15.1 Reading and Writing a File
Section 12.6.2, described how the read( ) and write( ) system calls are implemented. The corresponding service routines end up invoking the file object's read and write methods, which may be filesystem-dependent. For disk-based filesystems, these methods locate the physical blocks that contain the data being accessed, and activate the block device driver to start the data transfer.
Reading a file is page-based: the kernel always transfers whole pages of data at once. If a process issues a read( ) system call to get a few bytes, and that data is not already in RAM, the kernel allocates a new page frame, fills the page with the suitable portion of the file, adds the page to the page cache, and finally copies the requested bytes into the process address space. For most filesystems, reading a page of data from a file is just a matter of finding what blocks on disk contain the requested data. Once this is done, the kernel can use one or more page I/O operations to fill the pages. The read method of most filesystems is implemented by a common function named generic_file_read( ).
Write operations on disk-based files are slightly more complicated to handle, since the file size could change, and therefore the kernel might allocate or release some physical blocks on the disk. Of course, how this is precisely done depends on the filesystem type. However, many disk-based filesystems implement their write methods by means of a common function named generic_file_write( ). Examples of such filesystems are Ext2, System V/Coherent/Xenix, and Minix. On the other hand, several other filesystems, such as journaling and network filesystems, implement the write method by means of custom functions.
15.1.1 Reading from a File
The read method of the regular files that belong to almost all disk-based filesystems, as well as the read method of any block device file, is implemented by the generic_file_read( ) function. It acts on the following parameters:
filp
Address of the file object
buf
Linear address of the User Mode memory area where the characters read from the file must be stored
count
Number of characters to be read
ppos
Pointer to a variable that stores the offset from which reading must start (usually the f_pos field of the filp file object)
As a first step, the function checks whether the O_DIRECT flag of the file object is set. If so, the read access should bypass the page cache; we discuss this special case in the later section Section 15.3.
Let's assume that the O_DIRECT flag is not set. The function invokes access_ok( ) to verify that the buf and count parameters received from the system call service routine sys_read( ) are correct, and returns the -EFAULT error code if they aren't (see Section 9.2.4).
If everything is ok, generic_file_read( ) allocates a read operation descriptor — namely, a data structure of type read_descriptor_t that stores the current status of the ongoing file read operation. The fields of this descriptor are shown in Table 15-1.
Then the function invokes do_generic_file_read( ), passing to it the file object pointer filp, the pointer to the file offset ppos, the address of the just allocated read operation descriptor desc, and the address of the file_read_actor( ) function (see later). The do_generic_file_read( ) function performs the following actions:[1]
[1] As usual, for the sake of simplicity, we do not discuss how errors and anomalous conditions are handled.
1. Gets the address_space object corresponding to the file being read; its address is stored in filp->f_dentry->d_inode->i_mapping.
2. Gets the inode object that owns the address space; its address is stored in the host field of the address_space object. Notice that this object could be different from the inode pointed to by filp->f_dentry->d_inode (see Section 13.4.1).
3. Considers the file as subdivided in pages of data (4,096 bytes per page) and derives, from the file pointer *ppos, the logical number index of the page including the first requested byte. Also stores in offset the displacement inside the page of the first requested byte.
4. Checks whether the file pointer is inside the read-ahead window of the file. We defer discussing read-ahead until the later section Section 15.1.2.
5. Starts a cycle to read all pages that include the requested desc->count bytes. During a single iteration, the function transfers a page of data by performing the following substeps:
a. If index*4096+offset exceeds the file size stored in the i_size field of the inode object, it exits from the cycle and goes to Step 6.
b. Looks up the page cache to find the page that stores the requested data. Remember that the page cache is essentially a hash table indexed by the address of the address_space object and the displacement of the page inside the file (index).
c. If the page is not found inside the page cache, allocates a new page frame and inserts it into the page cache by invoking add_to_page_cache( ) (see Section 14.1.3). Remember that the PG_uptodate flag of the page is cleared, while the PG_locked flag is set. The function jumps to Step 5h.
d. Here the page has been found in the page cache. The function increments the usage counter of the page descriptor.
e. Checks the PG_uptodate flag of the page; if it is set, the data stored in the page is up-to-date. The function jumps to Step 5j.
f. Invokes generic_file_readahead( ) to consider activating further read-ahead operations on the file. As we'll see in the later section Section 15.1.2, this function could trigger I/O data transfers for some other blocks in the page. However, we may safely ignore the issue right now.
g. The data on the page is not valid, so it must be read from disk. The function gains exclusive access to the page by setting the PG_locked flag. Of course, the page might be already locked if a previously started I/O data transfer is not yet terminated; in this case, it sleeps until the page is unlocked, and then checks the PG_uptodate flag again in case another data transfer has performed the necessary read. If the flag is now set to 1, the function jumps to Step 5j. Otherwise, the function continues to perform the read.
h. Invokes the readpage method of the address_space object of the file. The corresponding function takes care of activating the I/O data transfer from the disk to the page. We discuss later what this function does for regular files and block device files.
i. Checks the PG_uptodate flag of the page. If the I/O data transfer is not already completed, the flag is still cleared, so the function invokes again the generic_file_readahead( ) function and waits until the I/O data transfer completes.
j. The page contains up-to-date data. The function invokes generic_file_readahead( ) to consider activating further read-ahead operations on the file. As we'll see in the later section Section 15.1.2, this function could trigger I/O data transfers for some other blocks in the page.
k. Invokes mark_page_accessed( ) to set the PG_referenced flag, which denotes that the page is actively used and should not be swapped out (see Chapter 16). This is done only if the page has been explicitly requested by the user (the kernel is not performing read-ahead).
l. Now it is time to copy the data on the page in the User Mode buffer. To do this, do_generic_file_read( ) invokes the file_read_actor( ) function, whose address has been passed as a parameter of the function. In turn, file_read_actor( ) takes one of the steps shown in the following list.
a. Invokes kmap( ), which establishes a permanent kernel mapping for the page if it is in high memory (see Section 7.1.6).
b. Invokes _ _copy_to_user( ), which copies the data on the page in the User Mode address space (see Section 9.2.5). Notice that this operation might block the process.
c. Invokes kunmap( ) to release any permanent kernel mapping of the page.
d. Updates the count, written, and buf fields of the read_descriptor_t descriptor.
m. Updates the index and offset local variables according to the number of bytes effectively transferred in the User Mode buffer.
n. Decrements the page descriptor usage counter.
o. If the count field of the read_descriptor_t descriptor is not null and all requested bytes in the page have been successfully transferred into the User Mode address space, continues the loop, with the next page of data in the file jumping to Step 5a.
6. Assigns to *ppos the value index*4096+offset, thus storing the next position where a read is to occur for a future invocation of this function.
7. Sets the f_reada field of the file descriptor to 1 to record the fact that data is being read sequentially from the file (see the later section Section 15.1.2).
8. Invokes update_atime( ) to store the current time in the i_atime field of the file's inode and to mark the inode as dirty.
15.1.1.1 The readpage method for regular files
As we saw in the previous section, the readpage method is used repeatedly by do_generic_file_read( ) to read individual pages from disk into memory.
The readpage method of the address_space object stores the address of the function that effectively activates the I/O data transfer from the physical disk to the page cache. For regular files, this field typically points to a wrapper that invokes the block_read_full_page( ) function. For instance, the readpage method of the Ext2 filesystem is implemented by the following function:
int ext2_readpage(struct file *file, struct page *page){ return block_read_full_page(page, ext2_get_block);}
The wrapper is needed because the block_read_full_page( ) function receives as parameters the descriptor page of the page to be filled and the address get_block of a function that helps block_read_full_page( ) find the right block. This function translates the block numbers relative to the beginning of the file into logical block numbers relative to positions of the block in the disk partition (for an example, see Chapter 17). Of course, the latter parameter depends on the type of filesystem to which the regular file belongs; in the previous example, the parameter is the address of the ext2_get_block( ) function.
The block_read_full_page( ) function starts a page I/O operation on the buffers included in the page. It allocates any necessary buffer heads, finds the buffers on disk using the get_block method described earlier, and transfers the data. Specifically, it performs the following steps:
1. Checks the page->buffers field; if it is NULL, invokes create_empty_buffers( ) to allocate asynchronous buffer heads for all buffers included in the page (see Section 13.4.8.2). The address of the buffer head for the first buffer in the page is stored in the page->buffers field. The b_this_page field of each buffer head points to the buffer head of the next buffer in the page.
2. Derives from the file offset relative to the page (page->index field) the file block number of the first block in the page.
3. For each buffer head of the buffers in the page, performs the following substeps:
a. If the BH_Uptodate flag is set, skips the buffer and continues with the next buffer in the page.
b. If the BH_Mapped flag is not set, invokes the filesystem-dependent function whose address has been passed as a parameter called get_block. The function looks in the on-disk data structures of the filesystem and finds the logical block number of the buffer (relative to the beginning of the disk partition rather than the beginning of the regular file). The filesystem-dependent function stores this number in the b_blocknr field of the corresponding buffer head, and sets its BH_Mapped flag. In rare cases, the filesystem-dependent function might not find the block, even if the block belongs to the regular file, because the application might have left a hole in that location (see Section 17.6.4). In this case, block_read_full_page( ) fills the buffer with 0's, sets the BH_Uptodate flag of the corresponding buffer head, and continues with the next buffer in the page.
c. Tests again the BH_Uptodate flag because the filesystem-dependent function could have triggered a block I/O operation that updated the buffer. If BH_Uptodate is set, continues with the next buffer in the page.
d. Stores the address of the buffer head in the arr local array, and continues with the next buffer in the page.
4. Now the arr local array stores the addresses of the buffer heads that correspond to the buffers whose content is not up-to-date. If the array is empty, all buffers in the page are valid. So the function sets the PG_uptodate flag of the page descriptor, unlocks the page, and terminates.
5. The arr local array is not empty. For each buffer head in the array, block_read_full_page( ) performs the following substeps:
a. Sets the BH_Lock flag. If the flag was already set, the function waits until the buffer is released.
b. Sets the b_end_io field of the buffer head to the address of the end_buffer_io_async( ) function (see Section 13.4.8.2).
c. Sets the BH_Async flag of the buffer head.
6. For each buffer head in the arr local array, invokes the submit_bh( ) function on it, specifying the operation type READ. As we saw in Section 13.4.6, this function triggers the I/O data transfer of the corresponding block.
15.1.1.2 The readpage method for block device files
In Section 13.2.3 and Section 13.4.5.2, we discussed how the kernel handles requests to open a block device file. We saw how the kernel allocates a descriptor of type block_device for any newly opened device driver and inserts it into a hash table. The bd_inode field of the descriptor points to a block device inode that belongs to the bdev special filesystem (see Section 13.4.1). Each I/O operation on the block device refers to this inode, rather than to the inode of the block device file that was specified in the open( ) system call. (Remember that different device files might refer to the same block device.)
Block devices use an address_space object that is stored in the i_data field of the corresponding block device inode. Unlike regular files — whose readpage method in the address_space object depends on the filesystem type to which the file belongs — the readpage method of block device files is always the same. It is implemented by the blkdev_readpage( ) function, which calls block_read_full_page( ):
int blkdev_readpage(struct file * file, struct * page page){ return block_read_full_page(page, blkdev_get_block);}
As you see, the function is once again a wrapper for the block_read_full_page( ) function described in the previous section. This time the second parameter points to a function that must translate the file block number relative to the beginning of the file into a logical block number relative to the beginning of the block device. For block device files, however, the two numbers coincide; therefore, the blkdev_get_block( ) function performs the following steps:
1. Checks whether the number of the first block in the page exceeds the size of the block device (stored in blk_size[MAJOR(inode->i_rdev)][MINOR(inode->i_rdev)], see Section 13.4.2). If so, returns the error code -EIO.
2. Sets the b_dev field of the buffer head to inode->r_dev.
3. Sets the b_blocknr field of the buffer head to the file block number of the first block in the page.
4. Sets the BH_Mapped flag of the buffer head to state that the b_dev and b_blocknr fields of the buffer head are significant.
15.1.2 Read-Ahead of Files
Many disk accesses are sequential. As we shall see in Chapter 17, regular files are stored on disk in large groups of adjacent sectors, so that they can be retrieved quickly with few moves of the disk heads. When a program reads or copies a file, it often accesses it sequentially, from the first byte to the last one. Therefore, many adjacent sectors on disk are likely to be fetched in several I/O operations.
Read-ahead is a technique that consists of reading several adjacent pages of data of a regular file or block device file, before they are actually requested. In most cases, read-ahead significantly enhances disk performance, since it lets the disk controller handle fewer commands, each of which refers to a larger chunk of adjacent sectors. Moreover, it improves system responsiveness. A process that is sequentially reading a file does not usually wait for the requested data because it is already available in RAM.
However, read-ahead is of no use to random accesses to files; in this case, it is actually detrimental since it tends to waste space in the page cache with useless information. Therefore, the kernel stops read-ahead when it determines that the most recently issued I/O access is not sequential to the previous one.
Read-ahead of files requires a sophisticated algorithm for several reasons:
· Since data is read page by page, the read-ahead algorithm does not have to consider the offsets inside the page, but only the positions of the accessed pages inside the file. A series of accesses to pages of the same file is considered sequential if the related pages are close to each other. We'll define the word "close" more precisely in a moment.
· Read-ahead must be restarted from scratch when the current access is not sequential with respect to the previous one (random access).
· Read-ahead should be slowed down or even stopped when a process keeps accessing the same pages over and over again (only a small portion of the file is being used).
· If necessary, the read-ahead algorithm must activate the low-level I/O device driver to make sure that the new pages will ultimately be read.
The read-ahead algorithm identifies a set of pages that correspond to a contiguous portion of the file as the read-ahead window. If the next read operation issued by a process falls inside this set of pages, the kernel considers the file access "sequential" to the previous one. The read-ahead window consists of pages requested by the process or read in advance by the kernel and included in the page cache. The read-ahead window always includes the pages requested in the last read-ahead operation; they are called the read-ahead group. If the next operation issued by a process falls inside the read-ahead group, the kernel might read in advance some of the pages following the read-ahead window just to ensure that the kernel will be "ahead" of the reading process. Not all the pages in the read-ahead window or group are necessarily up to date. They are invalid (i.e., their PG_uptodate flags are cleared) if their transfer from disk is not yet completed.
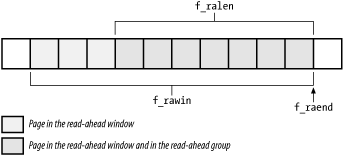
The file object includes the following fields related to read-ahead:
f_raend
Position of the first byte after the read-ahead group and the read-ahead window
f_rawin
Length in bytes of the current read-ahead window
f_ralen
Length in bytes of the current read-ahead group
f_ramax
Maximum number of characters to get in the next read-ahead operation
f_reada
Flag specifying whether the file pointer has been set explicitly by a lseek( ) system call (if value is 0) or implicitly by a previous read( ) system call (if value is 1)
When a file is opened, all these fields are set to 0. Figure 15-1 illustrates how some of the fields are used to delimit the read-ahead window and the read-ahead group.
Figure 15-1. Read-ahead window and read-ahead group
The kernel distinguishes two kinds of read-ahead operations:
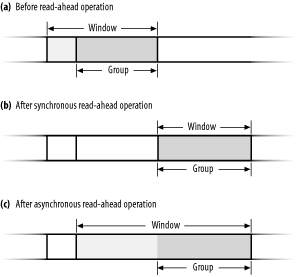
Synchronous read-ahead operation
Performed whenever a read access falls outside the current read-ahead window of a file. The synchronous read-ahead operation usually affects all pages requested by the user in the read operation plus one. After the operation, the read-ahead window coincides with the read-ahead group (see Figure 15-2).
Asynchronous read-ahead operation
Performed whenever a read access falls inside the current read-ahead group of a file. The asynchronous read-ahead operation usually tries to shift forward and to enlarge the read-ahead window of the file by reading from disk twice as many pages as the length of the previous read-ahead group. The new read-ahead window spans the old read-ahead group and the new one (see Figure 15-2).
Figure 15-2. Read-ahead group and window
To explain how read-ahead works, let's suppose a user issues a read( ) system call on a file. The do_generic_file_read( ) function checks whether the first page to be read falls inside the current read-ahead window of the file (Step 4 in Section 15.1.1). Three cases are considered:
· The first page to be read falls outside the current read-ahead window. The function sets the f_raend, f_ralen, f_ramax, and f_rawin fields of the file object to 0. Moreover, it disables asynchronous read-ahead operations by setting the reada_ok local variable to 0.
· The first page to be read falls inside the current read-ahead window. This means that the user is accessing the file sequentially. The function enables asynchronous read-ahead operations by setting the reada_ok local variable to 1.
· The current read-ahead window and groups are empty because the file was never accessed before; moreover, the first page to be read is the initial page of the file. In this special case, the function enables asynchronous read-ahead operations by setting the reada_ok local variable to 1.
The do_generic_file_read( ) function also adjusts the value stored in the f_ramax field of the file object, which represents the number of pages to be requested in the next read-ahead operation. Although its value is determined by the previous read-ahead operation on the file (if any), do_generic_file_read( ) ensures that f_ramax is always greater than the number of pages requested in the read( ) system call plus 1. Moreover, the function ensures that f_ramax is always greater than the value stored in the vm_min_readahead global variable (usually three pages) and smaller than a per-device upper bound. Each block device may define this upper bound by storing a value into the max_readahead array, which is indexed by the major and minor number of the device. If the driver does not specify an upper bound, the kernel uses the upper bound stored in the vm_max_readahead global variable (usually 31 pages). System administrators may tune the values in vm_min_readahead and vm_max_readahead by writing into the /proc/sys/vm/min-readahead and /proc/sys/vm/max-readahead files, respectively.[2]
[2] A special heuristic applies for read( ) system calls that affect only the first half of the initial page of the file. In this case, the do_generic_file_read( ) function sets the f_ramax field to 0. The idea is that if a user reads only a small number of characters at the beginning of the file, then she is not really interested in sequentially accessing the whole file, so read-ahead operations are useless.
We saw in the earlier section Section 15.1.1 that the do_generic_file_read( ) function invokes the generic_file_readahead( ) function several times, at least once for each page involved in the read request. The function receives as parameters the file and inode objects, the descriptor of the page currently considered by do_generic_file_read( ), and the value of the reada_ok flag, which enables or disables asynchronous read-ahead operations.
To read ahead a page, the generic_file_readahead( ) function invokes page_cache_read( ), which looks up (and optionally inserts) the page in the page cache and then invokes the readpage method of the corresponding address_space object to request the I/O data transfer.
The overall scheme of generic_file_readahead( ) is shown in Figure 15-3. Basically, the function distinguishes two cases: synchronous and asynchronous. It checks the page descriptor passed as its parameter. If the PG_locked flag in this descriptor is set, the page is most likely still involved in the I/O data transfer triggered by the do_generic_file_read( ) function and any read-ahead must be synchronous. Otherwise, asynchronous read-ahead is possible. We examine the actions based on the PG_locked flag in the following sections.
Figure 15-3. Overall scheme of the generic_file_readahead( ) function
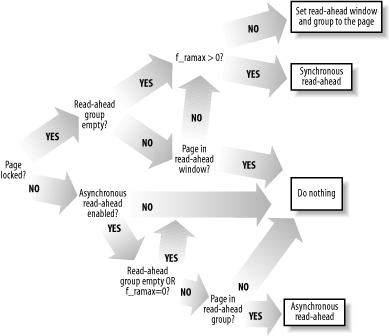
15.1.2.1 The accessed page is locked (synchronous read-ahead)
In this case, generic_file_readahead( ) may take three different courses of action:
· When the read access is not sequential with respect to the previous one (that is, either the read-ahead group is empty, or the accessed page is outside the read-ahead window) and f_ramax is not null, the function performs a synchronous read-ahead operation as follows:
o Reads f_ramax pages starting from the page following the accessed one.
o Sets the new read-ahead window and the new read-ahead group to contain the f_ramax pages just read and the page referenced by the do_generic_file_read( ) function.
o Doubles the value stored in f_ramax (but allows it to become no larger than the upper bound defined by the block device).
· When a synchronous read-ahead operation is likely to be performed, but the f_ramax field is set to 0, the generic_file_readahead( ) function resets the read-ahead window and the read-ahead group as follows:
o The read-ahead window includes just the accessed page, so its size is set to 1.
o The read-ahead group is set to be the same as the read-ahead window.
Remember that do_generic_file_read( ) sets f_ramax to 0 when the user requests the first few characters of a file.
· If the accessed page falls inside the non-null read-ahead window, the function does nothing. Since the page is locked, the corresponding I/O data transfers are still to be finished, so it is pointless to start an additional read operation.
15.1.2.2 The accessed page is unlocked (asynchronous read-ahead)
If the page accessed by the caller do_generic_file_read( ) function is unlocked, the corresponding I/O data transfers have most likely finished. In this case, generic_file_readahead( ) may take two different courses of action:
· When several conditions are satisfied, the function performs an asynchronous read-ahead operation. These conditions are as follows: asynchronous read-ahead operations are enabled, the read-head group is not empty and the accessed page falls into it, and the f_ramax field is not null. The function does the following:
o Reads f_ramax+1 pages starting from f_raend
o Sets the new read-ahead window to include the previous read-ahead group and the f_ramax+1 pages just read
o Sets the new read-ahead group to include the f_ramax+1 pages just read
o Doubles the value stored in f_ramax (but allows it to become no larger than the upper bound defined by the block device)
· The function does nothing whenever the function cannot start an asynchronous read-ahead operation — for instance, when the read operation is not sequential with respect to the previous one (the asynchronous read-ahead is disabled by do_generic_file_read( )), or when the access is sequential but the accessed page falls inside the read-ahead window and outside the read-ahead group (i.e., the process is lagging with respect to read-ahead).
15.1.3 Writing to a File
Recall that the write( ) system call involves moving data from the User Mode address space of the calling process into the kernel data structures, and then to disk. The write method of the file object permits each filesystem type to define a specialized write operation. In Linux 2.4, the write method of each disk-based filesystem is a procedure that basically identifies the disk blocks involved in the write operation, copies the data from the User Mode address space into some pages belonging to the page cache, and marks the buffers in those pages as dirty.
Several filesystems (such as Ext2) implement the write method of the file object by means of the generic_file_write( ) function, which acts on the following parameters:
file
File object pointer
buf
Address where the characters to be written into the file must be fetched
count
Number of characters to be written
ppos
Address of a variable storing the file offset from which writing must start
The function performs the following operations:
1. Verifies that the parameters count and buf are valid (they must refer to the User Mode address space); if not, returns the error code -EFAULT.
2. Determines the address inode of the inode object that corresponds to the file to be written (file->f_dentry->d_inode->i_mapping->host).
3. Acquires the semaphore inode->i_sem. Thanks to this semaphore, only one process at a time can issue a write( ) system call on the file.
4. If the O_APPEND flag of file->flags is on and the file is regular (not a block device file), sets *ppos to the end of the file so that all new data is appended to it.
5. Performs several checks on the size of the file. For instance, the write operation must not enlarge a regular file so much as to exceed the per-user limit stored in current->rlim[RLIMIT_FSIZE] (see Section 3.2.5) and the filesystem limit stored in inode->i_sb->s_maxbytes.
6. Stores the current time of day in the inode->mtime field (the time of last file write operation) and in the inode->mtime field (the time of last inode change), and marks the inode object as dirty.
7. Checks the value of the O_DIRECT flag of the file object. If it is set, the write operation bypasses the page cache. We discuss this case later in this chapter. In the rest of this section, we assume that O_DIRECT is not set.
8. Starts a cycle to update all the pages of the file involved in the write operation. During each iteration, performs the following substeps:
a. Tries to find the page in the page cache. If it isn't there, allocates a free page and adds it to the page cache.
b. Locks the page — that is, sets its PG_locked flag.
c. Increments the page usage counter as a fail-safe mechanism.
d. Invokes kmap( ) to get the starting linear address of the page (see Section 7.1.6).
e. Invokes the prepare_write method of the address_space object of the inode (file->f_dentry->d_inode->i_mapping). The corresponding function takes care of allocating asynchronous buffer heads for the page and of reading some buffers from disk, if necessary. We'll discuss in subsequent sections what this function does for regular files and block device files.
f. Invokes _ _copy_from_user( ) to copy the characters from the buffer in User Mode to the page.
g. Invokes the commit_write method of the address_space object of the inode (file->f_dentry->d_inode->i_mapping). The corresponding function marks the underlying buffers as dirty so they are written to disk later. We discuss what this function does for regular files and block device files in the next two sections.
h. Invokes kunmap( ) to release any permanent high-memory mapping established in Step 8d.
i. Sets the PG_referenced flag of the page; it is used by the memory reclaiming algorithm described in Chapter 16.
j. Clears the PG_locked flag, and wakes up any process that is waiting for the page to unlock.
k. Decrements the page usage counter to undo the increment in Step 8c.
9. Now all pages of the file involved in the write operation have been handled.Updates the value of *ppos to point right after the last character written.
10. Checks whether the O_SYNC flag of the file is set. If so, invokes generic_osync_inode( ) to force the kernel to flush all dirty buffers of the page to disk, blocking the current process until the I/O data transfers terminate. In Version 2.4.18 of Linux, this function over-ices the cake because it flushes to disk all dirty buffers of the file, not just those belonging to the file portion just written.
11. Releases the inode->i_sem semaphore.
12. Returns the number of characters written into the file.
15.1.3.1 The prepare_write and commit_write methods for regular files
The prepare_write and commit_write methods of the address_space object specialize the generic write operation implemented by generic_file_write( ) for regular files and block device files. Both of them are invoked once for every page of the file that is affected by the write operation.
Each disk-based filesystem defines its own prepare_write method. As with read operations, this method is simply a wrapper for a common function. For instance, the Ext2 filesystem implements the prepare_write method by means of the following function:
int ext2_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to){ return block_prepare_write(page,from,to,ext2_get_block);}
The ext2_get_block( ) function was already mentioned in the earlier section Section 15.1.1; it translates the block number relative to the file into a logical block number, which represents the position of the data on the physical block device.
The block_prepare_write( ) function takes care of preparing the buffers and the buffer heads of the file's page by performing the following steps:
1. Checks the page->buffers field; if it is NULL, the function invokes create_empty_buffers( ) to allocate buffer heads for all buffers included in the page (see Section 13.4.8.2). The address of the buffer head for the first buffer in the page is stored in the page->buffers field. The b_this_page field of each buffer head points to the buffer head of the next buffer in the page.
2. For each buffer head relative to a buffer included in the page and affected by the write operation, the following is performed:
a. If the BH_Mapped flag is not set, the function performs the following substeps:
1. Invokes the filesystem-dependent function whose address was passed as a parameter. The function looks in the on-disk data structures of the filesystem and finds the logical block number of the buffer (relative to the beginning of the disk partition rather than the beginning of the regular file). The filesystem-dependent function stores this number in the b_blocknr field of the corresponding buffer head and sets its BH_Mapped flag. The filesystem-specific function could allocate a new physical block for the file (for instance, if the accessed block falls inside a "hole" of the regular file, see section Section 17.6.4). In this case, it sets the BH_New flag.
2. Checks the value of the BH_New flag; if it is set, invokes unmap_underlying_metadata( ) to make sure that the buffer cache does not include a dirty buffer referencing the same block on disk.[3] Moreover, if the write operation does not rewrite the whole buffer, the function fills it with 0's. Then considers the next buffer in the page.
[3] Although unlikely, this case might happen if another block in the same buffer page was previously accessed by means of a block I/O operation (which caused our buffer head to be inserted in the buffer cache; see Section 14.2.2), and if in addition a user wrote into our block by accessing the corresponding block device file, thus making it dirty.
b. If the write operation does not rewrite the whole buffer and its BH_Uptodate flag is not set, the function invokes ll_rw_block( ) on the block to read its content from disk (see Section 13.4.6).
3. Blocks the current process until all read operations triggered in Step 2b have been completed.
Once the prepare_write method returns, the generic_file_write( ) function updates the page with the data stored in the User Mode address space. Next, it invokes the commit_write method of the address_space object. This method is implemented by the generic_commit_write( ) function for almost all disk-based filesystems.
The generic_commit_write( ) function performs the following steps:
1. Invokes the block_commit_write( ) function. In turn, this function considers all buffers in the page that are affected by the write operation; for each of them, it sets the BH_Uptodate and BH_Dirty flags and inserts the buffer head in the BUF_DIRTY list and in the list of dirty buffers of the inode (if it is not already in the list). The function also invokes the balance_dirty( ) function to keep the number of dirty buffers in the system bounded (see Section 14.2.4).
2. Checks whether the write operation enlarged the file. In this case, the function updates the i_size field of the file's inode and marks the inode object as dirty.
15.1.3.2 The prepare_write and commit_write methods for block device files
Write operations into block device files are very similar to the corresponding operations on regular files. In fact, the prepare_write method of the address_space object of block device files is usually implemented by the following function:
int blkdev_prepare_write(struct file *file, struct page *page, unsigned from, unsigned to){ return block_prepare_write(page, from, to, blkdev_get_block);}
As you see, the function is simply a wrapper to the block_prepare_write( ) function already discussed in the previous section. The only difference, of course, is in the second parameter, which points to the function that must translate the file block number relative to the beginning of the file to a logical block number relative to the beginning of the block device. Remember that for block device files, the two numbers coincide. (See the earlier section Section 15.1.1.2 for a discussion of the blkdev_get_block( ) function.)
The commit_write method for block device files is implemented by the following simple wrapper function:
int blkdev_commit_write(struct file *file, struct page *page, unsigned from, unsigned to){ return block_commit_write(page, from, to);}
As you see, the commit_write method for block device files does essentially the same things as the commit_write method for regular files (we described the block_commit_write( ) function in the previous section). The only difference is that the method does not check whether the write operation has enlarged the file; you simply cannot enlarge a block device file by appending characters to its last position.