7.1 Page Frame Management
We saw in Section 2.4 how the Intel Pentium processor can use two different page frame sizes: 4 KB and 4 MB (or 2 MB if PAE is enabled—see Section 2.4.6). Linux adopts the smaller 4 KB page frame size as the standard memory allocation unit. This makes things simpler for two reasons:
· The Page Fault exceptions issued by the paging circuitry are easily interpreted. Either the page requested exists but the process is not allowed to address it, or the page does not exist. In the second case, the memory allocator must find a free 4 KB page frame and assign it to the process.
· The 4 KB size is a multiple of most disk block sizes, so transfers of data between main memory and disks are more efficient. Yet this smaller size is much more manageable than the 4 MB size.
7.1.1 Page Descriptors
The kernel must keep track of the current status of each page frame. For instance, it must be able to distinguish the page frames that are used to contain pages that belong to processes from those that contain kernel code or kernel data structures. Similarly, it must be able to determine whether a page frame in dynamic memory is free. A page frame in dynamic memory is free if it does not contain any useful data. It is not free when the page frame contains data of a User Mode process, data of a software cache, dynamically allocated kernel data structures, buffered data of a device driver, code of a kernel module, and so on.
State information of a page frame is kept in a page descriptor of type struct page, whose fields are shown in Table 7-1. All page descriptors are stored in the mem_map array. Since each descriptor is less than 64 bytes long, mem_map requires about four page frames for each megabyte of RAM.
Table 7-1. The fields of the page descriptor |
||
|
Type |
Name |
Description |
|
struct list_head |
list |
Contains pointers to next and previous items in a doubly linked list of page descriptors |
|
struct address_space * |
mapping |
Used when the page is inserted into the page cache (see Section 14.1) |
|
unsigned long |
index |
Either the position of the data stored in the page within the page's disk image (see Chapter 14) or a swapped-out page identifier (see Chapter 16) |
|
struct page * |
next_hash |
Contains pointer to next item in a doubly linked circular list of the page cache hash table |
|
atomic_t |
count |
Page's reference counter |
|
unsigned long |
flags |
Array of flags (see Table 7-2) |
|
struct list_head |
lru |
Contains pointers to the least recently used doubly linked list of pages |
|
wait_queue_head_t |
wait |
Page's wait queue |
|
struct page * * |
pprev_hash |
Contains pointer to previous item in a doubly linked circular list of the page cache hash table |
|
struct buffer_head * |
buffers |
Used when the page stores buffers (see Section 13.4.8.2) |
|
void * |
virtual |
Linear address of the page frame in the fourth gigabyte (see Section 7.1.5 later in this chapter) |
|
struct zone_struct * |
zone |
The zone to which the page frame belongs (see Section 7.1.2) |
You don't have to fully understand the role of all fields in the page descriptor right now. In the following chapters, we often come back to the fields of the page descriptor. Moreover, several fields have different meaning, according to whether the page frame is free and what kernel component is using the page frame.
Let's describe in greater detail two of the fields:
count
A usage reference counter for the page. If it is set to 0, the corresponding page frame is free and can be assigned to any process or to the kernel itself. If it is set to a value greater than 0, the page frame is assigned to one or more processes or is used to store some kernel data structures.
flags
Includes up to 32 flags (see Table 7-2) that describe the status of the page frame. For each PG_xyz flag, the kernel defines some macros that manipulate its value. Usually, the PageXyz macro returns the value of the flag, while the SetPageXyz and ClearPageXyz macro set and clear the corresponding bit, respectively.
Table 7-2. Flags describing the status of a page frame |
|
|
Flag name |
Meaning |
|
PG_locked |
The page is involved in a disk I/O operation. |
|
PG_error |
An I/O error occurred while transferring the page. |
|
PG_referenced |
The page has been recently accessed for a disk I/O operation. |
|
PG_uptodate |
The flag is set after completing a read operation, unless a disk I/O error happened. |
|
PG_dirty |
The page has been modified (see Section 16.5.1). |
|
PG_lru |
The page is in the active or inactive page list (see Section 16.7.2). |
|
PG_active |
The page is in the active page list (see Section 16.7.2). |
|
PG_slab |
The page frame is included in a slab (see Section 7.2 later in this chapter). |
|
PG_skip |
Not used. |
|
PG_highmem |
The page frame belongs to the ZONE_HIGHMEM zone (see Section 7.1.2). |
|
PG_checked |
The flag used by the Ext2 filesystem (see Chapter 17). |
|
PG_arch_1 |
Not used on the 80 x 86 architecture. |
|
PG_reserved |
The page frame is reserved to kernel code or is unusable. |
|
PG_launder |
The page is involved in an I/O operation triggered by shrink_cache( ) (see Section 16.7.5). |
7.1.2 Memory Zones
In an ideal computer architecture, a page frame is a memory storage unit that can be used for anything: storing kernel and user data, buffering disk data, and so on. Any kind of page of data can be stored in any page frame, without limitations.
However, real computer architectures have hardware constraints that may limit the way page frames can be used. In particular, the Linux kernel must deal with two hardware constraints of the 80 x 86 architecture:
· The Direct Memory Access (DMA) processors for ISA buses have a strong limitation: they are able to address only the first 16 MB of RAM.
· In modern 32-bit computers with lots of RAM, the CPU cannot directly access all physical memory because the linear address space is too small.
To cope with these two limitations, Linux partitions the physical memory in three zones:
ZONE_DMA
Contains pages of memory below 16 MB
ZONE_NORMAL
Contains pages of memory at and above 16 MB and below 896 MB
ZONE_HIGHMEM
Contains pages of memory at and above 896 MB
The ZONE_DMA zone includes memory pages that can be used by old ISA-based devices by means of the DMA. (Section 13.1.4 gives further details on DMA.)
The ZONE_DMA and ZONE_NORMAL zones include the "normal" pages of memory that can be directly accessed by the kernel through the linear mapping in the fourth gigabyte of the linear address space (see Section 2.5.5). Conversely, the ZONE_HIGHMEM zone includes pages of memory that cannot be directly accessed by the kernel through the linear mapping in the fourth gigabyte of linear address space (see Section 7.1.6 later in this chapter). The ZONE_HIGHMEM zone is not used on 64-bit architectures.
Each memory zone has its own descriptor of type struct zone_struct (or equivalently, zone_t). Its fields are shown in Table 7-3.
Table 7-3. The fields of the zone descriptor |
||
|
Type |
Name |
Description |
|
char * |
name |
Contains a pointer to the conventional name of the zone: "DMA," "Normal," or "HighMem" |
|
unsigned long |
size |
Number of pages in the zone |
|
spinlock_t |
lock |
Spin lock protecting the descriptor |
|
unsigned long |
free_pages |
Number of free pages in the zone |
|
unsigned long |
pages_min |
Minimum number of pages of the zone that should remain free (see Section 16.7) |
|
unsigned long |
pages_low |
Lower threshold value for the zone's page balancing algorithm (see Section 16.7) |
|
unsigned long |
pages_high |
Upper threshold value for the zone's page balancing algorithm (see Section 16.7) |
|
int |
need_balance |
Flag indicating that the zone's page balancing algorithm should be activated (see Section 16.7) |
|
free_area_t [ ] |
free_area |
Used by the buddy system page allocator (see the later section Section 7.1.7) |
|
struct pglist_data * |
zone_pgdat |
Pointer to the descriptor of the node to which this zone belongs |
|
struct page * |
zone_mem_map |
Array of page descriptors of the zone (see the later section Section 7.1.7) |
|
unsigned long |
zone_start_paddr |
First physical address of the zone |
|
unsigned long |
zone_start_mapnr |
First page descriptor index of the zone |
The zone field in the page descriptor points to the descriptor of the zone to which the corresponding page frame belongs.
The zone_names array stores the canonical names of the three zones: "DMA," "Normal," and "HighMem."
When the kernel invokes a memory allocation function, it must specify the zones that contain the requested page frames. The kernel usually specifies which zones it's willing to use. For instance, if a page frame must be directly mapped in the fourth gigabyte of linear addresses but it is not going to be used for ISA DMA transfers, then the kernel requests a page frame either in ZONE_NORMAL or in ZONE_DMA. Of course, the page frame should be obtained from ZONE_DMA only if ZONE_NORMAL does not have free page frames. To specify the preferred zones in a memory allocation request, the kernel uses the struct zonelist_struct data structure (or equivalently zonelist_t), which is an array of zone descriptor pointers.
7.1.3 Non-Uniform Memory Access (NUMA)
We are used to thinking of the computer's memory as an homogeneous, shared resource. Disregarding the role of the hardware caches, we expect the time required for a CPU to access a memory location is essentially the same, regardless of the location's physical address and the CPU. Unfortunately, this assumption is not true in some architectures. For instance, it is not true for some multiprocessor Alpha or MIPS computers.
Linux 2.4 supports the Non-Uniform Memory Access (NUMA) model, in which the access times for different memory locations from a given CPU may vary. The physical memory of the system is partitioned in several nodes. The time needed by any given CPU to access pages within a single node is the same. However, this time might not be the same for two different CPUs. For every CPU, the kernel tries to minimize the number of accesses to costly nodes by carefully selecting where the kernel data structures that are most often referenced by the CPU are stored.
The physical memory inside each node can be split in several zones, as we saw in the previous section. Each node has a descriptor of type pg_data_t, whose fields are shown in Table 7-4. All node descriptors are stored in a simply linked list, whose first element is pointed to by the pgdat_list variable.
Table 7-4. The fields of the node descriptor |
||
|
Type |
Name |
Description |
|
zone_t [ ] |
node_zones |
Array of zone descriptors of the node |
|
zonelist_t [ ] |
node_zonelists |
Array of zonelist_t data structures used by the page allocator (see the later section Section 7.1.5) |
|
int |
nr_zones |
Number of zones in the node |
|
struct page * |
node_mem_map |
Array of page descriptors of the node |
|
unsigned long * |
valid_addr_bitmap |
Bitmap of usable physical addresses for the node |
|
struct bootmem_data x* |
bdata |
Used in the kernel initialization phase |
|
unsigned long |
node_start_paddr |
First physical address of the node |
|
unsigned long |
node_start_mapnr |
First page descriptor index of the node |
|
unsigned long |
node_size |
Size of the node (in pages) |
|
int |
node_id |
Identifier of the node |
|
pg_data_t * |
node_next |
Next item in the node list |
As usual, we are mostly concerned with the 80 x 86 architecture. IBM-compatible PCs use the Uniform Access Memory model (UMA), thus the NUMA support is not really required. However, even if NUMA support is not compiled in the kernel, Linux makes use of a single node that includes all system physical memory; the corresponding descriptor is stored in the contig_page_data variable.
On the 80 x 86 architecture, grouping the physical memory in a single node might appear useless; however, this approach makes the memory handling code more portable, because the kernel may assume that the physical memory is partitioned in one or more nodes in all architectures.[1]
[1] We have another example of this kind of design choice: Linux uses three levels of Page Tables even when the hardware architecture defines just two levels (see Section 2.5).
7.1.4 Initialization of the Memory Handling Data Structures
Dynamic memory and the values used to refer to it are illustrated in Figure 7-1. The zones of memory are now drawn to scale; ZONE_NORMAL is usually larger than ZONE_DMA, and, if present, ZONE_HIGHMEM is usually larger than ZONE_NORMAL. Notice that ZONE_HIGHMEM starts from physical address 0x38000000, which corresponds to 896 MB.
Figure 7-1. Memory layout
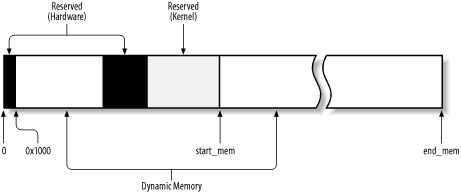
We already described how the paging_init( ) function initializes the kernel Page Tables according to the amount of RAM in the system in Section 2.5.5. Beside Page Tables, the paging_init( ) function also initializes other memory handling data structures. It invokes kmap_init( ), which essentially sets up the kmap_pte variable to create "windows" of linear addresses that allow the kernel to address the ZONE_HIGHMEM zone (see Section 7.1.6.2 later in this chapter). Then, paging_init( ) invokes the free_area_init( ) function, passing an array storing the sizes of the three memory zones to it.
The free_area_init( ) function sets up both the zone descriptors and the page descriptors. The function receives the zones_size array (size of each memory zone) as its parameter, and executes the following operations:[2]
[2] In NUMA architectures, these operations must be performed separately on every node. However, we are focusing on the 80 x 86 architecture, which has just one node.
1. Computes the total number of page frames in RAM by adding the value in zones_size, and stores the result in the totalpages local variable.
2. Initializes the active_list and inactive_list lists of page descriptors (see Chapter 16).
3. Allocates space for the mem_map array of page descriptors. The space needed is the product of totalpages by the page descriptor size.
4. Initializes some fields of the node descriptor contig_page_data:
5. contig_page_data.node_size = totalpages;6. contig_page_data.node_start_paddr = 0x00000000;contig_page_data.node_start_mapnr = 0;
7. Initializes some fields of all page descriptors. All page frames are marked as reserved, but later, the PG_reserved flag of the page frames in dynamic memory will be cleared:
8. for (p = mem_map; p < mem_map + totalpages; p++) {9. p->count = 0;10. SetPageReserved(p);11. init_waitqueue_head(&p->wait);12. p->list.next = p->list.prev = p;}
13. Stores the address of the memory zone descriptor in the zone local variable and for each element of the zone_names array (index j between 0 and 2), performs the following steps:
a. Initializes some fields of the descriptor:
b. zone->name = zone_names[j];c. zone->size = zones_size[j];d. zone->lock = SPIN_LOCK_UNLOCKED;e. zone->zone_pgdat = & contig_page_data;f. zone->free_pages = 0;zone->need_balance = 0;
g. If the zone is empty (that is, it does not include any page frame), the function goes back to the beginning of Step 6 and continues with the next zone.
h. Otherwise, the zone includes at least one page frame and the function initializes the pages_min, pages_low, and pages_high fields of the zone descriptor (see Chapter 16).
i. Sets up the zone_mem_map field of the zone descriptor to the address of the first page descriptor in the zone.
j. Sets up the zone_start_mapnr field of the zone descriptor to the index of the first page descriptor in the zone.
k. Sets up the zone_start_paddr field of the zone descriptor to the physical address of the first page frame in the zone.
l. Stores the address of the zone descriptor in the zone field of the page descriptor for each page frame of the zone.
m. If the zone is either ZONE_DMA or ZONE_NORMAL, stores the linear address in the fourth gigabyte that maps the page frame into the virtual field of every page descriptor of the zone.
n. Initializes the free_area_t structures in the free_area array of the zone descriptor (see Section 7.1.7 later in this chapter).
14. Initializes the node_zonelists array of the contig_page_data node descriptor. The array includes 16 elements; each element corresponds to a different type of memory request and specifies the zones (in order of preference) from where the page frames could be retrieved. See Section 7.1.5 later in this chapter for further details.
When the paging_init( ) function terminates, dynamic memory is not yet usable because the PG_reserved flag of all pages is set. Memory initialization is further carried on by the mem_init( ) function, which is invoked subsequently to paging_init( ).
Essentially, the mem_init( ) function initializes the value of num_physpages, the total number of page frames present in the system. It then scans all page frames associated with the dynamic memory; for each of them, the function sets the count field of the corresponding descriptor to 1, resets the PG_reserved flag, sets the PG_highmem flag if the page belongs to ZONE_HIGHMEM, and calls the free_ page( ) function on it. Besides releasing the page frame (see Section 7.1.7 later in this chapter), free_page( ) also increments the value of the free_pages field of the memory zone descriptor that owns the page frame. The free_pages fields of all zone descriptors are used by the nr_free_pages( ) function to compute the total number of free page frames in the dynamic memory.
The mem_init( ) function also counts the number of page frames that are not associated with dynamic memory. Several symbols produced while compiling the kernel (some are described in Section 2.5.3) enable the function to count the number of page frames reserved for the hardware, kernel code, and kernel data, and the number of page frames used during kernel initialization that can be successively released.
7.1.5 Requesting and Releasing Page Frames
After having seen how the kernel allocates and initializes the data structures for page frame handling, we now look at how page frames are allocated and released.
Page frames can be requested by using six slightly different functions and macros. Unless otherwise stated, they return the linear address of the first allocated page, or return NULL if the allocation failed.
alloc_pages(gfp_mask, order)
Function used to request 2order contiguous page frames. It returns the address of the descriptor of the first allocated page frame or returns NULL if the allocation failed.
alloc_page(gfp_mask)
Macro used to get a single page frame; it expands to:
alloc_pages(gfp_mask, 0)
It returns the address of the descriptor of the allocated page frame or returns NULL if the allocation failed.
_ _get_free_pages(gfp_mask, order)
Function that is similar to alloc_pages( ), but it returns the linear address of the first allocated page.
_ _get_free_page(gfp_mask)
Macro used to get a single page frame; it expands to:
_ _get_free_pages(gfp_mask, 0)
get_zeroed_page(gfp_mask) , or equivalently get_free_page(gfp_mask)
Function that invokes:
alloc_pages(gfp_mask, 0)
and then fills the page frame obtained with zeros.
_ _get_dma_pages(gfp_mask, order)
Macro used to get page frames suitable for DMA; it expands to:
_ _get_free_pages(gfp_mask | _ _GFP_DMA, order)
The parameter gfp_mask specifies how to look for free page frames. It consists of the following flags:
_ _GFP_WAIT
The kernel is allowed to block the current process waiting for free page frames.
_ _GFP_HIGH
The kernel is allowed to access the pool of free page frames left for recovering from very low memory conditions.
_ _GFP_IO
The kernel is allowed to perform I/O transfers on low memory pages in order to free page frames.
_ _GFP_HIGHIO
The kernel is allowed to perform I/O transfers on high memory pages in order free page frames.
_ _GFP_FS
The kernel is allowed to perform low-level VFS operations.
_ _GFP_DMA
The requested page frames must be included in the ZONE_DMA zone (see the earlier section Section 7.1.2.)
_ _GFP_HIGHMEM
The requested page frames can be included in the ZONE_HIGHMEM zone.
In practice, Linux uses the predefined combinations of flag values shown in Table 7-5; the group name is what you'll encounter as argument of the six page frame allocation functions.
The _ _GFP_DMA and _ _GFP_HIGHMEM flags are called zone modifiers; they specify the zones searched by the kernel while looking for free page frames. The node_zonelists field of the contig_page_data node descriptor is an array of lists of zone descriptors; each list is associated with one specific combination of the zone modifiers. Although the array includes 16 elements, only 4 are really used, since there are currently only 2 zone modifiers. They are shown in Table 7-6.
Table 7-6. Zone modifier lists |
||
|
_ _GFP_DMA |
_ _GFP_HIGHMEM |
Zone list |
|
0 |
0 |
ZONE_NORMAL + ZONE_DMA |
|
0 |
1 |
ZONE_HIGHMEM + ZONE_NORMAL + ZONE_DMA |
|
1 |
0 |
ZONE_DMA |
|
1 |
1 |
ZONE_DMA |
Page frames can be released through each of the following four functions and macros:
This function checks the page descriptor pointed to by page; if the page frame is not reserved (i.e., if the PG_reserved flag is equal to 0), it decrements the count field of the descriptor. If count becomes 0, it assumes that 2order contiguous page frames starting from addr are no longer used. In this case, the function invokes _ _free_pages_ok( ) to insert the page frame descriptor of the first free page in the proper list of free page frames (described in the following section).
free_pages(addr, order)
This function is similar to _ _free_pages( ), but it receives as an argument the linear address addr of the first page frame to be released.
_ _free_page(page)
This macro releases the page frame having the descriptor pointed to by page; it expands to:
_ _free_pages(page, 0)
free_page(addr)
This macro releases the page frame having the linear address addr; it expands to:
free_pages(addr, 0)
7.1.6 Kernel Mappings of High-Memory Page Frames
Page frames above the 896 MB boundary are not mapped in the fourth gigabyte of the kernel linear address spaces, so they cannot be directly accessed by the kernel. This implies that any page allocator function that returns the linear address of the assigned page frame doesn't work for the high memory.
For instance, suppose that the kernel invoked _ _get_free_pages(GFP_HIGHMEM,0) to allocate a page frame in high memory. If the allocator assigned a page frame in high memory, _ _get_free_pages( ) cannot return its linear address because it doesn't exist; thus, the function returns NULL. In turn, the kernel cannot use the page frame; even worse, the page frame cannot be released because the kernel has lost track of it.
In short, allocation of high-memory page frames must be done only through the alloc_pages( ) function and its alloc_page( ) shortcut, which both return the address of the page descriptor of the first allocated page frame. Once allocated, a high-memory page frame has to be mapped into the fourth gigabyte of the linear address space, even though the physical address of the page frame may well exceed 4 GB.
To do this, the kernel may use three different mechanisms, which are called permanent kernel mappings, temporary kernel mappings, and noncontiguous memory allocation. In this section, we focus on the first two techniques; the third one is discussed in Section 7.3 later in this chapter.
Establishing a permanent kernel mapping may block the current process; this happens when no free Page Table entries exist that can be used as "windows" on the page frames in high memory (see the next section). Thus, a permanent kernel mapping cannot be used in interrupt handlers and deferrable functions. Conversely, establishing a temporary kernel mapping never requires blocking the current process; its drawback, however, is that very few temporary kernel mappings can be established at the same time.
Of course, none of these techniques allow addressing the whole RAM simultaneously. After all, only 128 MB of linear address space are left for mapping the high memory, while PAE supports systems having up to 64 GB of RAM.
7.1.6.1 Permanent kernel mappings
Permanent kernel mappings allow the kernel to establish long-lasting mappings of high-memory page frames into the kernel address space. They use a dedicated Page Table whose address is stored in the pkmap_page_table variable. The number of entries in the Page Table is yielded by the LAST_PKMAP macro. As usual, the Page Table includes either 512 or 1,024 entries, according to whether PAE is enabled or disabled (see Section 2.4.6); thus, the kernel can access at most 2 or 4 MB of high memory at once.
The Page Table maps the linear addresses starting from PKMAP_BASE (usually 0xfe000000). The address of the descriptor corresponding to the first page frame in high memory is stored in the highmem_start_page variable.
The pkmap_count array includes LAST_PKMAP counters, one for each entry of the pkmap_page_table Page Table. We distinguish three cases:
The counter is 0
The corresponding Page Table entry does not map any high-memory page frame and is usable.
The counter is 1
The corresponding Page Table entry does not map any high-memory page frame, but it cannot be used because the corresponding TLB entry has not been flushed since its last usage.
The counter is n (greater than 1)
The corresponding Page Table entry maps a high-memory page frame, which is used by exactly n-1 kernel components.
The kmap( ) function establishes a permanent kernel mapping. It is essentially equivalent to the following code:
void * kmap(struct page * page)
{if (page < highmem_page_start)
return page->virtual;
return kmap_high(page);
}
The virtual field of the page descriptor stores the linear address in the fourth gigabyte mapping the page frame, if any. Thus, for any page frame below the 896 MB boundary, the field always includes the physical address of the page frame plus PAGE_OFFSET. Conversely, if the page frame is in high memory, the virtual field has a non-null value only if the page frame is currently mapped, either by the permanent or the temporary kernel mapping.
The kmap_high( ) function is invoked if the page frame really belongs to the high memory. The function is essentially equivalent to the following code:
void * kmap_high(struct page * page)
{ unsigned long vaddr;
spin_lock(&kmap_lock);
vaddr = (unsigned long) page->virtual;
if (!vaddr)
vaddr = map_new_virtual(page);
pkmap_count[(vaddr-PKMAP_BASE) >> PAGE_SHIFT]++;
spin_unlock(&kmap_lock);
return (void *) vaddr;
}
The function gets the kmap_lock spin lock to protect the Page Table against concurrent accesses in multiprocessor systems. Notice that there is no need to disable the interrupts because kmap( ) cannot be invoked by interrupt handlers and deferrable functions. Next, the kmap_high( ) function checks whether the virtual field of the page descriptor already stores a non-null linear address. If not, the function invokes the map_new_virtual( ) function to insert the page frame physical address in an entry of pkmap_page_table. Then kmap_high( ) increments the counter corresponding to the linear address of the page frame by 1 because another kernel component is going to access the page frame. Finally, kmap_high( ) releases the kmap_lock spin lock and returns the linear address that maps the page.
The map_new_virtual( ) function essentially executes two nested loops:
for (;;) {int count;
DECLARE_WAITQUEUE(wait, current);
for (count = LAST_PKMAP; count >= 0; --count) {last_pkmap_nr = (last_pkmap_nr + 1) & (LAST_PKMAP - 1);
if (!last_pkmap_nr) {flush_all_zero_pkmaps( );
count = LAST_PKMAP;
}
if (!pkmap_count[last_pkmap_nr]) {unsigned long vaddr = PKMAP_BASE + (last_pkmap_nr << PAGE_SHIFT);
set_pte(&(pkmap_page_table[last_pkmap_nr]), mk_pte(page, 0x63));
pkmap_count[last_pkmap_nr] = 1;
page->virtual = (void *) vaddr;
return vaddr;
}
}
current->state = TASK_UNITERRUPTIBLE;
add_wait_queue(&pkmap_map_wait, &wait);
spin_unlock(&kmap_lock);
schedule( );
remove_wait_queue(&pkmap_map_wait, &wait);
spin_lock(&kmap_lock);
if (page->virtual)
return (unsigned long) page->virtual;
}
In the inner loop, the function scans all counters in pkmap_count that are looking for a null value. The last_pkmap_nr variable stores the index of the last used entry in the pkmap_page_table Page Table. Thus, the search starts from where it was left in the last invocation of the map_new_virtual( ) function.
When the last counter in pkmap_count is reached, the search restarts from the counter at index 0. Before continuing, however, map_new_virtual( ) invokes the flush_all_zero_pkmaps( ) function, which starts another scanning of the counters looking for the value 1. Each counter that has value 1 denotes an entry in pkmap_page_table that is free but cannot be used because the corresponding TLB entry has not yet been flushed. flush_all_zero_pkmaps( ) issues the TLB flushes on such entries and resets their counters to zero.
If the inner loop cannot find a null counter in pkmap_count, the map_new_virtual( ) function blocks the current process until some other process releases an entry of the pkmap_page_table Page Table. This is achieved by inserting current in the pkmap_map_wait wait queue, setting the current state to TASK_UNINTERRUPTIBLE and invoking schedule( ) to relinquish the CPU. Once the process is awoken, the function checks whether another process has mapped the page by looking at the virtual field of the page descriptor; if some other process has mapped the page, the inner loop is restarted.
When a null counter is found by the inner loop, the map_new_virtual( ) function:
1. Computes the linear address that corresponds to the counter.
2. Writes the page's physical address into the entry in pkmap_page_table. The function also sets the bits Accessed, Dirty, Read/Write, and Present (value 0x63) in the same entry.
3. Sets to 1 the pkmap_count counter.
4. Writes the linear address into the virtual field of the page descriptor.
5. Returns the linear address.
The kunmap( ) function destroys a permanent kernel mapping. If the page is really in the high memory zone, it invokes the kunmap_high( ) function, which is essentially equivalent to the following code:
void kunmap_high(struct page * page)
{spin_lock(&kmap_lock);
if ((--pkmap_count[((unsigned long) page->virtual-PKMAP_BASE)>>PAGE_SHIFT])==1)
wake_up(&pkmap_map_wait);
spin_unlock(&kmap_lock);
}
Notice that if the counter of the Page Table entry becomes equal to 1 (free), kunmap_high( ) wakes up the processes waiting in the pkmap_map_wait wait queue.
7.1.6.2 Temporary kernel mappings
Temporary kernel mappings are simpler to implement than permanent kernel mappings; moreover, they can be used inside interrupt handlers and deferrable functions because they never block the current process.
Any page frame in high memory can be mapped through a window in the kernel address space—namely, a Page Table entry that is reserved for this purpose. The number of windows reserved for temporary kernel mappings is quite small.
Each CPU has its own set of five windows whose linear addresses are identified by the enum km_type data structure:
enum km_type {KM_BOUNCE_READ,
KM_SKB_DATA,
KM_SKB_DATA_SOFTIRQ,
KM_USER0,
KM_USER1,
KM_TYPE_NR
}
The kernel must ensure that the same window is never used by two kernel control paths at the same time. Thus, each symbol is named after the kernel component that is allowed to use the corresponding window. The last symbol, KM_TYPE_NR, does not represent a linear address by itself, but yields the number of different windows usable by every CPU.
Each symbol in km_type, except the last one, is an index of a fix-mapped linear address (see Section 2.5.6). The enum fixed_addresses data structure includes the symbols FIX_KMAP_BEGIN and FIX_KMAP_END; the latter is assigned to the index FIX_KMAP_BEGIN+(KM_TYPE_NR*NR_CPUS)-1. In this manner, there are KM_TYPE_NR fix-mapped linear addresses for each CPU in the system. Furthermore, the kernel initializes the kmap_pte variable with the address of the Page Table entry corresponding to the fix_to_virt(FIX_KMAP_BEGIN) linear address.
To establish a temporary kernel mapping, the kernel invokes the kmap_atomic( ) function, which is essentially equivalent to the following code:
void * kmap_atomic(struct page * page, enum km_type type)
{enum fixed_addresses idx;
if (page < highmem_start_page)
return page->virtual;
idx = type + KM_TYPE_NR * smp_processor_id( );
set_pte(kmap_pte-idx, mk_pte(page, 0x063));
_ _flush_tlb_one(fix_to_virt(FIX_KMAP_BEGIN+idx));
}
The type argument and the CPU identifier specify what fix-mapped linear address has to be used to map the request page. The function returns the linear address of the page frame if it doesn't belong to high memory; otherwise, it sets up the Page Table entry corresponding to the fix-mapped linear address with the page's physical address and the bits Present, Accessed, Read/Write, and Dirty. Finally, the TLB entry corresponding to the linear address is flushed.
To destroy a temporary kernel mapping, the kernel uses the kunmap_atomic( ) function. In the 80 x 86 architecture, however, this function does nothing.
Temporary kernel mappings should be used carefully. A kernel control path using a temporary kernel mapping must never block, because another kernel control path might use the same window to map some other high memory page.
7.1.7 The Buddy System Algorithm
The kernel must establish a robust and efficient strategy for allocating groups of contiguous page frames. In doing so, it must deal with a well-known memory management problem called external fragmentation: frequent requests and releases of groups of contiguous page frames of different sizes may lead to a situation in which several small blocks of free page frames are "scattered" inside blocks of allocated page frames. As a result, it may become impossible to allocate a large block of contiguous page frames, even if there are enough free pages to satisfy the request.
There are essentially two ways to avoid external fragmentation:
· Use the paging circuitry to map groups of noncontiguous free page frames into intervals of contiguous linear addresses.
· Develop a suitable technique to keep track of the existing blocks of free contiguous page frames, avoiding as much as possible the need to split up a large free block to satisfy a request for a smaller one.
The second approach is preferred by the kernel for three good reasons:
· In some cases, contiguous page frames are really necessary, since contiguous linear addresses are not sufficient to satisfy the request. A typical example is a memory request for buffers to be assigned to a DMA processor (see Chapter 13). Since the DMA ignores the paging circuitry and accesses the address bus directly while transferring several disk sectors in a single I/O operation, the buffers requested must be located in contiguous page frames.
· Even if contiguous page frame allocation is not strictly necessary, it offers the big advantage of leaving the kernel paging tables unchanged. What's wrong with modifying the Page Tables? As we know from Chapter 2, frequent Page Table modifications lead to higher average memory access times, since they make the CPU flush the contents of the translation lookaside buffers.
· Large chunks of contiguous physical memory can be accessed by the kernel through 4 MB pages. The reduction of translation lookaside buffers misses, in comparison to the use of 4 KB pages, significantly speeds up the average memory access time (see Section 2.4.8).
The technique adopted by Linux to solve the external fragmentation problem is based on the well-known buddy system algorithm. All free page frames are grouped into 10 lists of blocks that contain groups of 1, 2, 4, 8, 16, 32, 64, 128, 256, and 512 contiguous page frames, respectively. The physical address of the first page frame of a block is a multiple of the group size—for example, the initial address of a 16-page-frame block is a multiple of 16 x 212 (212 = 4,096, which is the regular page size).
We'll show how the algorithm works through a simple example.
Assume there is a request for a group of 128 contiguous page frames (i.e., a half-megabyte). The algorithm checks first to see whether a free block in the 128-page-frame list exists. If there is no such block, the algorithm looks for the next larger block—a free block in the 256-page-frame list. If such a block exists, the kernel allocates 128 of the 256 page frames to satisfy the request and inserts the remaining 128 page frames into the list of free 128-page-frame blocks. If there is no free 256-page block, the kernel then looks for the next larger block (i.e., a free 512-page-frame block). If such a block exists, it allocates 128 of the 512 page frames to satisfy the request, inserts the first 256 of the remaining 384 page frames into the list of free 256-page-frame blocks, and inserts the last 128 of the remaining 384 page frames into the list of free 128-page-frame blocks. If the list of 512-page-frame blocks is empty, the algorithm gives up and signals an error condition.
The reverse operation, releasing blocks of page frames, gives rise to the name of this algorithm. The kernel attempts to merge pairs of free buddy blocks of size b together into a single block of size 2b. Two blocks are considered buddies if:
· Both blocks have the same size, say b.
· They are located in contiguous physical addresses.
· The physical address of the first page frame of the first block is a multiple of 2 x b x 212.
The algorithm is iterative; if it succeeds in merging released blocks, it doubles b and tries again so as to create even bigger blocks.
7.1.7.1 Data structures
Linux uses a different buddy system for each zone. Thus, in the 80 x 86 architecture, there are three buddy systems: the first handles the page frames suitable for ISA DMA, the second handles the "normal" page frames, and the third handles the high-memory page frames. Each buddy system relies on the following main data structures:
· The mem_map array introduced previously. Actually, each zone is concerned with a subset of the mem_map elements. The first element in the subset and its number of elements are specified, respectively, by the zone_mem_map and size fields of the zone descriptor.
· An array having 10 elements of type free_area_t, one element for each group size. The array is stored in the free_area field of the zone descriptor.
· Ten binary arrays named bitmaps, one for each group size. Each buddy system has its own set of bitmaps, which it uses to keep track of the blocks it allocates.
The free_area_t (or equivalently, struct free_area_struct) data structure is defined as follows:
typedef struct free_area_struct { struct list_head free_list;
unsigned long *map;
} free_area_t;
The k th element of the free_area array in the zone descriptor is associated with a doubly linked circular list of blocks of size 2k; each member of such a list is the descriptor of the first page frame of a block. The list is implemented through the list field of the page descriptor.
The map field points to a bitmap whose size depends on the number of page frames in the zone. Each bit of the bitmap of the k th entry of the free_area array describes the status of two buddy blocks of size 2k page frames. If a bit of the bitmap is equal to 0, either both buddy blocks of the pair are free or both are busy; if it is equal to 1, exactly one of the blocks is busy. When both buddies are free, the kernel treats them as a single free block of size 2k+1.
Let's consider, for sake of illustration, a zone including 128 MB of RAM. The 128 MB can be divided into 32,768 single pages, 16,384 groups of 2 pages each, or 8,192 groups of 4 pages each, and so on up to 64 groups of 512 pages each. So the bitmap corresponding to free_area[0] consists of 16,384 bits, one for each pair of the 32,768 existing page frames; the bitmap corresponding to free_area[1] consists of 8,192 bits, one for each pair of blocks of two consecutive page frames; the last bitmap corresponding to free_area[9] consists of 32 bits, one for each pair of blocks of 512 contiguous page frames.
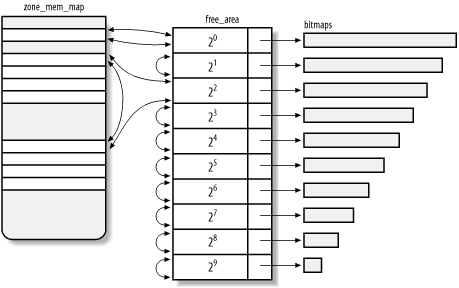
Figure 7-2 illustrates the use of the data structures introduced by the buddy system algorithm. The array zone_mem_map contains nine free page frames grouped in one block of one (a single page frame) at the top and two blocks of four further down. The double arrows denote doubly linked circular lists implemented by the free_list field. Notice that the bitmaps are not drawn to scale.
Figure 7-2. Data structures used by the buddy system
7.1.7.2 Allocating a block
The alloc_pages( ) function is the core of the buddy system allocation algorithm. Any other allocator function or macro listed in the earlier section Section 7.1.5 ends up invoking alloc_pages( ).
The function considers the list of the contig_page_data.node_zonelists array corresponding to the zone modifiers specified in the argument gfp_mask. Starting with the first zone descriptor in the list, it compares the number of free page frames in the zone (stored in the free_pages field of the zone descriptor), the number of requested page frames (argument order of alloc_pages( )), and the threshold value stored in the pages_low field of the zone descriptor. If free_pages - 2 order is smaller than or equal to pages_low, the function skips the zone and considers the next zone in the list. If no zone has enough free page frames, alloc_pages( ) restarts the loop, this time looking for a zone that has at least pages_min free page frames. If such a zone doesn't exist and if the current process is allowed to wait, the function invokes balance_classzone( ), which in turn invokes try_to_free_pages( ) to reclaim enough page frames to satisfy the memory request (see Section 16.7).
When alloc_pages( ) finds a zone with a suitable number of free page frames, it invokes the rmqueue( ) function to allocate a block in that zone. The function takes two arguments: the address of the zone descriptor, and order, which denotes the logarithm of the size of the requested block of free pages (0 for a one-page block, 1 for a two-page block, and so forth). If the page frames are successfully allocated, the rmqueue( ) function returns the address of the page descriptor of the first allocated page frame; that address is also returned by alloc_pages( ). Otherwise, rmqueue( ) returns NULL, and alloc_pages( ) consider the next zone in the list.
The rmqueue( ) function is equivalent to the following fragments. First, a few local variables are declared and initialized:
free_area_t * area = &(zone->free_area[order]);
unsigned int curr_order = order;
struct list_head *head, *curr;
struct page *page;
unsigned long flags;
unsigned int index;
unsigned long size;
The function disables interrupts and acquires the spin lock of the zone descriptor because it will alter its fields to allocate a block. Then it performs a cyclic search through each list for an available block (denoted by an entry that doesn't point to the entry itself), starting with the list for the requested order and continuing if necessary to larger orders. This is equivalent to the following fragment:
spin_lock_irqsave(&zone->lock, flags);
do {head = &area->free_list;
curr = head->next;
if (curr != head)
goto block_found;
curr_order++;
area++;
} while (curr_order < 10);
spin_unlock_irqrestore(&zone->lock, flags);
return NULL;
If the loop terminates, no suitable free block has been found, so rmqueue( ) returns a NULL value. Otherwise, a suitable free block has been found; in this case, the descriptor of its first page frame is removed from the list, the corresponding bitmap is updated, and the value of free_ pages in the zone descriptor is decreased:
block_found:
page = list_entry(curr, struct page, list);
list_del(curr);
index = page - zone->zone_mem_map;
if (curr_order != 9)
change_bit(index>>(1+curr_order), area->map);
zone->free_pages -= 1UL << order;
If the block found comes from a list of size curr_order greater than the requested size order, a while cycle is executed. The rationale behind these lines of codes is as follows: when it becomes necessary to use a block of 2k page frames to satisfy a request for 2h page frames (h < k), the program allocates the last 2h page frames and iteratively reassigns the first 2k - 2h page frames to the free_area lists that have indexes between h and k:
size = 1 << curr_order;
while (curr_order > order) {area--;
curr_order--;
size >>= 1;
/* insert *page as first element in the list and update the bitmap */
list_add(&page->list, &area->free_list);
change_bit(index >> (1+curr_order), area->map);
/* now take care of the second half of the free block starting at *page */
index += size;
page += size;
}
Finally, rmqueue( ) releases the spin lock, updates the count field of the page descriptor associated with the selected block, and executes the return instruction:
spin_unlock_irqrestore(&zone->lock, flags);
atomic_set(&page->count, 1);
return page;
As a result, the alloc_pages( ) function returns the address of the page descriptor of the first page frame allocated.
7.1.7.3 Freeing a block
The _ _free_pages_ok( ) function implements the buddy system strategy for freeing page frames. It uses two input parameters:
page
The address of the descriptor of the first page frame included in the block to be released
order
The logarithmic size of the block
The _ _free_pages_ok( ) function usually inserts the block of page frames in the buddy system data structures so they can be used in subsequent allocation requests. One case is an exception: if the current process is moving pages across memory zones to rebalance them, the function does not free the page frames, but inserts the block in a special list of the process. To decide what to do with the block of page frames, _ _free_pages_ok( ) checks the PF_FREE_PAGES flag of the process. It is set only if the process is rebalancing the memory zones. Anyway, we discuss this special case in Chapter 16; we assume here that the PF_FREE_PAGES flag of current is not set, so _ _free_pages_ok( ) inserts the block in the buddy system data structures.
The function starts by declaring and initializing a few local variables:
unsigned long flags;
unsigned long mask = (~0UL) << order;
zone_t * zone = page->zone;
struct page * base = zone->zone_mem_map;
free_area_t * area = &zone->free_area[order];
unsigned long page_idx = page - base;
unsigned long index = page_idx >> (1 + order);
struct page * buddy;
The page_idx local variable contains the index of the first page frame in the block with respect to the first page frame of the zone. The index local variable contains the bit number corresponding to the block in the bitmap.
The function clears the PG_referenced and PG_dirty flags of the first page frame, then it acquires the zone spin lock and disables interrupts:
page->flags &= ~((1<<PG_referenced) | (1<<PG_dirty));
spin_lock_irqsave(&zone->lock, flags);
The mask local variable contains the two's complement of 2order. It is used to increment the counter of free page frames in the zone:
zone->free_pages -= mask;
The function now starts a cycle executed at most 9 - order times, once for each possibility for merging a block with its buddy. The function starts with the smallest-sized block and moves up to the top size. The condition driving the while loop is:
mask + (1 << 9)
In the body of the loop, the bits set in mask are shifted to the left at each iteration and the buddy block of the block that has the number page_idx is checked:
if (!test_and_change_bit(index, area->map)) break;
If the buddy block is not free, the function breaks out of the cycle; if it is free, the function detaches it from the corresponding list of free blocks. The block number of the buddy is derived from page_idx by switching a single bit:
buddy = &base[page_idx ^ -mask];list_del(&buddy->list);
At the end of each iteration, the function updates the mask, area, index, and page_idx local variables:
mask <<= 1;area++;index >>= 1;page_idx &= mask;
The function then continues the next iteration, trying to merge free blocks twice as large as the ones considered in the previous cycle. When the cycle is finished, the free block obtained cannot be merged further with other free blocks. It is then inserted in the proper list:
list_add(&(base[page_idx].list), &area->free_list);
Finally, the function releases the zone spin lock and returns:
spin_unlock_irqrestore(&zone->lock, flags);
return;