
|
|
|
The Origins of Regular ExpressionsWhere did regular expressions come from and why the funny name? Rather interestingly, they grew from original research work on artificial intelligence, dating back nearly 60 years and preceding the era of computing. The Early HistoryIn the 1940s, Warren McCulloch and Walter Pitts modeled neuron-like finite state machines to mimic the human nervous system in an effort to help build a Turing machine. After being introduced to this research by John von Neumann, mathematician Stephen Kleene later described these models in a notation that he called regular sets. The actual term regular expression made its initial debut in Kleene's 1951 paper, from the University of Wisconsin at Madison, titled "Representation of events in nerve nets and finite automata." Regexes supplemented Kleene's Princeton University doctoral work, dating from the 1930s, on recursive algorithms,[1] a fundamental contribution which helped make electronic computing directly possible in the first place. Kleene's work also complemented related work by the more famous British scientist Alan Turing, who like Kleene was a doctoral student (1936-1938) of Professor Alonzo Church, the enigmatic head of Princeton's mathematics department. Church himself had extended the earlier recursive work of Vienna's Gödel, who'd briefly lectured Kleene at Princeton in 1934 before returning to Austria. Gödel later escaped from Hitler's Germany and came back to Princeton in 1940, via Russia and Japan, after World War II broke out. After Turing completed his own doctorate, and some hurried studies on ciphers, he returned to England in 1938 to successfully crack the Nazi's ENIGMA code via the use of repetitive symbolic manipulations. In these various ways, an early form of regular expressions grew from the mathematical culture dish of Princeton.
After the war ended, research continued towards regular expressions proper and the creation of their backbone components. The most famous of these is the asterisk wildcard, still technically known as the Kleene Star, which was heavily adopted by many different computing applications. From these beginnings, Kleene's regular expressions gradually made their way into a wide range of programming languages, helping develop many other different technologies along the way. qed, ed, and viJumping ahead a number of decades, MIT's Ken Thompson incorporated Kleene's regular sets notation into Butler Lampson and Peter Deutsch's original Berkeley qed editor program. This was the distant ancestor of Thompson's ed and Bill Joy's personal interpretation of vi. With the help of Dennis Ritchie, regexes were also popularized via the Unix grep program, and from this historical point, regexes inveigled their way into sed, lex, awk, nawk, gawk, and a host of other programs, including the venerable CHANGE command line editor within SQL*Plus. Enter PerlWhen Perl bubbled spontaneously from its primeval soup in 1987, consisting mainly of amino acids stripped from sed and awk, the rest was pure biological determinism, swimming along in the moonlight with the general tide of Unix. If you add Larry Wall's linguistic origins to this tidal churn, the strong relationship between Perl and regexes was an almost inevitable development (or a successful pre-adaptation, as Darwinist Stephen J. Gould might have put it). And the relationship with regexes has remained central to Perl ever since, as Figure C-1 illustrates. Perl vs. grepRegular expressions are found within many Unix tools to pattern-match groups of characters within input data. Such data usually comes in through files, though it can be any kind of data held within a scalar zvariable. Although many such tools exist for example, grep and awk[2] for finding patterns of characters, it's within Perl that pattern matching has been most strongly developed. Perl contains the greatest range of operators and metacharacters for finding and substituting patterns into something else. Compared to grep, regexes in Perl have three major advantages:
Figure C-1. Languages within languages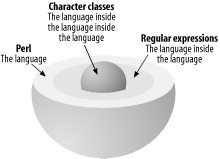 |
|
|
|