00:00.00),
(199904004, 'NOSHCO', 1999-04-22 00:00:00.00)]
As can be seen, the interface is almost identical. A recent change in the Python Database API has been to use Connect () as the constructor for connection objects rather than ODBC (), but mxODBC supports both forms, as well as the lower case connect ().
mxODBC offers access to a wide range of options and SQL constants that can control the behavior of a connection. The most important of these determines whether the connection commits every statement as it's executed or accumulates them in a transaction. The default behavior is to begin a transaction, so that changes to the database are permanent only when a user calls cursor.commit (). This can be modified two ways. First of all, when connecting, one can supply an argument as follows:
>>> myconn = ODBC.Windows.Connect('PYDBDEMOS', clear_auto_commit=1)
>>>
Second, one can set this and a wide range of other options through the setconnectoption (option, value) and getconnectoption (option) methods. The SQL object provides access to the full set of 636 ODBC constants that (among other things) define the options and possible values. Thus, you can achieve the same with:
>>> myconn.setconnectoption(SQL.AUTOCOMMIT, SQL.AUTOCOMMIT_ON)
>>> myconn.getconnectoption(SQL.AUTOCOMMIT)
1
>>>
This feature allows access to most of the key capabilities of ODBC drivers.
Now we'll take a quick look at the date and time functionality. The mxDateTime package was developed after much discussion on the Python DB-SIG to provide a platform-independent way to move data and time data between databases and applications. Its internal epoch is the year dot, giving it a far greater range than COM dates. The first thing to note is that the date objects in the previous session were smart enough to represent themselves in a readable manner! We'll grab a date out of the row above and play with it:
>>> aDateTime = data[0] [2]
>>> type(aDateTime)
<type 'DateTime'>
>>> int (aDateTime)
924130800
>>> str(aDateTime)
'1999-04-15 00:00:00.00'
>>>
mxDateTime also provides a large array of constants, methods, and submodules to perform date and calender calculations, parse dates, and even work out holidays. The following snippet should give you a feel:
>>> import DateTime
>>> DateTime.DateTimeFromCOMDate(0) # the Microsoft system
1899-12-30 00:00:00.00
>>> aDateTime.COMDate() # convert to Microsoft COM/Excel dates 36265.0
>>>
>>> DateTime.now() - aDateTime # RelativeDateTime object
<DateTimeDelta object for '16:23:40:16.18' at 1106530>
>>> aDateTime + DateTime.RelativeDateTime(months=+3)
1999-07-15 00:00:00.00
>>> >>> # first of next month�
>>> aDateTime + DateTime.RelativeDateTime(months=+1,day=1)
1999-05-01 00:00:00.00
>>> DateTime.now()
1999-05-01 23:42:20.15
>>> DateTime.Feasts.EasterSunday(2001)
2001-04-15 00:00:00.00
>>> DateTime.Parser.DateFromString('Friday 19th October 1987')
1987-10-19 00:00:00.00
>>>
A DateTimeDelta is defined for the difference between two points in time, and there are a full set of mathematical operations defined. Submodules include date parsers, holidays, and routines for ARPA and ISO dates. A large number of business applications need to handle dates and times intelligently, and these functions make it extremely easy and quick.
One of the key advantages of mxODBC is that it properly supports prepared statements. While these will be familiar to database programmers who work in C, they may not be to people used to standard Visual Basic or Delphi database development tools, so we'll explain the background.
There are two stages to the execution of an SQL statement. First, the database parses the SQL, works out a plan for executing the query, and compiles it into an executable routine. Second, the database executes the statement and returns the result set. For complex queries joining several tables, the parsing is not a trivial step, and may involve some analysis of the size of tables and the best order in which to filter records. It also consumes a large amount of memory compared to the subsequent execution.
If you wish to perform the same kind of query repeatedly (for example, inserting 1,000 rows in a table), the statement could, in theory, be parsed only once, leading to substantial performance gains. To support this, it's necessary to separate the SQL statement structure from the actual parameters to go into the database.
If you are working with ODBC in C, you execute one call to get a handle to the SQL statement, then others to actually call it repeatedly with differing data. In Python it is much simpler: just parameterize the statement, using a question mark as a placeholder:
>>> stmt = "UPDATE Invoices SET Hours = ? WHERE InvoiceID = ?"
>>> mycursor.execute(stmt, (45, 199904001))
1
>>>
mxODBC and any other DBAPI-compliant interface do the right thing to pass the arguments to the database, whatever their type. Don't confuse this with Python's modulo operator for substituting into strings.
At this point you've executed only a single statement. However, the cursor object is now caching a handle to the prepared statement; so a subsequent call of the form cursor.execute(stmt, newdata) will be much faster on any client/server database. Later in the chapter, you'll discover how much faster, when we bench mark a range of data access methods.
If you have a large block of data to insert or update, there's a method named executemany(),* which takes a block or rows and saves the need to write a Python loop to insert each one. The following snippet shows the most efficient way to do a bulk insertion or update. The SQL statement is parsed only once:
>>> mycursor.executemany(stmt,
� [ #begin a list of values
� (45, 199904001),
� (53, 199904002),
� (52, 199904003)
� ] )
1
>>>
Note that the block of data supplied is a list of tuples, the same format returned from fetchall() or from 2D COM arrays. Other languages let you work with one field at a time; Python lets you manipulate whole blocks of data in a single line!
The importance of prepared statements is hard to overstate. First of all, on single queries on a database that is being used lightly, there can be an increase of up to 50% in query execution. Second, if a system is designed to use only prepared
| * executemany() is the new standard, but many interface modules (including mxODBC and Gadfly) allow you to pass a list of tuples to execute() as well | ||||
statements, it consumes far less server memory, enabling it to support many more users and perform better under heavy loads. Third, it saves you a lot of work; there's no need to build the full SQL string yourself, leaving you free to concentrate purely on manipulating blocks of Python variables.
One key feature offered by client/server databases (but not Microsoft Access) is the stored procedure. This is a named, precompiled procedure in the database that may be called from outside: conceptually, a function you can call, complete with arguments. As well as offering the same performance benefits as prepared statements, these allow the database to encapsulate business logic. For example, rather than letting developers directly execute SQL on a group of tables relating to invoices, database administrators can provide an interface allowing the users to add, edit (only where appropriate), and query interfaces. This is standard practice in many companies, and ad hoc queries by users are sometimes banned because of concerns over database integrity or performance.
Access doesn't offer this feature, so we'll switch to a demonstration version of Sybase Adaptive Server Anywhere. The example database provided includes tables of customers and products, and a stored procedure interface to them. The procedure sp_product_info accepts a product ID as argument and returns information on that product gathered from several tables.
The DBAPI recommends that cursors can optionally offer a method named callproc(procname, [parameters]). It's optional because many databases, such as mySQL and Access, don't offer stored procedures. At the time of writing this was not yet implemented in mxODBC. Nevertheless, they can be called using standard SQL without trouble, as follows:
>>> mycursor.execute('sp_product_info(500)')
>>> mycursor.fetchall()
[(500, 'Visor', 'Cloth Visor', 'One size fits all', 'White', 36, 7.0)]
>>> mycursor.execute('CALL sp_product_info(500)'
>>> mycursor.fetchall()
[(500, 'Visor', 'Cloth Visor', 'One size fits all', 'White', 36, 7.0)]
>>> mycursor.execute('EXEC sp_product_info(500)')
>>> mycursor.fetchall()
[(500, 'Visor', 'Cloth Visor', 'One size fits all', 'White', 36, 7.0)]
There is a third Python module for working with ODBC that operates on different lines. Sam Rushing (http://www.nightmare.com) specializes in low-level work with Python and Windows and has produced a package named calldll that allows Python programs to dynamically load and call any function in a DLL. We discuss how this works in Chapter 22, Extending and Embedding with Visual C++ and Delphi. It has allowed Sam to produce an ODBC module that wraps and exposes almost every function in Microsoft's ODBC.DLL. To install this, you need to download the two files calldll.zip and dynwin.zip from his site. The latter contains a number of modules relating to ODBC. Naturally, one of these is called odbc.py, so you need to watch for name collisions. If you've been using the previous two modules, rename them out of the way before starting.
As with the other modules, calldll provides a safe, easy-to-use high-level interface for querying databases, but it bears no resemblance to the DBAPI. Here's the high-level usage:
>>> import odbc
>>> env = odbc.environment()
>>> conn = env.connection()
>>> conn.connect('accessdemo')
>>> import pprint
>>> pp = pprint.pprint
>>> results = conn.query('SELECT * FROM Invoices')
>>> pp(results[0]) #field information
[('InvoiceID', 4, 10, 0, 1),
('ClientID', 12, 10, 0, 1),
('InvoiceDate', 11, 19, 0, 1),
('Consultant', 12, 50, 0, 1),
('PeriodEnding', 11, 19, 0, 1),
('Hours', 8, 15, 0, 1)
('HourlyRate', 2, 19, 4, 1),
('Expenses', 2, 19, 4, 1),
('ExpenseDetails', 12, 50, 0, 1),
('TaxRate', 8, 15, 0, 1),
('Comments', 12, 50, 0, 1),
('DatePaid', 11, 19, 0, 1)]
>>> pp(results[1]) #first data row
['199904001',
'MEGAWAD',
'1999-12-31 00:00:00',
'Joe Hacker',
'1999-04-18 00:00:00',
'43.0',
'50.0000',
'0.0000',
None,
'0.175',
None,
None]
>>>
The high-level interface includes classes to represent the environment, connections, and statements. Perhaps of more interest is what happens when you drop down a level. Sam has encapsulated the idea of an ODBC function call in a general way. Let's take a look at his own source code for the connect() method:
def connect (self, dsn, uid=", auth="):
self.dsn = cstring (dsn)
self.uid = cstring (uid)
self.auth = cstring (auth)
retval = odbc.SQLConnect (
self, # connection handle
self.dsn, self.dsn.strlen(), #data source name
self.uid, self.uid.strlen(), #user identifier
self.auth, self.auth.strlen(), #authentication (password)
)
if retval in (SQL_SUCCESS, SQL_SUCCESS_WITH_INFO):
self.connected = 1
else:
raise error, 'SQLConnect failed: %d' % retval
If you're an experienced ODBC programmer working from C or C++, you'll recognize the call to SQLConnect and the constant values such as SQL_SUCCESS. The ODBC module in DynWin exposes the entire ODBC API to the programmer, offering the same possibilities as with programming in C.
One word of warning: while the high-level interface is reliable and quite friendly, the technologies underneath DynWin and calldll are less forgiving than most Python extensions. If you drop down to the lowest levels and call ODBC functions with the wrong arguments, it's possible to corrupt the stack and crash your program, the same as in C.
We expect this module to be of interest to experienced C and C++ programmers who know the ODBC API and wish to work with it at a low level. If this doesn't describe you, stick with the other ODBC modules; the performance is the same, but the interface operates at a much higher level of convenience.
The Data Access Object hierarchy is installed on your system if you have Microsoft Office, Access, or Visual Basic, or if you have ever installed a VB application that works with MDB files. It doesn't need an ODBC data source configured. We recommend running MakePy over the latest version of the Microsoft DAO Library on your system, as seen in Figure 13-3.
The hierarchy starts with a database engine (class DBEngine) and allows you to open multiple Database objects. Once a database is open you can create Recordset objects that are the broad equivalent of a cursor in the Python Database API. You can navigate through a Recordset and edit its fields. A Field is an object too, with a Name, a Value, and many more properties.
Let's start by connecting to the same database as before. This time you don't need the ODBC data source, but can go straight for the file:
>>> import win32com.client
>>> daoEngine = win32com.client.Dispatch("DAO.DBEngine')
 |
||||
| Figure 13-3. MakePy showing the DAO and ADO libraries |
||||
>>> daoDB = daoEngine.OpenDatabase('C:\\MYDIR\\pydbdemos.mdb')
>>> daoRS = daoDB.OpenRecordset('SELECT ClientID, InvoiceDate, \
Consultant, Hours FROM Invoices')
>>> daoRS.MoveLast() # need to do this to get an accurate size
>>> daoRS.RecordCount
4
>>>
Opening the database and getting the result set is no harder than with the Python API and ODBC. However, instead of calling fetchall() to create a Python list of tuples, you have a Recordset object through which you must iterate. Before, you stepped to the end and got a record count. Now let's look at some data:
>>> daoRS.MoveLast()
>>> daoRS.Fields('ClientID').Value # reference fields by name
'NOSHCO'
>>> daoRS.Fields(3).Value # or by position
18.0
>>> for i in range(daoRS.Fields.Count):
� daoField = daoRS.Fields[i]
� print '%s = %s' % (daoField.Name, daoField.Value)
�
ClientID = NOSHCO
InvoiceDate = <time object at 1191860>
Consultant = Tim Trainee
Hours = 18.0
>>>
The normal mode of operations is to work a field at a time, asking for the exact values you want. However, there's a method called Recordset.GetRows ( [rows_
to_fetch]) that can grab data in bulk. It returns the next few rows from the current position:
>>> daoRS.MoveFirst()
>>> data = daoRS.GetRows(4)
>>> pprint(data)
((L'MEGAWAD', L'MEGAWAD', L'NOSHCO'),
(<time object at 11921f0>,
<time object at 11921d0>,
<time object at 11921b0>,
<time object at 1192190>),
(L'Joe Hacker', L'Arthur Suit', L'Joe Hacker', L'Tim Trainee'),
(42.0, 24.0, 57.0, 18.0))
There are two things to notice. First, GetRows() returns columns, not rows. The matrix is transposed compared to the Python representation. Second, this is a COM server, so you get back Unicode strings and the date objects defined by the Python COM framework. As a reminder, let's take another look at the third date type:
>>> aDate = data[1][0] # remember how these dates work?
>>> type(aDate)
<type'time'>
>>> int (aDate) # can coerce to a Python date�
924130800
>>> aDate.Format() # �and knows how to display itself
'04/15/99 00:00:00'
>>>
It's possible to update and insert records using DAO, but the normal technique is to use the Edit() and AddNew() methods of a RecordSet as follows:
>>> daoRS2 = daoDB.OpenRecordset ('SELECT * FROM Clients')
>>> daoRS2.AddNew()
>>> daoRS2.Fields('ClientID').Value = 'WOMBLES'
>>> daoRS2.Fields('CompanyName').Value = 'Wimbledon Garbage Disposal Ltd.'
>>> daoRS2.Fields('ContactName').Value = 'Uncle Bulgaria'
>>> daoRS2.Update() # save the record
>>> daoRS2.Close()
To modify an existing record, use Edit() rather than AddNew() at the beginning.
This highlights what is arguably a benefit of the DAO model: the database does type checking on individual fields as you assign them. If you try to put a string in a date field, you get an error on the relevant line of code, whereas debugging long UPDATE or INSERT statements can take a little longer. However, for large volumes of insertions, working with an ODBC module's executemany() method is simpler since there is no need to loop over the fields in Python and DAO.
ADO looks almost identical to DAO at this level of detail; Microsoft simplified the object model considerably but kept the essentials the same. The big differences are that (a) data providers other than ODBC are permitted, and (b) all the Access specifics, including direct access to tables and relationships, have been dropped. The data provider can be specified either in a connection string or in a Provider property of the Connection object, before the connection is opened. Microsoft has data providers for the following applications at present:
� ODBC
� Microsoft Index Server
� Active Directory Services
� Jet engine (via DAO)
So, despite all the hype, you're still going to use either ODBC or DAO under the hood somewhere. We'll use our ODBC alias again:
>>> import win32com.client
>>> adoConn = win32com.client.Dispatch('ADODB.Connection')
>>> adoConn.Open('PYDBDEMOS') # use our ODBC alias again
>>> (adoRS, success) = adoConn.Execute('SELECT * FROM Clients')
>>> adoRS.MoveFirst()
>>> adoRS.Fields("CompanyName").Value
'Megawad Investments'
>>>
Adding, editing, and using GetRows() is identical to DAO. We won't go into the advanced capabilities of ADO here; numerous references are available.
You should use ADO if you know it's installed on client machines, because it's the COM API of the future. However, at the time of writing, you can count on DAO being present on all machines with a copy of Office, and ADO is not yet so widespread. If you stick to basic SQL statements, porting code between the two should be easy.
With database systems, performance is always important. A badly designed client/ server system can cost a great deal of money and have a shorter life than planned if attention is not paid to the way client applications interact with the server. Even with PC-based systems such as Access, database applications can often become slow, especially when multiple dynamic views of the data are used. Having discussed a wide range of data-access techniques, we now include some rough performance benchmarks. These are intended to show only the rough characteristics of different data-access APIs.
The standard task covered is to insert 1,000 rows into a simple table.The sample table, named analysis, can be thought of as a crude repository for financial data; it has four fields, tranid (integer), trandate (date), account (string) and amount (currency). To slow it down a bit, it's indexed uniquely on tranid and indexed with duplicates allowed on trandate and account. Thus any insertion involves updating three indexes. We created instances of this database in our sample Access database and in Sybase SQL Anywhere. It starts off empty. The tests were run on a Pentium 266, with client and server on the same machine and no other activity taking place. The source code for the test is in the module fastinsert.py at http://starship.python.net/crew/mhammond/ppw32/.
We first used mxODBC to connect to both the Access and Sybase databases and tried three different techniques, which are called Slow, Faster, and Fastest in Table 13-1.
| ||||||||||||||||||||||||||||||
First, a list of tuples was prepared holding the data for the 1,000 rows. In the Slow technique, we built a literal SQL statement each time. In the Faster technique, we used prepared statements as follows:
mystatement = """INSERT INTO analysis (tranid, trandate, account,
amount) VALUES(?, ?, ?, ?)"""
for row in mydata:
mycursor.execute(mystatement, row)
In the technique called Fastest, we used the executemany() method. This is the same at the database end, but moves the loop over 1,000 records from interpreted Python code into compiled C code.
Finally, we connected to the same Access database using the Jet engine. The two techniques here were to build and execute INSERT statements directly or to use the AddNew() and Update() methods of the RecordSet object.
These results are highly instructive. Sybase is far and away the faster system, even on a local PC. Also, as theory suggests, using prepared statements brought about a speedup of 55%, while using executemany() to optimize out the loop gets us up to over 500 rows per second.
Access, however, shows no improvement at all; in fact, it actually gets slightly slower! The reason for this is that the Jet engine doesn't support prepared statements at all. The Access ODBC drivers do support them for compatibility purposes, but they presumably get converted back into separate calls in the driver. The final technique we tried with Access, using Recordset.AddNew(), was the fastest way to work with Access databases.
The moral of this story is simple: if you are building a client/server system in Python, or even prototyping a system in Access that might later be moved to client/server, use ODBC and parameterize your SQL statements. If you are building a (hopefully single-user) Access-based system that will never be moved to client/server, go with DAO or ADO.
We now step away from Microsoft APIs altogether. Gadfly is an SQL relational database written in Python by Aaron Watters. It can be found at http://www.chordate.com, and is distributed in a 200-KB Zip file, including documentation.
Gadfly gives Python programs relational database capabilities without relying on any external database engines. It offers the following features:
� Compliance with the Python Database API
� Total portability between platforms
� A transaction log and recovery procedure
� A built-in TCP/IP server mode, allowing it to serve clients on remote machines
� Security policies to prevent accidental deletion of data
It's not intended as a multiuser production system, and some features are missing at present, notably Null values and Date/Time variables.
Aaron previously produced both a parsing engine named kwParsing and a library of data structures, including sets, directed graphs, and dictionaries, called kjBuckets. These C extensions are part of the Gadfly package and can build an efficient and fast in-memory SQL engine. If you are interested in either how to parse SQL statements or in the low-level relational operations, Gadfly is a great package to explore. To install and set up Gadfly, perform these steps:
1. Download the 217-KB Zip file.
2. Unzip to a directory on the Python path.
3. CD to the directory in a DOS prompt.
4. Type python gfinstall.py.
5. Create a subdirectory for a test database with MKDIR dbtest.
6. Type python gftest.py dbtest. This creates test tables in the directory and runs a large number of queries.
Gadfly can be used in almost exactly the same way as other data sources:
>>> from gadfly import gadfly
>>> connection = gadfly("test", "c:\\mydir\\gadfly\\dbtest")
>>> cursor = connection.cursor()
>>> cursor.execute('SELECT * FROM Frequents')
>>> from pprint import pprint
>>> cursor.description # only does fieldnames at present
(('PERWEEK', None, None, None, None, None, None),
('BAR', None, None, None, None, None, None),
('DRINKER', None, None, None, None, None, None))
>>> print cursor.pp() # it can format its own output
PERWEEK | BAR | DRINKER
============================
1 | lolas | adam
3 | cheers | woody
5 | cheers | sam
3 | cheers | norm
2 | joes | wilt
1 | joes | norm
6 | lolas | lola
2 | lolas | norm
3 | lolas | woody
0 | frankies | pierre
1 | pans | peter
>>> data = cursor.fetchall()
>>>
Like most interactive SQL clients, it can format its own output with the pp() method. One immediate surprise is the speed: Gadfly operates entirely in local memory and uses highly refined logic to produce an extremely fast implementation. We won't go into how!
Gadfly offers the same ability to prepare statements as mxODBC; if the same statement is passed in repeated calls, the cursor parses it only once:
>>>insertstat = "insert into phonenumbers(name,phone) values (?, ?)"
>>>cursor.execute(insertstat, ('nan', "0356"))
>>>cursor.execute(insertstat, ('bill', "2356"))
>>>cursor.execute(insertstat, ('tom', "4356"))
>>>
A matrix of values can be passed to execute() in a single try.
Like many SQL databases, Gadfly maintains metadata in tables, and you can query the structure of a Gadfly database:
>>> cursor = connection.cursor()
>>> cursor.execute('SELECT * FROM __table_names__')
>>> print cursor.pp()
IS_VIEW | TABLE_NAME
=========================
0 | EMPTY
1 | NONDRINKERS
1 | ALLDRINKERS
1 | __INDICES__
1 | DUAL
0 | LIKES
0 | FREQUENTS
0 | ACCESSES
0 | WORK
1 | __TABLE_NAMES__
0 | SERVES
1 | __DATADEFS__
1 | __COLUMNS__
1 | __INDEXCOLS__
>>>
Apart from the data tables, you can inspect metatables of tables, indexes, and columns in this manner.
Gadfly incorporates a TCP/IP client and server, transforming it into a proper client/server system. To start the server on the machine we've already tested, run the following command from a DOS prompt:
C:\MYDIR\gadfly>python gfserve.py 2222 test dbtest admin
The arguments specify the port, the database name, the database directory, and the password. The server console should start up and display the message ''waiting for connections.''
The client machine needs only the two files, gfclient.py and gfsocket.py (as well as Python, of course). At 15 KB, this must be one of the lightest database clients around. On the client machine, start Python and run the following commands. If you don't have a second PC handy, you can run the client from a second DOS
prompt (or PythonWin prompt) on the same machine provided TCP/IP is properly installed:
>>> # on client machine
>>> from gfclient import gfclient
>>> # connect with policy, port, password, machine name
>>> conn = gfclient("admin", 2222, "admin", "tahoe")
>>> cursor = conn.cursor()
>>> cursor.execute('SELECT * FROM LIKES')
>>> pprint(cursor.fetchall())
[(2, 'bud', 'adam'),
(1, 'rollingrock', 'wilt'),
(2, 'bud', 'sam'),
(3, 'rollingrock', 'norm'),
(2, 'bud', 'norm'),
(1, 'sierranevada', 'nan'),
(2, 'pabst', 'woody'),
(5, 'mickies', 'lola')]
>>>
As the queries execute, you should see messages on the server console.
Gadfly still lacks some features of production databases, but what is there is reputedly stable and fast. It could be useful for a local client that gathers data and occasionally downloads from or uploads to a master database elsewhere. It's an excellent tool for learning about client/server and relational concepts at zero cost. However, a major niche we see for it is in data laundering; you can develop scripts rapidly and save the output to local Gadfly tables, committing the results to a destination database only when the system is fully refined and working.
We have covered a wide range of database APIs and data sources, and demonstrated that Python can connect to data from any modern database. Now we will look at some areas in which Python can do useful things with the data.
The first major area of work is what we call data laundering. This involves writing programs to acquire data from a source database, reshape it in some way, and load it into a destination database. One major difference between database development and general application development is that databases are live; you can't just switch them off for a few months. This means that what would be a simple upgrade for a Windows application becomes a much more complex process of repeatedly migrating data and running in parallel. Here are some examples of areas where this type of work is needed:
Database upgrades and changes
When a database is replaced, the new database structure is almost always different. The new database needs to be developed with sample data available, then tested extensively, then run in parallel with the old one while all the users and client applications are moved across. Scripts are needed to migrate the data repeatedly (usually daily) from source to destination, often performing validity checks on the way in.
Connecting databases
Businesses often have databases whose areas of interest overlap. A fund manager might have a core system for processing deals in its funds, and a marketing database for tracking sales calls; marketing needs a recent copy of some of the deal information to help serve the clients, possibly simplified and predigested in various ways. Again, a daily process of exporting, rearranging, and loading is needed.
Data warehouses
The classic case for repeated data laundering is the data warehouse. A company has one or more transaction-processing databases, which usually have numerous highly normalized tables, optimized for insertion and lookups of small numbers of records at any one time. A data warehouse is a second, parallel database optimized for analysis. It's essentially read-only with a simple structure geared to computing averages and totals across the whole database. This is refreshed daily in a process known as the production data load. The production data load needs to acquire data from several databases, reshape it in ways that are often impossible for SQL, validate it in various ways, then load into the destination database. This is a perfect niche for Python.
All these tasks involve writing scripts to reshape the data.
We'll now start to build a toolkit to help with these kinds of operations. The toolkit is based on real classes and functions that have been used in a number of serious projects and have proved their utility many times over (see the case study later on), although we have simplified and cut down the code considerably for this book. All the code for the rest of this chapter can be found in the module laundry.py at http://starship.python.net/crew/mhammond/ppw32/.
There are several useful ways to represent data. The most obvious is as rows. The Python format for data as rows returned from database cursors is a list of tuples.
This is such a common representation that we'll wrap it in a class called DataSet. The class doesn't serve to hide the data; it's just a convenient place to hang a load of data-manipulation methods (as well as to keep the field names). Here's part of its definition, showing how to construct a DataSet and display its contents:
class DataSet:
"Wrapper around a tabular set of data"
def __init__(self):
self.data = []
self.fieldnames = []
def pp(self):
"Pretty-print a row at a time - nicked from Gadfly"
from string import join
stuff = [repr(self.fieldnames)] + map(repr, self.data)
print join(stuff, "\n")
def DataSetFromCursor(cursor):
" a handy constructor"
ds = DataSet()
ds.fieldnames = getFieldNames(cursor)
ds.data = cursor.fetchall()
return ds
>>> import ODBC.Windows
>>> conn= ODBC.Windows.Connect('PYDBDEMOS')
>>> cursor = conn.cursor()
>>> cursor.execute('SELECT ClientID, PeriodEnding, Consultant,
Hours FROM Invoices')
>>> import laundry
>>> ds = laundry.DataSetFromCursor(cursor)
>>> cursor.close()
>>> conn.close()
>>> ds.pp()
('ClientID', 'PeriodEnding', 'Consultant', 'Hours')
('MEGAWAD', 1999-04-18 00:00:00.00, 'Joe Hacker', 42.0)
('MEGAWAD', 1999-04-18 00:00:00.00, 'Arthur Suit', 24.0)
('MEGAWAD', 1999-04-25 00:00:00.00, 'Joe Hacker', 57.0)
('NOSHCO', 1999-04-25 00:00:00.00, 'Tim Trainee', 18.0)
('MEGAWAD', 1999-04-18 00:00:00.00, 'Joe Hacker', 42.0)
>>>
The ability to see the field names becomes useful when writing data-cleaning scripts at an interactive prompt.
Now that we have the data, what to do with it depends on the operation taking place. An approach that has stood the test of time is to keep adding operations to the Dataset class, building over time a veritable Swiss army knife. Common families of operations can include:
Field transformations
Applying functions to entire columns in order to format numbers and dates, switch encodings, or build database keys.
Row and column operations
Inserting, appending, and deleting whole columns, breaking into several separate datasets whenever a certain field changes, and sorting operations.
Filter operations
Extracting or dropping rows meeting user-defined criteria.
Geometric operations
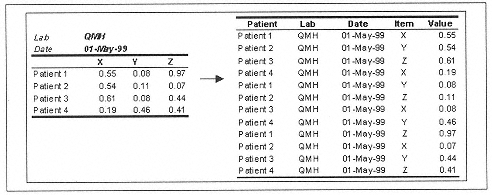
Cross-tabulate, detabulate (see Figure 13-4), and transpose.
Storage operations
Load and save to native Python data (marshal, cPickle), delimited text files, and fixed-width text files.
Some of these operations are best understood diagrammatically. Consider the operation in Figure 13-4, which can't be performed by SQL.
 |
||||
| Figure 13-4. Detabulating and adding constant columns |
||||
This operation was a mainstay of the case study that follows. Once the correct operations have been created, it can be reduced to a piece of Python code:
>>> ds1.pp() # presume we have the table above already
('Patient', 'X', 'Y', 'Z')
('Patient 1', 0.55, 0.08, 0.97)
('Patient 2', 0.54, 0.11, 0.07)
('Patient 3', 0.61, 0.08, 0.44)
('Patient 4', 0.19, 0.46, 0.41)
>>> ds2 = ds1.detabulate()
>>> ds2.addConstantColumn('Data',DateTime(1999,5,1),1)
>>> ds2.addConstantColumn('Lab','QMH', 1)
>>> ds2.pp()
('ROW', 'Lab', 'Date', 'Column', 'Value')
('Patient 1', 'QMH', 1999-05-01 00:00:00:00,
'X', 0.55)
('Patient 2', 'QMH', 1999-05-01 00:00:00.00, 'X', 0.54)
('Patient 3', 'QMH', 1999-05-01 00:00:00.00, 'X', 0.61)
('Patient 4', 'QMH', 1999-05-01 00:00:00.00, 'X', 0.19)
('Patient 1', 'QMH', 1999-05-01 00:00:00.00, 'Y', 0.08)
('Patient 2', 'QMH', 1999-05-01 00:00:00.00, 'Y', 0.11)
('Patient 3', 'QMH', 1999-05-01 00:00:00.00, 'Y', 0.08)
('Patient 4', 'QMH', 1999-05-01 00:00:00.00, 'Y', 0.46)
('Patient 1', 'QMH', 1999-05-01 00:00:00.00, 'Z', 0.97)
('Patient 2', 'QMH', 1999-05-01 00:00:00.00, 'Z', 0.07)
('Patient 3', 'QMH', 1999-05-01 00:00:00.00, 'Z', 0.44)
('Patient 4', 'QMH', 1999-05-01 00:00:00.00, 'Z', 0.41)
>>>
We won't show the methods to implement this; they involve straightforward Python loops and list slicing, as do most of the things we would want to do with a DataSet. Their effect is to take our data-laundering scripts to a higher level of abstraction and clarity.
Another useful and powerful representation of data is as a dictionary of keys and values. This leads to a much easier syntax when you edit and modify records; the field names can be used rather than numeric indexes. It's also useful when putting together data about the same thing from different sources. There will be some overlap between fields, but not total agreement. Dictionaries can represent sparse data compactly. A classic example is found in the Transaction architecture from Part II, where there was a method to convert a transaction to a list of dictionaries. A sales transaction has different keys and values from a payroll transaction.
You'll rarely want just one dictionary, so we have added the following method to convert a DataSet to a list of dictionaries:
class DataSet:
<continued�>
def asDicts(self):
"returns a list of dictionaries, each with all fieldnames"
dicts = []
fieldcount = len(self.fieldnames)
for row in self.data:
dict = {}
for i in range(fieldcount):
dict[self.fieldnames[i]] = row[i]
dicts.append(dict)
return dicts
This enables you to get a row from a query and modify it flexibly: let's grab our first invoice from the sample database and look at it. Assume you've just done a
�Select * FROM Invoices� in a cursor:
>>> dict = ds.asDicts() [0] # grab the first one
>>> pprint(dict)
| ||||||||||||||
{'ClientID': 'MEGAWAD',
'Comments': None,
'Consultant': 'Joe Hacker',
'DatePaid': None,
'ExpenseDetails': None,
'Expenses': 0.0,
'HourlyRate': 50.0,
'Hours': 42.0,
'InvoiceDate': 1999-04-15 00:00:00.00,
'InvoiceID': 199904001,
'PeriodEnding': 1999-04-18 00:00:00.00,
'TaxRate': 0.175}
>>>
You can now modify this easily, overwriting, dropping, and adding keys as needed. It's also possible to build powerful relational joins in a few lines of code using Python dictionaries; that is part of what Gadfly does.
When you want to do the opposite, tabulate a list of dictionaries easily by specifying the keys you want. The next function creates dictionaries:
def DataSetFromDicts(dictlist, keylist=None):
# tabulates shared keys
if not keylist: # take all the keys
all_key_dict = dictlist[0]
for dict in dictlist:
all_key_dict.update(dict)
keylist = all_key_dict.keys()
keylist.sort() # better than random order
ds = DataSet()
ds.fieldnames = tuple(keylist)
for dict in dictlist: # loop over rows
row = []
for key in keylist: # loop over fields
try:
value = dict[key]
except:
value = None
row.append(value)
ds.data.append(tuple(row))
return ds
If you supply a list of the keys you want, this function builds a Dataset with columns to match; if you omit the keys, it shows the set of all keys found in all dictionaries. This can be used as follows:
>>> pc1 = {'Name': 'Yosemite', 'Maker': 'Carrera', 'Speed':266}
>>> pc2 = {'Name': 'Tahoe', 'Maker': 'Gateway', 'Memory':64}
>>> pc3 = {'Name': 'Gogarth', 'Maker': 'NeXT', 'Speed':25, 'Elegance': 'Awesome'}
>>> pc4 = {'Name': 'BoxHill', 'Maker': 'Psion', 'Memory':2}
>>> my_kit = [pc1,pc2,pc3,pc4]
>>> comparison = laundry.DataSetFromDicts(my_kit,
� ['Name', 'Model', 'Memory']
� )
�
>>> comparison.pp()
('Name', 'Model', 'Memory')
('BoxHill', None, 2)
('Tahoe', None, 64)
('Gogarth', None, None)
('BoxHill', None, 2)
>>>
You now have the ability to move back and forth from a tabular to a dictionary representation.
Sooner or later you need to pump data into a destination database. We've already seen how DBAPI-compliant modules allow us to insert a list of tuples at one time, and how this provides optimal performance. In a case such as a data warehouse, the number of destination tables and fields will be quite small so it's no trouble to build the SQL statements by hand for each table; and we already have the list of tuples ready to go:
mycursor.executemany(MyTableStatement, MyDataSet.data)
Where there are many destination tables, a shortcut can be taken if the field names are simple and match the underlying database well; you can write a routine that uses the field names in the DataSet and generates an SQL INSERT statement to match.
Often there are better ways to bulk-load data. The important thing is to know that you have correctly structured DataSets for the destination database; if that's true, you can often save them to a tab- or comma-delimited file and use the database's bulk-load facility with far greater speed.
For our final example of what Python can do with data, we'll look at how Python supports building a three-tier client/server architecture. This will be a fairly straightforward example, as we did a lot of the groundwork in the last section.
Simple database applications have two tiers: database and user interface. A dialog to maintain client details might perform a SELECT query to get all the details of a customer and store those details in the user interface; either directly in text boxes, or in variables stored in the same form or module. When the data has been changed, the system performs an UPDATE query to store the results.
A three-tier architecture creates a Customer class to hold the information, and provides functions to load customers from the database and store them back to it. The GUI layer gets data from the Customer objects. Objects in the middle layer are often known as business objects, because they model things in the business or problem domain, rather than systems objects like database connections, or GUI objects like queries. If you are writing object-oriented programs, you're already at work on the business objects.
Three-tier also describes network partitioning. With modern distributed-object technologies such as COM and CORBA (and some much lighter alternatives like Python's RemoteCall package), it's easy to run the database on one machine, the business objects on another, and the GUI on a third. It's highly likely that your Customer object will pop up in many parts of the application, so the three-tier approach is much better for all but the simplest application. There's a lot of marketing hype about this. We'll just focus on the logical aspects.
Real-life databases need lots of tables to represent a business object such as a customer or an invoice. Similarly, the objects in memory are bound to have references to other objects and lists of subobjects; a Customer object may provide access to a list of invoices, and a list of correspondence items received. There is a lot of work involved in building class hierarchies and tables to match each other and code to fetch and store the right records at the right time. Furthermore, every change in the database may necessitate changing and recompiling your business object code, and vice versa.
Not with Python! Python's dynamic nature makes it possible to dramatically reduce the dependencies between database and business objects.
We saw in Chapter 6. A Financial Modeling Toolkit in Python, that Python objects can hold any attributes you want, in addition to those defined for the class. Any Python object's attributes and methods are held in a hidden, internal dictionary. And we have just learned how to fetch those!
The simplest way to construct an object from a database is to use an almost-empty class. Remember you can add attributes at runtime to a Python class as follows:
>>> class DumbDbRecord:
� pass
�
>>> r1 = DumbDbRecord()
>>> r1.CustomerID = 1234
>>> r1.Name = 'Pythonics Inc.'
>>>
It would be easy to examine a database cursor and add all attributes to an object such as this, creating a handy database record object with a clean syntax. However, this approach carries a weakness. You presumably will want to write objects that have attributes and methods important to the functioning of the program, and to keep them separate from data fetched from the database. We've therefore defined a class that can accept a dictionary of fields and values and keep them separate from its own attributes.
A helpful piece of Python magic is the ability to trap attribute access. We saw in Chapter 6 that a Python object can monitor attempts to set or get its attributes. If you ask an instance of this next class for an attribute it can't find, it goes and checks in the dictionary it got from the database:
class Record:
#holds arbitrary database data
def __init__(self):
self._dbdata = {}
def loadFromDict(self, aDict):
"accept all attributes in the dictionary"
self._dbdata.update(aDict)
def getData(self):
return self._dbdata.copy()
def pp(self):
"pretty-print my database data"
pprint(self._dbdata)
def __getattr__(self, key):
"""This is called if the object lacks the attribute.
If the key is not found, it raises an error in the
same way that the attribute access would were no
__getattr__ method present. """
return self._dbdata[key]
Now you can use it to represent any kind of object you want and access the variables with the most natural syntax:
>>> import laundry
>>> pc_dict = {'Name':'Yosemite', 'Maker':'Carrera','Speed':266}
>>> rec = laundry.Record()
>>> rec.loadFromDict(pc_dict)
>>> rec.Maker
'Carrera'
>>> rec.Speed
266
>>>
It's easy to extend DataSet to get a list of objects rather than dictionaries, and your data-manipulation code will be extremely readable. Furthermore, you can derive many of the INSERT and UPDATE statements you need automatically.
If you use this class and populate it with the results of a query, whenever someone adds a database field to the Customers table, your objects acquire the new data attribute automatically. If someone deletes a database field the program needs, your code will need fixing (Python is powerful, but not telepathic) but your model can be made reasonably robust against the deletion on information fields as well.*
| * Some Python GUI libraries, such as Tkinter, make it easy to build dialogs dynamically as well, so that the edit boxes displayed on a customer dialog could also depend on the available data. | ||||
The examples in this chapter used two tables, one of clients and one of invoices, with a master-detail relationship. In terms of objects, you'd say that a client has a list of related invoices. However, it might be expensive to fetch these every time when a user might want to see them only some of the time.
Let's implement a lazy fetch to get the data on demand. This Customer class inherits from our Record class. Given a database connection, it fetches its main attributes when explicitly asked, but the invoice list is retrieved on demand:
class Customer(Record):
def __getattr__(self, key):
#trap attempts to fetch the list of invoices
if key == 'Invoices':
self.fetchInvoices()
return self.Invoices
else:
#call the inherited method
return Record.__getattr__(self, key)
def fetch(self, conn, key):
self.conn = conn
cursor = self.conn.cursor()
cursor.execute("SELECT * FROM Clients \
WHERE ClientID = '%s'" % key)
dicts = DataSetFromCursor(cursor).asDicts()
assert len(dicts) == 1, 'Error fetching data!'
self.loadFromDict(dicts[0])
def fetchInvoices(self):
#presumes an attribute pointing to the database
cursor = self.conn.cursor()
cursor.execute("SELECT * FROM Invoices \
WHERE ClientID = '%s'" % self.ClientID)
ds = DataSetFromCursor(cursor)
self.Invoices = ds.asObjects()
Using this class is straightforward:
>>> c = laundry.Customer()
>>> c.fetch(conn, 'MEGAWAD') # assume an open connection
>>> c.CompanyName # see if we got data�
'MegaWad Investments'
>>> c.pp() # let's see all the fields
{'Address1': '1 St. Fredericks-Le-Grand',
'Address2': 'London EC1A 8AB',
'Address3': None,
'Address4': None,
'ClientID': 'MEGAWAD',
'CompanyName': 'MegaWad Investments',
'ContactName': 'Hachiro Kobayashi'}
>>> len(c.Invoices) # trigger another fetch
4
>>> c.Invoices[0].Hours # access a child object
42.0
>>>
The example so far only fetches data. The __setattr__() method lets you trap attempts to set attributes in an analogous way, which you can use to update field lists, type-check arguments, and keep track of whether an object has changed and so needs updates posted back to the database.
It's possible in Python to build an even more general data-driven object framework, where you declared some mapping of objects to database rows, along with the names of classes to use and the relationships between database tables, and let Python build an entire web of objects on demand.
The various integration technologies in Python make it easy to acquire data from any database. ODBC is our favorite because it turns the data into Python variables with the greatest speed and least lines of code; however, we have shown you how to get connected with a wide range of tools.
Once you fetch the data, manipulating it is easy in Python. Python objects can hold numbers, strings, and dates; and sets of data can be represented in native Python lists and tuples. This means the data is right there in front of you; there's no need to loop over the properties of Recordset objects or cursors.
In this chapter, we have shown how to build the beginnings of a powerful toolkit for transforming and manipulating data in Python. This makes it easy to switch between different representations of data, as rows, dictionaries of keys and values, or objects.
Python is particularly well suited to writing data-laundering scripts and to constructing dynamic object models on top of a database.
There is a Python Database Topic Guide at http://www.python.org/topics/database/ with many useful pointers.
mxODBC lives at http://starship.python.net/crew/lemburg/mxODBC.html.
Gadfly lives at http://www.chordate.com/gadfly.html.
For those interested in ODBC internals and capabilities, SolidTech include a full ODBC manual with their documentation at http://www.solidtech.com/devzone/manuals/.
Access Database Design and Programming by Steven Roman (O'Reilly) provides an excellent introduction to relational database concepts, SQL, and the formal operations on which it's built. It also provides a complete reference to Microsoft Access SQL (including the Data Definition Language) and to the DAO object hierarchy.
The Data Warehouse Toolkit by Ralph Kimball (John Wiley & Sons) is the definitive text on its subject and an excellent introduction to what goes on in real-world database projects.