7.2 Memory Area Management
This section deals with memory areas—that is, with sequences of memory cells having contiguous physical addresses and an arbitrary length.
The buddy system algorithm adopts the page frame as the basic memory area. This is fine for dealing with relatively large memory requests, but how are we going to deal with requests for small memory areas, say a few tens or hundreds of bytes?
Clearly, it would be quite wasteful to allocate a full page frame to store a few bytes. A better approach instead consists of introducing new data structures that describe how small memory areas are allocated within the same page frame. In doing so, we introduce a new problem called internal fragmentation. It is caused by a mismatch between the size of the memory request and the size of the memory area allocated to satisfy the request.
A classical solution (adopted by early Linux versions) consists of providing memory areas whose sizes are geometrically distributed; in other words, the size depends on a power of 2 rather than on the size of the data to be stored. In this way, no matter what the memory request size is, we can ensure that the internal fragmentation is always smaller than 50 percent. Following this approach, the kernel creates 13 geometrically distributed lists of free memory areas whose sizes range from 32 to 131, 056 bytes. The buddy system is invoked both to obtain additional page frames needed to store new memory areas and, conversely, to release page frames that no longer contain memory areas. A dynamic list is used to keep track of the free memory areas contained in each page frame.
7.2.1 The Slab Allocator
Running a memory area allocation algorithm on top of the buddy algorithm is not particularly efficient. A better algorithm is derived from the slab allocator schema developed in 1994 for the Sun Microsystem Solaris 2.4 operating system. It is based on the following premises:
· The type of data to be stored may affect how memory areas are allocated; for instance, when allocating a page frame to a User Mode process, the kernel invokes the get_zeroed_page( ) function, which fills the page with zeros.
The concept of a slab allocator expands upon this idea and views the memory areas as objects consisting of both a set of data structures and a couple of functions or methods called the constructor and destructor . The former initializes the memory area while the latter deinitializes it.
To avoid initializing objects repeatedly, the slab allocator does not discard the objects that have been allocated and then released but instead saves them in memory. When a new object is then requested, it can be taken from memory without having to be reinitialized.
In practice, the memory areas handled by Linux do not need to be initialized or deinitialized. For efficiency reasons, Linux does not rely on objects that need constructor or destructor methods; the main motivation for introducing a slab allocator is to reduce the number of calls to the buddy system allocator. Thus, although the kernel fully supports the constructor and destructor methods, the pointers to these methods are NULL.
· The kernel functions tend to request memory areas of the same type repeatedly. For instance, whenever the kernel creates a new process, it allocates memory areas for some fixed size tables such as the process descriptor, the open file object, and so on (see Chapter 3). When a process terminates, the memory areas used to contain these tables can be reused. Since processes are created and destroyed quite frequently, without the slab allocator, the kernel wastes time allocating and deallocating the page frames containing the same memory areas repeatedly; the slab allocator allows them to be saved in a cache and reused quickly.
· Requests for memory areas can be classified according to their frequency. Requests of a particular size that are expected to occur frequently can be handled most efficiently by creating a set of special-purpose objects that have the right size, thus avoiding internal fragmentation. Meanwhile, sizes that are rarely encountered can be handled through an allocation scheme based on objects in a series of geometrically distributed sizes (such as the power-of-2 sizes used in early Linux versions), even if this approach leads to internal fragmentation.
· There is another subtle bonus in introducing objects whose sizes are not geometrically distributed: the initial addresses of the data structures are less prone to be concentrated on physical addresses whose values are a power of 2. This, in turn, leads to better performance by the processor hardware cache.
· Hardware cache performance creates an additional reason for limiting calls to the buddy system allocator as much as possible. Every call to a buddy system function "dirties" the hardware cache, thus increasing the average memory access time. The impact of a kernel function on the hardware cache is called the function footprint; it is defined as the percentage of cache overwritten by the function when it terminates. Clearly, large footprints lead to a slower execution of the code executed right after the kernel function, since the hardware cache is by now filled with useless information.
The slab allocator groups objects into caches. Each cache is a "store" of objects of the same type. For instance, when a file is opened, the memory area needed to store the corresponding "open file" object is taken from a slab allocator cache named filp (for "file pointer"). The slab allocator caches used by Linux may be viewed at runtime by reading the /proc/slabinfo file.
The area of main memory that contains a cache is divided into slabs; each slab consists of one or more contiguous page frames that contain both allocated and free objects (see Figure 7-3).
Figure 7-3. The slab allocator components
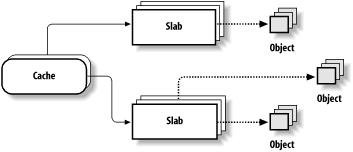
The slab allocator never releases the page frames of an empty slab on its own. It would not know when free memory is needed, and there is no benefit to releasing objects when there is still plenty of free memory for new objects. Therefore, releases occur only when the kernel is looking for additional free page frames (see Section 7.2.13 later in this chapter and Section 16.7).
7.2.2 Cache Descriptor
Each cache is described by a table of type struct kmem_cache_s (which is equivalent to the type kmem_cache_t). The most significant fields of this table are:
name
Character array storing the name of the cache.
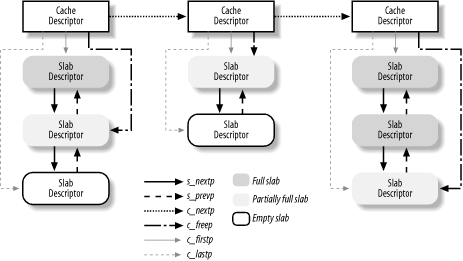
slabs_full
Doubly linked circular list of slab descriptors with no free objects.
slabs_partial
Doubly linked circular list of slab descriptors with both free and nonfree objects.
slabs_free
Doubly linked circular list of slab descriptors with free objects only.
spinlock
Spin lock protecting the cache from concurrent accesses in multiprocessor systems.
num
Number of objects packed into a single slab. (All slabs of the cache have the same size.)
objsize
Size of the objects included in the cache. (This size may be rounded up by the slab allocator if the initial addresses of the objects must be memory-aligned.)
gfporder
Logarithm of the number of contiguous page frames included in a single slab.
ctor, dtor
Point, respectively, to the constructor and destructor methods associated with the cache objects. They are currently set to NULL, as stated earlier.
next
Pointers for the doubly linked list of cache descriptors.
flags
A set of flags that describes permanent properties of the cache. There is, for instance, a flag that specifies which of two possible alternatives (see the following section) has been chosen to store the object descriptors in memory.
dflags
A set of flags that describe dynamic properties of the cache. There is, for instance, a flag that indicates whether the kernel is allocating new slabs to the cache. In multiprocessor systems, they must be accessed by acquiring the cache spin lock.
gfpflags
A set of flags passed to the buddy system function when allocating page frames. The field is typically used to specify the _ _GFP_DMA and _ _GFP_HIGHMEM zone modifiers. For instance, if _ _GFP_DMA is set in gfpflags, all objects of the cache can be used for ISA DMA.
7.2.3 Slab Descriptor
Each slab of a cache has its own descriptor of type struct slab_s (equivalent to the type slab_t). Slab descriptors can be stored in two possible places:
Stored outside the slab, in one of the general caches not suitable for ISA DMA pointed to by cache_sizes.
Internal slab descriptor
Stored inside the slab, at the beginning of the first page frame assigned to the slab.
The slab allocator chooses the second solution when the size of the objects is smaller than 512 or when internal fragmentation leaves enough space for the slab—and object descriptors (as described later)—inside the slab.
The most significant fields of a slab descriptor are:
inuse
Number of objects in the slab that are currently allocated.
s_mem
Points to the first object (either allocated or free) inside the slab.
free
Points to the first free object (if any) in the slab.
list
Pointers for one of the three doubly linked lists of slab descriptors (either the slabs_full, slabs_partial, or slabs_free list in the cache descriptor).
Figure 7-4 illustrates the major relationships between cache and slab descriptors. Full slabs, partially full slabs, and free slabs are linked in different lists.
Figure 7-4. Relationship between cache and slab descriptors
7.2.4 General and Specific Caches
Caches are divided into two types: general and specific. General caches are used only by the slab allocator for its own purposes, while specific caches are used by the remaining parts of the kernel.
The general caches are:
· A first cache contains the cache descriptors of the remaining caches used by the kernel. The cache_cache variable contains its descriptor.
· Twenty-six additional caches contain geometrically distributed memory areas. The table, called cache_sizes (whose elements are of type cache_sizes_t), points to the 26 cache descriptors associated with memory areas of size 32, 64, 128, 256, 512, 1,024, 2,048, 4,096, 8,192, 16,384, 32,768, 65,536, and 131,072 bytes, respectively. For each size, there are two caches: one suitable for ISA DMA allocations and the other for normal allocations. The table cache_sizes is used to efficiently derive the cache address corresponding to a given size.
The kmem_cache_init( ) and kmem_cache_sizes_init( ) functions are invoked during system initialization to set up the general caches.
Specific caches are created by the kmem_cache_create( ) function. Depending on the parameters, the function first determines the best way to handle the new cache (for instance, whether to include the slab descriptor inside or outside of the slab). It then creates a new cache descriptor for the new cache and inserts the descriptor in the cache_cache general cache.
It is also possible to destroy a cache by invoking kmem_cache_destroy( ). This function is mostly useful to modules that create their own caches when loaded and destroy them when unloaded. To avoid wasting memory space, the kernel must destroy all slabs before destroying the cache itself. The kmem_cache_shrink( ) function destroys all the slabs in a cache by invoking kmem_slab_destroy( ) iteratively (see the later section Section 7.2.7). The growing field of the cache descriptor is used to prevent kmem_cache_shrink( ) from shrinking a cache while another kernel control path attempts to allocate a new slab for it.
The names of all general and specific caches can be obtained at runtime by reading /proc/slabinfo; this file also specifies the number of free objects and the number of allocated objects in each cache.
7.2.5 Interfacing the Slab Allocator with the Buddy System
When the slab allocator creates new slabs, it relies on the buddy system algorithm to obtain a group of free contiguous page frames. For this purpose, it invokes the kmem_getpages( ) function:
void * kmem_getpages(kmem_cache_t *cachep, unsigned long flags) { void *addr;
flags |= cachep->gfpflags;
addr = (void*) _ _get_free_pages(flags, cachep->gfporder); return addr; }
The parameters have the following meaning:
cachep
Points to the cache descriptor of the cache that needs additional page frames (the number of required page frames is determined by the order in the cachep->gfporder field)
flags
Specifies how the page frame is requested (see Section 7.1.5 earlier in this chapter). This set of flags is combined with the specific cache allocation flags stored in the gfpflags of the cache descriptor.
In the reverse operation, page frames assigned to a slab allocator can be released (see Section 7.2.7 later in this chapter) by invoking the kmem_freepages( ) function:
void kmem_freepages(kmem_cache_t *cachep, void *addr) { unsigned long i = (1<<cachep->gfporder); struct page *page = & mem_map[_ _pa(addr) >> PAGE_SHIFT]; while (i--) { PageClearSlab(page); page++; } free_pages((unsigned long) addr, cachep->gfporder); }
The function releases the page frames, starting from the one having the linear address addr, that had been allocated to the slab of the cache identified by cachep.
7.2.6 Allocating a Slab to a Cache
A newly created cache does not contain slab and therefore does not contain any free objects. New slabs are assigned to a cache only when both of the following are true:
· A request has been issued to allocate a new object.
· The cache does not include free object.
Under these circumstances, the slab allocator assigns a new slab to the cache by invoking kmem_cache_grow( ). This function calls kmem_ getpages( ) to obtain a group of page frames from the buddy system; it then calls kmem_cache_slabmgmt( ) to get a new slab descriptor, either in the first page frame of the slab or in the general cache of order 0 pointed to by cache_sizes. Next, it calls kmem_cache_init_objs( ), which applies the constructor method (if defined) to all the objects contained in the new slab.
Then, kmem_cache_ grow( ) scans all page descriptors of the page frames assigned to the new slab, and loads the next and prev subfields of the list fields in the page descriptors with the addresses of, respectively, the cache descriptor and the slab descriptor. This works correctly because the list field is used by functions of the buddy system only when the page frame is free, while page frames handled by the slab allocator functions are not free as far as the buddy system is concerned. Therefore, the buddy system is not confused by this specialized use of the page frame descriptor. The function also sets the PG_slab flag of the page frames.
The function then adds the slab descriptor *slabp at the end of the fully free slab list of the cache descriptor *cachep:
list_add_tail(&slabp->list, &cachep->slabs_free);
7.2.7 Releasing a Slab from a Cache
As stated previously, the slab allocator never releases the page frames of an empty slab on its own. In fact, a slab is released only if both of the following conditions are true:
· The buddy system is unable to satisfy a new request for a group of page frames (a zone is low on memory).
· The slab is empty—all the objects included in it are unused.
When the kernel looks for additional free page frames, it calls try_to_free_pages( ); this function, in turn, may invoke kmem_cache_reap( ), which selects a cache that contains at least one empty slab. The function then removes the slab from the fully free slab list and destroys it by invoking kmem_slab_destroy( ):
void kmem_slab_destroy(kmem_cache_t *cachep, slab_t *slabp) { if (cachep->dtor) { int i; for (i = 0; i < cachep->num; i++) { void* objp = & slabp->s_mem[cachep->objsize*i]; (cachep->dtor)(objp, cachep, 0); } } kmem_freepages(cachep, slabp->s_mem - slabp->colouroff); if (OFF_SLAB(cachep)) kmem_cache_free(cachep->slabp_cache, slabp);}
The function checks whether the cache has a destructor method for its objects (the dtor field is not NULL), in which case it applies the destructor to all the objects in the slab; the objp local variable keeps track of the currently examined object. Next, it calls kmem_freepages( ), which returns all the contiguous page frames used by the slab to the buddy system. Finally, if the slab descriptor is stored outside of the slab (macro OFF_SLAB returns true, as explained later in this chapter), the function releases it from the cache of slab descriptors.
7.2.8 Object Descriptor
Each object has a descriptor of type kmem_bufctl_t. Object descriptors are stored in an array placed after the corresponding slab descriptor. Thus, like the slab descriptors themselves, the object descriptors of a slab can be stored in two possible ways that are illustrated in Figure 7-5.
Figure 7-5. Relationships between slab and object descriptors
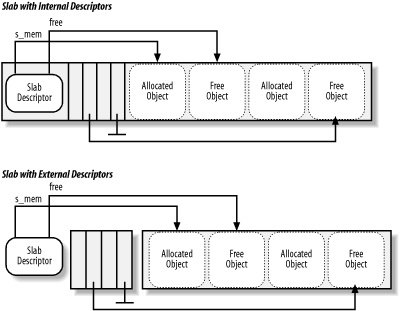
Stored outside the slab, in one of the general caches pointed to by cache_sizes. The size of the memory area, and thus the particular general cache used to store object descriptors, depends on the number of objects stored in the slab (num field of the cache descriptor).
Internal object descriptors
Stored inside the slab, right after the objects they describe.
The first object descriptor in the array describes the first object in the slab, and so on. An object descriptor is simply a unsigned integer, which is meaningful only when the object is free. It contains the index of the next free object in the slab, thus implementing a simple list of free objects inside the slab. The object descriptor of the last element in the free object list is marked by the conventional value BUFCTL_END (0xffffffff).
7.2.9 Aligning Objects in Memory
The objects managed by the slab allocator are aligned in memory—that is, they are stored in memory cells whose initial physical addresses are multiples of a given constant, which is usually a power of 2. This constant is called the alignment factor.
The largest alignment factor allowed by the slab allocator is 4,096—the page frame size. This means that objects can be aligned by referring to either their physical addresses or their linear addresses. In both cases, only the 12 least significant bits of the address may be altered by the alignment.
Usually, microcomputers access memory cells more quickly if their physical addresses are aligned with respect to the word size (that is, to the width of the internal memory bus of the computer). Thus, by default, the kmem_cache_create( ) function aligns objects according to the word size specified by the BYTES_PER_WORD macro. For Intel Pentium processors, the macro yields the value 4 because the word is 32 bits long.
When creating a new slab cache, it's possible to specify that the objects included in it be aligned in the first-level hardware cache. To achieve this, set the SLAB_HWCACHE_ALIGN cache descriptor flag. The kmem_cache_create( ) function handles the request as follows:
· If the object's size is greater than half of a cache line, it is aligned in RAM to a multiple of L1_CACHE_BYTES—that is, at the beginning of the line.
· Otherwise, the object size is rounded up to a factor of L1_CACHE_BYTES; this ensures that an object will never span across two cache lines.
Clearly, what the slab allocator is doing here is trading memory space for access time; it gets better cache performance by artificially increasing the object size, thus causing additional internal fragmentation.
7.2.10 Slab Coloring
We know from Chapter 2 that the same hardware cache line maps many different blocks of RAM. In this chapter, we have also seen that objects of the same size tend to be stored at the same offset within a cache. Objects that have the same offset within different slabs will, with a relatively high probability, end up mapped in the same cache line. The cache hardware might therefore waste memory cycles transferring two objects from the same cache line back and forth to different RAM locations, while other cache lines go underutilized. The slab allocator tries to reduce this unpleasant cache behavior by a policy called slab coloring: different arbitrary values called colors are assigned to the slabs.
Before examining slab coloring, we have to look at the layout of objects in the cache. Let's consider a cache whose objects are aligned in RAM. This means that the object address must be a multiple of a given positive value, say aln. Even taking the alignment constraint into account, there are many possible ways to place objects inside the slab. The choices depend on decisions made for the following variables:
num
Number of objects that can be stored in a slab (its value is in the num field of the cache descriptor).
osize
Object size, including the alignment bytes.
dsize
Slab descriptor size plus all object descriptors size. Its value is equal to 0 if the slab and object descriptors are stored outside of the slab.
free
Number of unused bytes (bytes not assigned to any object) inside the slab.
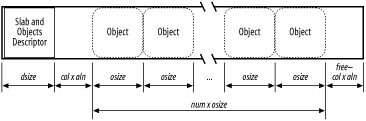
The total length in bytes of a slab can then be expressed as:
slab length = (num x osize) + dsize + free
free is always smaller than osize, since otherwise, it would be possible to place additional objects inside the slab. However, free could be greater than aln.
The slab allocator takes advantage of the free unused bytes to color the slab. The term "color" is used simply to subdivide the slabs and allow the memory allocator to spread objects out among different linear addresses. In this way, the kernel obtains the best possible performance from the microprocessor's hardware cache.
Slabs having different colors store the first object of the slab in different memory locations, while satisfying the alignment constraint. The number of available colors is (free/aln)+1. The first color is denoted as 0 and the last one (whose value is in the colour field of the cache descriptor) is denoted as free/aln.
If a slab is colored with color col, the offset of the first object (with respect to the slab initial address) is equal to col x aln+dsize bytes; this value is stored in the colour_off field of the cache descriptor. Figure 7-6 illustrates how the placement of objects inside the slab depends on the slab color. Coloring essentially leads to moving some of the free area of the slab from the end to the beginning.
Figure 7-6. Slab with color col and alignment aln
Coloring works only when free is large enough. Clearly, if no alignment is required for the objects or if the number of unused bytes inside the slab is smaller than the required alignment (free < aln), the only possible slab coloring is the one that has the color 0—the one that assigns a zero offset to the first object.
The various colors are distributed equally among slabs of a given object type by storing the current color in a field of the cache descriptor called colour_next. The kmem_cache_ grow( ) function assigns the color specified by colour_next to a new slab and then increments the value of this field. After reaching colour, it wraps around again to 0. In this way, each slab is created with a different color from the previous one, up to the maximum available colors.
7.2.11 Local Array of Objects in Multiprocessor Systems
The Linux 2.4 implementation of the slab allocator for multiprocessor systems differs from that of the original Solaris 2.4. To reduce spin lock contention among the processors, each cache of the slab allocator includes a small array of pointers to freed objects for each CPU in the system. Most of allocations and releases of slab objects affect the local array only; the slab data structures get involved only when the local array underflows or overflows.
The cache descriptor includes a cpudata array of pointers to cpucache_t data structures, one element for each CPU in the system. The cpucache_t data structure represents the descriptor of the local array of objects and includes the following fields:
avail
The number of available objects in the local array. It also acts as the index of the first free slot in the array.
limit
The size of the local array—that is, the maximum number of objects in the local array.
Notice that the local array descriptor does not include the address of the array itself; in fact, it is placed right after the descriptor. Of course, the array stores the pointers to the freed objects, not the object themselves, which are always placed inside the slabs of the cache. Nevertheless, the default size of the array depends on the size of the objects stored in the slab cache: the array size for small objects (up to 255 bytes) is 252 elements, the size for medium-size objects (between 256 and 1,023 bytes) is 124 elements, and the size for large objects (greater than 1,023 bytes) is 60 elements. Anyway, the system administrator can tune the size of the arrays for each cache by writing into the /proc/slabinfo file.
7.2.12 Allocating an Object in a Cache
New objects may be obtained by invoking the kmem_cache_alloc( ) function. The parameter cachep points to the cache descriptor from which the new free object must be obtained, while the parameter flag represents the flags to be passed to the buddy system allocator functions, should all slabs of the cache be full.
The function differs for uniprocessor systems and multiprocessor ones because in the latter case, it must also cope with the local array of freed objects. Let's discuss these two cases separately.
7.2.12.1 The uniprocessor case
kmem_cache_alloc( ) first disables the local interrupts; it then looks for a slab that includes a free object:
void * objp;slab_t * slabp;struct list_head * entry;local_irq_save(save_flags);entry = cachep->slabs_partial.next;if (entry == & cachep->slabs_partial) { entry = cachep->slabs_free.next; if (entry == & cachep->slabs_free) goto alloc_new_slab; list_del(entry); list_add(entry, & cachep->slab_partials);} slabp = list_entry(entry, slab_t, list);
The function looks into the slabs_partial doubly linked list, which links the descriptors of the slab that has at least one free object. If the list is empty (the list head points to itself), the function moves the first slab descriptor in the slabs_free list into slabs_partial. If even slabs_free is empty, the function allocates a new slab to the cache by invoking kmem_cache_grow( ), and then the whole procedure is repeated.
After obtaining a slab with a free object, the function increments the counter containing the number of objects currently allocated in the slab:
slabp->inuse++;
It then loads the objp local variable with the address of the first free object inside the slab:
objp = & slabp->s_mem[slabp->free * cachep->objsize];
The kmem_cache_alloc( ) function then updates the slabp->free field of the slab descriptor to point to the next free object:
slabp->free = ((kmem_bufctl_*)(slabp+1))[slabp->free]; if (slabp->free == BUFCTL_END) { list_del(&slabp->list); list_add(&slabp->list, &cachep->slabs_full);}
Recall that the object descriptor of a free object stores either the index of another free object in the slab, or it stores BUFCTL_END if the free object is the last one. The array of object descriptors is placed right after the slab descriptor, so its address is computed as (slabp+1).
The function terminates by re-enabling the local interrupts and returning the address of the new object:
local_irq_restore(save_flags);
return objp;
7.2.12.2 The multiprocessor case
kmem_cache_alloc( ) first disables the local interrupts; it then looks for a free object in the cache's local array associated with the running CPU:
void * objp;cpucache_t * cc;local_irq_save(save_flags);cc = cachep->cpudata[smp_processor_id( )];if (cc->avail) objp = ((void *)(cc+1))[--cc->avail];else { objp = kmem_cache_alloc_batch(cachep, flags); if (!objp) goto alloc_new_slab;}
local_irq_restore(save_flags);
return objp;
The cc local variable contains the address of the local array descriptor; thus, (cc+1) yields the address of the first local array element. If the avail field of the local array descriptor is positive, the function loads the address of the corresponding object into the objp local variable and decrements the counter. Otherwise, it invokes kmem_cache_alloc_batch( ) to repopulate the local array.
The kmem_cache_alloc_batch( ) function gets the cache spin lock and then allocates a predefined number of objects from the cache and inserts them into the local array:
count = cachep->batchcount;cc = cachep->cpudata[smp_processor_id( )];spin_lock(&cachep->spinlock);while (count--) { entry = cachep->slabs_partial.next; if (entry == &cachep->slabs_partial) { entry = cachep->slabs_free.next; if (entry == slabs_free) break; list_del(entry); list_add(entry, &cachep->slabs_partial); } slabp = list_entry(entry, slab_t, list); slabp->inuse++; objp = & slabp->s_mem[slabp->free * cachep->objsize]; slabp->free = ((kmem_bufctl_*)(((slab_t *)slabp)+1))[slabp->free]; if (slabp->free == BUFCTL_END) { list_del(&slabp->list); list_add(&slabp->list, &cachep->slabs_full); } ((void *)(cc+1))[cc->avail++] = objp;} spin_unlock(&cachep->spinlock);if (cc->avail) return ((void *)(cc+1))[--cc->avail];return NULL;
The number of pre-allocated objects is stored in the batchcount field of the cache descriptor; by default, it is half of the local array size, but the system administrator can modify it by writing into the /proc/slabinfo file. The code that gets the objects from the slabs is identical to that of the uniprocessor case, so we won't discuss it further.
The kmem_cache_alloc_batch( ) function returns NULL if the cache does not have free objects. In this case, kmem_cache_alloc( ) invokes kmem_cache_grow( ) and then repeats the whole procedure, (as in the uniprocessor case).
7.2.13 Releasing an Object from a Cache
The kmem_cache_free( ) function releases an object previously obtained by the slab allocator. Its parameters are cachep (the address of the cache descriptor) and objp (the address of the object to be released). As with kmem_cache_alloc( ), we discuss the uniprocessor case separately from the multiprocessor case.
7.2.13.1 The uniprocessor case
The function starts by disabling the local interrupts and then determines the address of the descriptor of the slab containing the object. It uses the list.prev subfield of the descriptor of the page frame storing the object:
slab_t * slabp;unsigned int objnr;local_irq_save(save_flags);slabp = (slab_t *) mem_map[_ _pa(objp) >> PAGE_SHIFT].list.prev;
Then the function computes the index of the object inside its slab, derives the address of its object descriptor, and adds the object to the head of the slab's list of free objects:
objnr = (objp - slabp->s_mem) / cachep->objsize;((kmem_bufctl_t *)(slabp+1))[objnr] = slabp->free;slabp->free = objnr;
Finally, the function checks whether the slab has to be moved to another list:
if (--slabp->inuse == 0) { /* slab is now fully free */ list_del(&slabp->list); list_add(&slabp->list, &cachep->slabs_free);} else if (slabp->inuse+1 == cachep->num) { /* slab was full */ list_del(&slabp->list); list_add(&slabp->list, &cachep->slabs_partial);}local_irq_restore(save_flags);return;
7.2.13.2 The multiprocessor case
The function starts by disabling the local interrupts; then it checks whether there is a free slot in the local array of object pointers:
cpucache_t * cc;local_irq_save(save_flags);cc = cachep->cpudata[smp_processor_id( )];if (cc->avail == cc->limit) { cc->avail -= cachep->batchcount; free_block(cachep, &((void *)(cc+1))[cc->avail], cachep->batchcount);} ((void *)(cc+1))[cc->avail++] = objp;local_irq_restore(save_flags);
return;
If there is at least one free slot in the local array, the function just sets it to the address of the object being freed. Otherwise, the function invokes free_block( ) to release a bunch of cachep->batchcount objects to the slab allocator cache.
The free_block(cachep,objpp,len) function acquires the cache spin lock and then releases len objects starting from the local array entry at address objpp:
spin_lock(&cachep->spinlock);for ( ; len > 0; len--, objpp++) { slab_t * slabp = (slab_t *) mem_map[_ _pa(*objpp) >> PAGE_SHIFT].list.prev; unsigned int objnr = (*objpp - slabp->s_mem) / cachep->objsize; ((kmem_bufctl_t *)(slabp+1))[objnr] = slabp->free; slabp->free = objnr; if (--slabp->inuse == 0) { /* slab is now fully free */ list_del(&slabp->list); list_add(&slabp->list, &cachep->slabs_free); } else if (slabp->inuse+1 == cachep->num) { /* slab was full */ list_del(&slabp->list); list_add(&slabp->list, &cachep->slabs_partial); }} spin_unlock(&cachep->spinlock);
The code that releases the objects to the slabs is identical to that of the uniprocessor case, so we don't discuss it further.
7.2.14 General Purpose Objects
As stated earlier in Section 7.1.7, infrequent requests for memory areas are handled through a group of general caches whose objects have geometrically distributed sizes ranging from a minimum of 32 to a maximum of 131,072 bytes.
Objects of this type are obtained by invoking the kmalloc( ) function:
void * kmalloc(size_t size, int flags) { cache_sizes_t *csizep = cache_sizes; kmem_cache_t * cachep; for (; csizep->cs_size; csizep++) { if (size > csizep->cs_size) continue; if (flags & _ _GFP_DMA) cachep = csizep->cs_dmacahep; else cachep = csizep->cs_cachep; return _ _kmem_cache_alloc(cachep, flags); } return NULL; }
The function uses the cache_sizes table to locate the nearest power-of-2 size to the requested size. It then calls kmem_cache_alloc( ) to allocate the object, passing to it either the cache descriptor for the page frames usable for ISA DMA or the cache descriptor for the "normal" page frames, depending on whether the caller specified the _ _GFP_DMA flag.[3]
[3] Actually, for more efficiency, the code of kmem_cache_alloc( ) is copied inside the body of kmalloc( ). The _ _kmem_cache alloc( ) function, which implements kmem_cache_alloc( ), is declared inline.
Objects obtained by invoking kmalloc( ) can be released by calling kfree( ):
void kfree(const void *objp) { kmem_cache_t * c; unsigned long flags; if (!objp) return; local_irq_save(flags); c = (kmem_cache_t *) mem_map[_ _pa(objp) >> PAGE_SHIFT].list.next; _ _kmem_cache_free(c, (void *) objp); local_irq_restore(flags); }
The proper cache descriptor is identified by reading the list.next subfield of the descriptor of the first page frame containing the memory area. The memory area is released by invoking kmem_cache_free( ).[4]
[4] As for kmalloc( ), the code of kmem_cache_free( ) is copied inside kfree( ). _ _kmem_cache_free( ), which implements kmem_cache_free( ), is declared inline.