| [ Team LiB ] |
|
5.13 Parallelizing Encryption and Decryption in Modes That Allow It (Without Breaking Compatibility)5.13.1 ProblemYou want to parallelize encryption, decryption, or keystream generation. 5.13.2 SolutionOnly some cipher modes are naturally parallelizable in a way that doesn't break compatibility. In particular, CTR mode is naturally parallizable, as are decryption with CBC and CFB. There are two basic strategies: one is to treat the message in an interleaved fashion, and the other is to break it up into a single chunk for each parallel process. The first strategy is generally more practical. However, it is often difficult to make either technique result in a speed gain when processing messages in software. 5.13.3 Discussion
Some cipher modes can have independent parts of the message operated upon independently. In such cases, there is the potential for parallelization. For example, with CTR mode, the keystream is computed in blocks, where each block of keystream is generated by encrypting a unique plaintext block. Those blocks can be computed in any order. In CBC, CFB, and OFB modes, encryption can't really be parallelized because the ciphertext for a block is necessary to create the ciphertext for the next block; thus, we can't compute ciphertext out of order. However, for CBC and CFB, when we decrypt, things are different. Because we only need the ciphertext of a block to decrypt the next block, we can decrypt the next block before we decrypt the first one. There are two reasonable strategies for parallelizing the work. When a message shows up all at once, you might divide it roughly into equal parts and handle each part separately. Alternatively, you can take an interleaved approach, where alternating blocks are handled by different threads. That is, the actual message is separated into two different plaintexts, as shown in Figure 5-5. Figure 5-5. Encryption through interleaving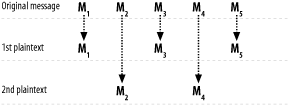 If done correctly, both approaches will result in the correct output. We generally prefer the interleaving approach, because all threads can do work with just a little bit of data available. This is particularly true in hardware, where buffers are small. With a noninterleaving approach, you must wait at least until the length of the message is known, which is often when all of the data is finally available. Then, if the message length is known in advance, you must wait for a large percentage of the data to show up before the second thread can be launched. Even the interleaved approach is a lot easier when the size of the message is known in advance because it makes it easier to get the message all in one place. If you need the whole message to come in before you know the length, parallelization may not be worthwhile, because in many cases, waiting for an entire message to come in before beginning work can introduce enough latency to thwart the benefits of parallelization. If you aren't generally going to get an entire message all at once, but you are able to determine the biggest message you might get, another reasonably easy approach is to allocate a result buffer big enough to hold the largest possible message. For the sake of simplicity, let's assume that the message arrives all at once and you might want to process a message with two parallel threads. The following code provides an example API that can handle CTR mode encryption and decryption in parallel (remember that encryption and decryption are the same operation in CTR mode). Because we assume the message is available up front, all of the information we need to operate on a message is passed into the function spc_pctr_setup( ), which requires a context object (here, the type is SPC_CTR2_CTX), the key, the key length in bytes, a nonce SPC_BLOCK_SZ - SPC_CTR_BYTES in length, the input buffer, the length of the message, and the output buffer. This function does not do any of the encryption and decryption, nor does it copy the input buffer anywhere. To process the first block, as well as every second block after that, call spc_pctr_do_odd( ), passing in a pointer to the context object. Nothing else is required because the input and output buffers used are the ones passed to the spc_pctr_setup( ) function. If you test, you'll notice that the results are exactly the same as with the CTR mode implementation from Recipe 5.9. This code requires the preliminaries from Recipe 5.5, as well as the spc_memset( ) function from Recipe 13.2. #include <stdlib.h>
#include <string.h>
typedef struct {
SPC_KEY_SCHED ks;
size_t len;
unsigned char ctr_odd[SPC_BLOCK_SZ];
unsigned char ctr_even[SPC_BLOCK_SZ];
unsigned char *inptr_odd;
unsigned char *inptr_even;
unsigned char *outptr_odd;
unsigned char *outptr_even;
} SPC_CTR2_CTX;
static void pctr_increment(unsigned char *ctr) {
unsigned char *x = ctr + SPC_CTR_BYTES;
while (x-- != ctr) if (++(*x)) return;
}
void spc_pctr_setup(SPC_CTR2_CTX *ctx, unsigned char *key, size_t kl,
unsigned char *nonce, unsigned char *in, size_t len,
unsigned char *out) {
SPC_ENCRYPT_INIT(&(ctx->ks), key, kl);
spc_memset(key,0, kl);
memcpy(ctx->ctr_odd, nonce, SPC_BLOCK_SZ - SPC_CTR_BYTES);
spc_memset(ctx->ctr_odd + SPC_BLOCK_SZ - SPC_CTR_BYTES, 0, SPC_CTR_BYTES);
memcpy(ctx->ctr_even, nonce, SPC_BLOCK_SZ - SPC_CTR_BYTES);
spc_memset(ctx->ctr_even + SPC_BLOCK_SZ - SPC_CTR_BYTES, 0, SPC_CTR_BYTES);
pctr_increment(ctx->ctr_even);
ctx->inptr_odd = in;
ctx->inptr_even = in + SPC_BLOCK_SZ;
ctx->outptr_odd = out;
ctx->outptr_even = out + SPC_BLOCK_SZ;
ctx->len = len;
}
void spc_pctr_do_odd(SPC_CTR2_CTX *ctx) {
size_t i, j;
unsigned char final[SPC_BLOCK_SZ];
for (i = 0; i + SPC_BLOCK_SZ < ctx->len; i += 2 * SPC_BLOCK_SZ) {
SPC_DO_ENCRYPT(&(ctx->ks), ctx->ctr_odd, ctx->outptr_odd);
pctr_increment(ctx->ctr_odd);
pctr_increment(ctx->ctr_odd);
for (j = 0; j < SPC_BLOCK_SZ / sizeof(int); j++)
((int *)ctx->outptr_odd)[j] ^= ((int *)ctx->inptr_odd)[j];
ctx->outptr_odd += SPC_BLOCK_SZ * 2;
ctx->inptr_odd += SPC_BLOCK_SZ * 2;
}
if (i < ctx->len) {
SPC_DO_ENCRYPT(&(ctx->ks), ctx->ctr_odd, final);
for (j = 0; j < ctx->len - i; j++)
ctx->outptr_odd[j] = final[j] ^ ctx->inptr_odd[j];
}
}
void spc_pctr_do_even(SPC_CTR2_CTX *ctx) {
size_t i, j;
unsigned char final[SPC_BLOCK_SZ];
for (i = SPC_BLOCK_SZ; i + SPC_BLOCK_SZ < ctx->len; i += 2 * SPC_BLOCK_SZ) {
SPC_DO_ENCRYPT(&(ctx->ks), ctx->ctr_even, ctx->outptr_even);
pctr_increment(ctx->ctr_even);
pctr_increment(ctx->ctr_even);
for (j = 0; j < SPC_BLOCK_SZ / sizeof(int); j++)
((int *)ctx->outptr_even)[j] ^= ((int *)ctx->inptr_even)[j];
ctx->outptr_even += SPC_BLOCK_SZ * 2;
ctx->inptr_even += SPC_BLOCK_SZ * 2;
}
if (i < ctx->len) {
SPC_DO_ENCRYPT(&(ctx->ks), ctx->ctr_even, final);
for (j = 0; j < ctx->len - i; j++)
ctx->outptr_even[j] = final[j] ^ ctx->inptr_even[j];
}
}
int spc_pctr_final(SPC_CTR2_CTX *ctx) {
spc_memset(&ctx, 0, sizeof(SPC_CTR2_CTX));
return 1;
}
5.13.4 See AlsoRecipe 5.5, Recipe 5.9, Recipe 13.2 |
| [ Team LiB ] |
|
