| [ Team LiB ] |
|
10.2 RADIUS and AvailabilityHigh availability has become the latest buzzword in Internet service. Advertisements abound for network operation centers (NOCs) with triple-capacity electric generators, dual HVAC systems, geographical dispersion, waterless combustion control, and other facilities to handle problems. While these certainly are methods to obtain and retain high availability, it seems that sometimes people lose sight of the point of such exercises: to maintain the existence and offering of services when others systems on all "sides" of the service are failing. I say "sides" to refer to the hierarchical tree in which most systems reside: there are often machines relying on a specific box, and that box relies on other boxes, and it also may work in tandem with others. There are several strategies for planning for failure, which is the main tenet in high availability. The one most disaster-planning experts use is to account for what would be a worst-case scenario for your implementation. There are several questions to ask yourself when designing a highly available system:
These questions give you a fairly complete estimate of your implementation's weak points, both inside and outside of your control. Let's step through each of the questions with regard to designing a RADIUS implementation. 10.2.1 Determining Normal System BehaviorTo establish a proper and accurate baseline for your system, there are two types of requirements you need to consider: explicit requirements, which are those mandated by your users or your company's management; and derived (or implicit) requirements, which mainly stem from the explicit requirements. For example, you may be required to make all reasonable efforts to have service restored within 15 minutes of downtime. The 15-minute window is an explicit requirement. However, you may also require that your systems have hot-swap hard drives so that you can indeed switch out a dead disc within 15 minutes. Your hot-swap requirement is derived from the explicit requirements. Let's take a look at each of these now. 10.2.1.1 Explicit requirementsSome RADIUS implementations must deal with a constant, heavy stream of users needing its services. In this case, a measurement called packets per second is used, which quite obviously is a threshold of how many packets per second can be received and processed by the server systems. A few calculations are in order to determine what this qualification should be.
Can you handle that? It may seem like a simple question, but it's one that must be answered. It's also important to consider the number of packets per transaction, as you may be faced with a "transactions per second" constraint. In this case, RADIUS call-check may be used, which can cause more packets to constitute a single transaction. Of course, each implementation is different, so careful consideration of your environment and what your requirements are is prudent. Some administrators believe that the primary factors in designing these systems are, of course, availability and response time. Consider the effect of a slow system: if a server is under heavy load, it will take a while to respond to a request. The client system will probably send the message again after a timeout period, which adds another packet to the load. You can begin to see the cascading effect of packet load, which likely will ultimately result in a system crash. Another requirement to consider is the average time between system failures, or the MTBF factor. You may be familiar with this statistic from its presence on nearly all hard disc drives. For smaller RADIUS setups, in which downtime is measured in under one thousand minutes per year (close to 17 hours), then MTBF may not be as important a measure as more active monitors like packet per second and MTRS (more on that later). For larger providers, however, a figure on acceptable MTBF should be determined as part of a high-availability plan. A common figure for which companies strive is 99.999% uptime. Most systems administrators install some sort of real-time monitoring system for their systems, but the key to maintaining five-nines is tackling problems before they become problems, per se. Diligence in examining log files and using accounting data to plan and analyze usage trends should both be part of a disaster-prevention plan. However, the techniques established in this chapter aren't meant to provide for five-nines uptime. Designing for that level of availability requires consultants and expensive equipment. Finally, while examining explicit requirements to high availability, we have to admit that all systems are going to fail at some point. There is no such thing as 100% uptime over any practical, meaningful length of time. The mean time to restore service, or MTRS, figure looks at how long it takes you or your systems to recover from an outage. This could be the most critical aspect of all of your requirements. Customers can tolerate some downtime, and few businesses run operations so important that any downtime is a catastrophic nightmare. But your customers, fellow employees, vendors, and partners will all scream if an outage is prolonged. It's likely your company earns more brownie points responding to problems quickly than it does ensuring no downtime occurs. There are a few ways to minimize the time it takes to restore service. With hardware, it is always good practice to keep hot spares of critical components around: hubs, switches, routers, hard drives, processors, memory, and disk controllers are all parts with limited (albeit long) lives. It's also advisable to keep copies of critical system software, including the operating system and your RADIUS implementation software, close to machines on which they're installed. Regular data backupsand perhaps even more importantly, regular test restorationsshould be conducted. Remember: the value of a backup is reduced to zero if it cannot be restored. 10.2.1.2 Derived requirementsThe processing power of your server is one requirement that can be mandated by a threshold or directive set to maintain service availability. For example, if you need to process 25 packets per second, you require a fairly powerful server. But there may be a better solution to increase your power: since you have multiple POPs separated around a state but your RADIUS servers are in one main location, then you may investigate using several systems in parallel and building a RADIUS server cluster. Network connectivity is also another under-compensated area. With heavy loads of traffic, it's critical to ensure your network connections are rock solid. Quality server-based network interface cards (NICs) from tier-1 manufacturers like 3Com and Intel are a must in this situation, and in most cases another NIC bound to another IP for the same machine will allow the box to spread the traffic load over the two cards. Additionally, if one dies, the other can still handle traffic and serve as an online backup until a new card can be installed. 10.2.2 Points of FailureTechWeb's TechEncyclopedia defines redundancy as "...peripherals, computer systems and network devices that take on the processing or transmission load when other units fail." More granularly, redundancy is the inclusion of independent yet identical sets of components to provide an alternate way of providing a function. The concept of redundancy can be applied to individual computers, sets of computers, networks, and even entire implementation design. Moreover, systems can be as redundant as needed; as with everything, however, there is a "happy medium." I should discuss certain terminology in regard to redundancy before proceeding further. A technique to balance and distribute loads across servers working in tandem is called a "round robin" strategy. For example, let's say I have three RADIUS servers in one POP. The NAS is configured to send calls in order to one of the three RADIUS servers; the mentality behind this is that the traffic load will be evenly placed among the three servers by choosing the next available server in the "list" upon dial-in so that no one server is operating under a much heavier load than the others. Secondly, "failover" is a term used to describe when an administrator has ensured service availability by enabling a service to cut over to another standby server when a primary server fails. This is most commonly found in groups of two servers in one geographic location, such as a particular POP in a city. There may be two RADIUS servers, for example: one configured to handle all of the requests normally and another to take over the duties if the first fails. Hence, the RADIUS service "fails over" to the backup server. (It's been known, however, for fail-over systems not to resume back to the normal servers when the failure condition is resolved. This can inadvertently direct large amounts of traffic to your failover servers, which might not be designed to handle such a load. It's something to be aware of.) Redundancy is often found inside specific pieces of hardware, particularly servers. Most industrial-strength servers include the capability, if not the hardware, to maintain redundancy in critical machine subsystems: power, processors, and controllers. In most cases, the computer's BIOS will detect a failure of a critical component within milliseconds and automatically cut over to the auxiliary device, which is already installed in the machine's chassis. This is one of the benefits you receive for paying extra money for a standard server-class system instead of commissioning a regular personal computer. Hubs and switches are also critical devices that are often overlooked. Ports on these devices can suddenly fail, leaving you without any connectivity to your machine. Unfortunately, switches and other concentrators designed for heavy use in a datacenter are often very expensive, so you must weigh the benefit of keeping an identical spare switch on site. Ideally, your machine will have two network cards present that are connected to two separate switches. This eliminates two probable points of failure: the port on a switch (or the entire switch, in the event of a power loss to a rack or a unit) and the NIC inside the chassis. This is cheap insurance and not very difficult to configure. There is an issue to consider with the dual-NIC approach, however. You must have a way to route traffic between both cards. Otherwise, when one card (or concentrator port) fails, your traffic routes will fail to switch over to the functioning interface. This phenomenon is known as "convergence failure." To cure this, run a routing daemon such as gated across all of your interfaces. Another problem that tends to creep up is managing IP addresses. These numbers often change, and this can create havoc for system administrators trying to announce and provide these numbers to the public. It also creates issues with proxy servers and other systems that see your servers as clients. To absolve the renumbering issue, use virtual loopback addresses. These function as aliases to your real address so that your public customers and other remote clients can use these numbers to reach your system no matter what numbering it uses. 10.2.3 Planning to FailHaving multiple servers ready to take over in case of failure is one of the most effective ways of combating downtime. Unfortunately, having multiple servers increases the total cost of ownership of the entire implementation, and many times management may want to increase availability but at the same time spend as little money as possible. However, budgeting for high availability systems is much like budgeting for any type of insurance, whether business or personalyou pay money up front for the time you will need it, but when you need it, you need it badly. A fellow author and systems designer/administrator once told of the concept of building for failure. I find that a healthy attitude to take. Companies often build technology infrastructures involving systems critical to their day-to-day operation and then later discover the need for fault tolerance and uptime increase. Renovating an existing implementation to conform to strict availability standards is extremely expensive. However, up-front planning reduces much of this cost, and allows you to take high availability to a level that otherwise may have been cost prohibitive. There are a few different levels, or "temperatures," of high availability (HA), ranging from inexpensive and least timely to most expensive and instantaneously available. It's easiest to delineate these temperatures into three groups, but that distinction made here should not be treated as a statement that other combinations of HA systems are not available. In fact, combinations are often necessary because of unique infrastructures and system peculiarities. The point of HA is to strategize your network layout and design to plan for every malicious network event and minimize downtime as much as possible. Cold standby servers offer the least protection from outages, but they are also the most cost-effective standby systems. Most often, the cold standby RADIUS server is actually a box performing another network duty (SMTP service, for example), but the administrator installs and configures the RADIUS server software on that machine and then shuts the service down. The problem with cold servers is that the administrator must know there is a problem with the primary servers, and he must actually perform the cutover to the standby server manually. While it's not expensive at all to keep a cold standby around, it provides very limited failover services and maximum uptime during an outage. The next step up on the availability thermometer is a warm standby server. Warm standby servers are most likely identical to the primary, in-service machines both in hardware configuration and software maintenance. However, these servers are powered on and able to take over service for a primary server should it go down in a matter of seconds. Software APIs residing on both machines normally can make and receive calls to determine when the standby server should take over duties from the active server. Hot standby servers are the most expensive and most effective way to ensure your implementation has the most uptime possible. Hot backups generally run the system software actively, which means a method of synchronization is present between the active and standby servers to make sure session information and real-time data is mirrored between the two. However, the standby server is not contacted unless all primary servers have gone offline or are otherwise unable to perform service. 10.2.4 Proactive System ManagementAn equally important part of maintaining a RADIUS implementation with the least downtime possible is keeping up with your system and examining it on a daily (or sometimes even more often) basis. There is a glut of monitoring tools on the market now, and there are as many freely available open source tools that can be had for the simple price of compilation and configuration. Most of these tools profile various metrics of your system in two key areas: service statistics and system statistics. Service monitoring is designed to see two things: whether the service is functional, period, and then what kind of load under which the service is operating. The most effective way to test the first tenet is to have a packet generator send RADIUS packets emulating an incoming NAS connection. If a response is received from the RADIUS server, I know it's operating. Beyond that, I want to see some statistics about the environment in which the service is being provided.
The same strategies for service monitoring can be applied to monitoring the health and activity of the hardware on which the service runs. It's important to determine a baseline with these metrics, as with any other metric, since the thresholds to which you want an alarm must be set at 25%-30% above your normal system activity tolerance. Here are a few key aspects of your system that need to be checked often.
10.2.5 Case Studies in Deployment and AvailabilityOnce you've focused on securing the availability of your hardware and software through redundancy, you should examine making the entire RADIUS service as a whole more available. It's important to remember, however, that consultants who specialize in designing a network topology to be highly available make six-figure salaries doing just that, so to present every opportunity to make a system highly available is beyond the scope of the concept here. Like all plans for failure, you as the designer must strive to reach the "sweet spot" between cost and results. In that spirit, I'll present two example network topologies that accomplish the most redundancy and availability without breaking the bank. I will cover the availability and redundancy strategies used in each design; then, you can take the best practices outlined here and use them as a starting point for your own design. And remember, part of being a designer is knowing when to bring in the big guns: don't be afraid to call a consultant if you realize that you're in over your head. It would simply be a waste of time, money, and system resources to continue at that point. 10.2.5.1 Scenario 1: A small, regional ISPRaleigh Internet, Inc., is a small Internet service provider operating within the Research Triangle Park region of North Carolina. The provider offers service to residents of the region and the surrounding counties. Raleigh Internet has created points of presence in three locations: at its head office in Durham, with 1,000 ports; in a co-located telco area in Chapel Hill, with 1,500 ports; and a rented set of 2,500 ports from a network conglomerate to serve the Raleigh city proper. Their average user load is 35% on each POP, for a total active port count under normal load of 1,750 ports. They wish to provide as much service availability as possible, but the budget is certainly not unlimited and 99.999% uptime is not an explicit requirement. The ISP does need to maintain support for processing at 90% load (4,500 ports) across all its POPs without problems. The company maintains a single set of RADIUS servers in its Durham office, along with its arsenal of other service machines for mail, personal web pages, Usenet, and additional services. It doesn't want to maintain separate RADIUS servers able to perform authentication on their own at each POP because of the administrative overhead involved in change management: for example, what if a user in Raleigh changed his password and then went to work in Chapel Hill? How would the password change propagate from the Raleigh machine to the Chapel Hill server? In addition, Raleigh Internet needs to maintain the ability to continue to authenticate users in the event one server goes down. The solution for Raleigh Internet would look something like the topology depicted in Figure 10-1. Figure 10-1. An availability solution for a small ISP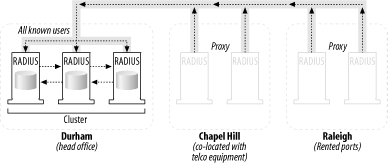 In this network design, each POP maintains two RADIUS machines that act solely as a proxy. The proxy servers are configured to send packets to the main RADIUS machines at the Durham office. The Durham office contains three RADIUS servers working in tandem with a real copy of the authentication database. Having the database on a single cluster of machines makes change management and propagation issues less of a problem. This solution also allows for the contingency of a RADIUS server in each POP going down: the remaining servers can still proxy to the cluster of real servers in Durham and continue processing AAA requests. The ISP decided against having real servers in each POP for two reasons: one, it didn't want to invest in expensive programming and consulting expenses to rectify the propagation problems. The benefits of having five-nines uptime, at least to management, were not worth the cost of ensuring more availability, since most of Raleigh Internet's customer base is in the residential market. Their customers didn't demand such uptime requirements since having access to the Internet wasn't mission critical. In summary, here are the key strategies involved with this scenario:
10.2.5.2 Scenario 2: A corporation with branch officesAcme Machine Tools, LLC, is a midsize manufacturer of shop automation and general construction equipment with just over 2,000 employees. Acme has a main office in Chicago, with three branch offices in Tempe, Dallas, and Birmingham. The company has NAS gear in Tempe, Dallas, and Birmingham, each with 500 ports and a nominal active port load of about 75 ports. The company would like to support a 98% maximum load at each POP (490 ports each), for a maximum system-wide load of 1,470 active ports. The company has hired RADIUS administrators for each POP as well as one for the corporate office. Acme wants to create a service that will allow its employees in the corporate offices to work from home and gain access to the corporate network by dialing in to each city. It also has a fleet of mobile workers that roam around the entire country while making sales calls, and they need to be granted access as well. It is assumed that each corporate employee who works from home will only dial in to the set of ports for his respective location (i.e., Jill from Tempe will only dial the Tempe number since she does not travel). However, the sales fleet needs access to the corporate network and from there, the Internet, from wherever they happen to be. It is also assumed that the work-from-home option is not offered to employees in the Chicago area. The company wants as little administrative overhead as possible, although Acme's resources are a bit more extensive and its budget considerably larger than Raleigh Internet's plan. How is this best accomplished? Figure 10-2 illustrates the most effective solution. Figure 10-2. Availability solution for a midsize corporation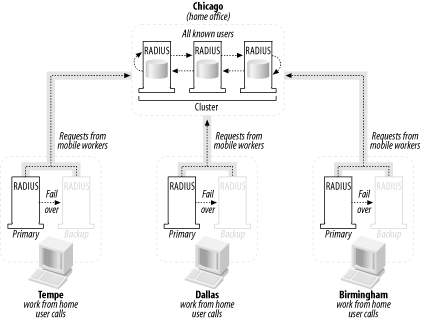 Let's take a closer look at this solution. I have placed two fully functional RADIUS servers in each city's POP, with one configured as the primary, always-on server and the other configured as a backup server for failover purposes in case the primary server goes down. Based on the assumptions previously listed, I know that the users who work from home in each city are the only ones that will be dialing that POP's number. By that assumption, I can simply sort the users that need dial-in access by their city of residence and configure only those users on each city's RADIUS servers. So the RADIUS servers in each city's POP will authenticate those users it knows about. But that leaves out the fleet of mobile workers. How will they gain access? First, I have placed a three-node parallel processing cluster of RADIUS serversthe core of the networkat the corporate head office in Chicago. These servers know about every user with remote-access privileges in the entire company, so these machines are effectively root servers, much in the same way that there are root DNS servers for the global Internet. The individual RADIUS servers in Birmingham, Dallas, and Tempe will be configured as clients on the root RADIUS cluster in Chicago. So when a mobile user dials a POP, and the POP does not explicitly know about those users, then the individual RADIUS server forwards the request to the root servers. So the mobile users are happy, the work-from-home users are happy, and your administrators are happy, toothe user management in this design is a cinch since the servers in Tempe, Dallas, and Birmingham all depend on the Chicago root nodes. All the administrators have to do is keep the corporate servers updated, which automatically makes the clients rely on updated information. In summary, here are the key strategies involved with this scenario:
|
| [ Team LiB ] |
|