5.3 Synchronization Primitives
Chapter 1 introduced the concepts of race condition and critical region for processes. The same definitions apply to kernel control paths. In this chapter, a race condition can occur when the outcome of a computation depends on how two or more interleaved kernel control paths are nested. A critical region is any section of code that must be completely executed by any kernel control path that enters it before another kernel control path can enter it.
We now examine how kernel control paths can be interleaved while avoiding race conditions among shared data. Table 5-1 lists the synchronization techniques used by the Linux kernel. The "Applies to" column indicates whether the synchronization technique applies to all CPUs in the system or to a single CPU. For instance, local interrupts disabling applies to just one CPU (other CPUs in the system are not affected); conversely, an atomic operation affects all CPUs in the system (atomic operations on several CPUs cannot interleave while accessing the same data structure).
Let's now briefly discuss each synchronization technique. In the later section Section 5.4, we show how these synchronization techniques can be combined to effectively protect kernel data structures.
5.3.1 Atomic Operations
Several assembly language instructions are of type "read-modify-write" — that is, they access a memory location twice, the first time to read the old value and the second time to write a new value.
Suppose that two kernel control paths running on two CPUs try to "read-modify-write" the same memory location at the same time by executing nonatomic operations. At first, both CPUs try to read the same location, but the memory arbiter (a hardware circuit that serializes accesses to the RAM chips) steps in to grant access to one of them and delay the other. However, when the first read operation has completed, the delayed CPU reads exactly the same (old) value from the memory location. Both CPUs then try to write the same (new) value on the memory location; again, the bus memory access is serialized by the memory arbiter, and eventually both write operations succeed. However, the global result is incorrect because both CPUs write the same (new) value. Thus, the two interleaving "read-modify-write" operations act as a single one.
The easiest way to prevent race conditions due to "read-modify-write" instructions is by ensuring that such operations are atomic at the chip level. Any such operation must be executed in a single instruction without being interrupted in the middle and avoiding accesses to the same memory location by other CPUs. These very small atomic operations can be found at the base of other, more flexible mechanisms to create critical sections.
Let's review 80 x 86 instructions according to that classification.
· Assembly language instructions that make zero or one aligned memory access are atomic.[2]
[2] A data item is aligned in memory when its address is a multiple of its size in bytes. For instance, the address of an aligned short integer must be a multiple of two, while the address of an aligned integer must be a multiple of four. Generally speaking, a unaligned memory access is not atomic.
· Read-modify-write assembly language instructions (such as inc or dec) that read data from memory, update it, and write the updated value back to memory are atomic if no other processor has taken the memory bus after the read and before the write. Memory bus stealing never happens in a uniprocessor system.
· Read-modify-write assembly language instructions whose opcode is prefixed by the lock byte (0xf0) are atomic even on a multiprocessor system. When the control unit detects the prefix, it "locks" the memory bus until the instruction is finished. Therefore, other processors cannot access the memory location while the locked instruction is being executed.
· Assembly language instructions (whose opcode is prefixed by a rep byte (0xf2, 0xf3), which forces the control unit to repeat the same instruction several times) are not atomic. The control unit checks for pending interrupts before executing a new iteration.
When you write C code, you cannot guarantee that the compiler will use a single, atomic instruction for an operation like a=a+1 or even for a++. Thus, the Linux kernel provides a special atomic_t type (a 24-bit atomically accessible counter) and some special functions (see Table 5-2) that act on atomic_t variables and are implemented as single, atomic assembly language instructions. On multiprocessor systems, each such instruction is prefixed by a lock byte.
Another class of atomic functions operate on bit masks (see Table 5-3). In this case, a bit mask is a generic integer variable.
5.3.2 Memory Barriers
When using optimizing compilers, you should never take for granted that instructions will be performed in the exact order in which they appear in the source code. For example, a compiler might reorder the assembly language instructions in such a way to optimize how registers are used. Moreover, modern CPUs usually execute several instructions in parallel, and might reorder memory accesses. These kinds of reordering can greatly speed up the program.
When dealing with synchronization, however, instructions reordering must be avoided. As a matter of fact, all synchronization primitives act as memory barriers. Things would quickly become hairy if an instruction placed after a synchronization primitive is executed before the synchronization primitive itself.
A memory barrier primitive ensures that the operations placed before the primitive are finished before starting the operations placed after the primitive. Thus, a memory barrier is like a firewall that cannot be passed by any assembly language instruction.
In the 80 x 86 processors, the following kinds of assembly language instructions are said to be "serializing" because they act as memory barriers:
· All instructions that operate on I/O ports
· All instructions prefixed by the lock byte (see Section 5.3.1)
· All instructions that write into control registers, system registers, or debug registers (for instance, cli and sti, which change the status of the IF flag in the eflags register)
· A few special assembly language instructions; among them, the iret instruction that terminates an interrupt or exception handler
Linux uses six memory barrier primitives, which are shown in Table 5-4. "Read memory barriers" act only on instructions that read from memory, while "write memory barriers" act only on instructions that write to memory. Memory barriers can be useful both in multiprocessor systems and in uniprocessor systems. The smp_xxx( ) primitives are used whenever the memory barrier should prevent race conditions that might occur only in multiprocessor systems; in uniprocessor systems, they do nothing. The other memory barriers are used to prevent race conditions occurring both in uniprocessor and multiprocessor systems.
The implementations of the memory barrier primitives depend on the architecture of the system. For instance, on the Intel platform, the rmb( ) macro expands into asm volatile("lock;addl $0,0(%%esp)":::"memory"). The asm instruction tells the compiler to insert some assembly language instructions. The volatile keyword forbids the compiler to reshuffle the asm instruction with the other instructions of the program. The memory keyword forces the compiler to assume that all memory locations in RAM have been changed by the assembly language instruction; therefore, the compiler cannot optimize the code by using the values of memory locations stored in CPU registers before the asm instruction. Finally, the lock;addl $0,0(%%esp) assembly language instruction adds zero to the memory location on top of the stack; the instruction is useless by itself, but the lock prefix makes the instruction a memory barrier for the CPU. The wmb( ) macro on Intel is actually simpler because it expands into asm volatile("":::"memory"). This is because Intel processors never reorder write memory accesses, so there is no need to insert a serializing assembly language instruction in the code. The macro, however, forbids the compiler to reshuffle the instructions.
Notice that in multiprocessor systems, all atomic operations described in the earlier section Section 5.3.1 act as memory barriers because they use the lock byte.
5.3.3 Spin Locks
A widely used synchronization technique is locking. When a kernel control path must access a shared data structure or enter a critical region, it needs to acquire a "lock" for it. A resource protected by a locking mechanism is quite similar to a resource confined in a room whose door is locked when someone is inside. If a kernel control path wishes to access the resource, it tries to "open the door" by acquiring the lock. It succeeds only if the resource is free. Then, as long as it wants to use the resource, the door remains locked. When the kernel control path releases the lock, the door is unlocked and another kernel control path may enter the room.
Figure 5-1 illustrates the use of locks. Five kernel control paths (P0, P1, P2, P3, and P4) are trying to access two critical regions (C1 and C2). Kernel control path P0 is inside C1, while P2 and P4 are waiting to enter it. At the same time, P1 is inside C2, while P3 is waiting to enter it. Notice that P0 and P1 could run concurrently. The lock for critical region C3 is open since no kernel control path needs to enter it.
Figure 5-1. Protecting critical regions with several locks
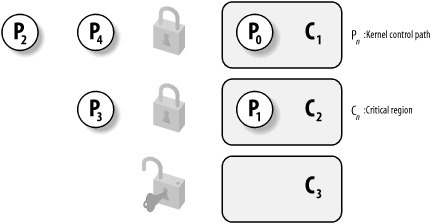
Spin locks are a special kind of lock designed to work in a multiprocessor environment. If the kernel control path finds the spin lock "open," it acquires the lock and continues its execution. Conversely, if the kernel control path finds the lock "closed" by a kernel control path running on another CPU, it "spins" around, repeatedly executing a tight instruction loop, until the lock is released.
Of course, spin locks are useless in a uniprocessor environment, since the waiting kernel control path would keep running, so the kernel control path that is holding the lock would not have any chance to release it.
The instruction loop of spin locks represents a "busy wait." The waiting kernel control path keeps running on the CPU, even if it has nothing to do besides waste time. Nevertheless, spin locks are usually very convenient, since many kernel resources are locked for a fraction of a millisecond only; therefore, it would be far more time-consuming to release the CPU and reacquire it later.
In Linux, each spin lock is represented by a spinlock_t structure consisting of a single lock field; the value 1 corresponds to the unlocked state, while any negative value and zero denote the locked state.
Five functions shown in Table 5-5 are used to initialize, test, and set spin locks. On uniprocessor systems, none of these functions do anything, except for spin_trylock( ), which always returns 1. All these functions are based on atomic operations; this ensures that the spin lock will be properly updated by a process running on a CPU even if other processes running on different CPUs attempt to modify the spin lock at the same time.[3]
[3] Spin locks, ironically enough, are global and therefore must themselves be protected against concurrent accesses.
Let's discuss in detail the spin_lock macro, which is used to acquire a spin lock. It takes the address slp of the spin lock as its parameter and yields essentially the following assembly language code:[4]
[4] The actual implementation of spin_lock is slightly more complicated. The code at label 2, which is executed only if the spin lock is busy, is included in an auxiliary section so that in the most frequent case (free spin lock) the hardware cache is not filled with code that won't be executed. In our discussion, we omit these optimization details.
1: lock; decb slp
jns 3f
2: cmpb $0,slp
pause
jle 2b
jmp 1b
3:
The decb assembly language instruction decrements the spin lock value; the instruction is atomic because it is prefixed by the lock byte. A test is then performed on the sign flag. If it is clear, it means that the spin lock was set to 1 (unlocked), so normal execution continues at label 3 (the f suffix denotes the fact that the label is a "forward" one; it appears in a later line of the program). Otherwise, the tight loop at label 2 (the b suffix denotes a "backward" label) is executed until the spin lock assumes a positive value. Then execution restarts from label 1, since it is unsafe to proceed without checking whether another processor has grabbed the lock. The pause assembly language instruction, which was introduced in the Pentium 4 model, is designed to optimize the execution of spin lock loops. By introducing a small delay, it speeds up the execution of code following the lock and reduces power consumption. The pause instruction is backward compatible with earlier models of Intel processors because it corresponds to the instructions rep;nop, which essentially do nothing.
The spin_unlock macro releases a previously acquired spin lock; it essentially yields the following code:
lock; movb $1, slp
Again, the lock byte ensures that the loading instruction is atomic.
5.3.4 Read/Write Spin Locks
Read/write spin locks have been introduced to increase the amount of concurrency inside the kernel. They allow several kernel control paths to simultaneously read the same data structure, as long as no kernel control path modifies it. If a kernel control path wishes to write to the structure, it must acquire the write version of the read/write lock, which grants exclusive access to the resource. Of course, allowing concurrent reads on data structures improves system performance.
Figure 5-2 illustrates two critical regions (C1 and C2) protected by read/write locks. Kernel control paths R0 and R1 are reading the data structures in C1 at the same time, while W0 is waiting to acquire the lock for writing. Kernel control path W1 is writing the data structures in C2, while both R2 and W2 are waiting to acquire the lock for reading and writing, respectively.
Figure 5-2. Read/write spin locks
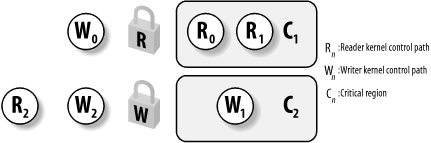
Each read/write spin lock is a rwlock_t structure; its lock field is a 32-bit field that encodes two distinct pieces of information:
· A 24-bit counter denoting the number of kernel control paths currently reading the protected data structure. The two's complement value of this counter is stored in bits 0-23 of the field.
· An unlock flag that is set when no kernel control path is reading or writing, and clear otherwise. This unlock flag is stored in bit 24 of the field.
Notice that the lock field stores the number 0x01000000 if the spin lock is idle (unlock flag set and no readers), the number 0x00000000 if it has been acquired for writing (unlock flag clear and no readers), and any number in the sequence 0x00ffffff, 0x00fffffe, and so on, if it has been acquired for reading by one, two, and more processes (unlock flag clear and the two's complement on 24 bits of the number of readers).
The rwlock_init macro initializes the lock field of a read/write spin lock to 0x01000000 (unlocked).
5.3.4.1 Getting and releasing a lock for reading
The read_lock macro, applied to the address rwlp of a read/write spin lock, essentially yields the following code:
movl $rwlp,%eax
lock; subl $1,(%eax)
jns 1f
call _ _read_lock_failed
1:
where _ _read_lock_failed( ) is the following assembly language function:
_ _read_lock_failed:
lock; incl (%eax)
1: cmpl $1,(%eax)
js 1b
lock; decl (%eax)
js _ _read_lock_failed
ret
The read_lock macro atomically decreases the spin lock value by 1, thus incrementing the number of readers. The spin lock is acquired if the decrement operation yields a nonnegative value; otherwise, the _ _read_lock_failed( ) function is invoked. The function atomically increments the lock field to undo the decrement operation performed by the read_lock macro, and then loops until the field becomes positive (greater than or equal to 1). Next, _ _read_lock_failed( ) tries to get the spin lock again (another kernel control path could acquire the spin lock for writing right after the cmpl instruction).
Releasing the read lock is quite simple because the read_unlock macro must simply increment the counter in the lock field to decrease the number of readers; thus, the macro yields the following assembly language instruction:
lock; incl rwlp
5.3.4.2 Getting and releasing a lock for writing
The write_lock function applied to the address rwlp of a read/write spin lock yields the following instructions:
movl $rwlp,%eax
lock; subl $0x01000000,(%eax)
jz 1f
call _ _write_lock_failed
1:
where _ _write_lock_failed( ) is the following assembly language function:
_ _write_lock_failed:
lock; addl $0x01000000,(%eax)
1: cmpl $0x01000000,(%eax)
jne 1b
lock; subl $0x01000000,(%eax)
jnz _ _write_lock_failed
ret
The write_lock macro atomically subtracts 0x01000000 from the spin lock value, thus clearing the unlock flag. The spin lock is acquired if the subtraction operation yields zero (no readers); otherwise, the _ _write_lock_failed( ) function is invoked. This function atomically adds 0x01000000 to the lock field to undo the subtraction operation performed by the write_lock macro, and then loops until the spin lock becomes idle (lock field equal to 0x01000000). Next, _ _write_lock_failed( ) tries to get the spin lock again (another kernel control path could acquire the spin lock right after the cmpl instruction).
Once again, releasing the write lock is much simpler because the write_unlock macro must simply set the unlock flag in the lock field. Thus, the macro yields the following assembly language instruction:
lock; addl $0x01000000,rwlp
5.3.5 The Big Reader Lock
Read/write spin locks are useful for data structures that are accessed by many readers and a few writers. They are more convenient than normal spin locks because they allow several readers to concurrently access the protected data structure. However, any time a CPU acquires a read/write spin lock, the counter in rwlock_t must be updated. A further access to the rwlock_t data structure performed by another CPU incurs in a significant performance penalty because the hardware caches of the two processors must be synchronized. Even worse, the new CPU changes the rwlock_t data structure, so the cache of the former CPU becomes invalid and there is another performance penalty when the former CPU releases the lock. In short, reader CPUs are playing ping-pong with the cache line containing the read/write spin lock data structure.
A special type of read/write spin locks, named big reader read/write spin locks, was designed to address this problem. The idea is to split the "reader" portion of the lock across all CPUs, so that each per-CPU data structure lies in its own line of the hardware caches. Readers do not need to stomp one another, so no reader CPU "snoops" the reader lock of another CPU. Conversely, the "writer" portion of the lock is common to all CPUs because only one CPU can acquire the lock for writing.
The _ _brlock_array array stores the "reader" portions of the big reader read/write spin locks; for every such lock, and for every CPU in the system, the array includes a lock flag, which is set to 1 when the lock is closed for reading by the corresponding CPU. Conversely, the _ _br_write_locks array stores the "writer" portions of the big reader spin locks — that is, a normal spin lock that is set when the big reader spin lock has been acquired for writing.
The br_read_lock( ) function acquires the spin lock for reading. It just sets the lock flag in _ _brlock_array corresponding to the executing CPU and the big reader spin lock to 1, and then waits until the spin lock in _ _br_write_locks is open. Conversely, the br_read_unlock( ) function simply clears the lock flag in _brlock_array.
The br_write_lock( ) function acquires the spin lock for writing. It invokes spin_lock to get the spin lock in _ _br_write_locks corresponding to the big reader spin lock, and then checks that all lock flags in _ _brlock_array corresponding to the big reader lock are cleared; if not, it releases the spin lock in _ _br_write_locks and starts again. The br_write_unlock( ) function simply invokes spin_unlock to release the spin lock in _ _br_write_locks.
As you may notice, acquiring an open big reader spin lock for reading is really fast, but acquiring it for writing is very slow because the CPU must acquire a spin lock and check several lock flags. Thus, big reader spin locks are rarely used. On the Intel architecture, there is just one big reader spin lock, used in the networking code.
5.3.6 Semaphores
We have already introduced semaphores in Section 1.6.5. Essentially, they implement a locking primitive that allows waiters to sleep until the desired resource becomes free.
Actually, Linux offers two kinds of semaphores:
· Kernel semaphores, which are used by kernel control paths
· System V IPC semaphores, which are used by User Mode processes
In this section, we focus on kernel semaphores, while IPC semaphores are described in Chapter 19.
A kernel semaphore is similar to a spin lock, in that it doesn't allow a kernel control path to proceed unless the lock is open. However, whenever a kernel control path tries to acquire a busy resource protected by a kernel semaphore, the corresponding process is suspended. It becomes runnable again when the resource is released. Therefore, kernel semaphores can be acquired only by functions that are allowed to sleep; interrupt handlers and deferrable functions cannot use them.
A kernel semaphore is an object of type struct semaphore, containing the fields shown in the following list.
count
Stores an atomic_t value. If it is greater than 0, the resource is free — that is, it is currently available. If count is equal to 0, the semaphore is busy but no other process is waiting for the protected resource. Finally, if count is negative, the resource is unavailable and at least one process is waiting for it.
wait
Stores the address of a wait queue list that includes all sleeping processes that are currently waiting for the resource. Of course, if count is greater than or equal to 0, the wait queue is empty.
sleepers
Stores a flag that indicates whether some processes are sleeping on the semaphore. We'll see this field in operation soon.
The init_MUTEX and init_MUTEX_LOCKED macros may be used to initialize a semaphore for exclusive access: they set the count field to 1 (free resource with exclusive access) and 0 (busy resource with exclusive access currently granted to the process that initializes the semaphore). Note that a semaphore could also be initialized with an arbitrary positive value n for count. In this case, at most n processes are allowed to concurrently access the resource.
5.3.6.1 Getting and releasing semaphores
Let's start by discussing how to release a semaphore, which is much simpler than getting one. When a process wishes to release a kernel semaphore lock, it invokes the up( ) assembly language function. This function is essentially equivalent to the following code:
movl $sem,%ecx
lock; incl (%ecx)
jg 1f
pushl %eax
pushl %edx
pushl %ecx
call _ _up
popl %ecx
popl %edx
popl %eax
1:
where _ _up( ) is the following C function:
void _ _up(struct semaphore *sem)
{wake_up(&sem->wait);
}
The up( ) function increments the count field of the *sem semaphore (at offset 0 of the semaphore structure), and then it checks whether its value is greater than 0. The increment of count and the setting of the flag tested by the following jump instruction must be atomically executed; otherwise, another kernel control path could concurrently access the field value, with disastrous results. If count is greater than 0, there was no process sleeping in the wait queue, so nothing has to be done. Otherwise, the _ _up( ) function is invoked so that one sleeping process is woken up.
Conversely, when a process wishes to acquire a kernel semaphore lock, it invokes the down( ) function. The implementation of down( ) is quite involved, but it is essentially equivalent to the following:
down:
movl $sem,%ecx
lock; decl (%ecx);
jns 1f
pushl %eax
pushl %edx
pushl %ecx
call _ _down
popl %ecx
popl %edx
popl %eax
1:
where _ _down( ) is the following C function:
void _ _down(struct semaphore * sem)
{ DECLARE_WAITQUEUE(wait, current);
current->state = TASK_UNINTERRUPTIBLE;
add_wait_queue_exclusive(&sem->wait, &wait);
spin_lock_irq(&semaphore_lock);
sem->sleepers++;
for (;;) { if (!atomic_add_negative(sem->sleepers-1, &sem->count)) {sem->sleepers = 0;
break;
}
sem->sleepers = 1;
spin_unlock_irq(&semaphore_lock);
schedule( );
current->state = TASK_UNINTERRUPTIBLE;
spin_lock_irq(&semaphore_lock);
}
spin_unlock_irq(&semaphore_lock);
remove_wait_queue(&sem->wait, &wait);
current->state = TASK_RUNNING;
wake_up(&sem->wait);
}
The down( ) function decrements the count field of the *sem semaphore (at offset 0 of the semaphore structure), and then checks whether its value is negative. Again, the decrement and the test must be atomically executed. If count is greater than or equal to 0, the current process acquires the resource and the execution continues normally. Otherwise, count is negative and the current process must be suspended. The contents of some registers are saved on the stack, and then _ _down( ) is invoked.
Essentially, the _ _down( ) function changes the state of the current process from TASK_RUNNING to TASK_UNINTERRUPTIBLE, and puts the process in the semaphore wait queue. Before accessing other fields of the semaphore structure, the function also gets the semaphore_lock spin lock and disables local interrupts. This ensures that no process running on another CPU is able to read or modify the fields of the semaphore while the current process is updating them.
The main task of the _ _down( ) function is to suspend the current process until the semaphore is released. However, the way in which this is done is quite involved. To easily understand the code, keep in mind that the sleepers field of the semaphore is usually set to 0 if no process is sleeping in the wait queue of the semaphore, and it is set to 1 otherwise. Let's try to explain the code by considering a few typical cases.
MUTEX semaphore open (count equal to 1, sleepers equal to 0)
The down macro just sets the count field to 0 and jumps to the next instruction of the main program; therefore, the _ _down( ) function is not executed at all.
MUTEX semaphore closed, no sleeping processes (count equal to 0, sleepers equal to 0)
The down macro decrements count and invokes the _ _down( ) function with the count field set to -1 and the sleepers field set to 0. In each iteration of the loop, the function checks whether the count field is negative. (Observe that the count field is not changed by atomic_add_negative( ) because sleepers is equal to 0 when the function is invoked.)
· If the count field is negative, the function invokes schedule( ) to suspend the current process. The count field is still set to -1, and the sleepers field to 1. The process picks up its run subsequently inside this loop and issues the test again.
· If the count field is not negative, the function sets sleepers to 0 and exits from the loop. It tries to wake up another process in the semaphore wait queue (but in our scenario, the queue is now empty), and terminates holding the semaphore. On exit, both the count field and the sleepers field are set to 0, as required when the semaphore is closed but no process is waiting for it.
MUTEX semaphore closed, other sleeping processes (count equal to -1, sleepers equal to 1)
The down macro decrements count and invokes the _ _down( ) function with count set to -2 and sleepers set to 1. The function temporarily sets sleepers to 2, and then undoes the decrement performed by the down macro by adding the value sleepers-1 to count. At the same time, the function checks whether count is still negative (the semaphore could have been released by the holding process right before _ _down( ) entered the critical region).
· If the count field is negative, the function resets sleepers to 1 and invokes schedule( ) to suspend the current process. The count field is still set to -1, and the sleepers field to 1.
· If the count field is not negative, the function sets sleepers to 0, tries to wake up another process in the semaphore wait queue, and exits holding the semaphore. On exit, the count field is set to 0 and the sleepers field to 0. The values of both fields look wrong, because there are other sleeping processes. However, consider that another process in the wait queue has been woken up. This process does another iteration of the loop; the atomic_add_negative( ) function subtracts 1 from count, restoring it to -1; moreover, before returning to sleep, the woken-up process resets sleepers to 1.
As you may easily verify, the code properly works in all cases. Consider that the wake_up( ) function in _ _down( ) wakes up at most one process because the sleeping processes in the wait queue are exclusive (see Section 3.2.4).
Only exception handlers, and particularly system call service routines, can use the down( ) function. Interrupt handlers or deferrable functions must not invoke down( ), since this function suspends the process when the semaphore is busy.[5] For this reason, Linux provides the down_trylock( ) function, which may be safely used by one of the previously mentioned asynchronous functions. It is identical to down( ) except when the resource is busy. In this case, the function returns immediately instead of putting the process to sleep.
[5] Exception handlers can block on a semaphore. Linux takes special care to avoid the particular kind of race condition in which two nested kernel control paths compete for the same semaphore; if that happens, one of them waits forever because the other cannot run and free the semaphore.
A slightly different function called down_interruptible( ) is also defined. It is widely used by device drivers since it allows processes that receive a signal while being blocked on a semaphore to give up the "down" operation. If the sleeping process is woken up by a signal before getting the needed resource, the function increments the count field of the semaphore and returns the value -EINTR. On the other hand, if down_interruptible( ) runs to normal completion and gets the resource, it returns 0. The device driver may thus abort the I/O operation when the return value is -EINTR.
Finally, since processes usually find semaphores in an open state, the semaphore functions are optimized for this case. In particular, the up( ) function does not enter in a critical region if the semaphore wait queue is empty; similarly, the down( ) function does not enter in a critical region if the semaphore is open. Much of the complexity of the semaphore implementation is precisely due to the effort of avoiding costly instructions in the main branch of the execution flow.
5.3.7 Read/Write Semaphores
Read/write semaphores are a new feature of Linux 2.4. They are similar to the read/write spin locks described earlier in Section 5.3.4, except that waiting processes are suspended until the semaphore becomes open again.
Many kernel control paths may concurrently acquire a read/write semaphore for reading; however, any writer kernel control path must have exclusive access to the protected resource. Therefore, the semaphore can be acquired for writing only if no other kernel control path is holding it for either read or write access. Read/write semaphores improve the amount of concurrency inside the kernel and improve overall system performance.
The kernel handles all processes waiting for a read/write semaphore in strict FIFO order. Each reader or writer that finds the semaphore closed is inserted in the last position of a semaphore's wait queue list. When the semaphore is released, the processes in the first positions of the wait queue list is checked. The first process is always awoken. If it is a writer, the other processes in the wait queue continue to sleep. If it is a reader, any other reader following the first process is also woken up and gets the lock. However, readers that have been queued after a writer continue to sleep.
Each read/write semaphore is described by a rw_semaphore structure that includes the following fields:
count
Stores two 16-bit counters. The counter in the most significant word encodes in two's complement form the sum of the number of nonwaiting writers (either 0 or 1) and the number of waiting kernel control paths. The counter in the less significant word encodes the total number of nonwaiting readers and writers.
wait_list
Points to a list of waiting processes. Each element in this list is a rwsem_waiter structure, including a pointer to the descriptor of the sleeping process and a flag indicating whether the process wants the semaphore for reading or for writing.
wait_lock
A spin lock used to protect the wait queue list and the rw_semaphore structure itself.
The init_rwsem( ) function initializes a rw_semaphore structure by setting the count field to 0, the wait_lock spin lock to unlocked, and wait_list to the empty list.
The down_read( ) and down_write( ) functions acquire the read/write semaphore for reading and writing, respectively. Similarly, the up_read( ) and up_write( ) functions release a read/write semaphore previously acquired for reading and for writing. The implementation of these four functions is long, but easy to follow because it resembles the implementation of normal semaphores; therefore, we avoid describing them.
5.3.8 Completions
Linux 2.4 also makes use of another synchronization primitive similar to semaphores: the completions. They have been introduced to solve a subtle race condition that occurs in multiprocessor systems when process A allocates a temporary semaphore variable, initializes it as closed MUTEX, passes its address to process B, and then invokes down( ) on it. Later on, process B running on a different CPU invokes up( ) on the same semaphore. However, the current implementation of up( ) and down( ) also allows them to execute concurrently on the same semaphore. Thus, process A can be woken up and destroy the temporary semaphore while process B is still executing the up( ) function. As a result, up( ) might attempt to access a data structure that no longer exists.
Of course, it is possible to change the implementation of down( ) and up( ) to forbid concurrent executions on the same semaphore. However, this change would require additional instructions, which is a bad thing to do for functions that are so heavily used.
The completion is a synchronization primitive that is specifically designed to solve this problem. The completion data structure includes a wait queue head and a flag:
struct completion {unsigned int done;
wait_queue_head_t wait;
};
The function corresponding to up( ) is called complete( ). It receives as an argument the address of a completion data structure, sets the done field to 1, and invokes wake_up( ) to wake up the exclusive process sleeping in the wait wait queue.
The function corresponding to down( ) is called wait_for_completion( ). It receives as an argument the address of a completion data structure and checks the value of the done flag. If it is set to 1, wait_for_completion( ) terminates because complete( ) has already been executed on another CPU. Otherwise, the function adds current to the tail of the wait queue as an exclusive process and puts current to sleep in the TASK_UNINTERRUPTIBLE state. Once woken up, the function removes current from the wait queue, sets done to 0, and terminates.
The real difference between completions and semaphores is how the spin lock included in the wait queue is used. Both complete( ) and wait_for_completion( ) use this spin lock to ensure that they cannot execute concurrently, while up( ) and down( ) use it only to serialize accesses to the wait queue list.
5.3.9 Local Interrupt Disabling
Interrupt disabling is one of the key mechanisms used to ensure that a sequence of kernel statements is treated as a critical section. It allows a kernel control path to continue executing even when hardware devices issue IRQ signals, thus providing an effective way to protect data structures that are also accessed by interrupt handlers. By itself, however, local interrupt disabling does not protect against concurrent accesses to data structures by interrupt handlers running on other CPUs, so in multiprocessor systems, local interrupt disabling is often coupled with spin locks (see the later section Section 5.4).
Interrupts can be disabled on a CPU with the cli assembly language instruction, which is yielded by the _ _cli( ) macro. Interrupts can be enabled on a CPU by means of the sti assembly language instruction, which is yielded by the _ _sti( ) macro. Recent kernel versions also define the local_irq_disable( ) and local_irq_enable( ) macros, which are equivalent respectively to _ _cli( ) and _ _sti( ), but whose names are not architecture dependent and are also much easier to understand.
When the kernel enters a critical section, it clears the IF flag of the eflags register to disable interrupts. But at the end of the critical section, often the kernel can't simply set the flag again. Interrupts can execute in nested fashion, so the kernel does not necessarily know what the IF flag was before the current control path executed. In these cases, the control path must save the old setting of the flag and restore that setting at the end.
Saving and restoring the eflags content is achieved by means of the _ _save_flags and _ _restore_flags macros, respectively. Typically, these macros are used in the following way:
_ _save_flags(old);
_ _cli( );
[...]
_ _restore_flags(old);
The _ _save_flags macro copies the content of the eflags register into the old local variable; the IF flag is then cleared by _ _cli( ). At the end of the critical region, the macro _ _restore_flags restores the original content of eflags; therefore, interrupts are enabled only if they were enabled before this control path issued the _ _cli( ) macro. Recent kernel versions also define the local_irq_save( ) and local_irq_restore( ) macros, which are essentially equivalent to _ _save_flags( ) and _ _restore_flags( ), but whose names are easier to understand.
5.3.10 Global Interrupt Disabling
Some critical kernel functions can execute on a CPU only if no interrupt handler or deferrable function is running on any other CPU. This synchronization requirement is satisfied by global interrupt disabling. A typical scenario consists of a driver that needs to reset the hardware device. Before fiddling with I/O ports, the driver performs global interrupt disabling, ensuring that no other driver will access the same ports.
As we shall see in this section, global interrupt disabling significantly lowers the system concurrency level; it is deprecated because it can be replaced by more efficient synchronization techniques.
Global interrupt disabling is performed by the cli( ) macro. On uniprocessor system, the macro just expands into _ _cli( ), disabling local interrupts. On multiprocessor systems, the macro waits until all interrupt handlers and all deferrable functions in the other CPUs terminate, and then acquires the global_irq_lock spin lock. The key activities required for multiprocessor systems occur inside the _ _global_cli( ) function, which is called by cli( ):
_ _save_flags(flags);
if (!(flags & 0x00000200)) /* testing IF flag */ {_ _cli( );
if (!local_irq_count[smp_processor_id( )])
get_irqlock(smp_processor_id( ));
}
First of all, _ _global_cli( ) checks the value of the IF flag of the eflags register because it refuses to "promote" the disabling of a local interrupt to a global one. Deadlock conditions can easily occur if this constraint is removed and global interrupts are disabled inside a critical region protected by a spin lock. For instance, consider a spin lock that is also accessed by interrupt handlers. Before acquiring the spin lock, the kernel must disable local interrupts, otherwise an interrupt handler could freeze waiting until the interrupted program released the spin lock. Now, suppose that a kernel control path disables local interrupts, acquires the spin lock, and then invokes cli( ). The latter macro waits until all interrupt handlers on the other CPUs terminate; however, an interrupt handler could be stuck waiting for the spin lock to be released. To avoid this kind of deadlock, _ _global_cli( ) refuses to run if local interrupts are already disabled before its invocation.
If cli( ) is invoked with local interrupts enabled, _ _global_cli( ) disables them. If cli( ) is invoked inside an interrupt service routine (i.e., local_irq_count macro returns a value different than 0), _ _global_cli( ) returns without performing any further action.[6] Otherwise, _ _global_irq( ) invokes the get_irqlock( ) function, which acquires the global_irq_lock spin lock and waits for the termination of all interrupt handlers running on the other CPUs. Moreover, if cli( ) is not invoked by a deferrable function, get_irqlock( ) waits for the termination of all bottom halves running on the other CPUs.
[6] This case should never occur because protection against concurrent execution of interrupt handlers should be based on spin locks rather than on global interrupt disabling. In short, an interrupt service routine should never execute the cli( ) macro.
global_irq_lock differs from normal spin locks because invoking get_irqlock( ) does not freeze the CPU if it already owns the lock. In fact, the global_irq _holder variable contains the logical identifier of the CPU that is holding the lock; this value is checked by get_irqlock( ) before starting the tight loop of the spin lock.
Once cli( ) returns, no other interrupt handler on other CPUs starts running until interrupts are re-enabled by invoking the sti( ) macro. On multiprocessor systems, sti( ) invokes the _ _global_sti( ) function:
cpu = smp_processor_id( );
if (!local_irq_count[cpu])
release_irqlock(cpu);
_ _sti( );
The release_irqlock( ) function releases the global_irq_lock spin lock. Notice that similar to cli( ), the sti( ) macro invoked inside an interrupt service routine is equivalent to _ _sti( ) because it doesn't release the spin lock.
Linux also provides global versions of the _ _save_flags and _ _restore_flags macros, which are also called save_flags and restore_flags. They save and reload, respectively, information controlling the interrupt handling for the executing CPU. As illustrated in Figure 5-3, save_flags yields an integer value that depends on three conditions; restore_flags performs actions based on the value yielded by save_flags.
Figure 5-3. Actions performed by save_ flags( ) and restore_ flags( )
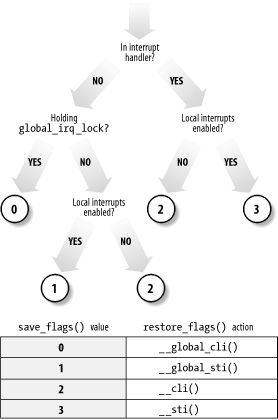
Finally, the synchronize_irq( ) function is called when a kernel control path wishes to synchronize itself with all interrupt handlers:
for (i = 0; i < smp_num_cpus; i++)
if (local_irq_count(i)) { cli( ); sti( ); break; }
By invoking cli( ), the function acquires the global_irq _lock spin lock and then waits until all executing interrupt handlers terminate; once this is done, it reenables interrupts. The synchronize_irq( ) function is usually called by device drivers when they want to make sure that all activities carried on by interrupt handlers are over.
5.3.11 Disabling Deferrable Functions
In Section 4.7.1, we explained that deferrable functions can be executed at unpredictable times (essentially, on termination of hardware interrupt handlers). Therefore, data structures accessed by deferrable functions must be protected against race conditions.
A trivial way to forbid deferrable functions execution on a CPU is to disable interrupts on that CPU. Since no interrupt handler can be activated, softirq actions cannot be started asynchronously.
Globally disabling interrupts on all CPUs also disable deferrable functions on all CPUs. In fact, recall that the do_softirq( ) function refuses to execute the softirqs when the global_irq_lock spin lock is closed. When the cli( ) macro returns, the invoking kernel control path can assume that no deferrable function is in execution on any CPU, and that none are started until interrupts are globally re-enabled.
As we shall see in the next section, however, the kernel sometimes needs to disable deferrable functions without disabling interrupts. Local deferrable functions can be disabled on each CPU by setting the _ _local_bh_count field of the irq_stat structure associated with the CPU to a nonzero value. Recall that the do_softirq( ) function never executes the softirqs if it finds a nonzero value in this field. Moreover, tasklets and bottom halves are implemented on top of softirqs, so writing a nonzero value in the field disables the execution of all deferrable functions on a given CPU, not just softirqs.
The local_bh_disable macro increments the _ _local_bh_count field by 1, while the local_bh_enable macro decrements it. The kernel can thus use several nested invocations of local_bh_disable; deferrable functions will be enabled again only by the local_bh_enable macro matching the first local_bh_disable invocation.