13.1 Modifying a Script in the Toolkit
Let's look at
a typical task you'll often perform as part of your
Oracle database administration duties: checking on the jobs scheduled
via Oracle's built-in scheduling package, DBMS_JOBS.
First, we'll see how DBAs typically check on these
jobs by examining the DBA_JOBS data dictionary view. Then
we'll take a look at a script we've
developed to make your checking easier and more efficient. And
finally we'll make a few modifications to that
script and its supporting files in order to demonstrate how easy it
can be to customize and extend the scripts in our toolkit.
13.1.1 The Standard Approach
The Oracle job scheduler is easy to use. You submit a PL/SQL job and
Oracle runs it at specified intervals. Here's a
short example that illustrates how it works:
The ANALYZE_SCOTT procedure will analyze all of
SCOTT's objects at 3:00 AM each morning. We create
it like this:
create or replace procedure analyze_scott
is
begin
dbms_utility.analyze_schema('SCOTT','COMPUTE');
end;
/
show errors procedure analyze_scottThen we submit the job: declare
jobno integer;
begin
dbms_job.submit(
job => jobno
, what => 'analyze_scott;'
, next_date => (sysdate + ( 1/1440)) /* Start in 1 min */
, interval => '(trunc(sysdate) + 1) + (3/24)' /* Then at 3AM */
);
commit;
end;
/The following SQL on the DBA_JOBS view tells you which jobs are
scheduled:
select schema_user, job, last_date, next_date, broken,
interval, failures, what
from dba_jobs
order by schema_user, next_date;Our newly created procedure appears like this: USER JOB LAST DATE NEXT DATE B INTERVAL FAILURES WHAT
----- --- ------------ ------------ - ----------- -------- --------------
SCOTT 42 mar-17 15:50 mar-18 03:00 N (trunc(sys 0 analyze_scott;
date) + 1)
+ (3/24)
1 row selected.
That's pretty easy. And if you're
checking on only a handful of jobs in one or two databases, this
approach works just fine. It becomes unwieldy, however, if you need
to check a large number of databases on a regular basis.
13.1.2 Checking on Scheduled Jobs with the dba_jobsm.pl Script
We've provided a script in
our toolkit that makes checking on scheduled jobs a lot more flexible
and efficient. Using the dba_jobsm.pl script,
you can check on several databases in succession and combine the
output into a single report. The script can also email this report to
us so we can easily scan it for BROKEN jobs. (A Y in
DBA_JOBS's BROKEN column indicates that a job has
failed 16 times or has been manually disabled via
DBMS_JOB's BROKEN procedure.)
13.1.2.1 Configuring dba_jobsm.pl
The
dba_jobsm.pl script is installed automatically
when you install the toolkit (see Chapter 9).
You'll find it in Perl's script
installation directory. On Unix systems, this is
/usr/local/bin/ (or another location, depending on your
chosen install configuration). It will also be found in the PDBA
installation directory:
- PDBA-1.00/routine_tasks/dba_jobsm.pl
On Win32, you'll find the script as
C:\Perl\bin\dba_jobsm.pl.
There is also a configuration file that stores the parameters for
the dba_jobsm.pl script (see Example 13-1). On Unix, the
dba_jobs.conf configuration file is:
- PDBA-1.00/routine_tasks/dba_jobs.conf
On Win32 it is:
- C:\Perl\site\lib\PDBA\conf\dba_jobs.conf
Example 13-1. dba_jobs.conf
package dbajobs;
use vars qw{ $emailAddresses %databases };
$emailAddresses = [qw{[email protected]}];
%databases = ( sherlock => { ts01 => 'system', },
watson => { ts98 => 'system', ts99 => 'system', } );
1;
The
configuration file is very straightforward. It contains two hashes:
one for the email address to which the final report will be sent, and
one for the servers we wish to check, broken down by machine and
database.
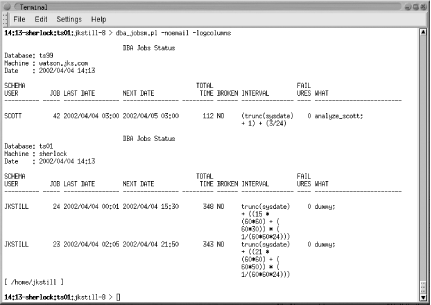
An example of a final report
generated by this script is displayed in Figure 13-1; this particular example was generated with
the -noemail option specified.
13.1.2.2 dba_jobsm.pl: A walkthrough of the main script
The following may look daunting, but we
thought we'd walk through at least one complete PDBA
Toolkit script in this book, just to show you its low-level wiring.
We expect that some readers will find sufficient inspiration in these
pages (or frustration with our code) to decide to customize our
scripts or create their own. When creating your own scripts, you can
treat ours as something of an artist's palette from
which you can cut and paste the elements you require.
With that rationalization out of the way, let's
plunge into a no-holds-barred familiarization exercise before you
embark on your own missions into no-man's-land.
We'll focus on one group of lines at a time.
01: #!/usr/bin/perl
02:
03: =head1 dba_jobsm.pl
04:
05: like dba_jobs.pl, but connects to multiple servers
06: as specified in the configuration file
07:
08: =cut
09:
10: use warnings;
11: use strict;
12: use PDBA;
13: use PDBA::CM;
14: use PDBA::GQ;
15: use PDBA::OPT;
16: use PDBA::ConfigFile;
17: use PDBA::LogFile;
18: use Getopt::Long;
- Line 1
-
Informs the command shell that this script runs with the
/usr/bin/perl binary program. The
#! shebang is recognized by Unix command shells
as an identifier indicating which executable to run the script with.
This magic cookie, as it's
sometimes known, must be on line 1. On Win32 the
#! line is simply treated as just another
comment.
- Lines 3 to 8
-
Inline documentation. (The perldoc
FULL_PATH/dba_jobsm.pl command displays all of the
documentation.)
- Lines 10 to 18
-
Specify the modules needed for this script:
- use warnings
-
Makes Perl detect and flag program warnings as well as errors.
Alternatively, use the -w flag switch on line 1.
(We'll show an example a bit later.)
- use strict
-
Enforces coding discipline. For instance, you must name package
variables explicitly. (See Appendix A, for
information about variable scoping.)
The next few lines load up the necessary PDBA Toolkit modules; these
include the PDBA mother-ship module, the Connection Manager, the
Generic Query module, the Options password retriever, the Config File
loader, and the Log File creator. (See Chapter 9
for a discussion of all these modules.)
- Line 20
-
Sets the date format for retrieving date columns from Oracle.
(We'll say more about configuring this in a later
section.)
- Line 22
-
Declares our intended use of the %optctl hash.
- Line 26
-
Sets the pass-through option for Getopt::Long.
We can then specify extra options via the command line to pass
through to PDBA::OPT. Example 13-2 demonstrates why we need this.
Example 13-2. passthrough.pl
#!/usr/bin/perl -w
use Getopt::Long;
my %optctl=( );
Getopt::Long::Configure(qw{pass_through});
GetOptions( \%optctl, "database=s", "username=s",);
print join(":", @ARGV);
The following script call processes the command line options created
by GetOptions, including
database and username, and
leaves the -pwc_conf option and its argument in
the @ARGV program parameters array printed by
passthrough.pl:
$ passthrough.pl -database orcl -username system -pwc_conf test.conf
-pwc_conf:test.conf
If you remove the pass_through directive,
GetOptions raises an error, because the
-pwc_conf flag is unspecified, unlike
database and username.
$ passthrough.pl -database orcl -username system -pwc_conf test.conf
Unknown option: pwc_conf
test.conf
Let's continue with the next group of lines in
dba_jobsm.pl:
28: GetOptions( \%optctl,
29: "help!",
30: "conf=s",
31: "confpath=s",
32: "logfile=s",
33: "logcolumns!",
34: "email!",
35: "verbose!",
36: "debug!",
37: );
- Lines 28 to 37
-
Calls the GetOptions function from the
Getopt::Long module, passing the expected
command line option names and processing them as they appear on the
command line. Those specified with =s, such as
conf=s, require an argument. The following
command makes Getopt::Long assign the string
-logfile as the argument to
-conf. This is because
-conf explicitly requires an argument:
$ dba_jobsm.pl -conf -logfile test.log
Unknown exception from user code:
Could not load config file -logfile
A configured exclamation point following a
GetOptions parameter, such as
email!, tells Getopt::Long
the option is a Boolean switch (1 or 0). These options switch to
false with a no prefix, as in
dba_jobs.pl -conf dbatest.conf -noemail. (For
much more on Getopt::Long, try perldoc
Getopt::Long.)
39: if ( $optctl{help} ) { usage(1) }
- Line 39
-
Employs the usage subroutine.
We'll discuss this in lines 212-229.
Let's move on to the next group of lines:
41: # config is required
42: my $configFile = $optctl{conf}
43: ? $optctl{conf}
44: : 'dba_jobs.conf';
- Lines 42 to 44
-
Determine which configuration file to use. If the expression before
? is true, the expression following
? is returned. If the expression before
? is false, the expression following
: is returned. Therefore, if the
-conf option value fills
$optctl{conf}, line 43 assigns this value to
$configFile. Otherwise, line 44 assigns it to a
default of dba_jobs.conf.
46: # load the configuration file
47: unless (
48: new PDBA::ConfigLoad(
49: FILE => $configFile,
50: DEBUG => $optctl{debug},
51: PATH => $optctl{confpath},
52: )
53: ) {
54: die "could not load config file $configFile\n";
55: }
- Lines 46 to 55
-
Load the configuration file. Lines 48 to 52 invoke
PDBA::ConfigLoad's
new method, passing values for FILE, DEBUG, and PATH. The
PDBA::ConfigLoad module ignores PATH if it is
undefined or if it is an empty string. If the configuration file
fails to load, the program exits on line 54 with a
die command.
57: # setup and open the log file
58: my $logFile = $optctl{logfile}
59: ? $optctl{logfile}
60: : PDBA->pdbaHome . q{/logs/dba_jobsm.log};
61:
62: my $logFh = new PDBA::LogFile($logFile);
- Lines 57 to 60
-
Determine the name and location of the logfile. As with the
configuration file, the name is supplied by the -logfile
option. The default dba_jobsm.log
file is placed in PDBA_HOME/logs directory.
(Note that the forward slash is acceptable to Win32, which uses it
internally anyway.)
- Line 62
-
Creates a new PDBA::LogFile
object, $logFh, and the program writes to this
object handle when sending audit messages to the logfile.
64: if ( $optctl{debug} ) {
65:
66: foreach my $machine ( keys %dbajobs::databases ) {
67: print "machine: $machine\n";
68: foreach my $database ( keys %{$dbajobs::databases{$machine}} ) {
69: print "\tdb: $database\n";
70: print
"\t\tusername: $dbajobs::databases{$machine}->{$database}\n";
71: }
72: }
73: exit;
74: }
- Lines 64 to 74
-
Execute only if the -debug program option is
specified. Line 66 sets up a loop which iterates through each
$machine in the
%dbajobs::databases hash. This is loaded from
the configuration file, with each machine, database, and username
being printed to the screen.
76: my $instanceName = undef;
77: my $machineName = undef;
78: my $systemDate = undef;
79: my $row = {};
80: my $tmpFile;
- Lines 76 to 80
-
Simply declare some variables for later use.
82: if ($optctl{email}) {
83:
84: use POSIX;
85:
86: if ( 'unix' eq PDBA->osname ) {
87: $tmpFile = POSIX::tmpnam( );
88: } else {
89: $tmpFile = 'C:\TEMP' . POSIX::tmpnam( ) . 'tmp';
90: }
91:
92: print "TMPFILE: $tmpFile\n" if $optctl{verbose};
93:
94: open(FILE,"> $tmpFile") || die "cannot create $tmpFile\n";
95: select(FILE);
96:
97: # reset the format and format_top names, as using select(FILE)
98: # will cause Perl to look for FILE and FILE_TOP
99: $~ = 'STDOUT';
100: $^ = 'STDOUT_TOP';
101:
102: }
- Line 82
-
Gatekeeper for the next code body. It only runs if the
-email flag was set.
- Line 84
-
Loads the POSIX module because we need a
temporary file for email formatting purposes later on.
- Lines 86 to 90
-
Name this temporary file via the POSIX::tmpnam
function. On Unix, this defaults to something like
/tmp/fileiZZd123. On Win32,
POSIX::tmpname returns a
\random_value. string. We want all of our
temporary files stored in the same location on Win32, and we ensure
this on line 89. If POSIX::tmpnam returns a
filename of \wpo., this is converted into
C:\TEMP\wpo.tmp.
- Line 94
-
Creates and opens the temporary file.
- Line 95
-
Uses Perl's main select
operator and sets the default output filehandle to be the temporary
file. All write and print
statements without specific filehandle parameters will now go to the
temporary file.
- Lines 99 to 100
-
Set the print format names for the write
operator. The $^ built-in Perl variable sets the
name for the header format. The $~ variable sets
the equivalent for the body format.
 |
You can avoid using built-in Perl variable names like
$~ and $^ if you use the
English module. This makes all such variables
readable to English speakers:
use English;
# Use English names so your code won't
# look like an obscure Klingon dialect! :-)
$FORMAT_TOP_NAME = 'STDOUT_TOP'; # $~
$FORMAT_TOP = 'STDOUT'; # $^
For more information about such variables, invoke perldoc
perlvar.
The default names for these are STDOUT and
STDOUT_TOP, which is what our code uses too. The
default usually works fine for console output, but when we changed
our default filehandle to FILE the default
formats changed too, into FILE and
FILE_TOP. Because we still want to use
STDOUT and STDOUT_TOP, we
need to explicitly reset them both back again.
|
|
104: foreach my $machine ( keys %dbajobs::databases ) {
105:
106: foreach my $database ( keys %{$dbajobs::databases{$machine}} ) {
107:
108: my $username = $dbajobs::databases{$machine}->{$database};
109:
110: # retrieve the password from the password server
111: my $password = PDBA::OPT->pwcOptions (
112: INSTANCE => $database,
113: MACHINE => $machine,
114: USERNAME => $username
115: );
- Line 104
-
Begins the loop where the real work begins. As with line 66, this
line begins looping through the machines defined in the configuration
file.
- Line 106
-
Iterates through each database as defined for each machine.
- Line 108
-
Retrieves the current loop iteration's DBA username.
- Lines 111 to 115
-
Retrieve the password for the username from the password server. (You
could modify the dba_jobsm.pl script to avoid
using the password server, but this would require a fair amount of
work and would also necessitate giving up all the security and
ease-of-use the server delivers. However, we will demonstrate how
this is possible in a later section.)
117: # create a database connection
118: my $dbh = new PDBA::CM(
119: DATABASE => $database,
120: USERNAME => $username,
121: PASSWORD => $password,
122: );
123:
124: $dbh->do(qq{alter session set nls_date_format = '$nlsDateFormat'});
- Lines 117 to 122
-
Create the database connection via
PDBA::CM's Connection Manager.
One of the advantages of using PDBA::CM, rather
than DBI, is the use of the cm.conf
configuration file. This contains a default
ORACLE_HOME value that sets the
$ENV{ORACLE_HOME} environment variable, making
it unnecessary to set the Oracle environment before running a script.
- Line 124
-
Sets NLS_DATE_FORMAT for your current database session.
126: # get the host and instance name
127: my $gn = new PDBA::GQ($dbh,'v$instance');
128: my $gnHash = $gn->next;
129: $instanceName = $gnHash->{INSTANCE_NAME};
130: $machineName = $gnHash->{HOST_NAME};
131: undef $gn;
132: undef $gnHash;
133:
134: print "Instance Name: $instanceName\n" if $optctl{verbose};
135: print "Host Name: $machineName\n" if $optctl{verbose};
136:
137: # get the system date
138: $systemDate = PDBA->sysdate($dbh, NLS_DATE_FORMAT => $nlsDateFormat);
139: print "System Date: $systemDate\n" if $optctl{verbose};
- Line 127
-
Uses PDBA::GQ to execute a SQL statement of
select * from v$instance. The
PDBA::GQ module also prepares the SQL statement.
Because we failed to specify any columns, it assumes we want all of
them. To select specific columns you can use
PDBA::GQ like this:
my $gn = new PDBA::GQ($dbh,'$v$instance',
{ COLUMNS => [qw(host_name instance_name)] } );
- Line 128
-
Retrieves the first row from query object $gn
via PDBA::GQ's
next method. Its default return value is a hash
reference. On lines 129 and 130 we assign
$instanceName and
$machineName. The sharp-eyed among you may be
wondering why we haven't followed line 128 with the
following:
$gn->finish;
All open cursors must be finished before database disconnection.
Fortunately V$INSTANCE only holds one row, so the
$gn cursor finished automatically.
- Lines 131 to 132
-
Undefine $gn and $gnHash,
as we're done with them in this particular loop
iteration and we should clear them out before the next one.
- Line 138
-
Sets $systemDate to the current database SYSDATE
value.
141: my $gq = new PDBA::GQ ( $dbh, 'dba_jobs',
142: {
143: COLUMNS => [
144: qw(schema_user job last_date next_date
interval failures what),
145: q{round(total_time,2) total_time},
146: q{decode(broken,'N','NO','Y','YES','UNKNOWN') broken},
147: ],
148: ORDER_BY => q{schema_user, next_date}
149: }
150: );
- Line 141
-
Begins a complex instantiation of a database query via
PDBA::GQ.
- Line 143
-
Begins specifying the columns to include in the query.
|
There is a difference between the q{} and
qq{} operators. They're
identical in use to either single quotes
(` ') or
double quotes ("
") in Perl. Variables only interpolate
within the qq{} braces. For instance,
let's run the following code:
my $str = 'this is Earth calling';
print qq{$str\n};
print q{$str\n};
The second printed line remains uninterpolated:
this is Earth calling
$str\n
The use of these and other quoting functions such as
qw{} makes Perl code formatting much plainer to
the eye. Check out perldoc perlop for much more
detail.
|
|
- Lines 145 to 146
-
Perform column manipulation. We use Oracle's ROUND
function to format TOTAL_TIME, and its DECODE function to return YES
or NO from the BROKEN column, rather than Y or N (see Figure 13-1).
- Line 148
-
Supplies the ORDER BY clause to the SQL query.
152: # print the column names in the log
153: my $colHash = $gq->getColumns;
154: $logFh->printflush(
155: join('~', (
156: $machine, $database,
157: map {$_} sort keys %{$colHash}
158: )
159: ) . "\n") if $optctl{logcolumns};
- Line 153
-
Uses PDBA::GQ's
getColumns method to return the SQL
query's column names into the hash reference,
$colHash, in this kind of form:
$colHash = { 'BROKEN' => 8,
'LAST_DATE' => 2,
'FAILURES' => 5,
'TOTAL_TIME' => 7,
'WHAT' => 6,
'JOB' => 1,
'INTERVAL' => 4,
'NEXT_DATE' => 3,
'SCHEMA_USER' => 0 };
- Lines 154 to 159
-
We need to consider these lines together. Line 159 allows the
printing of columns only if the -logcolumns
option was included on the command line. We want these column names
printed in the database specified order. That's what
line 157 does with the map function. The columns
retrieved into $colHash have no particular
order, because hashes lack any guarantee as to the order in which
keys are stored (see Appendix A). To get them in
the $gq query order, we employ a little Perl
magic. We sort the keys into alphabetical order,
we then map them to an array, and then
join all of these elements together with the
machine and the database strings to form a ~
delimited superstring. To read about these functions, try the
following:
$ perldoc -f map
$ perldoc -f sort
$ perldoc -f join
161: while ( $row = $gq->next({}) ) {
162: $logFh->printflush(
163: join("~", (
164: $machine ,
165: $database ,
166: # the map function is used to place all values from the
167: # $row hash ref into an array. The ternary ?: operator
168: # is used with 'defined( )' to avoid warnings on undefined
169: # values. These occur when a NULL is returned from a
170: # SQL statement
171: map { defined($row->{$_}) ? $row->{$_} : '' }
sort keys %$row
172: )
173: ) . "\n"
174: );
175: write;
176: }
- Lines 161 to 185
-
Retrieve the data from our query object. Line 161 retrieves a row at
a time into the hash reference, $row.
- Lines 162 to 174
-
Begin the process of retrieving the query data. The column values in
the $row hash reference are printed to the
logfile. Notice the use of Perl's
defined operator, which traps potential NULLs.
- Line 175
-
Consists of a write statement.
We'll come back to this at line 231.
178: $dbh->disconnect;
179:
180: # set number of lines on page left to 0
181: # forcing a form feed
182: $- = 0;
183:
184: }
185: }
- Line 178
-
Terminates the connection to this database before the next loop.
- Line 182
-
Issues a form feed via the $- built-in Perl
variable. This is known as $FORMAT_LINES_LEFT,
if you use English.pm, and it's
the number of lines left on a page of the currently selected output
channel.
187: if ($optctl{email}) {
188:
189: #email here
190: close FILE;
191: select(STDOUT);
192:
193: open(FILE, "$tmpFile") ||
die "cannot open $tmpFile for read - $!\n";
194: my @msg = <FILE>;
195: close FILE;
196: my $msg = join('',@msg);
197:
198: my $subject = qq{DBA Jobs Report For All Servers};
199:
200: unless ( PDBA->email($dbajobs::emailAddresses,$msg,$subject) ) {
201: warn "Error Sending Email\n";
202: }
203:
204: unlink $tmpFile;
205:
206: $logFh->printflush(("report mailed to ",
@$dbajobs::emailAddresses, "\n"));
207: }
208:
209:
210: ## end of main
- Line 187
-
Follows the main loop exit. If -email was set,
we execute the following code body.
- Lines 190 to 191
-
Close the FILE opened earlier and reset STDOUT to be the default
output filehandle.
- Line 193
-
Opens the temporary email file, which has been filled by the
write function on line 175
(we'll discuss write formats
later at line 231).
- Lines 194 to 196
-
Read the entire contents of this temporary file into the
@msg array before closing the file. Line 196
then creates the scalar $msg, from
@msg, by joining all of its elements together,
including their embedded newlines.
- Line 198
-
Creates the email $subject header.
- Lines 200 to 202
-
Mail the recipients designated in the
dba_jobs.conf configuration file via the
PDBA module's
mail method.
- Lines 204 to 206
-
Remove the temporary file and write one last audit message, with line
210 marking the end of the main program section.
13.1.2.3 dba_jobsm.pl: A walkthrough of functions and formats
We've finished
looking at the main logic of the script. Now we've
reached the script's functions and print formats.
Just for orientation, you might like to revisit line 39 in the main
program to check its context before looking at the
usage subroutine:
39: if ( $optctl{help} ) { usage(1) }
The usage routine is called when the
-help command option is flagged. It accepts one
argument, $exitVal, read in at line 213. The
usage subroutine outputs a help message, then
exits Perl with $exitVal returned to the command
shell as the error code:
212: sub usage {
213: my $exitVal = shift;
214: use File::Basename;
215: my $basename = basename($0);
216: print qq/
217: usage: $basename
218:
219: -help show help and exit
220: -conf configuration file ( needed for email )
221: -confpath path to configuration file ( optional )
222: -logfile logfile - may include path ( optional )
223: -logcolumns include column names in logfile
224: -email send email to users in config file
225: -verbose verbosity on
226:
227: /;
228: exit $exitVal;
229: };
- Lines 214 to 215
-
Determine the name of the current script with
File::Basename. Even if the
script's name changes,
$basename remains correct.
- Lines 216 to 227
-
Use Perl's qq// operator to
print the help information. The use of qq// is
much neater than a series of print statements
and much easier to edit.
- Line 228
-
Exits the program.
231: no warnings;
232: format STDOUT_TOP =
233:
234: DBA Jobs Status
235: Database: @<<<<<<<<<<<<<<<
236: $instanceName
237: Machine : @<<<<<<<<<<<<<<<
238: $machineName
239: Date : @<<<<<<<<<<<<<<<<<<<<
240: $systemDate
241:
242: SCHEMA TOTAL
FAIL
243: USER JOB LAST DATE NEXT DATE TIME BROKEN
INTERVAL URES WHAT
244: ---------- ----- ---------------- ---------------- --------- ------
--------------- ---- -------------------------
245:
246: .
247:
248:
249: format STDOUT =
250: @<<<<<<<<< @#### @<<<<<<<<<<<<<<< @<<<<<<<<<<<<<<< @######## @<<<<<
^<<<<<<<<<<<<<< @### @<<<<<<<<<<<<<<<<<<<<<<<<
251: $row->{SCHEMA_USER}, $row->{JOB}, $row->{LAST_DATE},
$row->{NEXT_DATE}, $row->{TOTAL_TIME}, $row->{BROKEN},
$row->{INTERVAL}, $row->{FAILURES}, $row->{WHAT}
252: ~~
^<<<<<<<<<<<<<<
253:
$row->{INTERVAL}
254: .
- Line 231
-
Begins the print formatting section for the earlier
write command:
175: write;
A no warnings call is made at line 231 to
prevent Perl from overreacting to acceptable difficulties such as
NULL values returning from Oracle.
- Lines 232 to 246
-
Create the STDOUT_TOP header format, which appears at the top of each
page. Perl formats use literal text, variables, and field holders to
determine how data will be printed (with much of the original layout
borrowed from FORTRAN and the nroff program).
You can learn more about Perl formats by invoking:
$ perldoc perlform
- Line 235
-
Contains the literal text of `Database:
' followed by a field holder of
@<<<<<<<<<<. This
tells Perl that the print data should be left justified.
- Lines 242 to 244
-
Print the literal text of the column names.
- Line 246
-
Terminates the STDOUT_TOP format with a period.
- Lines 249 to 253
-
Define the STDOUT body of the report.
- Line 254
-
Terminates the STDOUT format and brings us to the end of the
script.
13.1.3 Modifying the dba_jobsm.pl Script
By
now you should have a good understanding of the structure and logic
of the existing version of the dba_jobsm.pl
script and its dba_jobs.conf configuration file.
Now let's talk about how you might want to modify
the script and file to provide some code flexibility. In addition to
showing specific modifications for this particular case, the
following sections should give you the background necessary to be
able to examine and modify additional scripts to suit your own
requirements.
13.1.3.1 Configuring parameters
The first change
we'll make involves Oracle's
NLS_DATE_FORMAT, a setting used within the database to set the
default format in which date column data will be returned. This
format is currently hard-coded into the script at line 20:
20: my $nlsDateFormat = q{yyyy/mm/dd hh24:mi};
If we ever want to change this value, we'll have to
edit the script each time. It's much better to
specify this value as a configurable item in the
dba_jobs.conf configuration file. So
let's comment out line 20 of the script with a
# hash character as follows:
20: #my $nlsDateFormat = q{yyyy/mm/dd hh24:mi};
Now find lines 124 and 138. They look like the following:
124:$dbh->do(qq{alter session set nls_date_format = '$nlsDateFormat' });
...
138: $systemDate = PDBA->sysdate($dbh, NLS_DATE_FORMAT => $nlsDateFormat );
You need to change these lines to this:
124: $dbh->do(qq{alter session set nls_date_format = '$dbajobs::nlsDateFormat' });
...
138: $systemDate = PDBA->sysdate($dbh, NLS_DATE_FORMAT => $dbajobs::nlsDateFormat );
Save the dba_jobsm.pl file and open
dba_jobs.conf. Now we'll add an
entry for NLS_DATE_FORMAT. We've displayed the
relevant code snippet that adds the
$nlsDateFormat variable. Notice that this
variable name has also been added to the use
vars statement. Doing so prevents use
warnings from raising a message about the single use of a
variable.
package dbajobs;
use vars qw{ $emailAddresses $nlsDateFormat %databases };
$nlsDateFormat = q{yyyy/mm/dd hh24:mi};
$emailAddresses = [qw{[email protected]}];
...
Now simply run dba_jobsm.pl to test it. Be sure
to change the value of the $nlsDateFormat
variable so you can verify the results.
13.1.3.2 Adding passwords to the configuration file
Although we encourage you to use
the password server, we'll show you how to work
around it just in case you're unable to use it for
some reason. While putting passwords in configuration files is
workable, it is both a security risk and more work to maintain.
However, given those caveats, let's begin with the
configuration file by creating data constructs that can hold DBA
passwords as well as usernames:
package dbajobs;
use vars qw{ $emailAddresses $nlsDateFormat %databases };
$nlsDateFormat = q{yyyy/mm/dd hh24:mi};
$emailAddresses = [qw{[email protected]}];
%databases = ( sherlock => { ts01 => [qw{system manager}], },
watson => { ts98 => [qw{system manager}],
ts99 => [qw{system manager}], } );
1;
The DBA user and its password are placed inside array references. The
user is element 0 of each array reference, and the password is
element 1.
Now it's time to change the script. Open
dba_jobsm.pl and locate the following lines:
15: use PDBA::OPT;
...
70: print
"\t\tusername: $dbajobs::databases{$machine}->{$database}\n";
...
108: my $username = $dbajobs::databases{$machine}->{$database};
...
111: my $password = PDBA::OPT->pwcOptions (
112: INSTANCE => $database,
113: MACHINE => $machine,
114: USERNAME => $username
115: );
Change these lines so they appear like those in Example 13-3:
Example 13-3. Results of changes to dba_jobsm.pl for password usage.
15: #use PDBA::OPT; --- Commented out, array references used below! :-)
...
70: print
"\t\tusername: $dbajobs::databases{$machine}->{$database}[0]\n";
...
108: my $username = $dbajobs::databases{$machine}->{$database}[0];
...
111: my $password = $dbajobs::databases{$machine}->{$database}[1];
112: #INSTANCE => $database,
113: #MACHINE => $machine,
114: #USERNAME => $username
115: #);
Once again, run the script to validate the changes.
|
