| [ Team LiB ] |
|
9.1 Intrasite and Intersite TopologiesTwo distinct types of replication links exist with Active Directory sites: intrasite (within sites) and intersite (between sites). An Active Directory service known as the Knowledge Consistency Checker (KCC) is responsible for automatically generating the replication links between intrasite DCs. The KCC will create intersite links automatically for you but only when an administrator has specified that two sites should be connected. Every aspect of the KCC and the links that are created is configurable, so you can manipulate what has been automatically created and what will be automatically created via manipulation of the various options. You can even disable the KCC if you wish and manually create all links. Note that there is a large distinction between the KCC (the process that runs every 15 minutes and creates the replication topology) and the replication process itself. The KCC is not involved in the regular work of replicating the actual data in any way. Intrasite replication along the links created by the KCC uses a notification process to announce that changes have occurred. So each domain controller is responsible for notifying its replication partners of changes. If no changes occur at all within a 6-hour period, the replication process is kicked off automatically anyway just to make sure. Intersite replication, on the other hand, does not use a notification process. Instead it uses a replication schedule to transfer updates, using compression to reduce the total traffic size. The KCC and the topologies it generates have been dramatically improved in Windows Server 2003 Active Directory. With Windows 2000 Active Directory, when there were more than 200 sites with domain controllers, it could take the KCC longer than 15 minutes to complete and also drive up CPU utilization. Since the KCC runs every 15 minutes, it could get backlogged or not finish. Typically when faced with this situation, administrators had to disable the KCC and manually create connection objects. With Windows Server 2003, Microsoft has stated that the new limit is closer to 5,000 sites when running a forest at the Windows Server 2003 forest functional level, which is a vast improvement. In fact, the KCC was largely rewritten in Windows Server 2003 and is much more scalable and efficient. However, we don't think as an Active Directory administrator you should just accept the topologies it creates without examining them in detail. You should investigate and understand what has been done by the KCC. If you then look over the topology and are happy with it, you have actively, rather than passively, accepted what has been done. While letting the KCC do its own thing is fine, every organization is different, and you may have requirements for the site and link design that it is not aware of and cannot build automatically. Other administrators will want to delve into the internals of Active Directory and turn off the KCC entirely, doing everything by hand. This approach is valid, as long as you know what you're doing, but we prefer to let the KCC do its work, helping it along with a guiding hand every now and then. We cover all these options in the design section later. 9.1.1 The KCCDCs within sites have links created between them by the KCC. These links use the DC's GUID as the unique identifier. These links exist in Active Directory as connection objects and use only the Directory Service Remote Procedure Call (DS-RPC) transport to replicate with one another. No other replication transport mechanism is available. However, when you need to connect two sites, you manually create a site link via the Active Directory Sites and Services MMC snap-in and specify a replication transport to use. When you do this, the Intersite Topology Generator (ISTG) automatically creates connection objects in Active Directory between domain controllers in the two sites. Within each site, an ISTG is designated to generate the intersite topology for that particular site via the KCC process. There are two replication transports to choose from when creating a site link: standard DS-RPC or Inter-Site Mechanism Simple Mail Transport Protocol (ISM-SMTP). The latter means sending updates via the mail system using certificates and encryption for security. There are two reasons that the ISTG cannot automatically create links between two sites. First, the ISTG has no idea which sites you will want to connect. Second, the ISTG does not know which replication transport protocol you will want to use. The KCC runs locally every 15 minutes on each DC. The default time period can be changed, and it can be started manually on demand if required. If we create two servers called Server A and Server B in a new domain, the KCC will run on each server to create links. Each KCC is tasked with creating a link to define incoming replication only. The KCC on Server A will define an incoming link from Server B, and Server B's KCC will define an incoming link from Server A. The KCC creates only one incoming link per replication partner, so Server A will never have two incoming links from Server B, for example. The KCC does not create one topology for all NCs, nor one topology per NC. The Configuration and Schema NCs share one replication topology, so the KCC creates a topology for these two together. The KCC also creates another topology on a per-domain basis. Because the Schema and Configuration are enterprisewide in scope, the KCC needs to replicate changes to these items across site links. The KCC needs to maintain a forestwide topology spanning all domains for these two NCs together. However, unless a domain is set up to span multiple sites, the topology for a particular domain will be made up of only intrasite connections. If the domain does span sites, the KCC needs to create a replication topology across those sites. The GC is not a Naming Context in its own right, so it can't really have its own replication topology. As the GC is formed from a selection of attributes on those servers that host the GC in each domain, the GC replication becomes part of the replication for each domain. As two partners replicate a domain NC, the GC is replicated as well. There is no replication of the GC between different domains. 9.1.2 Automatic Intrasite Topology Generation by the KCCFor each NC, the KCC builds a bidirectional ring of links between the DCs in a site. However, while upstream and downstream links are created between partners around a ring, the KCC creates links across the ring as well. It does this to make sure that it stays within the following guidelines:
Technically speaking, due to the three-hop rule, when you put in your eighth DC, the KCC will start adding branches across the circular ring. Assuming you have five servers in a ring and you add a sixth, the other servers around the ring add and delete connection objects to accommodate the newcomer. So if Server C and Server D are linked, and Server F interposes itself between them, Server C and Server D delete their interconnections and create connections to Server F instead. Server F also creates connections to Server C and Server D. Let's take a look at this process in more detail. 9.1.2.1 Two serversMycorp starts off with one DC, Server A. When Server B is promoted as the second DC for the domain, the DCPROMO process uses Server A as its source for Active Directory information for the GC, Schema, and Configuration on Server B. During the promotion process, the Configuration Container is replicated from Server A to Server B, and Server B creates the relevant incoming connection object representing Server A. Server B then informs Server A that it exists, and Server A correspondingly creates the incoming connection object representing Server B. Replication now occurs for all NCs using the connection objects. While replication occurs separately for each NC, the same connection object is used for all three at this moment. 9.1.2.2 Three serversThe DCPROMO process is later started on Server C. Server C then uses a DNS lookup and picks one of the existing DCs to use as a promotion partner. For now we'll say that it picks Server B. During the promotion process, the Configuration container is replicated from Server B to Server C, and Server C creates the relevant incoming connection object representing Server B. Server C then informs Server B that it exists, and Server B correspondingly creates the incoming connection object representing Server C. Replication now occurs for all NCs using the connection objects. At present, you have two-way links between Server A and Server B as well as between Server B and Server C. We have no links between Server A and Server C, but the KCC must create a ring topology for replication purposes. So as soon as Server B does a full replication to Server C, Server C knows about Server A from the Configuration NC. Server C's KCC then instantly creates an incoming connection object for Server A. Server A now finds out about Server C in one of two ways:
Server A now creates an incoming connection object for Server C. This completes the Server A to Server B to Server C to Server A loop. 9.1.2.3 Four serversServer D comes along, and the promotion process starts. It picks Server C to connect to. Server D ends up creating the incoming connection object for Server C. Server C also creates the incoming connection object for Server D. You now have the loop from the previous section plus a two-way link from Server C to Server D. See Figure 9-1 for this topology. Figure 9-1. Adding a fourth DC to a site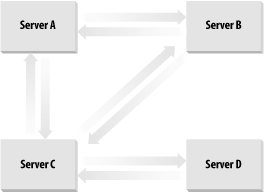 Server D's KCC now uses the newly replicated data from Server C to go through the existing topology. It knows that it has to continue the ring topology, and as it is already linked to Server C, Server D has to create an incoming connection object for one of Server C's partners. It chooses Server B in this case. So Server D's KCC creates an incoming connection object for Server B. Server D then requests changes from Server B. The rest of the process can happen in a number of ways, so we'll just play out one scenario. Server B now knows about Server D. Server B's KCC kicks into action and realizes that it doesn't need the link to Server C, so it deletes that connection and creates a new one directly to Server D itself. Finally, as replication takes place around the ring along the existing links, Server C notes that it has a now defunct incoming link from Server B and removes it. You now have a simple ring, as depicted in Figure 9-2. Figure 9-2. Ring of four DCs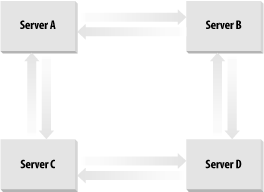 9.1.2.4 Eight serversOnce you hit eight servers connected together, you need more links across the ring if you are to maintain the three-hop rule. If you look at Figure 9-3, you will see this demonstrated. If the cross-ring links did not exist, some servers would be four hops away from one another. The KCC figures out which servers it wishes to link by allowing the last server to enter the ring to make the initial choice. Thus, if Server H is the new server in the ring, it knows that Server D is four hops away and makes a connection to it. When Server D's KCC receives the new data that Server H has linked to it, it reciprocates and creates a link to Server H. Figure 9-3. Eight servers and the extra KCC-generated links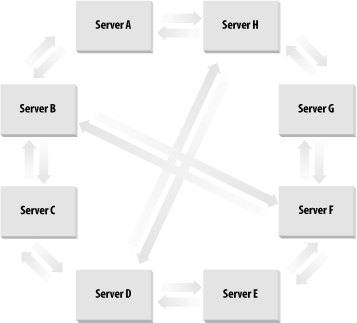 However, this doesn't completely solve the problem. Consider Server B and Server F: they're still four hops away from each other. Now the KCC creates a link between these pairs to maintain the three-hop rule. 9.1.2.5 Now what?We've now gone through the mechanism that the KCC uses for intrasite link generation between DCs. However, that's not the whole story. Remember that Active Directory can have multiple domains per site, so what happens if we add othercorp.com (a new domain in the same forest) to the same site or even sales.mycorp.com (a new child domain)? What happens then? The answer is the same for both, and it is based on NCs:
Once the two domains integrate, the KCC-generated topologies for mycorp.com and the other domain stay the same. However, the KCC-generated Configuration/Schema replication topology that exists separately on both domains will form itself into its own ring, encompassing both domains according to standard KCC rules. To summarize, when you have multiple domains in a site, each domain its own KCC-generated topology connecting its DCs, but all the DCs in the site, no matter what domain they come from, linked in a separate topology representing Schema/Configuration replication. 9.1.3 Site LinksThe Basic Building Blocks of Intersite TopologiesHaving sites is all well and good, but you need to be able to connect them if you are ever going to replicate any data. An intersite connection of this type is known as a site link. Site links are created manually by the administrator and are used to indicate that it is possible for two or more sites to replicate with each other. Site links connect more than two sites if the underlying physical network already connects multiple sites together using ATM, Frame Relay, MANs with T1 connections, or similar connections. For example, if a 64 Kbps Frame Relay network exists and is shared by multiple sites, all those sites can share a single site link. Sites do not have to be physically connected by a network for replication to occur. Replication can occur via multiple links between any two hosts from separate sites. However, for Active Directory to be able to understand that replication should be occurring between these two sites, you have to create a site link between them. Figure 9-4 shows part of a network that has two site links connecting three sites. Figure 9-4. Broken Sales domain replication over site links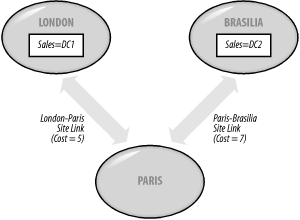 The site links correspond to the underlying physical network of two dedicated leased-line connections, with one network having a slightly higher cost than the other (not a monetary cost, but a value set by the administrator indicating the speed of the link). The Sales domain has two domain controllers that need to replicate, one in London and one in Brasilia. However, in this figure replication is broken, as the two DCs cannot directly replicate with each other over a single site link. This may seem confusing as both servers are more than likely able to see each other across the network, but you must nevertheless create a site link between sites that have DCs that need to replicate. Consider it another way. There are three ways to fix the problem. First, you could add a new Sales DC, say Sales=DC3, to Paris. This allows Sales=DC1 to replicate with Sales=DC3 and Sales=DC3 to replicate with Sales=DC2. Second, you could use a site link bridge, discussed in the next section. Third, you could create a third site link (with the combined cost of the two physical networks that will be used for the replication traffic) that indicates to the two servers that they can replicate with each other. Figure 9-5 shows that new site link in place. Figure 9-5. Working Sales domain replication over site links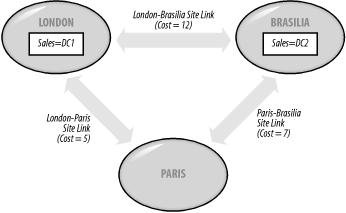 Replication of the Sales domain is now possible between Sales=DC1 and Sales=DC2. Replication traffic will go over the existing physical links, for a total cost of 12 to use those links. We've mentioned that site links have a cost, but that's not their only property. In fact, site links have four important properties:
9.1.3.1 CostAs each link has a cost, it is possible to calculate the total cost of traveling over any one route by adding up all the costs of the individual routes. If multiple routes exist between two disparate sites, the KCC will automatically identify the lowest-cost route and use that for replication. 9.1.3.2 ScheduleThe schedule on a link represents the time period that replication is allowed across that link. Servers also maintain times that they are allowed to replicate. Obviously, if two servers and a link do not have times that coincide, no replication will ever be possible. Between the scheduled start and stop times for replication on a site link, the server is available to open so-called windows for replication to occur. As soon as any server that replicates through that link becomes available for replication, a replication window is opened between the site link and that server. As soon as two servers that need to replicate with each other have two windows that coincide, replication can occur. Once a server becomes unavailable for replication, the window is removed for that server. Once the site link becomes unavailable, all windows close.
9.1.3.3 TransportSite links can currently replicate using two transport mechanisms: A site link using DS-RPC means that servers wishing to replicate using that site link can make direct synchronous connections using TCP/IP across the link. As the transport protocol is synchronous, the replication across the connection is conducted and negotiated in real time between two partners. This is the normal sort of connection for a real-time link. However, some sites may not be connected all the time. In fact, they may dial up only every half hour to send and receive email or be connected across the Internet, or they may even have a very unreliable link. This sort of link is where ISM-SMTP comes into play. The SMTP connector, as a site link using the ISM-SMTP transport is called, allows partner DCs to encrypt and email their updates to each other. In this scenario, Active Directory assumes that you already have an underlying SMTP-based connection mechanism between these two sites. If you don't, you'll have to set one up for this to work. If a connection is in place, the SMTP Connector assumes that the existing underlying mail routing structure will sort out how mail is transferred. To that end, a site link using the SMTP Connector ignores the scheduling tab, as it will send and receive updates automatically via the underlying system whenever the email system sends and receives them itself. SMTP Connector messages are encrypted using digital signatures, so to encrypt the messages, you need to install the optional Certificate Server service and obtain your own digital signature for your organization.
9.1.3.4 When the KCC becomes involvedWhen you have two sites that you want to connect, you have two options. You can manually create a site link between them, at which point the KCC will automatically connect together one DC from each site. The KCC will automatically select the DCs and create the relevant incoming connection objects for both servers. Alternatively, you can create the incoming connection objects manually in Active Directory using the Sites and Services snap-in. The two DCs that link two sites, no matter how the connection objects are created, are known as bridgehead servers. The KCC actively uses site link costs to identify which routes it should be using for replication purposes. If a stable series of site links exists in an organization, and a new route is added with a lower cost, the KCC will switch over to use the new link where appropriate and delete the old link. The network of connections that the KCC creates is known as a minimum-cost-spanning tree. 9.1.3.5 Having the KCC compound your mistakesIf you make a mistake with site link costs, you can cause network problems very quickly. For this reason, you need to be aware of what the KCC is doing. If you bring up a new site link with a very high cost, say 50, and you accidentally leave off the zero, the route cost of 5 for the new site link may cause the KCCs on all DCs to suddenly reorganize the links to route through your new slow link. Your link becomes saturated, and your servers replicate much more slowly, if at all, over the slow link. In fact, the KCC didn't make the mistake, but it has compounded it by following its algorithm. If a real cost-5 link were introduced that represented a real cost saving over many other routes, it is the KCC's job to switch over and use that link. That's why you always need to check your data for the intersite replication topology carefully. While it's difficult to guard against occassionally making a mistake like this, no matter how careful an administrator you are, if you understand how the KCC works, you can use this information to debug potential problems much more rapidly. 9.1.4 Site Link BridgesThe Second Building Blocks of Intersite TopologiesWhile site links are used to indicate that replication can take place between two sites, site link bridges indicate that replication is possible between two sites that don't have a direct site link. Site link bridges can be created automatically by the KCC, or they can be created manually. When a bridge is created, certain specified site links become members of that bridge and are designated as being interconnected (or bridged) for replication purposes. The bridge knows how these sites are connected, so you could specify, for example, that this site link bridge bridged the London-Paris link and the Paris-Brasilia link. Then servers in Brasilia or London will see that a replication connection is now possible via the site link bridge, and the site link bridge will know that for traffic to get from London to Brasilia, it must use the London-Paris and then Paris-Brasilia links, in that order. Figure 9-6 demonstrates this in action. Figure 9-6. Working Sales domain replication using a site link bridge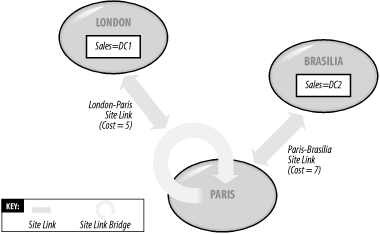 The point here is that a site link bridge knows how the site links in its care are interconnected and thus how to route requests from one site through to another along its network of site links. For a more complex example, consider the network of site links corresponding to physical networks in Figure 9-7. Figure 9-7. A network of site links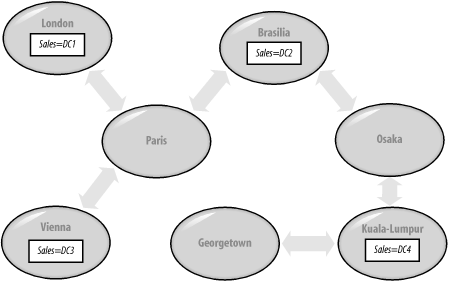 If you had to connect all four DCs using only site links, you would have to manually connect London and Vienna to Brasilia using something like Vienna-London and London-Brasilia (although that isn't the only solution) and then connect Brasilia-Kuala Lumpur. However, with a site link bridge, you could bridge every site link except Kuala Lumpur to Georgetown (capital of the Pulau-Pinang province in Malaysia, by the way). Bridging all the links except this one tells the servers in those sites that are bridged that they can replicate to any sites that are bridged over the existing site links. So when Vienna wishes to replicate to Kuala Lumpur, the site link bridge knows that the traffic should go from Vienna to Paris to Brasilia to Osaka and finally to Kuala Lumpur. Bridging the Kuala Lumpur-Georgetown site link would probably make sense, but in this example there is no need, as no Sales domain servers currently exist in that site. There are a number of reasons why site link bridges make great sense:
Now that you've seen the site links and site link bridges, let's look at how to design your sites and their replication links. |
| [ Team LiB ] |
|
