3.2 Process Descriptor
To manage processes, the kernel must have a clear picture of what each process is doing. It must know, for instance, the process's priority, whether it is running on a CPU or blocked on an event, what address space has been assigned to it, which files it is allowed to address, and so on. This is the role of the process descriptor — a task_struct type structure whose fields contain all the information related to a single process. As the repository of so much information, the process descriptor is rather complex. In addition to a large number of fields containing process attributes, the process descriptor contains several pointers to other data structures that, in turn, contain pointers to other structures. Figure 3-1 describes the Linux process descriptor schematically.
Figure 3-1. The Linux process descriptor
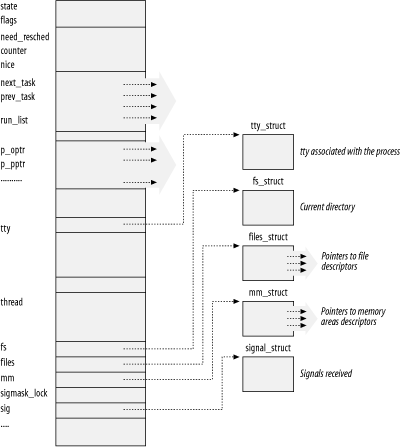
The five data structures on the right side of the figure refer to specific resources owned by the process. These resources are covered in future chapters. This chapter focuses on two types of fields that refer to the process state and to process parent/child relationships.
3.2.1 Process State
As its name implies, the state field of the process descriptor describes what is currently happening to the process. It consists of an array of flags, each of which describes a possible process state. In the current Linux version, these states are mutually exclusive, and hence exactly one flag of state is set; the remaining flags are cleared. The following are the possible process states:
TASK_RUNNING
The process is either executing on a CPU or waiting to be executed.
TASK_INTERRUPTIBLE
The process is suspended (sleeping) until some condition becomes true. Raising a hardware interrupt, releasing a system resource the process is waiting for, or delivering a signal are examples of conditions that might wake up the process (put its state back to TASK_RUNNING).
TASK_UNINTERRUPTIBLE
Like the previous state, except that delivering a signal to the sleeping process leaves its state unchanged. This process state is seldom used. It is valuable, however, under certain specific conditions in which a process must wait until a given event occurs without being interrupted. For instance, this state may be used when a process opens a device file and the corresponding device driver starts probing for a corresponding hardware device. The device driver must not be interrupted until the probing is complete, or the hardware device could be left in an unpredictable state.
TASK_STOPPED
Process execution has been stopped; the process enters this state after receiving a SIGSTOP, SIGTSTP, SIGTTIN, or SIGTTOU signal. When a process is being monitored by another (such as when a debugger executes a ptrace( ) system call to monitor a test program), each signal may put the process in the TASK_STOPPED state.
TASK_ZOMBIE
Process execution is terminated, but the parent process has not yet issued a wait( )-like system call — wait( ), wait3( ), wait4( ), or waitpid( ) — to return information about the dead process. Before the wait( )-like call is issued, the kernel cannot discard the data contained in the dead process descriptor because the parent might need it. (See Section 3.5.2 near the end of this chapter.)
The value of the state field is usually set with a simple assignment. For instance:
procdesc_ptr->state = TASK_RUNNING;
The kernel also uses the set_task_state and set_current_state macros: they set the state of a specified process and of the process currently executed, respectively. Moreover, these macros ensure that the assignment operation is not mixed with other instructions by the compiler or the CPU control unit. Mixing the instruction order may sometimes lead to catastrophic results (see Chapter 5).
3.2.2 Identifying a Process
As a general rule, each execution context that can be independently scheduled must have its own process descriptor; therefore, even lightweight processes, which share a large portion of their kernel data structures, have their own task_struct structures.
The strict one-to-one correspondence between the process and process descriptor makes the 32-bit process descriptor address[1] a useful means for the kernel to identify processes. These addresses are referred to as process descriptor pointers. Most of the references to processes that the kernel makes are through process descriptor pointers.
[1] Technically, these 32 bits are only the offset component of a logical address. However, since Linux uses a single kernel data segment, we can consider the offset to be equivalent to a whole logical address. Furthermore, since the base addresses of the code and data segments are set to 0, we can treat the offset as a linear address.
On the other hand, Unix-like operating systems allow users to identify processes by means of a number called the Process ID (or PID), which is stored in the pid field of the process descriptor. PIDs are numbered sequentially: the PID of a newly created process is normally the PID of the previously created process incremented by one. However, for compatibility with traditional Unix systems developed for 16-bit hardware platforms, the maximum PID number allowed on Linux is 32,767. When the kernel creates the 32,768th process in the system, it must start recycling the lower, unused PIDs.
Linux associates a different PID with each process or lightweight process in the system. (As we shall see later in this chapter, there is a tiny exception on multiprocessor systems.) This approach allows the maximum flexibility, since every execution context in the system can be uniquely identified.
On the other hand, Unix programmers expect threads in the same group to have a common PID. For instance, it should be possible to a send a signal specifying a PID that affects all threads in the group. In fact, the POSIX 1003.1c standard states that all threads of a multithreaded application must have the same PID.
To comply with this standard, Linux 2.4 introduces the notion of thread group. A thread group is essentially a collection of lightweight processes that correspond to the threads of a multithreaded application. All descriptors of the lightweight processes in the same thread group are collected in a doubly linked list implemented through the thread_group field of the task_struct structure. The identifier shared by the threads is the PID of the first lightweight process in the group; it is stored in the tgid field of the process descriptors. The getpid( ) system call returns current->tgid instead of current->pid, so all the threads of a multithreaded application share the same identifier. The tgid field has the same value as the pid field, both for normal processes and for lightweight processes not included in a thread group. Therefore, the getpid( ) system call works as usual for them.
Later, we'll show you how it is possible to derive a true process descriptor pointer efficiently from its respective PID. Efficiency is important because many system calls such as kill( ) use the PID to denote the affected process.
3.2.2.1 Processor descriptors handling
Processes are dynamic entities whose lifetimes range from a few milliseconds to months. Thus, the kernel must be able to handle many processes at the same time, and process descriptors are stored in dynamic memory rather than in the memory area permanently assigned to the kernel. Linux stores two different data structures for each process in a single 8 KB memory area: the process descriptor and the Kernel Mode process stack.
In Section 2.3, we learned that a process in Kernel Mode accesses a stack contained in the kernel data segment, which is different from the stack used by the process in User Mode. Since kernel control paths make little use of the stack, only a few thousand bytes of kernel stack are required. Therefore, 8 KB is ample space for the stack and the process descriptor.
Figure 3-2 shows how the two data structures are stored in the 2-page (8 KB) memory area. The process descriptor resides at the beginning of the memory area and the stack grows downward from the end.
Figure 3-2. Storing the process descriptor and the process kernel stack
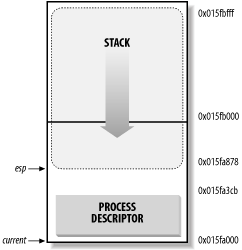
The esp register is the CPU stack pointer, which is used to address the stack's top location. On Intel systems, the stack starts at the end and grows toward the beginning of the memory area. Right after switching from User Mode to Kernel Mode, the kernel stack of a process is always empty, and therefore the esp register points to the byte immediately following the memory area.
The value of the esp is decremented as soon as data is written into the stack. Since the process descriptor is less than 1,000 bytes long, the kernel stack can expand up to 7,200 bytes.
The C language allows the process descriptor and the kernel stack of a process to be conveniently represented by means of the following union construct:
union task_union { struct task_struct task; unsigned long stack[2048]; };
The process descriptor shown in Figure 3-2 is stored starting at address 0x015fa000, and the stack is stored starting at address 0x015fc000. The value of the esp register points to the current top of the stack at 0x015fa878.
The kernel uses the alloc_task_struct and free_task_struct macros to allocate and release the 8 KB memory area storing a process descriptor and a kernel stack.
3.2.2.2 The current macro
The close association between the process descriptor and the Kernel Mode stack just described offers a key benefit in terms of efficiency: the kernel can easily obtain the process descriptor pointer of the process currently running on a CPU from the value of the esp register. In fact, since the memory area is 8 KB (213 bytes) long, all the kernel has to do is mask out the 13 least significant bits of esp to obtain the base address of the process descriptor. This is done by the current macro, which produces assembly language instructions like the following:
movl $0xffffe000, %ecx andl %esp, %ecx movl %ecx, p
After executing these three instructions, p contains the process descriptor pointer of the process running on the CPU that executes the instruction.[2]
[2] One drawback to the shared-storage approach is that, for efficiency reasons, the kernel stores the 8-KB memory area in two consecutive page frames with the first page frame aligned to a multiple of 213. This may turn out to be a problem when little dynamic memory is available.
The current macro often appears in kernel code as a prefix to fields of the process descriptor. For example, current->pid returns the process ID of the process currently running on the CPU.
Another advantage of storing the process descriptor with the stack emerges on multiprocessor systems: the correct current process for each hardware processor can be derived just by checking the stack, as shown previously. Linux 2.0 did not store the kernel stack and the process descriptor together. Instead, it was forced to introduce a global static variable called current to identify the process descriptor of the running process. On multiprocessor systems, it was necessary to define current as an array—one element for each available CPU.
3.2.2.3 The process list
To allow an efficient search through processes of a given type (for instance, all processes in a runnable state), the kernel creates several lists of processes. Each list consists of pointers to process descriptors. A list pointer (that is, the field that each process uses to point to the next process) is embedded right in the process descriptor's data structure. When you look at the C-language declaration of the task_struct structure, the descriptors may seem to turn in on themselves in a complicated recursive manner. However, the concept is no more complicated than any list, which is a data structure containing a pointer to the next instance of itself.
A circular doubly linked list (see Figure 3-3) links all existing process descriptors; we will call it the process list. The prev_task and next_task fields of each process descriptor are used to implement the list. The head of the list is the init_task descriptor referenced by the first element of the task array; it is the ancestor of all processes, and is called process 0 or swapper (see Section 3.4.2 later in this chapter). The prev_task field of init_task points to the process descriptor inserted last in the list.
Figure 3-3. The process list

The SET_LINKS and REMOVE_LINKS macros are used to insert and to remove a process descriptor in the process list, respectively. These macros also take care of the parenthood relationship of the process (see Section 3.2.3 later in this chapter).
Another useful macro, called for_each_task , scans the whole process list. It is defined as:
#define for_each_task(p) \ for (p = &init_task ; (p = p->next_task) != &init_task ; )
The macro is the loop control statement after which the kernel programmer supplies the loop. Notice how the init_task process descriptor just plays the role of list header. The macro starts by moving past init_task to the next task and continues until it reaches init_task again (thanks to the circularity of the list).
3.2.2.4 Doubly linked lists
The process list is a special doubly linked list. However, as you may have noticed, the Linux kernel uses hundreds of doubly linked lists that store the various kernel data structures.
For each list, a set of primitive operations must be implemented: initializing the list, inserting and deleting an element, scanning the list, and so on. It would be both a waste of programmers' efforts and a waste of memory to replicate the primitive operations for each different list.
Therefore, the Linux kernel defines the list_head data structure, whose fields next and prev represent the forward and back pointers of a generic doubly linked list element, respectively. It is important to note, however, that the pointers in a list_head field store the addresses of other list_head fields rather than the addresses of the whole data structures in which the list_head structure is included (see Figure 3-4).
Figure 3-4. A doubly linked list built with list_head data structures
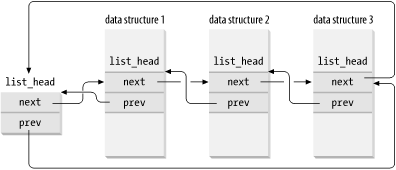
A new list is created by using the LIST_HEAD(list_name) macro. It declares a new variable named list_name of type list_head, which is the conventional first element of the new list (much as init_task is the conventional first element of the process list).
Several functions and macros implement the primitives, including those shown in the following list.
list_add(n,p)
Inserts an element pointed by n right after the specified element pointed by p (to insert n at the beginning of the list, set p to the address of the conventional first element)
list_add_tail(n,h)
Inserts an element pointed by n at the end of the list specified by the address h of its conventional first element
list_del(p)
Deletes an element pointed by p (there is no need to specify the conventional first element of the list)
list_empty(p)
Checks if the list specified by the address of its conventional first element is empty
list_entry(p,t,f)
Returns the address of the data structure of type t in which the list_head field that has the name f and the address p is included
list_for_each(p,h)
Scans the elements of the list specified by the address h of the conventional first element (similar to for_each_task for the process list)
3.2.2.5 The list of TASK_RUNNING processes
When looking for a new process to run on the CPU, the kernel has to consider only the runnable processes (that is, the processes in the TASK_RUNNING state). Since it is rather inefficient to scan the whole process list, a doubly linked circular list of TASK_RUNNING processes called runqueue has been introduced. This list is implemented through the run_list field of type list_head in the process descriptor. As in the previous case, the init_task process descriptor plays the role of list header. The nr_running variable stores the total number of runnable processes.
The add_to_runqueue( ) function inserts a process descriptor at the beginning of the list, while del_from_runqueue( ) removes a process descriptor from the list. For scheduling purposes, two functions, move_first_runqueue( ) and move_last_runqueue( ), are provided to move a process descriptor to the beginning or the end of the runqueue, respectively. The task_on_runqueue( ) function checks whether a given process is inserted into the runqueue.
Finally, the wake_up_process( ) function is used to make a process runnable. It sets the process state to TASK_RUNNING and invokes add_to_runqueue( ) to insert the process in the runqueue list. It also forces the invocation of the scheduler when the process has a dynamic priority larger than that of the current process or, in SMP systems, that of a process currently executing on some other CPU (see Chapter 11).
3.2.2.6 The pidhash table and chained lists
In several circumstances, the kernel must be able to derive the process descriptor pointer corresponding to a PID. This occurs, for instance, in servicing the kill( ) system call. When process P1 wishes to send a signal to another process, P2, it invokes the kill( ) system call specifying the PID of P2 as the parameter. The kernel derives the process descriptor pointer from the PID and then extracts the pointer to the data structure that records the pending signals from P2's process descriptor.
Scanning the process list sequentially and checking the pid fields of the process descriptors is feasible but rather inefficient. To speed up the search, a pidhash hash table consisting of PIDHASH_SZ elements has been introduced (PIDHASH_SZ is usually set to 1,024). The table entries contain process descriptor pointers. The PID is transformed into a table index using the pid_hashfn macro:
#define pid_hashfn(x) ((((x) >> 8) ^ (x)) & (PIDHASH_SZ - 1))
As every basic computer science course explains, a hash function does not always ensure a one-to-one correspondence between PIDs and table indexes. Two different PIDs that hash into the same table index are said to be colliding.
Linux uses chaining to handle colliding PIDs; each table entry is a doubly linked list of colliding process descriptors. These lists are implemented by means of the pidhash_next and pidhash_pprev fields in the process descriptor. Figure 3-5 illustrates a pidhash table with two lists. The processes having PIDs 199 and 26,799 hash into the 200th element of the table, while the process having PID 26,800 hashes into the 217th element of the table.
Figure 3-5. The pidhash table and chained lists
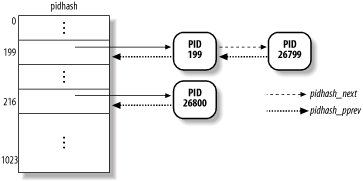
Hashing with chaining is preferable to a linear transformation from PIDs to table indexes because at any given instance, the number of processes in the system is usually far below 32,767 (the maximum allowed PID). It is a waste of storage to define a table consisting of 32,768 entries, if, at any given instance, most such entries are unused.
The hash_ pid( ) and unhash_ pid( ) functions are invoked to insert and remove a process in the pidhash table, respectively. The find_task_by_pid( ) function searches the hash table and returns the process descriptor pointer of the process with a given PID (or a null pointer if it does not find the process).
3.2.3 Parenthood Relationships Among Processes
Processes created by a program have a parent/child relationship. When a process creates multiple children, these children have sibling relationships. Several fields must be introduced in a process descriptor to represent these relationships. Processes 0 and 1 are created by the kernel; as we shall see later in the chapter, process 1 (init) is the ancestor of all other processes. The descriptor of a process P includes the following fields:
Points to the process descriptor of the process that created P or to the descriptor of process 1 (init) if the parent process no longer exists. Therefore, when a shell user starts a background process and exits the shell, the background process becomes the child of init.
p_pptr (parent)
Points to the current parent of P (this is the process that must be signaled when the child process terminates); its value usually coincides with that of p_opptr. It may occasionally differ, such as when another process issues a ptrace( ) system call requesting that it be allowed to monitor P (see Section 20.1.5).
p_cptr (child)
Points to the process descriptor of the youngest child of P — that is, of the process created most recently by it.
p_ysptr (younger sibling)
Points to the process descriptor of the process that has been created immediately after P by P's current parent.
p_osptr (older sibling)
Points to the process descriptor of the process that has been created immediately before P by P's current parent.
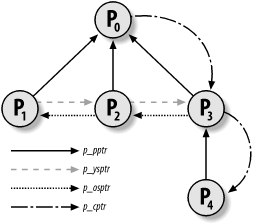
Figure 3-6 illustrates the parent and sibling relationships of a group of processes. Process P0 successively created P1, P2, and P3. Process P3, in turn, created process P4. Starting with p_cptr and using the p_osptr pointers to siblings, P0 is able to retrieve all its children.
Figure 3-6. Parenthood relationships among five processes
3.2.4 How Processes Are Organized
The runqueue list groups all processes in a TASK_RUNNING state. When it comes to grouping processes in other states, the various states call for different types of treatment, with Linux opting for one of the choices shown in the following list.
· Processes in a TASK_STOPPED or in a TASK_ZOMBIE state are not linked in specific lists. There is no need to group processes in either of these two states, since stopped and zombie processes are accessed only via PID or via linked lists of the child processes for a particular parent.
· Processes in a TASK_INTERRUPTIBLE or TASK_UNINTERRUPTIBLE state are subdivided into many classes, each of which corresponds to a specific event. In this case, the process state does not provide enough information to retrieve the process quickly, so it is necessary to introduce additional lists of processes. These are called wait queues.
3.2.4.1 Wait queues
Wait queues have several uses in the kernel, particularly for interrupt handling, process synchronization, and timing. Because these topics are discussed in later chapters, we'll just say here that a process must often wait for some event to occur, such as for a disk operation to terminate, a system resource to be released, or a fixed interval of time to elapse. Wait queues implement conditional waits on events: a process wishing to wait for a specific event places itself in the proper wait queue and relinquishes control. Therefore, a wait queue represents a set of sleeping processes, which are woekn up by the kernel when some condition becomes true.
Wait queues are implemented as doubly linked lists whose elements include pointers to process descriptors. Each wait queue is identified by a wait queue head, a data structure of type wait_queue_head_t:
struct _ _wait_queue_head { spinlock_t lock; struct list_head task_list;};typedef struct _ _wait_queue_head wait_queue_head_t;
Since wait queues are modified by interrupt handlers as well by major kernel functions, the doubly linked lists must be protected from concurrent accesses, which could induce unpredictable results (see Chapter 5). Synchronization is achieved by the lock spin lock in the wait queue head.
Elements of a wait queue list are of type wait_queue_t:
struct _ _wait_queue { unsigned int flags; struct task_struct * task; struct list_head task_list;};typedef struct _ _wait_queue wait_queue_t;
Each element in the wait queue list represents a sleeping process, which is waiting for some event to occur; its descriptor address is stored in the task field. However, it is not always convenient to wake up all sleeping processes in a wait queue.
For instance, if two or more processes are waiting for exclusive access to some resource to be released, it makes sense to wake up just one process in the wait queue. This process takes the resource, while the other processes continue to sleep. (This avoids a problem known as the "thundering herd," with which multiple processes are awoken only to race for a resource that can be accessed by one of them, and the result is that remaining processes must once more be put back to sleep.)
Thus, there are two kinds of sleeping processes: exclusive processes (denoted by the value 1 in the flags field of the corresponding wait queue element) are selectively woken up by the kernel, while nonexclusive processes (denoted by the value 0 in flags) are always woken up by the kernel when the event occurs. A process waiting for a resource that can be granted to just one process at a time is a typical exclusive process. Processes waiting for an event like the termination of a disk operation are nonexclusive.
3.2.4.2 Handling wait queues
The add_wait_queue( ) function inserts a nonexclusive process in the first position of a wait queue list. The add_wait_queue_exclusive( ) function inserts an exclusive process in the last position of a wait queue list. The remove_wait_queue( ) function removes a process from a wait queue list. The waitqueue_active( ) function checks whether a given wait queue list is empty.
A new wait queue may be defined by using the DECLARE_WAIT_QUEUE_HEAD(name) macro, which statically declares and initializes a new wait queue head variable called name. The init_waitqueue_head( ) function may be used to initialize a wait queue head variable that was allocated dynamically.
A process wishing to wait for a specific condition can invoke any of the functions shown in the following list.
· The sleep_on( ) function operates on the current process:
· void sleep_on(wait_queue_head_t *q)
· {· unsigned long flags;· wait_queue_t wait;· wait.flags = 0;· wait.task = current;· current->state = TASK_UNINTERRUPTIBLE;· add_wait_queue(q, &wait);
· schedule( );
· remove_wait_queue(q, &wait);
}
The function sets the state of the current process to TASK_UNINTERRUPTIBLE and inserts it into the specified wait queue. Then it invokes the scheduler, which resumes the execution of another process. When the sleeping process is woken, the scheduler resumes execution of the sleep_on( ) function, which removes the process from the wait queue.
· The interruptible_sleep_on( ) is identical to sleep_on( ), except that it sets the state of the current process to TASK_INTERRUPTIBLE instead of setting it to TASK_UNINTERRUPTIBLE so that the process can also be woken up by receiving a signal.
· The sleep_on_timeout( ) and interruptible_sleep_on_timeout( ) functions are similar to the previous ones, but they also allow the caller to define a time interval after which the process will be woken up by the kernel. To do this, they invoke the schedule_timeout( ) function instead of schedule( ) (see Section 6.6.2).
· The wait_event and wait_event_interruptible macros, introduced in Linux 2.4, put the calling process to sleep on a wait queue until a given condition is verified. For instance, the wait_event_interruptible(wq,condition) macro essentially yields the following fragment (we have omitted the code related to signal handling and return values on purpose):
· if (!(condition)) {
· wait_queue_t _ _wait; · init_waitqueue_entry(&_ _wait, current);
· add_wait_queue(&wq, &_ _wait);
· for (;;) {
· set_current_state(TASK_INTERRUPTIBLE);
· if (condition)
· break;· schedule();· }· current->state = TASK_RUNNING;· remove_wait_queue(&wq, &_ _wait);
}
These macros should be used instead of the older sleep_on( ) and interruptible_sleep_on( ), because the latter functions cannot test a condition and atomically put the process to sleep when the condition is not verified and are thus a well-known source of race conditions.
Notice that any process put to sleep by one of the above functions or macros is nonexclusive. Whenever the kernel wants to insert an exclusive process into a wait queue, it invokes add_wait_queue_exclusive( ) directly.
Processes inserted in a wait queue enter the TASK_RUNNING state by means of one of the following macros: wake_up, wake_up_nr, wake_up_all, wake_up_sync, wake_up_sync_nr, wake_up_interruptible, wake_up_interruptible_nr, wake_up_interruptible_all, wake_up_interruptible_sync, and wake_up_interruptible_sync_nr. We can understand what each of these ten macros does from its name:
· All macros take into consideration sleeping processes in TASK_INTERRUPTIBLE state; if the macro name does not include the string "interruptible," sleeping processes in TASK_UNINTERRUPTIBLE state are also considered.
· All macros wake all nonexclusive processes having the required state (see the previous bullet item).
· The macros whose name include the string "nr" wake a given number of exclusive processes having the required state; this number is a parameter of the macro. The macros whose name include the string "all" wake all exclusive processes having the required state. Finally, the macros whose names don't include "nr" or "all" wake exactly one exclusive process that has the required state.
· The macros whose names don't include the string "sync" check whether the priority of the woken processes is higher than that of the processes currently running in the systems and invoke schedule( ) if necessary. These checks are not made by the macros whose names include the string "sync."
For instance, the wake_up macro is equivalent to the following code fragment:
void wake_up(wait_queue_head_t *q){ struct list_head *tmp; wait_queue_t *curr; list_for_each(tmp, &q->task_list) { curr = list_entry(tmp, wait_queue_t, task_list); wake_up_process(curr->task); if (curr->flags) break; }}
The list_for_each macro scans all items in the doubly linked list of q. For each item, the list_entry macro computes the address of the correspondent wait_queue_t variable. The task field of this variable stores the pointer to the process descriptor, which is then passed to the wake_up_process( ) function. If the woken process is exclusive, the loop terminates. Since all nonexclusive processes are always at the beginning of the doubly linked list and all exclusive processes are at the end, the function always waken the nonexclusive processes and then wakes one exclusive process, if any exists.[3] Notice that awoken processes are not removed from the wait queue. A process could be awoken while the wait condition is still false; in this case, the process may suspend itself again in the same wait queue.
[3] By the way, it is rather uncommon that a wait queue includes both exclusive and nonexclusive processes.
3.2.5 Process Resource Limits
Each process has an associated set of resource limits, which specify the amount of system resources it can use. These limits keep a user from overwhelming the system (its CPU, disk space, and so on). Linux recognizes the following resource limits:
RLIMIT_AS
The maximum size of process address space, in bytes. The kernel checks this value when the process uses malloc( ) or a related function to enlarge its address space (see Section 8.1).
RLIMIT_CORE
The maximum core dump file size, in bytes. The kernel checks this value when a process is aborted, before creating a core file in the current directory of the process (see Section 10.1.1). If the limit is 0, the kernel won't create the file.
RLIMIT_CPU
The maximum CPU time for the process, in seconds. If the process exceeds the limit, the kernel sends it a SIGXCPU signal, and then, if the process doesn't terminate, a SIGKILL signal (see Chapter 10).
RLIMIT_DATA
The maximum heap size, in bytes. The kernel checks this value before expanding the heap of the process (see Section 8.6).
RLIMIT_FSIZE
The maximum file size allowed, in bytes. If the process tries to enlarge a file to a size greater than this value, the kernel sends it a SIGXFSZ signal.
RLIMIT_LOCKS
The maximum number of file locks. The kernel checks this value when the process enforces a lock on a file (see Section 12.7).
RLIMIT_MEMLOCK
The maximum size of nonswappable memory, in bytes. The kernel checks this value when the process tries to lock a page frame in memory using the mlock( ) or mlockall( ) system calls (see Section 8.3.4).
RLIMIT_NOFILE
The maximum number of open file descriptors. The kernel checks this value when opening a new file or duplicating a file descriptor (see Chapter 12).
RLIMIT_NPROC
The maximum number of processes that the user can own (see Section 3.4.1 later in this chapter).
RLIMIT_RSS
The maximum number of page frames owned by the process. The kernel checks this value when the process uses malloc( ) or a related function to enlarge its address space (see Section 8.1).
RLIMIT_STACK
The maximum stack size, in bytes. The kernel checks this value before expanding the User Mode stack of the process (see Section 8.4).
The resource limits are stored in the rlim field of the process descriptor. The field is an array of elements of type struct rlimit, one for each resource limit:
struct rlimit { unsigned long rlim_cur; unsigned long rlim_max; };
The rlim_cur field is the current resource limit for the resource. For example, current->rlim[RLIMIT_CPU].rlim_cur represents the current limit on the CPU time of the running process.
The rlim_max field is the maximum allowed value for the resource limit. By using the getrlimit( ) and setrlimit( ) system calls, a user can always increase the rlim_cur limit of some resource up to rlim_max. However, only the superuser (or, more precisely, a user who has the CAP_SYS_RESOURCE capability) can increase the rlim_max field or set the rlim_cur field to a value greater than the corresponding rlim_max field.
Most resource limits contain the value RLIM_INFINITY (0xffffffff), which means that no user limit is imposed on the corresponding resource (of course, real limits exist due to kernel design restrictions, available RAM, available space on disk, etc.). However, the system administrator may choose to impose stronger limits on some resources. Whenever a user logs into the system, the kernel creates a process owned by the superuser, which can invoke setrlimit( ) to decrease the rlim_max and rlim_cur fields for a resource. The same process later executes a login shell and becomes owned by the user. Each new process created by the user inherits the content of the rlim array from its parent, and therefore the user cannot override the limits enforced by the system.