| [ Team LiB ] |
|
17.1 DataSet XML MethodsThe ADO.NET DataSet stores information internally in a proprietary binary format that's optimized for XML representation. This means that data can be retrieved in XML format seamlessly, without any data loss or conversion errors. Table 17-1 lists the DataSet methods that work with XML. The key decision you make when dealing with the XML representation of a DataSet is deciding how to handle the schema, which defines the allowed structure and data types for the XML document. If you save the schema, you can use it as a basic form of error checking. Simply reload the schema into the DataSet before you insert any data.
Example 17-1 shows a console application that writes the retrieved XML to a file, reads it back, and then displays the XML for the retrieved DataSet using the GetXml( ) method. Note that this code doesn't provide any error handling for its file operations (i.e., the WriteXml( ) and ReadXml( ) methods). Example 17-1. Writing a DataSet to XML with a schemausing System;
using System.Data;
using System.Data.SqlClient;
public class SaveDataSet
{
private static string connectionString = "Data Source=localhost;" +
"Initial Catalog=Northwind;Integrated Security=SSPI";
public static void Main()
{
string SQL = "SELECT CategoryID, CategoryName, " +
"Description FROM Categories";
// Create ADO.NET objects.
SqlConnection con = new SqlConnection(connectionString);
SqlCommand com = new SqlCommand(SQL, con);
SqlDataAdapter adapter = new SqlDataAdapter(com);
DataSet ds = new DataSet("Nortwind");
// Execute the command.
try
{
con.Open();
adapter.FillSchema(ds, SchemaType.Mapped, "Categories");
adapter.Fill(ds, "Categories");
}
catch (Exception err)
{
Console.WriteLine(err.ToString());
}
finally
{
con.Close();
}
// Save DataSet to disk (with schema).
ds.WriteXmlSchema("mydata.xsd");
ds.WriteXml("mydata.xml");
// Reset DataSet.
ds.Reset();
// Read schema and reload data.
ds.ReadXmlSchema("mydata.xsd");
ds.ReadXml("mydata.xml");
// Display DataSet.
Console.WriteLine("DataSet retrieved.");
Console.WriteLine(ds.GetXml());
}
}
17.1.1 Dissecting the DataSet XMLThe DataSet XML follows a predefined format that follows a few simple rules:
Here's the default XML (excerpted to the first two rows) created by Example 17-1 for the Categories table: <?xml version="1.0" standalone="yes"?>
<Northwind>
<Categories>
<CategoryID>1</CategoryID>
<CategoryName>Beverages</CategoryName>
<Description>Soft drinks, coffees, teas, beers, and ales</Description>
</Categories>
<Categories>
<CategoryID>2</CategoryID>
<CategoryName>Condiments</CategoryName>
<Description>Sweet and savory sauces, relishes, spreads, and
seasonings</Description>
</Categories>
<!-- Other categories omitted. -->
</Northwind>
It's possible to modify this representation without resorting to additional code or an XSLT transform. You'll learn how you can alter the structure of the XML data with ADO.NET a little later in this chapter. 17.1.2 Dissecting the DataSet XML SchemaThe rules for the schema document are a little more subtle. First of all, a complexType is defined for each type of table row. Complex types define a structure that is composed of several separate pieces of information. In the following example, the Categories element is a complex type that contains several subtags: <?xml version="1.0" standalone="yes"?>
<xs:schema id="Northwind" xmlns=""
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata">
<xs:element name="Northwind" msdata:IsDataSet="true">
<xs:complexType>
<xs:choice maxOccurs="unbounded">
<xs:element name="Categories">
<xs:complexType>
<!-- Definition of Categories type omitted. -->
</xs:complexType>
</xs:element>
</xs:choice>
</xs:complexType>
<!-- Additional code omitted. -->
</xs:schema>
The XSD sequence element is nested inside the complexType element, indicating that the fields must occur in a set order: <xs:element name="Categories">
<xs:complexType>
<xs:sequence>
<!-- Definition of Categories type omitted. -->
</xs:sequence>
</xs:complexType>
</xs:element>
Every field in a row is declared using the corresponding XSD data type. If the field is optional (in other words, DataColumn.AllowDbNull is True), the minOccurs attribute is set to 0, indicating that this element isn't necessary. Similarly, a maxLength restriction element is added to a type if the DataColumn.MaxLength property is set. <xs:element name="Categories">
<xs:complexType>
<xs:sequence>
<xs:element name="CategoryID" msdata:ReadOnly="true"
msdata:AutoIncrement="true" type="xs:int" />
<xs:element name="CategoryName">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:maxLength value="15" />
</xs:restriction>
</xs:simpleType>
</xs:element>
<xs:element name="Description" minOccurs="0">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:maxLength value="1073741823" />
</xs:restriction>
</xs:simpleType>
</xs:element>
</xs:sequence>
</xs:complexType>
</xs:element>
Additional database-specific information is added using the msdata namespace, which allows attributes such as ReadOnly and AutoIncrement that aren't part of the XSD standard but are recognized by ADO.NET. Finally, the XSD document ends with a definition of unique elements to represent DataSet constraints. In the next snippet, a single unique element represents the primary key definition for the CategoryID field. Two XPath elements are also contained: a selector element that indicates how to find the table this constraint applies to and a field element that indicates how to find the relevant column. <xs:unique name="Constraint1" msdata:PrimaryKey="true"> <xs:selector xpath=".//Categories" /> <xs:field xpath="CategoryID" /> </xs:unique> Remember, the XSD schema is created based on the characteristics of the DataColumn and Constraint objects in the DataSet. To make sure you have as much information as possible, use the FillSchema( ) method before the WriteXmlSchema( ) method (or a strongly typed DataSet).
17.1.3 XML Write and Read ModesBy default, the WriteXml( ) method simply outputs the XML data. You must create the XSD document separately. However, you can use an overloaded version of the WriteXml( ) method, which accepts a value from the XmlWriteMode enumeration. These values are described in Table 17-2.
For example, you can choose to write the XSD inline with the XML. This shortens the coding but can waste some disk space if you store multiple DataSet files with the same schema. It can also lead to versioning problems if you modify the DataSet structure later on, and it no longer matches the schema. // Save DataSet to disk (with schema).
ds.WriteXml("mydata.xml", XmlWriteMode.WriteSchema);
// Reset the DataSet.
ds.Reset();
// Read schema and reload data.
ds.ReadXml("mydata.xml", XmlReadMode.ReadSchema);
The mydata.xml file now has the following structure: <?xml version="1.0" standalone="yes"?>
<Northwind>
<!-- Inline XSD schema document goes here. -->
<Categories>
<CategoryID>1</CategoryID>
<CategoryName>Beverages</CategoryName>
<Description>Soft drinks, coffees, teas, beers, and ales</Description>
</Categories>
<!-- Other rows omitted. -->
</Northwind>
In this case, you don't need to specify the XmlReadMode.ReadSchema when retrieving the data. The default, XmlReadMode.Auto, inspects the file and uses ReadSchema mode if it contains a schema. On the other hand, the default when saving data is XmlWriteMode.IgnoreSchema, which uses only the data. The full list of XmlWriteMode values is shown in Table 17-3.
17.1.4 Dissecting the DiffGramThe DataSet doesn't just contain schema information and a single set of data, it also tracks the state of each row and, if modified, the current and original values. In order to record this information in XML, ADO.NET defines a special DiffGram format. The DiffGram format is divided into three sections: the current data, the original data, and any errors: <?xml version="1.0"?>
<diffgr:diffgram
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"
xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1"
xmlns:xsd="http://www.w3.org/2001/XMLSchema">
<DataInstance>
</DataInstance>
<diffgr:before>
</diffgr:before>
<diffgr:errors>
</diffgr:errors>
</diffgr:diffgram>
The DataInstance element contains the actual DataSet information. Rows that have been changed are marked with the diffgr:hasChanges attribute. The diffgr:before element lists the information about the original values, while elements in diffgr:errors represent the DataRow.RowError property. Elements are matched between these three sections using the diffgr:id attribute. Example 17-2 creates a DiffGram (and displays it in a console window). The DataSet is made up of three rows retrieved from the database. The first row is modified, the second is deleted, and a fourth row is created and added programmatically. Example 17-2. Writing a DataSet DiffGramusing System;
using System.Data;
using System.Data.SqlClient;
public class SaveDiffGram
{
private static string connectionString = "Data Source=localhost;" +
"Initial Catalog=Northwind;Integrated Security=SSPI";
public static void Main()
{
string SQL = "SELECT TOP 3 CategoryID, CategoryName, " +
"Description FROM Categories";
// Create ADO.NET objects.
SqlConnection con = new SqlConnection(connectionString);
SqlCommand com = new SqlCommand(SQL, con);
SqlDataAdapter adapter = new SqlDataAdapter(com);
DataSet ds = new DataSet("Nortwind");
// Execute the command.
try
{
con.Open();
adapter.FillSchema(ds, SchemaType.Mapped, "Categories");
adapter.Fill(ds, "Categories");
}
catch (Exception err)
{
Console.WriteLine(err.ToString());
}
finally
{
con.Close();
}
// Modify the DataSet (change first row, delete second,
// and add a fourth).
DataRow row = ds.Tables["Categories"].Rows[0];
row["CategoryName"] = "Pastries";
row["Description"] = "Danishes, donuts, and coffee cake";
ds.Tables["Categories"].Rows[1].Delete();
row = ds.Tables["Categories"].NewRow();
row["CategoryName"] = "Baked goods";
row["Description"] = "Bread, croissants, and bagels";
ds.Tables["Categories"].Rows.Add(row);
// Save DataSet diffgram to disk.
ds.WriteXml("mydata.xml" , XmlWriteMode.DiffGram);
// Display DataSet diffgram.
ds.WriteXml(Console.Out , XmlWriteMode.DiffGram);
}
}
The DiffGram includes all four rows. However, the deleted row appears only in the diffgr:before section: <?xml version="1.0" standalone="yes"?>
<diffgr:diffgram
xmlns:msdata="urn:schemas-microsoft-com:xml-msdata"
xmlns:diffgr="urn:schemas-microsoft-com:xml-diffgram-v1">
<Nortwind>
<Categories diffgr:id="Categories1" msdata:rowOrder="0"
diffgr:hasChanges="modified">
<CategoryID>1</CategoryID>
<CategoryName>Pastries</CategoryName>
<Description>Danishes, donuts, and coffee cake</Description>
</Categories>
<Categories diffgr:id="Categories3" msdata:rowOrder="2">
<CategoryID>3</CategoryID>
<CategoryName>Confections</CategoryName>
<Description>Desserts, candies, and sweet breads</Description>
</Categories>
<Categories diffgr:id="Categories4" msdata:rowOrder="3"
diffgr:hasChanges="inserted">
<CategoryID>4</CategoryID>
<CategoryName>Baked goods</CategoryName>
<Description>Bread, croissants, and bagels</Description>
</Categories>
</Nortwind>
<diffgr:before>
<Categories diffgr:id="Categories1" msdata:rowOrder="0">
<CategoryID>1</CategoryID>
<CategoryName>Beverages</CategoryName>
<Description>Soft drinks, coffees, teas, beers,
and ales</Description>
</Categories>
<Categories diffgr:id="Categories2" msdata:rowOrder="1">
<CategoryID>2</CategoryID>
<CategoryName>Condiments</CategoryName>
<Description>Sweet and savory sauces, relishes, spreads, and
seasonings</Description>
</Categories>
</diffgr:before>
</diffgr:diffgram>
Without the DiffGram, the XML file resembles the first section, without the added msdata and diffgr attributes. In other words, the deleted row isn't saved, and no distinction is made between the original rows and the inserted row. When you reload the non-DiffGram XML into a DataSet, every row is set to DataRowState.Unchanged. If you tried to update the data source with this DataSet, no changes are made.
The default output generated with WriteXml( ) and WriteXmlSchema( ) includes the current contents. The DiffGram output, on the other hand, generates the information needed to use the DataSet change tracking. If you use a DataSet as a return value from a method in a web service or a component exposed through .NET remoting, the DiffGram is automatically returned. For example, consider what happens if you modify the code in Example 17-2 to become a rudimentary web service in Example 17-3. Example 17-3. A web service that returns a modified DataSet<%@ Webservice Class="ADOService" Language="C#" %>
using System;
using System.Web.Services;
using System.Data;
using System.Data.SqlClient;
public class ADOService : System.Web.Services.WebService
{
private string connectionString = "Data Source=localhost;" +
"Initial Catalog=Northwind;Integrated Security=SSPI";
[WebMethod]
public DataSet GetCategoriesTest()
{
string SQL = "SELECT TOP 3 CategoryID, CategoryName, " +
"Description FROM Categories";
// Create ADO.NET objects.
SqlConnection con = new SqlConnection(connectionString);
SqlCommand com = new SqlCommand(SQL, con);
SqlDataAdapter adapter = new SqlDataAdapter(com);
DataSet ds = new DataSet("Nortwind");
// Execute the command.
con.Open();
adapter.FillSchema(ds, SchemaType.Mapped, "Categories");
adapter.Fill(ds, "Categories");
con.Close();
// Modify the DataSet.
DataRow row = ds.Tables["Categories"].Rows[0];
row["CategoryName"] = "Pastries";
row["Description"] = "Danishes, donuts, and coffee cake";
ds.Tables["Categories"].Rows[1].Delete();
row = ds.Tables["Categories"].NewRow();
row["CategoryName"] = "Baked goods";
row["Description"] = "Bread, croissants, and bagels";
ds.Tables["Categories"].Rows.Add(row);
// Return DataSet
return ds;
}
}
If you try this web method using the Internet Explorer test page, you'll find that the retrieved result includes a schema (at the beginning of the message), followed by a DiffGram containing the DataSet contents and recording all changes Figure 17-1 shows a partially collapsed view of this information. Figure 17-1. A DataSet schema and DiffGram returned by a web method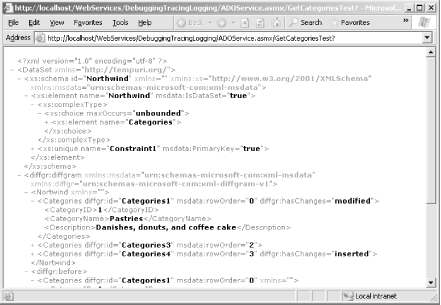 Thus, a .NET client can capture this information and automatically recreate an identical DataSet instance. A third-party client, however, needs to prepare for this information and handle it accordingly. |
| [ Team LiB ] |
|
