20.1 Executable Files
Chapter 1 defined a process as an "execution context." By this we mean the collection of information needed to carry on a specific computation; it includes the pages accessed, the open files, the hardware register contents, and so on. An executable file is a regular file that describes how to initialize a new execution context (i.e., how to start a new computation).
Suppose a user wants to list the files in the current directory; he knows that this result can be simply achieved by typing the filename of the /bin/ls [1] external command at the shell prompt. The command shell forks a new process, which in turn invokes an execve( ) system call (see Section 20.4 later in this chapter), passing as one of its parameters a string that includes the full pathname for the ls executable file—/bin/ls, in this case. The sys_execve( ) service routine finds the corresponding file, checks the executable format, and modifies the execution context of the current process according to the information stored in it. As a result, when the system call terminates, the process starts executing the code stored in the executable file, which performs the directory listing.
[1] The pathnames of executable files are not fixed in Linux; they depend on the distribution used. Several standard naming schemes, such as FHS, have been proposed for all Unix systems.
When a process starts running a new program, its execution context changes drastically since most of the resources obtained during the process's previous computations are discarded. In the preceding example, when the process starts executing /bin/ls, it replaces the shell's arguments with new ones passed as parameters in the execve( ) system call and acquires a new shell environment (see the later section Section 20.1.2). All pages inherited from the parent (and shared with the Copy On Write mechanism) are released so that the new computation starts with a fresh User Mode address space; even the privileges of the process could change (see the later section Section 20.1.1). However, the process PID doesn't change, and the new computation inherits from the previous one all open file descriptors that were not closed automatically while executing the execve( ) system call.[2]
[2] By default, a file already opened by a process stays open after issuing an execve( )system call. However, the file is automatically closed if the process has set the corresponding bit in the close_on_exec field of the files_struct structure (see Table 12-7 in Chapter 12); this is done by means of the fcntl( )system call.
20.1.1 Process Credentials and Capabilities
Traditionally, Unix systems associate with each process some credentials, which bind the process to a specific user and a specific user group. Credentials are important on multiuser systems because they determine what each process can or cannot do, thus preserving both the integrity of each user's personal data and the stability of the system as a whole.
The use of credentials requires support both in the process data structure and in the resources being protected. One obvious resource is a file. Thus, in the Ext2 filesystem, each file is owned by a specific user and is bound to a group of users. The owner of a file may decide what kind of operations are allowed on that file, distinguishing among herself, the file's user group, and all other users. When a process tries to access a file, the VFS always checks whether the access is legal, according to the permissions established by the file owner and the process credentials.
The process's credentials are stored in several fields of the process descriptor, listed in Table 20-1. These fields contain identifiers of users and user groups in the system, which are usually compared with the corresponding identifiers stored in the inodes of the files being accessed.
A UID of 0 specifies the superuser (root), while a GID of 0 specifies the root group. If a process credential stores a value of 0, the kernel bypasses the permission checks and allows the privileged process to perform various actions, such as those referring to system administration or hardware manipulation, that are not possible to unprivileged processes.
When a process is created, it always inherits the credentials of its parent. However, these credentials can be modified later, either when the process starts executing a new program or when it issues suitable system calls. Usually, the uid, euid, fsuid, and suid fields of a process contain the same value. When the process executes a setuid program—that is, an executable file whose setuid flag is on—the euid and fsuid fields are set to the identifier of the file's owner. Almost all checks involve one of these two fields: fsuid is used for file-related operations, while euid is used for all other operations. Similar considerations apply to the gid, egid, fsgid, and sgid fields that refer to group identifiers.
As an illustration of how the fsuid field is used, consider the typical situation when a user wants to change his password. All passwords are stored in a common file, but he cannot directly edit this file because it is protected. Therefore, he invokes a system program named /usr/bin/passwd, which has the setuid flag set and whose owner is the superuser. When the process forked by the shell executes such a program, its euid and fsuid fields are set to 0—to the PID of the superuser. Now the process can access the file, since, when the kernel performs the access control, it finds a 0 value in fsuid. Of course, the /usr/bin/passwd program does not allow the user to do anything but change his own password.
Unix's long history teaches the lesson that setuid programs are quite dangerous: malicious users could trigger some programming errors (bugs) in the code to force setuid programs to perform operations that were never planned by the program's original designers. In the worst case, the entire system's security can be compromised. To minimize such risks, Linux, like all modern Unix systems, allows processes to acquire setuid privileges only when necessary and drop them when they are no longer needed. This feature may turn out to be useful when implementing user applications with several protection levels. The process descriptor includes an suid field, which stores the values of the effective identifiers (euid and fsuid) right after the execution of the setuid program. The process can change the effective identifiers by means of the setuid( ), setresuid( ), setfsuid( ), and setreuid( ) system calls.[3]
[3] GID effective credentials can be changed by issuing the corresponding setgid( ), setresgid( ), setfsgid( ), and setregid( ) system calls.
Table 20-2 shows how these system calls affect the process's credentials. Be warned that if the calling process does not already have superuser privileges—that is, if its euid field is not null—these system calls can be used only to set values already included in the process's credential fields. For instance, an average user process can store the value 500 into its fsuid field by invoking the setfsuid( ) system call, but only if one of the other credential fields already holds the same value.
To understand the sometimes complex relationships among the four user ID fields, consider for a moment the effects of the setuid( ) system call. The actions are different, depending on whether the calling process's euid field is set to 0 (that is, the process has superuser privileges) or to a normal UID.
If the euid field is 0, the system call sets all credential fields of the calling process (uid, euid, fsuid, and suid) to the value of the parameter e. A superuser process can thus drop its privileges and become a process owned by a normal user. This happens, for instance, when a user logs in: the system forks a new process with superuser privileges, but the process drops its privileges by invoking the setuid( ) system call and then starts executing the user's login shell program.
If the euid field is not 0, the system call modifies only the value stored in euid and fsuid, leaving the other two fields unchanged. This allows a process executing a setuid program to have its effective privileges stored in euid and fsuid set alternately to uid (the process acts as the user who launched the executable file) and to suid (the process acts as the user who owns the executable file).
20.1.1.1 Process capabilities
Linux is moving toward another model of process credentials based on the notion of "capabilities." A capability is simply a flag that asserts whether the process is allowed to perform a specific operation or a specific class of operations. This model is different from the traditional "superuser versus normal user" model in which a process can either do everything or do nothing, depending on its effective UID. As illustrated in Table 20-3, several capabilities have already been included in the Linux kernel.
Table 20-3. Linux capabilities |
|
|
Name |
Description |
|
CAP_CHOWN |
Ignore restrictions on file user and group ownership changes. |
|
CAP_DAC_OVERRIDE |
Ignore file access permissions. |
|
CAP_DAC_READ_SEARCH |
Ignore file/directory read and search permissions. |
|
CAP_FOWNER |
Generally ignore permission checks on file ownership. |
|
CAP_FSETID |
Ignore restrictions on setting the setuid and setgid flags for files. |
|
CAP_KILL |
Bypass permission checks when generating signals. |
|
CAP_IPC_LOCK |
Allow locking of pages and of shared memory segments. |
|
CAP_IPC_OWNER |
Skip IPC ownership checks. |
|
CAP_LEASE |
Allow taking of leases on files (see Section 12.7.1). |
|
CAP_LINUX_IMMUTABLE |
Allow modification of append-only and immutable Ext2/Ext3 files. |
|
CAP_MKNOD |
Allow privileged mknod( ) operations. |
|
CAP_NET_ADMIN |
Allow general networking administration. |
|
CAP_NET_BIND_SERVICE |
Allow binding to TCP/UDP sockets below 1,024. |
|
CAP_NET_BROADCAST |
Currently unused. |
|
CAP_NET_RAW |
Allow use of RAW and PACKET sockets. |
|
CAP_SETGID |
Ignore restrictions on group's process credentials manipulations. |
|
CAP_SETPCAP |
Allow capability manipulations. |
|
CAP_SETUID |
Ignore restrictions on user's process credentials manipulations. |
|
CAP_SYS_ADMIN |
Allow general system administration. |
|
CAP_SYS_BOOT |
Allow use of reboot( ). |
|
CAP_SYS_CHROOT |
Allow use of chroot( ). |
|
CAP_SYS_MODULE |
Allow inserting and removing of kernel modules. |
|
CAP_SYS_NICE |
Skip permission checks of the nice( ) and setpriority( ) system calls, and allow creation of real-time processes. |
|
CAP_SYS_PACCT |
Allow configuration of process accounting. |
|
CAP_SYS_PTRACE |
Allow use of ptrace( ) on any process. |
|
CAP_SYS_RAWIO |
Allow access to I/O ports through ioperm( ) and iopl( ). |
|
CAP_SYS_RESOURCE |
Allow resource limits to be increased. |
|
CAP_SYS_TIME |
Allow manipulation of system clock and real-time clock. |
|
CAP_SYS_TTY_CONFIG |
Allow execution of the vhangup( ) system call to configure the terminal. |
The main advantage of capabilities is that, at any time, each program needs a limited number of them. Consequently, even if a malicious user discovers a way to exploit a buggy program, she can illegally perform only a limited set of operations.
Assume, for instance, that a buggy program has only the CAP_SYS_TIME capability. In this case, the malicious user who discovers an exploitation of the bug can succeed only in illegally changing the real-time clock and the system clock. She won't be able to perform any other kind of privileged operations.
Neither the VFS nor the Ext2 filesystem currently supports the capability model, so there is no way to associate an executable file with the set of capabilities that should be enforced when a process executes that file. Nevertheless, a process can explicitly get and set its capabilities by using, respectively, the capget( ) and capset( ) system calls, provided that the process already owns the CAP_SETPCAP capability. For instance, it is possible to modify the login program to retain a subset of the capabilities and drop the others.
The Linux kernel already takes capabilities into account. Let's consider, for instance, the nice( ) system call, which allows users to change the static priority of a process. In the traditional model, only the superuser can raise a priority; the kernel should therefore check whether the euid field in the descriptor of the calling process is set to 0. However, the Linux kernel defines a capability called CAP_SYS_NICE, which corresponds exactly to this kind of operation. The kernel checks the value of this flag by invoking the capable( ) function and passing the CAP_SYS_NICE value to it.
This approach works thanks to some "compatibility hacks" that have been added to the kernel code: each time a process sets the euid and fsuid fields to 0 (either by invoking one of the system calls listed in Table 20-2 or by executing a setuid program owned by the superuser), the kernel sets all process capabilities so that all checks will succeed. When the process resets the euid and fsuid fields to the real UID of the process owner, the kernel checks the keep_capabilities flag in the process descriptor and drops all capabilities of the process if the flag is set. A process can set and reset the keep_capabilities flag by means of the Linux-specific prctl( ) system call.
20.1.2 Command-Line Arguments and Shell Environment
When a user types a command, the program that is loaded to satisfy the request may receive some command-line arguments from the shell. For example, when a user types the command:
$ ls -l /usr/bin
to get a full listing of the files in the /usr/bin directory, the shell process creates a new process to execute the command. This new process loads the /bin/ls executable file. In doing so, most of the execution context inherited from the shell is lost, but the three separate arguments ls, -l, and /usr/bin are kept. Generally, the new process may receive any number of arguments.
The conventions for passing the command-line arguments depend on the high-level language used. In the C language, the main( ) function of a program may receive as parameters an integer specifying how many arguments have been passed to the program and the address of an array of pointers to strings. The following prototype formalizes this standard:
int main(int argc, char *argv[])
Going back to the previous example, when the /bin/ls program is invoked, argc has the value 3, argv[0] points to the ls string, argv[1] points to the -l string, and argv[2] points to the /usr/bin string. The end of the argv array is always marked by a null pointer, so argv[3] contains NULL.
A third optional parameter that may be passed in the C language to the main( ) function is the parameter containing environment variables. They are used to customize the execution context of a process, to provide general information to a user or other processes, or to allow a process to keep some information across an execve( ) system call.
To use the environment variables, main( ) can be declared as follows:
int main(int argc, char *argv[], char *envp[])
The envp parameter points to an array of pointers to environment strings of the form:
VAR_NAME=something
where VAR_NAME represents the name of an environment variable, while the substring following the = delimiter represents the actual value assigned to the variable. The end of the envp array is marked by a null pointer, like the argv array. The address of the envp array is also stored in the environ global variable of the C library.
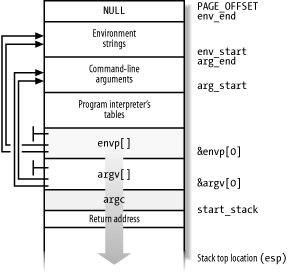
Command-line arguments and environment strings are placed on the User Mode stack, right before the return address (see Section 9.2.3). The bottom locations of the User Mode stack are illustrated in Figure 20-1. Notice that the environment variables are located near the bottom of the stack, right after a 0 long integer.
Figure 20-1. The bottom locations of the User Mode stack
20.1.3 Libraries
Each high-level source code file is transformed through several steps into an object file, which contains the machine code of the assembly language instructions corresponding to the high-level instructions. An object file cannot be executed, since it does not contain the linear address that corresponds to each reference to a name of a global symbol external to the source code file, such as functions in libraries or other source code files of the same program. The assigning, or resolution, of such addresses is performed by the linker, which collects all the object files of the program and constructs the executable file. The linker also analyzes the library's functions used by the program and glues them into the executable file in a manner described later in this chapter.
Most programs, even the most trivial ones, use libraries. Consider, for instance, the following one-line C program:
void main(void) { }
Although this program does not compute anything, a lot of work is needed to set up the execution environment (see Section 20.4 later in this chapter) and to kill the process when the program terminates (see Section 3.5). In particular, when the main( ) function terminates, the C compiler inserts an exit( ) function call in the object code.
We know from Chapter 9 that programs usually invoke system calls through wrapper routines in the C library. This holds for the C compiler too. Besides including the code directly generated by compiling the program's statements, each executable file also includes some "glue" code to handle the interactions of the User Mode process with the kernel. Portions of such glue code are stored in the C library.
Many other libraries of functions, besides the C library, are included in Unix systems. A generic Linux system could easily have 50 different libraries. Just to mention a couple of them: the math library libm includes advanced functions for floating point operations, while the X11 library libX11 collects together the basic low-level functions for the X11 Window System graphics interface.
All executable files in traditional Unix systems were based on static libraries. This means that the executable file produced by the linker includes not only the code of the original program but also the code of the library functions that the program refers to. One big disadvantage of static libraries is that they eat lots of space on disk. Indeed, each statically linked executable file duplicates some portion of library code.
Modern Unix systems use shared libraries. The executable file does not contain the library object code, but only a reference to the library name. When the program is loaded in memory for execution, a suitable program called the program interpreter (or ld.so) takes care of analyzing the library names in the executable file, locating the library in the system's directory tree and making the requested code available to the executing process. A process can also load additional shared libraries at runtime by using the dlopen( ) library function.
Shared libraries are especially convenient on systems that provide file memory mapping, since they reduce the amount of main memory requested for executing a program. When the program interpreter must link some shared library to a process, it does not copy the object code, but just performs a memory mapping of the relevant portion of the library file into the process's address space. This allows the page frames containing the machine code of the library to be shared among all processes that are using the same code.
Shared libraries also have some disadvantages. The startup time of a dynamically linked program is usually longer than that of a statically linked one. Moreover, dynamically linked programs are not as portable as statically linked ones, since they may not execute properly in systems that include a different version of the same library.
A user may always require a program to be linked statically. For example, the GCC compiler offers the -static option, which tells the linker to use the static libraries instead of the shared ones.
20.1.4 Program Segments and Process Memory Regions
The linear address space of a Unix program is traditionally partitioned, from a logical point of view, in several linear address intervals called segments:[4]
[4] The word "segment" has historical roots, since the first Unix systems implemented each linear address interval with a different segment register. Linux, however, does not rely on the segmentation mechanism of the 80 x 86 microprocessors to implement program segments.
Includes the executable code
Initialized data segment
Contains the initialized data—that is, the static variables and the global variables whose initial values are stored in the executable file (because the program must know their values at startup).
Uninitialized data segment (bss)
Contains the uninitialized data—that is, all global variables whose initial values are not stored in the executable file (because the program sets the values before referencing them); it is historically called a bss segment.
Stack segment
Contains the program stack, which includes the return addresses, parameters, and local variables of the functions being executed.
Each mm_struct memory descriptor (see Section 8.2) includes some fields that identify the role of particular memory regions of the corresponding process:
start_code, end_code
Store the initial and final linear addresses of the memory region that includes the native code of the program—the code in the executable file. Since the text segment includes shared libraries but the executable file does not, the memory region demarcated by these fields is a subset of the text segment.
start_data, end_data
Store the initial and final linear addresses of the memory region that includes the native initialized data of the program, as specified in the executable file. The fields identify a memory region that roughly corresponds to the data segment. Actually, start_data should almost always be set to the address of the first page right after end_code, and thus the field is unused. The end_data field is used, though.
start_brk, brk
Store the initial and final linear addresses of the memory region that includes the dynamically allocated memory areas of the process (see Section 8.6). This memory region is sometimes called the heap.
start_stack
Stores the address right above that of main( )'s return address; as illustrated in Figure 20-1, higher addresses are reserved (recall that stacks grow toward lower addresses).
arg_start, arg_end
Store the initial and final addresses of the stack portion containing the command-line arguments.
env_start, env_end
Store the initial and final addresses of the stack portion containing the environment strings.
Notice that shared libraries and file memory mapping have made the classification of the process's address space based on program segments a bit obsolete, since each of the shared libraries is mapped into a different memory region from those discussed in the preceding list.
Now we'll describe, by means of a simple example, how the Linux kernel maps shared libraries into the process's address space. We assume as usual that the User Mode address space ranges from 0x00000000 and 0xbfffffff. We consider the /sbin/init program, which creates and monitors the activity of all the processes that implement the outer layers of the operating system (see Section 3.4.2). The memory regions of the corresponding init process are shown in Table 20-4 (this information can be obtained from the /proc/1/maps file; you might see a different table, of course, depending on the version of the init program and how it has been compiled and linked). Notice that all regions listed are implemented by means of private memory mappings (the letter p in the Permissions column). This is not surprising because these memory regions exist only to provide data to a process. While executing instructions, a process may modify the contents of these memory regions; however, the files on disk associated with them stay unchanged. This is precisely how private memory mappings act.
The memory region starting from 0x8048000 is a memory mapping associated with the portion of the /sbin/init file ranging from byte 0 to byte 20,479 (only the start and end of the region are shown in the /proc/1/maps file, but the region size can easily be derived from them). The permissions specify that the region is executable (it contains object code), read only (it's not writable because the instructions don't change during a run), and private, so we can guess that the region maps the text segment of the program.
The memory region starting from 0x804d000 is a memory mapping associated with another portion of /sbin/init ranging from byte 16384 (corresponding to offset 0x4000 shown in Table 20-4) to 20,479. Since the permissions specify that the private region may be written, we can conclude that it maps the data segment of the program.
The next one-page memory region starting from 0x0804e000 is anonymous, that is, it is not associated with any file and includes the bss segment of init.
Similarly, the next three memory regions starting from 0x40000000, 0x40015000, and 0x40016000 correspond to the text segment, the data segment, and the bss segment, respectively, of the /lib/ld.2.2.3.so library, which is the program interpreter for the ELF shared libraries. The program interpreter is never executed alone: it is always memory-mapped inside the address space of a process executing another program.
On this system, the C library happens to be stored in the /lib/libc.2.2.3.so file. The text segment, data segment, and bss segment of the C library are mapped into the next three memory regions, starting from address 0x40020000. Remember that page frames included in private regions can be shared among several processes with the Copy On Write mechanism, as long as they are not modified. Thus, since the text segment is read-only, the page frames containing the executable code of the C library are shared among almost all currently executing processes (all except the statically linked ones).
Finally, the last anonymous memory region from 0xbfffd000 to 0xbfffffff is associated with the User Mode stack. We already explained in Section 8.4 how the stack is automatically expanded toward lower addresses whenever necessary.
20.1.5 Execution Tracing
Execution tracing is a technique that allows a program to monitor the execution of another program. The traced program can be executed step by step, until a signal is received, or until a system call is invoked. Execution tracing is widely used by debuggers, together with other techniques like the insertion of breakpoints in the debugged program and run-time access to its variables. We focus on how the kernel supports execution tracing rather than discussing how debuggers work.
In Linux, execution tracing is performed through the ptrace( ) system call, which can handle the commands listed in Table 20-5. Processes having the CAP_SYS_PTRACE capability flag set are allowed to trace any process in the system except init. Conversely, a process P with no CAP_SYS_PTRACE capability is allowed to trace only processes having the same owner as P. Moreover, a process cannot be traced by two processes at the same time.
The ptrace( ) system call modifies the p_pptr field in the descriptor of the traced process so that it points to the tracing process; therefore, the tracing process becomes the effective parent of the traced one. When execution tracing terminates—i.e., when ptrace( ) is invoked with the PTRACE_DETACH command—the system call sets p_pptr to the value of p_opptr, thus restoring the original parent of the traced process (see Section 3.2.3).
Several monitored events can be associated with a traced program:
· End of execution of a single assembly language instruction
· Entering a system call
· Exiting from a system call
· Receiving a signal
When a monitored event occurs, the traced program is stopped and a SIGCHLD signal is sent to its parent. When the parent wishes to resume the child's execution, it can use one of the PTRACE_CONT, PTRACE_SINGLESTEP, and PTRACE_SYSCALL commands, depending on the kind of event it wants to monitor.
The PTRACE_CONT command just resumes execution; the child executes until it receives another signal. This kind of tracing is implemented by means of the PT_PTRACED flag in the ptrace field of the process descriptor, which is checked by the do_signal( ) function (see Section 10.3).
The PTRACE_SINGLESTEP command forces the child process to execute the next assembly language instruction, and then stops it again. This kind of tracing is implemented on 80 x 86-based machines by means of the TF trap flag in the eflags register: when it is on, a "Debug" exception is raised right after any assembly language instruction. The corresponding exception handler just clears the flag, forces the current process to stop, and sends a SIGCHLD signal to its parent. Notice that setting the TF flag is not a privileged operation, so User Mode processes can force single-step execution even without the ptrace( ) system call. The kernel checks the PT_DTRACE flag in the process descriptor to keep track of whether the child process is being single-stepped through ptrace( ).
The PTRACE_SYSCALL command causes the traced process to resume execution until a system call is invoked. The process is stopped twice: the first time when the system call starts, and the second time when the system call terminates. This kind of tracing is implemented by means of the PT_TRACESYS flag in the processor descriptor, which is checked in the system_call( ) assembly language function (see Section 9.2.2).
A process can also be traced using some debugging features of the Intel Pentium processors. For example, the parent could set the values of the dr0, . . . dr7 debug registers for the child by using the PTRACE_POKEUSR command. When an event monitored by a debug register occurs, the CPU raises the "Debug" exception; the exception handler can then suspend the traced process and send the SIGCHLD signal to the parent.