What Is Data Munging?
Data
munging means taking data that's stored
in one format and changing it into another format. The term
"data munging" has an ironically
mixed etymological origin. The following definition is taken from
version 4.3.0 of the Jargon file:
munge /muhnj/ vt.
1. [derogatory] To imperfectly transform information. 2. A
comprehensive rewrite of a routine, data structure or the whole
program. 3. To modify data in some way the speaker
doesn't need to go into right now or cannot describe
succinctly (compare mumble). 4. To add
spamblock to an email address.
This term is often confused with mung, which
probably was derived from it. However, it also appears the word
`munge' was in common use in
Scotland in the 1940s, and in Yorkshire in the 1950s, as a verb,
meaning to munch up into a masticated mess, and as a noun, meaning
the result of munging something up (the parallel with the
kluge/kludge pair is
amusing). The OED reports `munge' as an
archaic verb meaning "to wipe (a
person's nose)".
Perl, with its excellent text-processing capabilities and high
performance, is ideally suited to the task of data munging. In this
chapter we'll focus on those munging capabilities
most relevant to processing Oracle data. If you want to learn more,
we recommend the book, Data Munging With Perl,
by David Cross (Manning, 2001), which we've found to
be invaluable in our own data-munging
efforts:
How Data Munging Works
Figure D-1 illustrates
graphically how data munging works. As shown in the figure, there are
several distinct components and steps involved in a data-munging
operation:
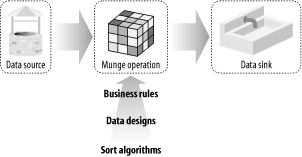
- The data source
-
On one side of the munging equation is our data source, or initial
wellspring of data. This can be anything from a raw binary file to a
stream of digital output from a remote MySQL database. Because Perl
was designed from the start to be one of the fastest text-processing
languages available, it is able to process and transform data at a
very high speed. For this reason, Perl is an ideal language for data
munging.
- The munge operation
-
Once the source data is extracted, we begin our munge operation. This
operation can be any kind of transformation. We can reverse data,
expand data, and recombine data. We can munge it through regular
expressions or sprintf style commands, as in
Appendix C, or we can parse it through complex data
trees. Although Perl abounds with such techniques, there are three
controlling paradigms:
- Sort algorithms
-
Some of the world's brightest mathematicians have
created sort algorithms, and all of these algorithms can be
programmed in Perl. The language is also packed with built-in
commands, such as sort and
map, and Perl-specific sort techniques, such as
the Schwartzian transform.
- Data structure and design
-
The central munge operation must be able to represent the data
structures for both the source and the sink (which is essentially the
destination), no matter how complex. It must also be able to
transform data from one structure into the other. Because
Perl's referenced structures are virtually unbounded
in extent, Perl is a perfect language for handling such
transformations.
- Business rules
-
We can easily encapsulate business rules within Perl modules, and can
thus provide reusable, business-specific data transformations.
- The data sink
-
Our transformed data is finally deposited within a chosen data sink.
A data sink works conceptually the same way as a
"heat sink" does in engineering; it
sucks away the final output from a processing operation. In data
munging, this output is the final data generated, rather than the
unwanted "heat" in the process. (In
engineering, the heat would be generated by a piece of electrical
equipment such as a satellite or a laptop computer.)
The Art of Algorithms
There are legions of algorithms used
with data munging. The most venerable source for all of them is
Donald Knuth's The Art of Computer
Programming, volumes 1-3 (Addison-Wesley, 1998). Professor
Knuth began writing this magnum opus in 1962,
and it is divided into several volumes as follows:
- Volume 1: Fundamental Algorithms
- Volume 2: Seminumerical Algorithms
- Volume 3: Sorting and Searching
We make use of his Soundex algorithm, from
volume 3, later in this appendix, and you can check out Professor
Knuth's own home page here:
- http://www-cs-faculty.stanford.edu/~knuth
Those who already have volumes 1 through 3 will be happy to know that
Professor Knuth is also aiming to complete the following volumes:
- Volume 4: Combinatorial Algorithms
- Volume 5: Syntactic Algorithms
For a more Perl-based approach, check out the following excellent
book, written by several of the main authors behind
perldoc:
- Mastering Algorithms with Perl, by Jon
Orwant, John Macdonald, and Jarkko Hietaniemi (O'Reilly &
Associates, 1999)
Enter the Real World
You may have spotted a problem with Figure D-1.
Yes, it's just too spotless and
clean for the real world. One data source, one munge operation, and
one data sink. How convenient. If you've ever
carried out telecom call transfers, share deal transfers, or any
other major corporate data transfer, you'll know
that data-munging operations often tend to look a bit more like Figure D-2.
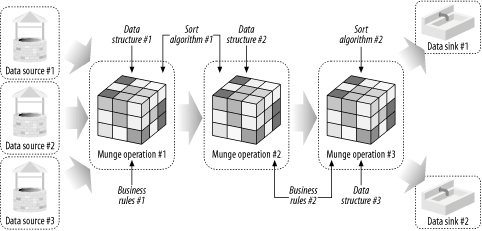
But this is no problem for Perl. Although Figure D-2 is complex, that's just fine,
because Perl is also designed to be complex. That allows it to map
itself to the real world's necessary complexity. Or,
in the words of Mr. Wall himself:
You have a deep desire to turn the complex into the simple, and Perl
is just another tool to help you do that just as I am using
English right now to try to simplify reality. I can use English for
that because English is a mess.
This is important, and a little hard to understand. English is useful
because it's a mess. Since
English is a mess, it maps well onto the problem space, which is also
a mess, which we call reality. Similarly, Perl was designed to be a
mess (though in the nicest of possible ways).
This is counterintuitive, so let me explain. If
you've been educated as any kind of an engineer, it
has been pounded into your skull that great engineering is simple
engineering. We are taught to admire suspension bridges more than
railroad trestles. We are taught to value simplicity and beauty.
That's nice. I like circles too.
However, complexity is not always the enemy. What's
important is not simplicity or complexity, but how you bridge the
two.
In the next section, we'll take a look at a
real-world Oracle data transfer and illustrate how Perl can help
munge the data. We'll later point you towards the
many Perl modules that you can use to invoke the specific conversion
or formatting operations you need in order to transform your data
appropriately.
|
