| [ Team LiB ] |
|
5.15 Performing File or Disk Encryption5.15.1 ProblemYou want to encrypt a file or a disk. 5.15.2 SolutionIf you're willing to use a nonce or an initialization vector, standard modes such as CBC and CTR are acceptable. For file-at-a-time encryption, you can avoid the use of a nonce or IV altogether by using the LION construction, described in Section 5.15.3. Generally, keys will be generated from a password. For that, use PKCS #5, as discussed in Recipe 4.10. 5.15.3 DiscussionDisk encryption is usually done in fixed-size chunks at the operating system level. File encryption can be performed in chunks so that random access to an encrypted file doesn't require decrypting the entire file. This also has the benefit that part of a file can be changed without reencrypting the entire file. CBC mode is commonly used for this purpose, and it is used on chunks that are a multiple of the block size of the underlying block cipher, so that padding is never necessary. This eliminates any message expansion that one would generally expect with CBC mode. However, when people are doing disk or file encryption with CBC mode, they often use a fixed initialization vector. That's a bad idea because an initialization vector is expected to be random for CBC mode to obtain its security goals. Using a fixed IV leads to dictionary-like attacks that can often lead to recovering, at the very least, the beginning of a file. Other modes that require only a nonce (not an initialization vector) tend to be streaming modes. These fail miserably when used for disk encryption if the nonce does not change every single time the contents associated with that nonce change.
For example, if you're encrypting file-by-file in 8,192-byte chunks, you need a separate nonce for each 8,192-byte chunk, and you need to select a new nonce every single time you want to protect a modified version of that chunk. You cannot just make incremental changes, then reencrypt with the same nonce. In fact, even for modes where sequential nonces are possible, they really don't make much sense in the context of file encryption. For example, some people think they can use just one CTR mode nonce for the entire disk. But if you ever reuse the same piece of keystream, there are attacks. Therefore, any time you change even a small piece of data, you will have to reencrypt the entire disk using a different nonce to maintain security. Clearly, that isn't practical. Therefore, no matter what mode you choose to use, you should choose random initial values. Many people don't like IVs or nonces for file encryption because of storage space issues. They believe they shouldn't "waste" space on storing an IV or nonce. When you're encrypting fixed-size chunks, there are not any viable alternatives; if you want to ensure security, you must use an IV. If you're willing to accept message expansion, you might want to consider a high-level mode such as CWC, so that you can also incorporate integrity checks. In practice, integrity checks are usually ignored on filesystems, though, and the filesystems trust that the operating system's access control system will ensure integrity. Actually, if you're willing to encrypt and decrypt on a per-file basis, where you cannot decrypt the file in parts, you can actually get rid of the need for an initialization vector by using LION, which is a construction that takes a stream cipher and hash function and turns them into a block cipher that has an arbitrary block size. Essentially, LION turns those constructs into a single block cipher that has a variable block length, and you use the cipher in ECB mode. Throughout this book, we repeatedly advise against using raw block cipher operations for things like file encryption. However, when the block size is always the same length as the message you want to encrypt, ECB mode isn't so bad. The only problem is that, given a {key, plaintext} pair, an unchanged file will always encrypt to the same value. Therefore, an attacker who has seen a particular file encrypted once can find any unchanged versions of that file encrypted with the same key. A single change in the file thwarts this problem, however. In practice, most people probably won't be too concerned with this kind of problem. Using raw block cipher operations with LION is useful only if the block size really is the size of the file. You can't break the file up into 8,192-byte chunks or anything like that, which can have a negative impact on performance, particularly as the file size gets larger. Considering what we've discussed, something like CBC mode with a randomly chosen IV per block is probably the best solution for pretty much any use, even if it does take up some additional disk space. Nonetheless, we recognize that people may want to take an approach where they only need to have a key, and no IV or nonce. Therefore, we'll show you LION, built out of the RC4 implementation from Recipe 5.23 and SHA1 (see Recipe 6.7). The structure of LION is shown in Figure 5-6.
The one oddity of this technique is that files must be longer than the output size of the message digest function (20 bytes in the case of SHA1). Therefore, if you have files that small, you will either need to come up with a nonambiguous padding scheme, which is quite complicated to do securely, or you'll need to abandon LION (either just for small messages or in general). LION requires a key that is twice as long as the output size of the message digest function. As with regular CBC-style encryption for files, if you're using a cipher that takes fixed-size keys, we expect you'll generate a key of the appropriate length from a password. Figure 5-6. The structure of LION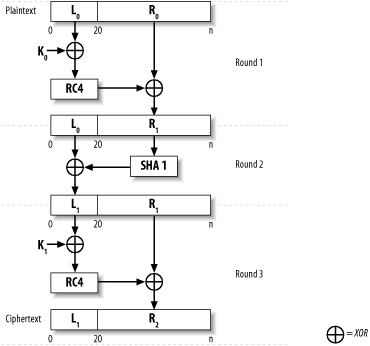 We also assume a SHA1 implementation with a very standard API. Here, we use an API that works with OpenSSL, which should be easily adaptable to other libraries. To switch hash functions, replace the SHA1 calls as appropriate, and change the value of HASH_SZ to be the digest size of the hash function that you wish to use. The function spc_lion_encrypt( ) encrypts its first argument, putting the result into the memory pointed to by the second argument. The third argument specifies the size of the message, and the last argument is the key. Again, note that the input size must be larger than the hash function's output size. The spc_lion_decrypt( ) function takes a similar argument set as spc_lion_encrypt( ), merely performing the inverse operation. #include <stdio.h>
#include <openssl/rc4.h>
#include <openssl/sha.h>
#define HASH_SZ 20
#define NUM_WORDS (HASH_SZ / sizeof(int))
void spc_lion_encrypt(char *in, char *out, size_t blklen, char *key) {
int i, tmp[NUM_WORDS];
RC4_KEY k;
/* Round 1: R = R ^ RC4(L ^ K1) */
for (i = 0; i < NUM_WORDS; i++)
tmp[i] = ((int *)in)[i] ^ ((int *)key)[i];
RC4_set_key(&k, HASH_SZ, (char *)tmp);
RC4(&k, blklen - HASH_SZ, in + HASH_SZ, out + HASH_SZ);
/* Round 2: L = L ^ SHA1(R) */
SHA1(out + HASH_SZ, blklen - HASH_SZ, out);
for (i = 0; i < NUM_WORDS; i++)
((int *)out)[i] ^= ((int *)in)[i];
/* Round 3: R = R ^ RC4(L ^ K2) */
for (i = 0; i < NUM_WORDS; i++)
tmp[i] = ((int *)out)[i] ^ ((int *)key)[i + NUM_WORDS];
RC4_set_key(&k, HASH_SZ, (char *)tmp);
RC4(&k, blklen - HASH_SZ, out + HASH_SZ, out + HASH_SZ);
}
void spc_lion_decrypt(char *in, char *out, size_t blklen, char *key) {
int i, tmp[NUM_WORDS];
RC4_KEY k;
for (i = 0; i < NUM_WORDS; i++)
tmp[i] = ((int *)in)[i] ^ ((int *)key)[i + NUM_WORDS];
RC4_set_key(&k, HASH_SZ, (char *)tmp);
RC4(&k, blklen - HASH_SZ, in + HASH_SZ, out + HASH_SZ);
SHA1(out + HASH_SZ, blklen - HASH_SZ, out);
for (i = 0; i < NUM_WORDS; i++) {
((int *)out)[i] ^= ((int *)in)[i];
tmp[i] = ((int *)out)[i] ^ ((int *)key)[i];
}
RC4_set_key(&k, HASH_SZ, (char *)tmp);
RC4(&k, blklen - HASH_SZ, out + HASH_SZ, out + HASH_SZ);
}
5.15.4 See AlsoRecipe 4.10, Recipe 5.23, Recipe 6.7 |
| [ Team LiB ] |
|
