8.4 Page Fault Exception Handler
As stated previously, the Linux Page Fault exception handler must distinguish exceptions caused by programming errors from those caused by a reference to a page that legitimately belongs to the process address space but simply hasn't been allocated yet.
The memory region descriptors allow the exception handler to perform its job quite efficiently. The do_page_fault( ) function, which is the Page Fault interrupt service routine for the 80 x 86 architecture, compares the linear address that caused the Page Fault against the memory regions of the current process; it can thus determine the proper way to handle the exception according to the scheme that is illustrated in Figure 8-4.
Figure 8-4. Overall scheme for the Page Fault handler
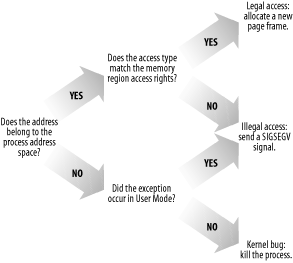
In practice, things are a lot more complex because the Page Fault handler must recognize several particular subcases that fit awkwardly into the overall scheme, and it must distinguish several kinds of legal access. A detailed flow diagram of the handler is illustrated in Figure 8-5.
Figure 8-5. The flow diagram of the Page Fault handler
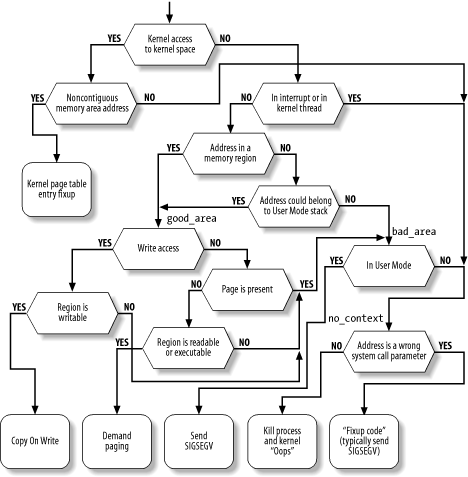
The identifiers vmalloc_fault, good_area, bad_area, and no_context are labels appearing in do_page_fault( ) that should help you to relate the blocks of the flow diagram to specific lines of code.
The do_ page_fault( ) function accepts the following input parameters:
· The regs address of a pt_regs structure containing the values of the microprocessor registers when the exception occurred.
· A 3-bit error_code, which is pushed on the stack by the control unit when the exception occurred (see Section 4.2.4). The bits have the following meanings.
o If bit 0 is clear, the exception was caused by an access to a page that is not present (the Present flag in the Page Table entry is clear); otherwise, if bit 0 is set, the exception was caused by an invalid access right.
o If bit 1 is clear, the exception was caused by a read or execute access; if set, the exception was caused by a write access.
o If bit 2 is clear, the exception occurred while the processor was in Kernel Mode; otherwise, it occurred in User Mode.
The first operation of do_ page_fault( ) consists of reading the linear address that caused the Page Fault. When the exception occurs, the CPU control unit stores that value in the cr2 control register:
asm("movl %%cr2,%0":"=r" (address)); if (regs->eflags & 0x00000200) local_irq_enable();tsk = current;
The linear address is saved in the address local variable. The function also ensures that local interrupts are enabled if they were enabled before the fault and saves the pointers to the process descriptor of current in the tsk local variable.
As shown at the top of Figure 8-5, do_ page_fault( ) checks whether the faulty linear address belongs to the fourth gigabyte and the exception was caused by the kernel trying to access a nonexisting page frame:
if (address >= TASK_SIZE && !(error_code & 0x101)) goto vmalloc_fault;
The code at label vmalloc_fault takes care of faults that were likely caused by accessing a noncontiguous memory area in Kernel Mode; we describe this case in the later section Section 8.4.5.
Next, the handler checks whether the exception occurred while handling an interrupt or executing a kernel thread (remember that the mm field of the process descriptor is always NULL for kernel threads):
info.i_code = SEGV_MAPERR;if (in_interrupt( ) || !tsk->mm) goto no_context;
In both cases, do_ page_fault( ) does not try to compare the linear address with the memory regions of current, since it would not make any sense: interrupt handlers and kernel threads never use linear addresses below TASK_SIZE, and thus never rely on memory regions. (See the next section for information on the info local variable and a description of the code at the no_context label.)
Let's suppose that the Page Fault did not occur in an interrupt handler or in a kernel thread. Then the function must inspect the memory regions owned by the process to determine whether the faulty linear address is included in the process address space:
down_read(&tsk->mm->mmap_sem);vma = find_vma(tsk->mm, address); if (!vma) goto bad_area; if (vma->vm_start <= address) goto good_area;
If vma is NULL, there is no memory region ending after address, and thus the faulty address is certainly bad. On the other hand, the first memory region ending after address might not include address; if it does, the function jumps to the code at label good_area.
If none of the two "if" conditions are satisfied, the function has determined that address is not included in any memory region; however, it must perform an additional check, since the faulty address may have been caused by a push or pusha instruction on the User Mode stack of the process.
Let's make a short digression to explain how stacks are mapped into memory regions. Each region that contains a stack expands toward lower addresses; its VM_GROWSDOWN flag is set, so the value of its vm_end field remains fixed while the value of its vm_start field may be decreased. The region boundaries include, but do not delimit precisely, the current size of the User Mode stack. The reasons for the fuzz factor are:
· The region size is a multiple of 4 KB (it must include complete pages) while the stack size is arbitrary.
· Page frames assigned to a region are never released until the region is deleted; in particular, the value of the vm_start field of a region that includes a stack can only decrease; it can never increase. Even if the process executes a series of pop instructions, the region size remains unchanged.
It should now be clear how a process that has filled up the last page frame allocated to its stack may cause a Page Fault exception: the push refers to an address outside of the region (and to a nonexistent page frame). Notice that this kind of exception is not caused by a programming error; thus it must be handled separately by the Page Fault handler.
We now return to the description of do_ page_fault( ), which checks for the case described previously:
if (!(vma->vm_flags & VM_GROWSDOWN)) goto bad_area; if (error_code & 4 /* User Mode */ && address + 32 < regs->esp) goto bad_area; if (expand_stack(vma, address)) goto bad_area; goto good_area;
If the VM_GROWSDOWN flag of the region is set and the exception occurred in User Mode, the function checks whether address is smaller than the regs->esp stack pointer (it should be only a little smaller). Since a few stack-related assembly language instructions (like pusha) perform a decrement of the esp register only after the memory access, a 32-byte tolerance interval is granted to the process. If the address is high enough (within the tolerance granted), the code invokes the expand_stack( ) function to check whether the process is allowed to extend both its stack and its address space; if everything is OK, it sets the vm_start field of vma to address and returns 0; otherwise, it returns 1.
Note that the preceding code skips the tolerance check whenever the VM_GROWSDOWN flag of the region is set and the exception did not occur in User Mode. These conditions mean that the kernel is addressing the User Mode stack and that the code should always run expand_stack( ).
8.4.1 Handling a Faulty Address Outside the Address Space
If address does not belong to the process address space, do_page_fault( ) proceeds to execute the statements at the label bad_area. If the error occurred in User Mode, it sends a SIGSEGV signal to current (see Section 10.2) and terminates:
bad_area: up_read(&tsk->mm->mmap_sem);if (error_code & 4) { /* User Mode */ tsk->thread.cr2 = address; tsk->thread.error_code = error_code; tsk->thread.trap_no = 14; info.si_signo = SIGSEGV; info.si_errno = 0; info.si_addr = (void *) address; force_sig_info(SIGSEGV, &info, tsk); return; }
The force_sig_info( ) function makes sure that the process does not ignore or block the SIGSEGV signal, and sends the signal to the User Mode process while passing some additional information in the info local variable (see Section 10.2.2). The info.si_code field is already set to SEGV_MAPERR (if the exception was due to a nonexisting page frame) or to SEGV_ACCERR (if the exception was due to an invalid access to an existing page frame).
If the exception occurred in Kernel Mode (bit 2 of error_code is clear), there are still two alternatives:
· The exception occurred while using some linear address that has been passed to the kernel as parameter of a system call.
· The exception is due to a real kernel bug.
The function distinguishes these two alternatives as follows:
no_context: if ((fixup = search_exception_table(regs->eip)) != 0) { regs->eip = fixup; return; }
In the first case, it jumps to a "fixup code," which typically sends a SIGSEGV signal to current or terminates a system call handler with a proper error code (see Section 9.2.6).
In the second case, the function prints a complete dump of the CPU registers, the Kernel Mode stack on the console, and on a system message buffer, and then kills the current process by invoking the do_exit( ) function (see Chapter 20). This is the so-called "Kernel oops" error, named after the message displayed. The dumped values can be used by kernel hackers to reconstruct the conditions that triggered the bug, and thus find and correct it.
8.4.2 Handling a Faulty Address Inside the Address Space
If address belongs to the process address space, do_ page_fault( ) proceeds to the statement labeled good_area:
good_area: info.si_code = SEGV_ACCERR;write = 0;
if (error_code & 2) { /* write access */ if (!(vma->vm_flags & VM_WRITE))
goto bad_area;
write++;
} else /* read access */
if ((error_code & 1) ||
!(vma->vm_flags & (VM_READ | VM_EXEC)))
goto bad_area;
If the exception was caused by a write access, the function checks whether the memory region is writable. If not, it jumps to the bad_area code; if so, it sets the write local variable to 1.
If the exception was caused by a read or execute access, the function checks whether the page is already present in RAM. In this case, the exception occurred because the process tried to access a privileged page frame (one whose User/Supervisor flag is clear) in User Mode, so the function jumps to the bad_area code.[6] If the page is not present, the function also checks whether the memory region is readable or executable.
[6] However, this case should never happen, since the kernel does not assign privileged page frames to the processes.
If the memory region access rights match the access type that caused the exception, the handle_mm_fault( ) function is invoked to allocate a new page frame:
survive:
ret = handle_mm_fault(tsk->mm, vma, address, write);
if (ret == 1 || ret == 2) {if (ret == 1) tsk->min_flt++; else tsk->maj_flt++;
up_read(&tsk->mm->mmap_sem);
return;
}
The handle_mm_fault( ) function returns 1 or 2 if it succeeded in allocating a new page frame for the process. The value 1 indicates that the Page Fault has been handled without blocking the current process; this kind of Page Fault is called minor fault. The value 2 indicates that the Page Fault forced the current process to sleep (most likely because time was spent while filling the page frame assigned to the process with data read from disk); a Page Fault that blocks the current process is called a major fault. The function can also returns -1 (for not enough memory) or 0 (for any other error).
If handle_mm_fault( ) returns the value 0, a SIGBUS signal is sent to the process:
if (!ret) {up_read(&tsk->mm->mmap_sem);
tsk->thread.cr2 = address;
tsk->thread.error_code = error_code;
tsk->thread.trap_no = 14;
info.si_signo = SIGBUS;
info.si_errno = 0;
info.si_code = BUS_ADRERR;
info.si_addr = (void *) address;
force_sig_info(SIGBUS, &info, tsk);
if (!(error_code & 4)) /* Kernel Mode */
goto no_context;
}
If handle_mm_fault( ) cannot allocate the new page frame, the kernel usually kills the current process. However, if current is the init process, it is just put at the end of the run queue and the scheduler is invoked; once init resumes its execution, handle_mm_fault( ) is executed again:
if (ret == -1) {up_read(&tsk->mm->mmap_sem);
if (tsk->pid != 1) {if (error_code & 4) /* User Mode */
do_exit(SIGKILL);
goto no_context;
}
tsk->policy |= SCHED_YIELD;
schedule();
down_read(&tsk->mm->mmap_sem);
goto survive;
}
The handle_mm_fault( ) function acts on four parameters:
mm
A pointer to the memory descriptor of the process that was running on the CPU when the exception occurred
vma
A pointer to the descriptor of the memory region, including the linear address that caused the exception
address
The linear address that caused the exception
write_access
Set to 1 if tsk attempted to write in address and to 0 if tsk attempted to read or execute it
The function starts by checking whether the Page Middle Directory and the Page Table used to map address exist. Even if address belongs to the process address space, the corresponding Page Tables might not have been allocated, so the task of allocating them precedes everything else:
spin_lock(&mm->page_table_lock);
pgd = pgd_offset(mm, address);
pmd = pmd_alloc(mm, pgd, address);
if (pmd) {pte = pte_alloc(mm, pmd, address);
if (pte)
return handle_pte_fault(mm, vma, address, write_access, pte);
}
spin_unlock(&mm->page_table_lock);
return -1;
The pgd local variable contains the Page Global Directory entry that refers to address; pmd_alloc( ) is invoked to allocate, if needed, a new Page Middle Directory.[7] pte_alloc( ) is then invoked to allocate, if needed, a new Page Table. If both operations are successful, the pte local variable points to the Page Table entry that refers to address.
[7] On 80 x 86 microprocessors, this kind of allocation never occurs since the Page Middle Directories are either included in the Page Global Directory (PAE not enabled) or allocated together with the Page Global Directory (PAE enabled).
The handle_pte_fault( ) function is then invoked to inspect the Page Table entry corresponding to address and to determine how to allocate a new page frame for the process:
· If the accessed page is not present—that is, if it is not already stored in any page frame—the kernel allocates a new page frame and initializes it properly; this technique is called demand paging.
· If the accessed page is present but is marked read only—i.e., if it is already stored in a page frame—the kernel allocates a new page frame and initializes its contents by copying the old page frame data; this technique is called Copy On Write.
8.4.3 Demand Paging
The term demand paging denotes a dynamic memory allocation technique that consists of deferring page frame allocation until the last possible moment—until the process attempts to address a page that is not present in RAM, thus causing a Page Fault exception.
The motivation behind demand paging is that processes do not address all the addresses included in their address space right from the start; in fact, some of these addresses may never be used by the process. Moreover, the program locality principle (see Section 2.4.7) ensures that, at each stage of program execution, only a small subset of the process pages are really referenced, and therefore the page frames containing the temporarily useless pages can be used by other processes. Demand paging is thus preferable to global allocation (assigning all page frames to the process right from the start and leaving them in memory until program termination) since it increases the average number of free page frames in the system and therefore allows better use of the available free memory. From another viewpoint, it allows the system as a whole to get a better throughput with the same amount of RAM.
The price to pay for all these good things is system overhead: each Page Fault exception induced by demand paging must be handled by the kernel, thus wasting CPU cycles. Fortunately, the locality principle ensures that once a process starts working with a group of pages, it sticks with them without addressing other pages for quite a while. Thus, Page Fault exceptions may be considered rare events.
An addressed page may not be present in main memory for the following reasons:
· The page was never accessed by the process. The kernel can recognize this case since the Page Table entry is filled with zeros—i.e., the pte_none macro returns the value 1.
· The page was already accessed by the process, but its content is temporarily saved on disk. The kernel can recognize this case since the Page Table entry is not filled with zeros (however, the Present flag is cleared since the page is not present in RAM).
The handle_ pte_fault( ) function distinguishes the two cases by inspecting the Page Table entry that refers to address:
entry = *pte;
if (!pte_present(entry)) { if (pte_none(entry))
return do_no_page(mm, vma, address, write_access, pte);
return do_swap_page(mm, vma, address, pte, entry, write_access);
}
We'll examine the case in which the page is saved on disk (using the do_swap_ page( ) function) in Section 16.6.
In the other situation, when the page was never accessed, the do_no_page( ) function is invoked. There are two ways to load the missing page, depending on whether the page is mapped to a disk file. The function determines this by checking the nopage method of the vma memory region object, which points to the function that loads the missing page from disk into RAM if the page is mapped to a file. Therefore, the possibilities are:
· The vma->vm_ops->nopage field is not NULL. In this case, the memory region maps a disk file and the field points to the function that loads the page. This case is covered in Section 15.2.4 and in Section 19.3.5.
· Either the vm_ops field or the vma->vm_ops->nopage field is NULL. In this case, the memory region does not map a file on disk—i.e., it is an anonymous mapping. Thus, do_no_ page( ) invokes the do_anonymous_page( ) function to get a new page frame:
· if (!vma->vm_ops || !vma->vm_ops->nopage) return do_anonymous_page(mm, vma, page_table, write_access, address);
The do_anonymous_page( ) function handles write and read requests separately:
if (write_access) { spin_unlock(&mm->page_table_lock);
page = alloc_page(GFP_HIGHUSER);
addr = kmap_atomic(page, KM_USER0);
memset((void *)(addr), 0, PAGE_SIZE);
kunmap_atomic(addr, KM_USER0);
spin_lock(&mm->page_table_lock);
mm->rss++;
entry = pte_mkwrite(pte_mkdirty(mk_pte(page, vma->vm_page_prot)));
lru_cache_add(page);
mark_page_accessed(page);
set_pte(page_table, entry);
spin_unlock(&mm->page_table_lock);
return 1;
}
When handling a write access, the function invokes alloc_page( ) and fills the new page frame with zeros by using the memset macro. The function then increments the min_flt field of tsk to keep track of the number of minor Page Faults caused by the process. Next, the function increments the rss field of the memory descriptor to keep track of the number of page frames allocated to the process.[8] The Page Table entry is then set to the physical address of the page frame, which is marked as writable and dirty. The lru_cache_add( ) and mark_page_accessed( ) functions insert the new page frame in the swap-related data structures; we discuss them in Chapter 16.
[8] Linux records the number of minor and major Page Faults for each process. This information, together with several other statistics, may be used to tune the system.
Conversely, when handling a read access, the content of the page is irrelevant because the process is addressing it for the first time. It is safer to give a page filled with zeros to the process rather than an old page filled with information written by some other process. Linux goes one step further in the spirit of demand paging. There is no need to assign a new page frame filled with zeros to the process right away, since we might as well give it an existing page called zero page, thus deferring further page frame allocation. The zero page is allocated statically during kernel initialization in the empty_zero_page variable (an array of 1,024 long integers filled with zeros); it is stored in the fifth page frame (starting from physical address 0x00004000) and can be referenced by means of the ZERO_PAGE macro.
The Page Table entry is thus set with the physical address of the zero page:
entry = pte_wrprotect(mk_pte(ZERO_PAGE, vma->vm_page_prot));
set_pte(page_table, entry);
spin_unlock(&mm->page_table_lock);
return 1;
Since the page is marked as nonwritable, if the process attempts to write in it, the Copy On Write mechanism is activated. Only then does the process get a page of its own to write in. The mechanism is described in the next section.
8.4.4 Copy On Write
First-generation Unix systems implemented process creation in a rather clumsy way: when a fork( ) system call was issued, the kernel duplicated the whole parent address space in the literal sense of the word and assigned the copy to the child process. This activity was quite time consuming since it required:
· Allocating page frames for the Page Tables of the child process
· Allocating page frames for the pages of the child process
· Initializing the Page Tables of the child process
· Copying the pages of the parent process into the corresponding pages of the child process
This way of creating an address space involved many memory accesses, used up many CPU cycles, and completely spoiled the cache contents. Last but not least, it was often pointless because many child processes start their execution by loading a new program, thus discarding entirely the inherited address space (see Chapter 20).
Modern Unix kernels, including Linux, follow a more efficient approach called Copy On Write (COW). The idea is quite simple: instead of duplicating page frames, they are shared between the parent and the child process. However, as long as they are shared, they cannot be modified. Whenever the parent or the child process attempts to write into a shared page frame, an exception occurs. At this point, the kernel duplicates the page into a new page frame that it marks as writable. The original page frame remains write-protected: when the other process tries to write into it, the kernel checks whether the writing process is the only owner of the page frame; in such a case, it makes the page frame writable for the process.
The count field of the page descriptor is used to keep track of the number of processes that are sharing the corresponding page frame. Whenever a process releases a page frame or a Copy On Write is executed on it, its count field is decremented; the page frame is freed only when count becomes NULL.
Let's now describe how Linux implements COW. When handle_ pte_fault( ) determines that the Page Fault exception was caused by an access to a page present in memory, it executes the following instructions:
if (pte_present(entry)) { if (write_access) {if (!pte_write(entry))
return do_wp_page(mm, vma, address, pte, entry);
entry = pte_mkdirty(entry);
}
entry = pte_mkyoung(entry);
set_pte(pte, entry);
flush_tlb_page(vma, address);
spin_unlock(&mm->page_table_lock);
return 1;
}
The handle_pte_fault( ) function is architecture-independent: it considers any possible violation of the page access rights. However, in the 80 x 86 architecture, if the page is present then the access was for writing and the page frame is write-protected (see Section 8.4.2). Thus, the do_wp_page( ) function is always invoked.
The do_wp_page( ) function starts by deriving the page descriptor of the page frame referenced by the Page Table entry involved in the Page Fault exception. Next, the function determines whether the page must really be duplicated. If only one process owns the page, Copy On Write does not apply and the process should be free to write the page. Basically, the function reads the count field of the page descriptor: if it is equal to 1, COW must not be done. Actually, the check is slightly more complicated, since the count field is also incremented when the page is inserted into the swap cache (see Section 16.3). However, when COW is not to be done, the page frame is marked as writable so that it does not cause further Page Fault exceptions when writes are attempted:
set_pte(page_table, pte_mkyoung(pte_mkdirty(pte_mkwrite(pte))));
flush_tlb_page(vma, address);
spin_unlock(&mm->page_table_lock);
return 1; /* minor fault */
If the page is shared among several processes by means of the COW, the function copies the content of the old page frame (old_page) into the newly allocated one (new_page). To avoid race conditions, the usage counter of old_page is incremented before starting the copy operation:
old_page = pte_page(pte);
atomic_inc(&old_page->count);
spin_unlock(&mm->page_table_lock);
new_page = alloc_page(GFP_HIGHUSER);
vto = kmap_atomic(new_page, KM_USER0);
if (old_page == ZERO_PAGE) {memset((void *)vto, 0, PAGE_SIZE);
} else {vfrom = kmap_atomic(old_page, KM_USER1);
memcpy((void *)vto, (void *)vfrom, PAGE_SIZE);
kunmap_atomic(vfrom, KM_USER1);
}
kunmap_atomic(vto, KM_USER0);
If the old page is the zero page, the new frame is efficiently filled with zeros by using the memset macro. Otherwise, the page frame content is copied using the memcpy macro. Special handling for the zero page is not strictly required, but it improves the system performance because it preserves the microprocessor hardware cache by making fewer address references.
Since the allocation of a page frame can block the process, the function checks whether the Page Table entry has been modified since the beginning of the function (pte and *page_table do not have the same value). In this case, the new page frame is released, the usage counter of old_page is decrement (to undo the increment made previously), and the function terminates.
If everything looks OK, the physical address of the new page frame is finally written into the Page Table entry and the corresponding TLB register is invalidated:
set_pte(pte, pte_mkwrite(pte_mkdirty(mk_pte(new_page, vma->vm_page_prot))));
flush_tlb_page(vma, address);
lru_cache_add(new_page);
spin_unlock(&mm->page_table_lock);
The lru_cache_add( ) inserts the new page frame in the swap-related data structures; see Chapter 16 for its description.
Finally, do_wp_page( ) decrements the usage counter of old_page twice. The first decrement undoes the safety increment made before copying the page frame contents; the second decrement reflects the fact that the current process no longer owns the page frame.
8.4.5 Handling Noncontiguous Memory Area Accesses
We have seen in Section 7.3 that the kernel is quite lazy in updating the Page Table entries corresponding to noncontiguous memory areas. In fact, the vmalloc( ) and vfree( ) functions limit themselves to update the master kernel Page Tables (i.e., the Page Global Directory init_mm.pgd and its child Page Tables).
However, once the kernel initialization phase ends, the master kernel Page Tables are not directly used by any process or kernel thread. Thus, consider the first time that a process in Kernel Mode accesses a noncontiguous memory area. When translating the linear address into a physical address, the CPU's memory management unit encounters a null Page Table entry and raises a Page Fault. However, the handler recognizes this special case because the exception occurred in Kernel Mode and the faulty linear address is greater than TASK_SIZE. Thus, the handler checks the corresponding master kernel Page Table entry:
vmalloc_fault:asm("movl %%cr3,%0":"=r" (pgd));pgd = _ _pgd_offset(address) + (pgd_t *) _ _va(pgd);pgd_k = init_mm.pgd + _ _pgd_offset(address);if (!pgd_present(*pgd_k)) goto no_context;set_pgd(pgd, *pgd_k);pmd = pmd_offset(pgd, address);pmd_k = pmd_offset(pgd_k, address);if (!pmd_present(*pmd_k)) goto no_context;set_pmd(pmd, *pmd_k); pte_k = pte_offset(pmd_k, address);if (!pte_present(*pte_k)) goto no_context;return;
The pgd local variable is loaded with the Page Global Directory address of the current process, which is stored in the cr3 register,[9] while the pgd_k local variable is loaded with the master kernel Page Global Directory. If the entry corresponding to the faulty linear address is null, the function jumps to the code at the no_context label (see the earlier section Section 8.4.1). Otherwise, the entry is copied into the corresponding entry of the process Page Global Directory. Then the whole operation is repeated with the master Page Middle Directory entry and, subsequently, with the master Page Table entry.
[9] The kernel doesn't use current->mm->pgd to derive the address because this fault can occur at any instant, even during a process switch.