12.2 VFS Data Structures
Each VFS object is stored in a suitable data structure, which includes both the object attributes and a pointer to a table of object methods. The kernel may dynamically modify the methods of the object and, hence, it may install specialized behavior for the object. The following sections explain the VFS objects and their interrelationships in detail.
12.2.1 Superblock Objects
A superblock object consists of a super_block structure whose fields are described in Table 12-2.
Table 12-2. The fields of the superblock object |
||
|
Type |
Field |
Description |
|
struct list_head |
s_list |
Pointers for superblock list |
|
kdev_t |
s_dev |
Device identifier |
|
unsigned long |
s_blocksize |
Block size in bytes |
|
unsigned char |
s_blocksize_bits |
Block size in number of bits |
|
unsigned char |
s_dirt |
Modified (dirty) flag |
|
unsigned long long |
s_maxbytes |
Maximum size of the files |
|
struct file_system_type * |
s_type |
Filesystem type |
|
struct super_operations * |
s_op |
Superblock methods |
|
struct dquot_operations * |
dq_op |
Disk quota methods |
|
unsigned long |
s_flags |
Mount flags |
|
unsigned long |
s_magic |
Filesystem magic number |
|
struct dentry * |
s_root |
Dentry object of mount directory |
|
struct rw_semaphore |
s_umount |
Semaphore used for unmounting |
|
struct semaphore |
s_lock |
Superblock semaphore |
|
int |
s_count |
Reference counter |
|
atomic_t |
s_active |
Secondary reference counter |
|
struct list_head |
s_dirty |
List of modified inodes |
|
struct list_head |
s_locked_inodes |
List of inodes involved in I/O |
|
struct list_head |
s_files |
List of file objects assigned to the superblock |
|
struct block_device * |
s_bdev |
Pointer to the block device driver descriptor |
|
struct list_head |
s_instances |
Pointers for a list of superblock objects of a given filesystem type (see Section 12.3.2) |
|
struct quota_mount_options |
s_dquot |
Options for disk quota |
|
union |
u |
Specific filesystem information |
All superblock objects are linked in a circular doubly linked list. The first element of this list is represented by the super_blocks variable, while the s_list field of the superblock object stores the pointers to the adjacent elements in the list. The sb_lock spin lock protects the list against concurrent accesses in multiprocessor systems.
The last u union field includes superblock information that belongs to a specific filesystem; for instance, as we shall see later in Chapter 17, if the superblock object refers to an Ext2 filesystem, the field stores an ext2_sb_info structure, which includes the disk allocation bit masks and other data of no concern to the VFS common file model.
In general, data in the u field is duplicated in memory for reasons of efficiency. Any disk-based filesystem needs to access and update its allocation bitmaps in order to allocate or release disk blocks. The VFS allows these filesystems to act directly on the u union field of the superblock in memory without accessing the disk.
This approach leads to a new problem, however: the VFS superblock might end up no longer synchronized with the corresponding superblock on disk. It is thus necessary to introduce an s_dirt flag, which specifies whether the superblock is dirty—that is, whether the data on the disk must be updated. The lack of synchronization leads to the familiar problem of a corrupted filesystem when a site's power goes down without giving the user the chance to shut down a system cleanly. As we shall see in Section 14.2.4, Linux minimizes this problem by periodically copying all dirty superblocks to disk.
The methods associated with a superblock are called superblock operations. They are described by the super_operations structure whose address is included in the s_op field.
Each specific filesystem can define its own superblock operations. When the VFS needs to invoke one of them, say read_inode( ), it executes the following:
sb->s_op->read_inode(inode);
where sb stores the address of the superblock object involved. The read_inode field of the super_operations table contains the address of the suitable function, which is therefore directly invoked.
Let's briefly describe the superblock operations, which implement higher-level operations like deleting files or mounting disks. They are listed in the order they appear in the super_operations table:
Fills the fields of the inode object whose address is passed as the parameter from the data on disk; the i_ino field of the inode object identifies the specific filesystem inode on the disk to be read.
read_inode2(inode, p)
Similar to the previous one, but the inode is identified by a 64-bit number pointed by p. This method should disappear as soon as the whole VFS architecture moves to 64-bit quantities; for now, it is used by the ReiserFS filesystem only.
dirty_inode(inode)
Invoked when the inode is marked as modified (dirty). Used by filesystems like ReiserFS and Ext3 to update the filesystem journal on disk.
write_inode(inode, flag)
Updates a filesystem inode with the contents of the inode object passed as the parameter; the i_ino field of the inode object identifies the filesystem inode on disk that is concerned. The flag parameter indicates whether the I/O operation should be synchronous.
put_inode(inode)
Releases the inode object whose address is passed as the parameter. As usual, releasing an object does not necessarily mean freeing memory, since other processes may still use that object.
delete_inode(inode)
Deletes the data blocks containing the file, the disk inode, and the VFS inode.
put_super(super)
Releases the superblock object whose address is passed as the parameter (because the corresponding filesystem is unmounted).
write_super(super)
Updates a filesystem superblock with the contents of the object indicated.
write_super_lockfs(super)
Blocks changes to the filesystem and updates the superblock with the contents of the object indicated. The method should be implemented by journaling filesystems, and should be invoked by the Logical Volume Manager (LVM) driver. It is currently not in use.
unlockfs(super)
Undoes the block of filesystem updates achieved by the write_super_lockfs( ) superblock method.
statfs(super, buf)
Returns statistics on a filesystem by filling the buf buffer.
remount_fs(super, flags, data)
Remounts the filesystem with new options (invoked when a mount option must be changed).
clear_inode(inode)
Like put_inode, but also releases all pages that contain data concerning the file that corresponds to the indicated inode.
umount_begin(super)
Interrupts a mount operation because the corresponding unmount operation has been started (used only by network filesystems).
fh_to_dentry(super, filehandle, len, filehandletype. parent)
Used by the Network File System (NFS) kernel thread knfsd to return the dentry object corresponding to a given file handle. (A file handle is an identifier of a NFS file.)
dentry_to_fh(dentry, filehandle, lenp, need_parent)
Used by the NFS kernel thread knfsd to derive the file handle corresponding to a given dentry object.
show_options(seq_file, vfsmount)
Used to display the filesystem-specific options
The preceding methods are available to all possible filesystem types. However, only a subset of them applies to each specific filesystem; the fields corresponding to unimplemented methods are set to NULL. Notice that no read_super method to read a superblock is defined—how could the kernel invoke a method of an object yet to be read from disk? We'll find the read_super method in another object describing the filesystem type (see the later section Section 12.4).
12.2.2 Inode Objects
All information needed by the filesystem to handle a file is included in a data structure called an inode. A filename is a casually assigned label that can be changed, but the inode is unique to the file and remains the same as long as the file exists. An inode object in memory consists of an inode structure whose fields are described in Table 12-3.
Table 12-3. The fields of the inode object |
||
|
Type |
Field |
Description |
|
struct list_head |
i_hash |
Pointers for the hash list |
|
struct list_head |
i_list |
Pointers for the inode list |
|
struct list_head |
i_dentry |
Pointers for the dentry list |
|
struct list_head |
i_dirty_buffers |
Pointers for the modified buffers list |
|
struct list_head |
i_dirty_data_buffers |
Pointers for the modified data buffers list |
|
unsigned long |
i_ino |
inode number |
|
unsigned int |
i_count |
Usage counter |
|
kdev_t |
i_dev |
Device identifier |
|
umode_t |
i_mode |
File type and access rights |
|
nlink_t |
i_nlink |
Number of hard links |
|
uid_t |
i_uid |
Owner identifier |
|
gid_t |
i_gid |
Group identifier |
|
kdev_t |
i_rdev |
Real device identifier |
|
off_t |
i_size |
File length in bytes |
|
time_t |
i_atime |
Time of last file access |
|
time_t |
i_mtime |
Time of last file write |
|
time_t |
i_ctime |
Time of last inode change |
|
unsigned int |
i_blkbits |
Block size in number of bits |
|
unsigned long |
i_blksize |
Block size in bytes |
|
unsigned long |
i_blocks |
Number of blocks of the file |
|
unsigned long |
i_version |
Version number, automatically incremented after each use |
|
struct semaphore |
i_sem |
inode semaphore |
|
struct semaphore |
i_zombie |
Secondary inode semaphore used when removing or renaming the inode |
|
struct inode_operations * |
i_op |
inode operations |
|
struct file_operations * |
i_fop |
Default file operations |
|
struct super_block * |
i_sb |
Pointer to superblock object |
|
wait_queue_head_t |
i_wait |
inode wait queue |
|
struct file_lock * |
i_flock |
Pointer to file lock list |
|
struct address_space * |
i_mapping |
Pointer to an address_space object (see Chapter 14) |
|
struct address_space |
i_data |
address_space object for block device file |
|
struct dquot ** |
i_dquot |
inode disk quotas |
|
struct list_head |
i_devices |
Pointers of a list of block device file inodes (see Chapter 13) |
|
struct pipe_inode_info * |
i_pipe |
Used if the file is a pipe (see Chapter 19) |
|
struct block_device * |
i_bdev |
Pointer to the block device driver |
|
struct char_device * |
i_cdev |
Pointer to the character device driver |
|
unsigned long |
i_dnotify_mask |
Bit mask of directory notify events |
|
struct dnotify_struct * |
i_dnotify |
Used for directory notifications |
|
unsigned long |
i_state |
inode state flags |
|
unsigned int |
i_flags |
Filesystem mount flags |
|
unsigned char |
i_sock |
Nonzero if file is a socket |
|
atomic_t |
i_writecount |
Usage counter for writing processes |
|
unsigned int |
i_attr_flags |
File creation flags |
|
_ _u32 |
i_generation |
inode version number (used by some filesystems) |
|
union |
u |
Specific filesystem information |
The final u union field is used to include inode information that belongs to a specific filesystem. For instance, as we shall see in Chapter 17, if the inode object refers to an Ext2 file, the field stores an ext2_inode_info structure.
Each inode object duplicates some of the data included in the disk inode—for instance, the number of blocks allocated to the file. When the value of the i_state field is equal to I_DIRTY_SYNC, I_DIRTY_DATASYNC, or I_DIRTY_PAGES, the inode is dirty—that is, the corresponding disk inode must be updated; the I_DIRTY macro can be used to check the value of these three flags at once (see later for details). Other values of the i_state field are I_LOCK (the inode object is involved in a I/O transfer), I_FREEING (the inode object is being freed), and I_CLEAR (the inode object contents are no longer meaningful).
Each inode object always appears in one of the following circular doubly linked lists:
· The list of valid unused inodes, typically those mirroring valid disk inodes and not currently used by any process. These inodes are not dirty and their i_count field is set to 0. The first and last elements of this list are referenced by the next and prev fields, respectively, of the inode_unused variable. This list acts as a disk cache.
· The list of in-use inodes, typically those mirroring valid disk inodes and used by some process. These inodes are not dirty and their i_count field is positive. The first and last elements are referenced by the inode_in_use variable.
· The list of dirty inodes. The first and last elements are referenced by the s_dirty field of the corresponding superblock object.
Each of the lists just mentioned links the i_list fields of the proper inode objects.
inode objects are also included in a hash table named inode_hashtable. The hash table speeds up the search of the inode object when the kernel knows both the inode number and the address of the superblock object corresponding to the filesystem that includes the file.[4] Since hashing may induce collisions, the inode object includes an i_hash field that contains a backward and a forward pointer to other inodes that hash to the same position; this field creates a doubly linked list of those inodes. The hash table also includes a special chain list for the inodes not assigned to a superblock (such as the inodes used by sockets; see Chapter 18); its first and last elements are referenced by the anon_hash_chain variable.
[4] Actually, a Unix process may open a file and then unlink it. The i_nlink field of the inode could become 0, yet the process is still able to act on the file. In this particular case, the inode is removed from the hash table, even if it still belongs to the in-use or dirty list.
The methods associated with an inode object are also called inode operations. They are described by an inode_operations structure, whose address is included in the i_op field. Here are the inode operations in the order they appear in the inode_operations table:
create(dir, dentry, mode)
Creates a new disk inode for a regular file associated with a dentry object in some directory.
lookup(dir, dentry)
Searches a directory for an inode corresponding to the filename included in a dentry object.
link(old_dentry, dir, new_dentry)
Creates a new hard link that refers to the file specified by old_dentry in the directory dir; the new hard link has the name specified by new_dentry.
unlink(dir, dentry)
Removes the hard link of the file specified by a dentry object from a directory.
symlink(dir, dentry, symname)
Creates a new inode for a symbolic link associated with a dentry object in some directory.
mkdir(dir, dentry, mode)
Creates a new inode for a directory associated with a dentry object in some directory.
rmdir(dir, dentry)
Removes from a directory the subdirectory whose name is included in a dentry object.
mknod(dir, dentry, mode, rdev)
Creates a new disk inode for a special file associated with a dentry object in some directory. The mode and rdev parameters specify, respectively, the file type and the device's major number.
rename(old_dir, old_dentry, new_dir, new_dentry)
Moves the file identified by old_entry from the old_dir directory to the new_dir one. The new filename is included in the dentry object that new_dentry points to.
readlink(dentry, buffer, buflen)
Copies into a memory area specified by buffer the file pathname corresponding to the symbolic link specified by the dentry.
follow_link(inode, dir)
Translates a symbolic link specified by an inode object; if the symbolic link is a relative pathname, the lookup operation starts from the specified directory.
truncate(inode)
Modifies the size of the file associated with an inode. Before invoking this method, it is necessary to set the i_size field of the inode object to the required new size.
permission(inode, mask)
Checks whether the specified access mode is allowed for the file associated with inode.
revalidate(dentry)
Updates the cached attributes of a file specified by a dentry object (usually invoked by the network filesystem).
setattr(dentry, iattr)
Notifies a "change event" after touching the inode attributes.
getattr(dentry, iattr)
Used by networking filesystems when noticing that some cached inode attributes must be refreshed.
The methods just listed are available to all possible inodes and filesystem types. However, only a subset of them applies to a specific inode and filesystem; the fields corresponding to unimplemented methods are set to NULL.
12.2.3 File Objects
A file object describes how a process interacts with a file it has opened. The object is created when the file is opened and consists of a file structure, whose fields are described in Table 12-4. Notice that file objects have no corresponding image on disk, and hence no "dirty" field is included in the file structure to specify that the file object has been modified.
Table 12-4. The fields of the file object |
||
|
Type |
Field |
Description |
|
struct list_head |
f_list |
Pointers for generic file object list |
|
struct dentry * |
f_dentry |
dentry object associated with the file |
|
struct vfsmount * |
f_vfsmnt |
Mounted filesystem containing the file |
|
struct file_operations * |
f_op |
Pointer to file operation table |
|
atomic_t |
f_count |
File object's usage counter |
|
unsigned int |
f_flags |
Flags specified when opening the file |
|
mode_t |
f_mode |
Process access mode |
|
loff_t |
f_pos |
Current file offset (file pointer) |
|
unsigned long |
f_reada |
Read-ahead flag |
|
unsigned long |
f_ramax |
Maximum number of pages to be read-ahead |
|
unsigned long |
f_raend |
File pointer after last read-ahead |
|
unsigned long |
f_ralen |
Number of read-ahead bytes |
|
unsigned long |
f_rawin |
Number of read-ahead pages |
|
struct fown_struct |
f_owner |
Data for asynchronous I/O via signals |
|
unsigned int |
f_uid |
User's UID |
|
unsigned int |
f_gid |
User's GID |
|
int |
f_error |
Error code for network write operation |
|
unsigned long |
f_version |
Version number, automatically incremented after each use |
|
void * |
private_data |
Needed for tty driver |
|
struct kiobuf * |
f_iobuf |
Descriptor for direct access buffer (see Section 15.2) |
|
long |
f_iobuf_lock |
Lock for direct I/O transfer |
The main information stored in a file object is the file pointer—the current position in the file from which the next operation will take place. Since several processes may access the same file concurrently, the file pointer cannot be kept in the inode object. Each file object is always included in one of the following circular doubly linked lists:
· The list of "unused" file objects. This list acts both as a memory cache for the file objects and as a reserve for the superuser; it allows the superuser to open a file even if the dynamic memory in the system is exhausted. Since the objects are unused, their f_count fields are 0. The first element of the list is a dummy and it is stored in the free_list variable. The kernel makes sure that the list always contains at least NR_RESERVED_FILES objects, usually 10.
· The list of "in use" file objects not yet assigned to a superblock. The f_count field of each element in this list is set to 1. The first element of the list is a dummy and it is stored in the anon_list variable.
· Several lists of "in use" file objects already assigned to superblocks. Each superblock object stores in the s_files field the dummy first element of a list of file objects; thus, file objects of files belonging to different filesystems are included in different lists. The f_count field of each element in such a list is set to 1 plus the number of processes that are using the file object.
Regardless of which list a file object is in at the moment, the pointers of the next and previous elements in the list are stored in the f_list field of the file object. The files_lock semaphore protects the lists against concurrent accesses in multiprocessor systems.
The size of the list of "unused" file objects is stored in the nr_free_files field of the files_stat variable. The get_empty_filp( ) function is invoked when the VFS must allocate a new file object. The function checks whether the "unused" list has more than NR_RESERVED_FILES items, in which case one can be used for the newly opened file. Otherwise, it falls back to normal memory allocation.
The files_stat variable also includes the nr_files field (which stores the number of file objects included in all lists) and the max_files field (which is the maximum number of allocatable file objects—i.e., the maximum number of files that can be accessed at the same time in the system).[5]
[5] By default, max_files stores the value 8,192, but the system administrator can tune this parameter by writing into the /proc/sys/fs/file-max file.
As we explained earlier in Section 12.1.1, each filesystem includes its own set of file operations that perform such activities as reading and writing a file. When the kernel loads an inode into memory from disk, it stores a pointer to these file operations in a file_operations structure whose address is contained in the i_fop field of the inode object. When a process opens the file, the VFS initializes the f_op field of the new file object with the address stored in the inode so that further calls to file operations can use these functions. If necessary, the VFS may later modify the set of file operations by storing a new value in f_op.
The following list describes the file operations in the order in which they appear in the file_operations table:
llseek(file, offset, origin)
Updates the file pointer.
read(file, buf, count, offset)
Reads count bytes from a file starting at position *offset; the value *offset (which usually corresponds to the file pointer) is then incremented.
write(file, buf, count, offset)
Writes count bytes into a file starting at position *offset; the value *offset (which usually corresponds to the file pointer) is then incremented.
readdir(dir, dirent, filldir)
Returns the next directory entry of a directory in dirent; the filldir parameter contains the address of an auxiliary function that extracts the fields in a directory entry.
poll(file, poll_table)
Checks whether there is activity on a file and goes to sleep until something happens on it.
ioctl(inode, file, cmd, arg)
Sends a command to an underlying hardware device. This method applies only to device files.
mmap(file, vma)
Performs a memory mapping of the file into a process address space (see Chapter 15).
open(inode, file)
Opens a file by creating a new file object and linking it to the corresponding inode object (see Section 12.6.1 later in this chapter).
flush(file)
Called when a reference to an open file is closed—that is, when the f_count field of the file object is decremented. The actual purpose of this method is filesystem-dependent.
release(inode, file)
Releases the file object. Called when the last reference to an open file is closed—that is, when the f_count field of the file object becomes 0.
fsync(file, dentry)
Writes all cached data of the file to disk.
fasync(fd, file, on)
Enables or disables asynchronous I/O notification by means of signals.
lock(file, cmd, file_lock)
Applies a lock to the file (see Section 12.7 later in this chapter).
readv(file, vector, count, offset)
Reads bytes from a file and puts the results in the buffers described by vector; the number of buffers is specified by count.
writev(file, vector, count, offset)
Writes bytes into a file from the buffers described by vector; the number of buffers is specified by count.
sendpage(file, page, offset, size, pointer, fill)
Transfers data from this file to another file; this method is used by sockets (see Chapter 18).
get_unmapped_area(file, addr, len, offset, flags)
Gets an unused address range to map the file (used for frame buffer memory mappings).
The methods just described are available to all possible file types. However, only a subset of them apply to a specific file type; the fields corresponding to unimplemented methods are set to NULL.
12.2.4 dentry Objects
We mentioned in Section 12.1.1 that the VFS considers each directory a file that contains a list of files and other directories. We shall discuss in Chapter 17 how directories are implemented on a specific filesystem. Once a directory entry is read into memory, however, it is transformed by the VFS into a dentry object based on the dentry structure, whose fields are described in Table 12-5. The kernel creates a dentry object for every component of a pathname that a process looks up; the dentry object associates the component to its corresponding inode. For example, when looking up the /tmp/test pathname, the kernel creates a dentry object for the / root directory, a second dentry object for the tmp entry of the root directory, and a third dentry object for the test entry of the /tmp directory.
Notice that dentry objects have no corresponding image on disk, and hence no field is included in the dentry structure to specify that the object has been modified. Dentry objects are stored in a slab allocator cache called dentry_cache; dentry objects are thus created and destroyed by invoking kmem_cache_alloc( ) and kmem_cache_free( ).
Each dentry object may be in one of four states:
Free
The dentry object contains no valid information and is not used by the VFS. The corresponding memory area is handled by the slab allocator.
Unused
The dentry object is not currently used by the kernel. The d_count usage counter of the object is 0, but the d_inode field still points to the associated inode. The dentry object contains valid information, but its contents may be discarded if necessary in order to reclaim memory.
In use
The dentry object is currently used by the kernel. The d_count usage counter is positive and the d_inode field points to the associated inode object. The dentry object contains valid information and cannot be discarded.
Negative
The inode associated with the dentry does not exist, either because the corresponding disk inode has been deleted or because the dentry object was created by resolving a pathname of a nonexisting file. The d_inode field of the dentry object is set to NULL, but the object still remains in the dentry cache so that further lookup operations to the same file pathname can be quickly resolved. The term "negative" is misleading since no negative value is involved.
12.2.5 The dentry Cache
Since reading a directory entry from disk and constructing the corresponding dentry object requires considerable time, it makes sense to keep in memory dentry objects that you've finished with but might need later. For instance, people often edit a file and then compile it, or edit and print it, or copy it and then edit the copy. In such cases, the same file needs to be repeatedly accessed.
To maximize efficiency in handling dentries, Linux uses a dentry cache, which consists of two kinds of data structures:
· A set of dentry objects in the in-use, unused, or negative state.
· A hash table to derive the dentry object associated with a given filename and a given directory quickly. As usual, if the required object is not included in the dentry cache, the hashing function returns a null value.
The dentry cache also acts as a controller for an inode cache. The inodes in kernel memory that are associated with unused dentries are not discarded, since the dentry cache is still using them. Thus, the inode objects are kept in RAM and can be quickly referenced by means of the corresponding dentries.
All the "unused" dentries are included in a doubly linked "Least Recently Used" list sorted by time of insertion. In other words, the dentry object that was last released is put in front of the list, so the least recently used dentry objects are always near the end of the list. When the dentry cache has to shrink, the kernel removes elements from the tail of this list so that the most recently used objects are preserved. The addresses of the first and last elements of the LRU list are stored in the next and prev fields of the dentry_unused variable. The d_lru field of the dentry object contains pointers to the adjacent dentries in the list.
Each "in use" dentry object is inserted into a doubly linked list specified by the i_dentry field of the corresponding inode object (since each inode could be associated with several hard links, a list is required). The d_alias field of the dentry object stores the addresses of the adjacent elements in the list. Both fields are of type struct list_head.
An "in use" dentry object may become "negative" when the last hard link to the corresponding file is deleted. In this case, the dentry object is moved into the LRU list of unused dentries. Each time the kernel shrinks the dentry cache, negative dentries move toward the tail of the LRU list so that they are gradually freed (see Section 16.7.6).
The hash table is implemented by means of a dentry_hashtable array. Each element is a pointer to a list of dentries that hash to the same hash table value. The array's size depends on the amount of RAM installed in the system. The d_hash field of the dentry object contains pointers to the adjacent elements in the list associated with a single hash value. The hash function produces its value from both the address of the dentry object of the directory and the filename.
The dcache_lock spin lock protects the dentry cache data structures against concurrent accesses in multiprocessor systems. The d_lookup( ) function looks in the hash table for a given parent dentry object and filename.
The methods associated with a dentry object are called dentry operations; they are described by the dentry_operations structure, whose address is stored in the d_op field. Although some filesystems define their own dentry methods, the fields are usually NULL and the VFS replaces them with default functions. Here are the methods, in the order they appear in the dentry_operations table:
Determines whether the dentry object is still valid before using it for translating a file pathname. The default VFS function does nothing, although network filesystems may specify their own functions.
d_hash(dentry, name)
Creates a hash value; this function is a filesystem-specific hash function for the dentry hash table. The dentry parameter identifies the directory containing the component. The name parameter points to a structure containing both the pathname component to be looked up and the value produced by the hash function.
d_compare(dir, name1, name2)
Compares two filenames; name1 should belong to the directory referenced by dir. The default VFS function is a normal string match. However, each filesystem can implement this method in its own way. For instance, MS-DOS does not distinguish capital from lowercase letters.
d_delete(dentry)
Called when the last reference to a dentry object is deleted (d_count becomes 0). The default VFS function does nothing.
d_release(dentry)
Called when a dentry object is going to be freed (released to the slab allocator). The default VFS function does nothing.
d_iput(dentry, ino)
Called when a dentry object becomes "negative"—that is, it loses its inode. The default VFS function invokes iput( ) to release the inode object.
12.2.6 Files Associated with a Process
We mentioned in Section 1.5 that each process has its own current working directory and its own root directory. These are just two examples of data that must be maintained by the kernel to represent the interactions between a process and a filesystem. A whole data structure of type fs_struct is used for that purpose (see Table 12-6) and each process descriptor has an fs field that points to the process fs_struct structure.
A second table, whose address is contained in the files field of the process descriptor, specifies which files are currently opened by the process. It is a files_struct structure whose fields are illustrated in Table 12-7.
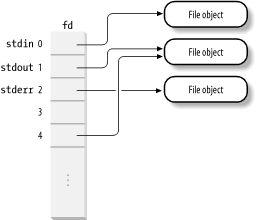
The fd field points to an array of pointers to file objects. The size of the array is stored in the max_fds field. Usually, fd points to the fd_array field of the files_struct structure, which includes 32 file object pointers. If the process opens more than 32 files, the kernel allocates a new, larger array of file pointers and stores its address in the fd fields; it also updates the max_fds field.
For every file with an entry in the fd array, the array index is the file descriptor. Usually, the first element (index 0) of the array is associated with the standard input of the process, the second with the standard output, and the third with the standard error (see Figure 12-3). Unix processes use the file descriptor as the main file identifier. Notice that, thanks to the dup( ), dup2( ), and fcntl( ) system calls, two file descriptors may refer to the same opened file—that is, two elements of the array could point to the same file object. Users see this all the time when they use shell constructs like 2>&1 to redirect the standard error to the standard output.
A process cannot use more than NR_OPEN (usually, 1, 048 ,576) file descriptors. The kernel also enforces a dynamic bound on the maximum number of file descriptors in the rlim[RLIMIT_NOFILE] structure of the process descriptor; this value is usually 1,024, but it can be raised if the process has root privileges.
The open_fds field initially contains the address of the open_fds_init field, which is a bitmap that identifies the file descriptors of currently opened files. The max_fdset field stores the number of bits in the bitmap. Since the fd_set data structure includes 1,024 bits, there is usually no need to expand the size of the bitmap. However, the kernel may dynamically expand the size of the bitmap if this turns out to be necessary, much as in the case of the array of file objects.
Figure 12-3. The fd array
The kernel provides an fget( ) function to be invoked when the kernel starts using a file object. This function receives as its parameter a file descriptor fd . It returns the address in current->files->fd[fd] (that is, the address of the corresponding file object), or NULL if no file corresponds to fd . In the first case, fget( ) increments the file object usage counter f_count by 1.
The kernel also provides an fput( ) function to be invoked when a kernel control path finishes using a file object. This function receives as its parameter the address of a file object and decrements its usage counter, f_count. Moreover, if this field becomes 0, the function invokes the release method of the file operations (if defined), releases the associated dentry object and filesystem descriptor, decrements the i_writecount field in the inode object (if the file was opened for writing), and finally moves the file object from the "in use" list to the "unused" one.