17.6 Managing Ext2 Disk Space
The storage of a file on disk differs from the view the programmer has of the file in two ways: blocks can be scattered around the disk (although the filesystem tries hard to keep blocks sequential to improve access time), and files may appear to a programmer to be bigger than they really are because a program can introduce holes into them (through the lseek( ) system call).
In this section, we explain how the Ext2 filesystem manages the disk space — how it allocates and deallocates inodes and data blocks. Two main problems must be addressed:
· Space management must make every effort to avoid file fragmentation — the physical storage of a file in several, small pieces located in nonadjacent disk blocks. File fragmentation increases the average time of sequential read operations on the files, since the disk heads must be frequently repositioned during the read operation.[2] This problem is similar to the external fragmentation of RAM discussed in Section 7.1.7.
[2] Please note that fragmenting a file across block groups (A Bad Thing) is quite different from the not-yet-implemented fragmentation of blocks to store many files in one block (A Good Thing).
· Space management must be time-efficient; that is, the kernel should be able to quickly derive from a file offset the corresponding logical block number in the Ext2 partition. In doing so, the kernel should limit as much as possible the number of accesses to addressing tables stored on disk, since each such intermediate access considerably increases the average file access time.
17.6.1 Creating Inodes
The ext2_new_inode( ) function creates an Ext2 disk inode, returning the address of the corresponding inode object (or NULL, in case of failure). It acts on two parameters: the address dir of the inode object that refers to the directory into which the new inode must be inserted and a mode that indicates the type of inode being created. The latter argument also includes an MS_SYNCHRONOUS flag that requires the current process to be suspended until the inode is allocated. The function performs the following actions:
1. Invokes new_inode( ) to allocate a new inode object and initializes its i_sb field to the superblock address stored in dir->i_sb.
2. Invokes down( ) on the s_lock semaphore included in the parent superblock. As we know, the kernel suspends the current process if the semaphore is already busy.
3. If the new inode is a directory, tries to place it so that directories are evenly scattered through partially filled block groups. In particular, allocates the new directory in the block group that has the maximum number of free blocks among all block groups that have a greater than average number of free inodes. (The average is the total number of free inodes divided by the number of block groups).
4. If the new inode is not a directory, allocates it in a block group having a free inode. The function selects the group by starting from the one that contains the parent directory and moving farther away from it; to be precise:
a. Performs a quick logarithmic search starting from the block group that includes the parent directory dir. The algorithm searches log(n) block groups, where n is the total number of block groups. The algorithm jumps further ahead until it finds an available block group — for example, if we call the number of the starting block group i, the algorithm considers block groups i mod (n), i+1 mod (n), i+1+2 mod (n), i+1+2+4 mod (n), etc.
b. If the logarithmic search failed in finding a block group with a free inode, the function performs an exhaustive linear search starting from the block group that includes the parent directory dir.
5. Invokes load_inode_bitmap( ) to get the inode bitmap of the selected block group and searches for the first null bit into it, thus obtaining the number of the first free disk inode.
6. Allocates the disk inode: sets the corresponding bit in the inode bitmap and marks the buffer containing the bitmap as dirty. Moreover, if the filesystem has been mounted specifying the MS_SYNCHRONOUS flag, invokes ll_rw_block( ) and waits until the write operation terminates (see Section 12.4.2).
7. Decrements the bg_free_inodes_count field of the group descriptor. If the new inode is a directory, increments the bg_used_dirs_count field. Marks the buffer containing the group descriptor as dirty.
8. Decrements the s_free_inodes_count field of the disk superblock and marks the buffer containing it as dirty. Sets the s_dirt field of the VFS's superblock object to 1.
9. Initializes the fields of the inode object. In particular, sets the inode number i_no and copies the value of xtime.tv_sec into i_atime, i_mtime, and i_ctime. Also loads the i_block_group field in the ext2_inode_info structure with the block group index. Refer to Table 17-3 for the meaning of these fields.
10. Inserts the new inode object into the hash table inode_hashtable and invokes mark_inode_dirty( ) to move the inode object into the superblock's dirty inode list (see Section 12.2.2).
11. Invokes up( ) on the s_lock semaphore included in the parent superblock.
12. Returns the address of the new inode object.
17.6.2 Deleting Inodes
The ext2_free_inode( ) function deletes a disk inode, which is identified by an inode object whose address is passed as the parameter. The kernel should invoke the function after a series of cleanup operations involving internal data structures and the data in the file itself. It should come after the inode object has been removed from the inode hash table, after the last hard link referring to that inode has been deleted from the proper directory and after the file is truncated to 0 length to reclaim all its data blocks (see Section 17.6.6 later in this chapter). It performs the following actions:
1. Invokes down( ) on the s_lock semaphore included in the parent superblock to get exclusive access to the superblock object.
2. Invokes clear_inode( ) to perform the following operations:
a. Invokes invalidate_inode_buffers( ) to remove the dirty buffers that belong to the inode from its i_dirty_buffers and i_dirty_data_buffers lists (see Section 14.2.1).
b. If the I_LOCK flag of the inode is set, some of the inode's buffers are involved in I/O data transfers; the function suspends the current process until these I/O data transfers terminate.
c. Invokes the clear_inode method of the superblock object, if defined; the Ext2 filesystem does not define it.
d. Sets the state of the inode to I_CLEAR (the inode object contents are no longer meaningful).
3. Computes the index of the block group containing the disk inode from the inode number and the number of inodes in each block group.
4. Invokes load_inode_bitmap( ) to get the inode bitmap.
5. Increments the bg_free_inodes_count field of the group descriptor. If the deleted inode is a directory, decrements the bg_used_dirs_count field. Marks the buffer that contains the group descriptor as dirty.
6. Increments the s_free_inodes_count field of the disk superblock and marks the buffer that contains it as dirty. Also sets the s_dirt field of the superblock object to 1.
7. Clears the bit corresponding to the disk inode in the inode bitmap and marks the buffer that contains the bitmap as dirty. Moreover, if the filesystem has been mounted with the MS_SYNCHRONIZE flag, invokes ll_rw_block( ) and waits until the write operation on the bitmap's buffer terminates.
8. Invokes up( ) on the s_lock semaphore included in the parent superblock object.
17.6.3 Data Blocks Addressing
Each nonempty regular file consists of a group of data blocks. Such blocks may be referred to either by their relative position inside the file (their file block number) or by their position inside the disk partition (their logical block number, explained in Section 13.4.4).
Deriving the logical block number of the corresponding data block from an offset f inside a file is a two-step process:
1. Derive from the offset f the file block number — the index of the block that contains the character at offset f.
2. Translate the file block number to the corresponding logical block number.
Since Unix files do not include any control characters, it is quite easy to derive the file block number containing the f th character of a file: simply take the quotient of f and the filesystem's block size and round down to the nearest integer.
For instance, let's assume a block size of 4 KB. If f is smaller than 4,096, the character is contained in the first data block of the file, which has file block number 0. If f is equal to or greater than 4,096 and less than 8,192, the character is contained in the data block that has file block number 1, and so on.
This is fine as far as file block numbers are concerned. However, translating a file block number into the corresponding logical block number is not nearly as straightforward, since the data blocks of an Ext2 file are not necessarily adjacent on disk.
The Ext2 filesystem must therefore provide a method to store the connection between each file block number and the corresponding logical block number on disk. This mapping, which goes back to early versions of Unix from AT&T, is implemented partly inside the inode. It also involves some specialized blocks that contain extra pointers, which are an inode extension used to handle large files.
The i_block field in the disk inode is an array of EXT2_N_BLOCKS components that contain logical block numbers. In the following discussion, we assume that EXT2_N_BLOCKS has the default value, namely 15. The array represents the initial part of a larger data structure, which is illustrated in Figure 17-5. As can be seen in the figure, the 15 components of the array are of 4 different types:
· The first 12 components yield the logical block numbers corresponding to the first 12 blocks of the file—to the blocks that have file block numbers from 0 to 11.
· The component at index 12 contains the logical block number of a block that represents a second-order array of logical block numbers. They correspond to the file block numbers ranging from 12 to b/4+11, where b is the filesystem's block size (each logical block number is stored in 4 bytes, so we divide by 4 in the formula). Therefore, the kernel must look in this component for a pointer to a block, and then look in that block for another pointer to the ultimate block that contains the file contents.
· The component at index 13 contains the logical block number of a block containing a second-order array of logical block numbers; in turn, the entries of this second-order array point to third-order arrays, which store the logical block numbers that correspond to the file block numbers ranging from b/4+12 to (b/4)2+(b/4)+11.
· Finally, the component at index 14 uses triple indirection: the fourth-order arrays store the logical block numbers corresponding to the file block numbers ranging from (b/4)2+(b/4)+12 to (b/4)3+(b/4)2+(b/4)+11 upward.
Figure 17-5. Data structures used to address the file's data blocks
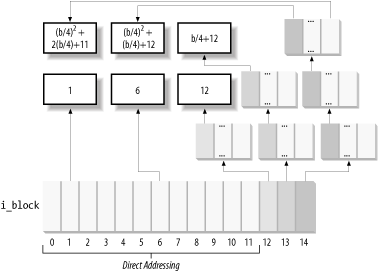
In Figure 17-5, the number inside a block represents the corresponding file block number. The arrows, which represent logical block numbers stored in array components, show how the kernel finds its way to reach the block that contains the actual contents of the file.
Notice how this mechanism favors small files. If the file does not require more than 12 data blocks, any data can be retrieved in two disk accesses: one to read a component in the i_block array of the disk inode and the other to read the requested data block. For larger files, however, three or even four consecutive disk accesses may be needed to access the required block. In practice, this is a worst-case estimate, since dentry, buffer, and page caches contribute significantly to reduce the number of real disk accesses.
Notice also how the block size of the filesystem affects the addressing mechanism, since a larger block size allows the Ext2 to store more logical block numbers inside a single block. Table 17-10 shows the upper limit placed on a file's size for each block size and each addressing mode. For instance, if the block size is 1,024 bytes and the file contains up to 268 kilobytes of data, the first 12 KB of a file can be accessed through direct mapping and the remaining 13-268 KB can be addressed through simple indirection. Files larger than 2 GB must be opened on 32-bit architectures by specifying the O_LARGEFILE opening flag. In any case, the Ext2 filesystem puts an upper limit on the file size equal to 2 TB minus 4,096 bytes.
17.6.4 File Holes
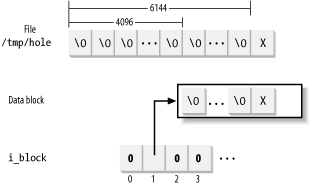
A file hole is a portion of a regular file that contains null characters and is not stored in any data block on disk. Holes are a long-standing feature of Unix files. For instance, the following Unix command creates a file in which the first bytes are a hole:
$ echo -n "X" | dd of=/tmp/hole bs=1024 seek=6
Now /tmp/hole has 6,145 characters (6,144 null characters plus an X character), yet the file occupies just one data block on disk.
File holes were introduced to avoid wasting disk space. They are used extensively by database applications and, more generally, by all applications that perform hashing on files.
The Ext2 implementation of file holes is based on dynamic data block allocation: a block is actually assigned to a file only when the process needs to write data into it. The i_size field of each inode defines the size of the file as seen by the program, including the hole, while the i_blocks field stores the number of data blocks effectively assigned to the file (in units of 512 bytes).
In our earlier example of the dd command, suppose the /tmp/hole file was created on an Ext2 partition that has blocks of size 4,096. The i_size field of the corresponding disk inode stores the number 6,145, while the i_blocks field stores the number 8 (because each 4,096-byte block includes eight 512-byte blocks). The second element of the i_block array (corresponding to the block having file block number 1) stores the logical block number of the allocated block, while all other elements in the array are null (see Figure 17-6).
Figure 17-6. A file with an initial hole
17.6.5 Allocating a Data Block
When the kernel has to locate a block holding data for an Ext2 regular file, it invokes the ext2_get_block( ) function. If the block does not exist, the function automatically allocates the block to the file. Remember that this function is invoked every time the kernel issues a read or write operation on a Ext2 regular file (see Section 15.1.1 and Section 15.1.3).
The ext2_get_block( ) function handles the data structures already described in Section 17.6.3, and when necessary, invokes the ext2_alloc_block( ) function to actually search for a free block in the Ext2 partition.
To reduce file fragmentation, the Ext2 filesystem tries to get a new block for a file near the last block already allocated for the file. Failing that, the filesystem searches for a new block in the block group that includes the file's inode. As a last resort, the free block is taken from one of the other block groups.
The Ext2 filesystem uses preallocation of data blocks. The file does not get just the requested block, but rather a group of up to eight adjacent blocks. The i_prealloc_count field in the ext2_inode_info structure stores the number of data blocks preallocated to a file that are still unused, and the i_prealloc_block field stores the logical block number of the next preallocated block to be used. Any preallocated blocks that remain unused are freed when the file is closed, when it is truncated, or when a write operation is not sequential with respect to the write operation that triggered the block preallocation.
The ext2_alloc_block( ) function receives as parameters a pointer to an inode object and a goal. The goal is a logical block number that represents the preferred position of the new block. The ext2_getblk( ) function sets the goal parameter according to the following heuristic:
1. If the block that is being allocated and the previously allocated block have consecutive file block numbers, the goal is the logical block number of the previous block plus 1; it makes sense that consecutive blocks as seen by a program should be adjacent on disk.
2. If the first rule does not apply and at least one block has been previously allocated to the file, the goal is one of these blocks' logical block numbers. More precisely, it is the logical block number of the already allocated block that precedes the block to be allocated in the file.
3. If the preceding rules do not apply, the goal is the logical block number of the first block (not necessarily free) in the block group that contains the file's inode.
The ext2_alloc_block( ) function checks whether the goal refers to one of the preallocated blocks of the file. If so, it allocates the corresponding block and returns its logical block number; otherwise, the function discards all remaining preallocated blocks and invokes ext2_new_block( ).
This latter function searches for a free block inside the Ext2 partition with the following strategy:
1. If the preferred block passed to ext2_alloc_block( ), the goal, is free, and the function allocates the block.
2. If the goal is busy, the function checks whether one of the next 64 blocks after the preferred block is free.
3. If no free block is found in the near vicinity of the preferred block, the function considers all block groups, starting from the one including the goal. For each block group, the function does the following:
a. Looks for a group of at least eight adjacent free blocks.
b. If no such group is found, looks for a single free block.
The search ends as soon as a free block is found. Before terminating, the ext2_new_block( ) function also tries to preallocate up to eight free blocks adjacent to the free block found and sets the i_prealloc_block and i_prealloc_count fields of the disk inode to the proper block location and number of blocks.
17.6.6 Releasing a Data Block
When a process deletes a file or truncates it to 0 length, all its data blocks must be reclaimed. This is done by ext2_truncate( ), which receives the address of the file's inode object as its parameter. The function essentially scans the disk inode's i_block array to locate all data blocks and all blocks used for the indirect addressing. These blocks are then released by repeatedly invoking ext2_free_blocks( ).
The ext2_free_blocks( ) function releases a group of one or more adjacent data blocks. Besides its use by ext2_truncate( ), the function is invoked mainly when discarding the preallocated blocks of a file (see the earlier section Section 17.6.5). Its parameters are:
inode
The address of the inode object that describes the file
block
The logical block number of the first block to be released
count
The number of adjacent blocks to be released
The function invokes down( ) on the s_lock superblock's semaphore to get exclusive access to the filesystem's superblock, and then performs the following actions for each block to be released:
1. Gets the block bitmap of the block group, including the block to be released
2. Clears the bit in the block bitmap that corresponds to the block to be released and marks the buffer that contains the bitmap as dirty
3. Increments the bg_free_blocks_count field in the block group descriptor and marks the corresponding buffer as dirty
4. Increments the s_free_blocks_count field of the disk superblock, marks the corresponding buffer as dirty, and sets the s_dirt flag of the superblock object
5. If the filesystem has been mounted with the MS_SYNCHRONOUS flag set, invokes ll_rw_block( ) and waits until the write operation on the bitmap's buffer terminates
Finally, the function invokes up( ) to release the superblock's s_lock semaphore.