| [ Team LiB ] |
|
5.6 Using a Generic CBC Mode Implementation5.6.1 ProblemYou want a more high-level interface for CBC mode than your library provides. Alternatively, you want a portable CBC interface, or you have only a block cipher implementation and you would like to use CBC mode. 5.6.2 SolutionCBC mode XORs each plaintext block with the previous output block before encrypting. The first block is XOR'd with the IV. Many libraries provide a CBC implementation. If you need code that implements CBC mode, you will find it in the following discussion. 5.6.3 Discussion
CBC mode is a way to use a raw block cipher and, if used properly, it avoids all the security risks associated with using the block cipher directly. CBC mode works on a message in blocks, where blocks are a unit of data on which the underlying cipher operates. For example, AES uses 128-bit blocks, whereas older ciphers such as DES almost universally use 64-bit blocks. See Recipe 5.4 for a discussion of the advantages and disadvantages of this mode, as well as a comparison to other cipher modes. CBC mode works (as illustrated in Figure 5-1) by taking the ciphertext output for the previous block, XOR'ing that with the plaintext for the current block, and encrypting the result with the raw block cipher. The very first block of plaintext gets XOR'd with an initialization vector, which needs to be randomly selected to ensure meeting security goals but which may be publicly known.
Figure 5-1. CBC mode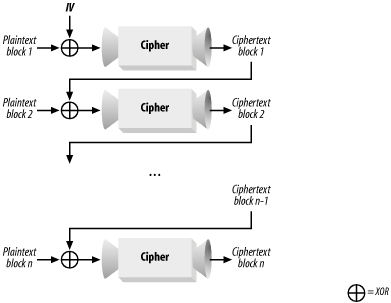 Many libraries already come with an implementation of CBC mode for any ciphers they support. Some don't, however. For example, you may only get an implementation of the raw block cipher when you obtain reference code for a new cipher. Generally, CBC mode requires padding. Because the cipher operates on block-sized quantities, it needs to have a way of handling messages that do not break up evenly into block-sized parts. This is done by adding padding to each message, as described in Recipe 5.11. Padding always adds to the length of a message. If you wish to avoid message expansion, you have a couple of options. You can ensure that your messages always have a length that is a multiple of the block size; in that case, you can simply turn off padding. Otherwise, you have to use a different mode. See Recipe 5.4 for our mode recommendations. If you're really a fan of CBC mode, you can support arbitrary-length messages without message expansion using a modified version of CBC mode known as ciphertext stealing or CTS mode. We do not discuss CTS mode in the book, but there is a recipe about it on this book's web site. Here, we present a reasonably optimized implementation of CBC mode that builds upon the raw block cipher interface presented in Recipe 5.5. It also requires the spc_memset( ) function from Recipe 13.2. 5.6.3.1 The high-level APIThis implementation has two APIs. The first API is the high-level API, which takes a message as input and returns a dynamically allocated result. This API only deals with padded messages. If you want to turn off cipher padding, you will need to use the incremental interface. unsigned char *spc_cbc_encrypt(unsigned char *key, size_t kl, unsigned char *iv,
unsigned char *in, size_t il, size_t *ol);
unsigned char *spc_cbc_decrypt(unsigned char *key, size_t kl, unsigned char *iv,
unsigned char *in, size_t il, size_t *ol);
Both functions pass out the number of bytes in the result by writing to the memory pointed to by the final argument. If decryption fails for some reason, spc_cbc_decrypt( ) will return 0. Such an error means that the input was not a multiple of the block size, or that the padding was wrong.
Here's the implementation of the above interface: #include <stdlib.h>
#include <string.h>
unsigned char *spc_cbc_encrypt(unsigned char *key, size_t kl, unsigned char *iv,
unsigned char *in, size_t il, size_t *ol) {
SPC_CBC_CTX ctx;
size_t tmp;
unsigned char *result;
if (!(result = (unsigned char *)malloc(((il / SPC_BLOCK_SZ) * SPC_BLOCK_SZ) +
SPC_BLOCK_SZ))) return 0;
spc_cbc_encrypt_init(&ctx, key, kl, iv);
spc_cbc_encrypt_update(&ctx, in, il, result, &tmp);
spc_cbc_encrypt_final(&ctx, result+tmp, ol);
*ol += tmp;
return result;
}
unsigned char *spc_cbc_decrypt(unsigned char *key, size_t kl, unsigned char *iv,
unsigned char *in, size_t il, size_t *ol) {
int success;
size_t tmp;
SPC_CBC_CTX ctx;
unsigned char *result;
if (!(result = (unsigned char *)malloc(il))) return 0;
spc_cbc_decrypt_init(&ctx, key, kl, iv);
spc_cbc_decrypt_update(&ctx, in, il, result, &tmp);
if (!(success = spc_cbc_decrypt_final(&ctx, result+tmp, ol))) {
*ol = 0;
spc_memset(result, 0, il);
free(result);
return 0;
}
*ol += tmp;
result = (unsigned char *)realloc(result, *ol);
return result;
}
Note that this code depends on the SPC_CBC_CTX data type, as well as the incremental CBC interface, neither of which we have yet discussed. 5.6.3.2 SPC_CBC_CTX data typeLet's look at the SPC_CBC_CTX data type. It's defined as: typedef struct {
SPC_KEY_SCHED ks;
int ix;
int pad;
unsigned char iv[SPC_BLOCK_SZ];
unsigned char ctbuf[SPC_BLOCK_SZ];
} SPC_CBC_CTX;
The ks field is an expanded version of the cipher key. The ix field is basically used to determine how much data is needed before we have processed data that is a multiple of the block length. The pad field specifies whether the API needs to add padding or should expect messages to be exactly block-aligned. The iv field is used to store the initialization vector for the next block of encryption. The ctbuf field is only used in decryption to cache ciphertext until we have enough to fill a block. 5.6.3.3 Incremental initializationTo begin encrypting or decrypting, we need to initialize the mode. Initialization is different for each mode. Here are the functions for initializing an SPC_CBC_CTX object: void spc_cbc_encrypt_init(SPC_CBC_CTX *ctx, unsigned char *key, size_t kl,
unsigned char *iv) {
SPC_ENCRYPT_INIT(&(ctx->ks), key, kl);
spc_memset(key, 0, kl);
memcpy(ctx->iv, iv, SPC_BLOCK_SZ);
ctx->ix = 0;
ctx->pad = 1;
}
void spc_cbc_decrypt_init(SPC_CBC_CTX *ctx, unsigned char *key, size_t kl,
unsigned char *iv) {
SPC_DECRYPT_INIT(&(ctx->ks), key, kl);
spc_memset(key, 0, kl);
memcpy(ctx->iv, iv, SPC_BLOCK_SZ);
ctx->ix = 0;
ctx->pad = 1;
}
These functions are identical, except that they call the appropriate method for keying, which may be different depending on whether we're encrypting or decrypting. Both of these functions erase the key that you pass in! Note that the initialization vector (IV) must be selected randomly. You should also avoid encrypting more than about 240 blocks of data using a single key. See Recipe 4.9 for more on initialization vectors. Now we can add data as we get it using the spc_cbc_encrypt_update( ) and spc_cbc_decrypt_update( ) functions. These functions are particularly useful when a message comes in pieces. You'll get the same results as if the message had come in all at once. When you wish to finish encrypting or decrypting, you call spc_cbc_encrypt_final( ) or spc_cbc_decrypt_final( ), as appropriate.
5.6.3.4 Incremental encryptingThe function spc_cbc_encrypt_update( ) has the following signature: int spc_cbc_encrypt_update(CBC_CTX *ctx, unsigned char *in, size_t il,
unsigned char *out, size_t *ol);
This function has the following arguments:
This API is in the spirit of PKCS #11,[11] which provides a standard cryptographic interface to hardware. We do this so that the above functions can have the bulk of their implementations replaced with calls to PKCS #11-compliant hardware. Generally, PKCS #11 reverses the order of input and output argument sets. Also, it does not securely wipe key material.
If you are using padding and you know the length of the input message in advance, you can calculate the output length easily. If the message is of a length that is an exact multiple of the block size, the output message will be a block larger. Otherwise, the message will get as many bytes added to it as necessary to make the input length a multiple of the block size. Using integer math, we can calculate the output length as follows, where il is the input length: ((il / SPC_BLOCK_SZ) * SPC_BLOCK_SZ) + SPC_BLOCK_SZ If we do not have the entire message at once, when using padding the easiest thing to do is to assume there may be an additional block of output. That is, if you pass in 7 bytes, allocating 7 + SPC_BLOCK_SZ is safe. If you wish to be a bit more precise, you can always add SPC_BLOCK_SZ bytes to the input length, then reduce the number to the next block-aligned size. For example, if we have an 8-byte block, and we call spc_cbc_encrypt_update( ) with 7 bytes, there is no way to get more than 8 bytes of output, no matter how much data was buffered internally. Note that if no data was buffered internally, we won't get any output! Of course, you can exactly determine the amount of data to pass in if you are keeping track of how many bytes are buffered at any given time (which you can do by looking at ctx->ix). If you do that, add the buffered length to your input length. The amount of output is always the largest block-aligned value less than or equal to this total length. If you're not using padding, you will get a block of output for every block of input. To switch off padding, you can call the following function, passing in a for the second argument: void spc_cbc_set_padding(SPC_CBC_CTX *ctx, int pad) {
ctx->pad = pad;
}
Here's our implementation of spc_cbc_encrypt_update( ): int spc_cbc_encrypt_update(SPC_CBC_CTX *ctx, unsigned char *in, size_t il,
unsigned char *out, size_t *ol) {
/* Keep a ptr to in, which we advance; we calculate ol by subtraction later. */
int i;
unsigned char *start = out;
/* If we have leftovers, but not enough to fill a block, XOR them into the right
* places in the IV slot and return. It's not much stuff, so one byte at a time
* is fine.
*/
if (il < SPC_BLOCK_SZ-ctx->ix) {
while (il--) ctx->iv[ctx->ix++] ^= *in++;
if (ol) *ol = 0;
return 1;
}
/* If we did have leftovers, and we're here, fill up a block then output the
* ciphertext.
*/
if (ctx->ix) {
while (ctx->ix < SPC_BLOCK_SZ) --il, ctx->iv[ctx->ix++] ^= *in++;
SPC_DO_ENCRYPT(&(ctx->ks), ctx->iv, ctx->iv);
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((unsigned int *)out)[i] = ((unsigned int *)(ctx->iv))[i];
out += SPC_BLOCK_SZ;
}
/* Operate on word-sized chunks, because it's easy to do so. You might gain a
* couple of cycles per loop by unrolling and getting rid of i if you know your
* word size a priori.
*/
while (il >= SPC_BLOCK_SZ) {
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((unsigned int *)(ctx->iv))[i] ^= ((unsigned int *)in)[i];
SPC_DO_ENCRYPT(&(ctx->ks), ctx->iv, ctx->iv);
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((unsigned int *)out)[i] = ((unsigned int *)(ctx->iv))[i];
out += SPC_BLOCK_SZ;
in += SPC_BLOCK_SZ;
il -= SPC_BLOCK_SZ;
}
/* Deal with leftovers... one byte at a time is fine. */
for (i = 0; i < il; i++) ctx->iv[i] ^= in[i];
ctx->ix = il;
if (ol) *ol = out-start;
return 1;
}
The following spc_cbc_encrypt_final( ) function outputs any remaining data and securely wipes the key material in the context, along with all the intermediate state. If padding is on, it will output one block. If padding is off, it won't output anything. If padding is off and the total length of the input wasn't a multiple of the block size, spc_cbc_encrypt_final( ) will return 0. Otherwise, it will always succeed. int spc_cbc_encrypt_final(SPC_CBC_CTX *ctx, unsigned char *out, size_t *ol) {
int ret;
unsigned char pad;
if (ctx->pad) {
pad = SPC_BLOCK_SZ - ctx->ix;
while (ctx->ix < SPC_BLOCK_SZ) ctx->iv[ctx->ix++] ^= pad;
SPC_DO_ENCRYPT(&(ctx->ks), ctx->iv, out);
spc_memset(ctx, 0, sizeof(SPC_CBC_CTX));
if(ol) *ol = SPC_BLOCK_SZ;
return 1;
}
if(ol) *ol = 0;
ret = !(ctx->ix);
spc_memset(ctx, 0, sizeof(SPC_CBC_CTX));
return ret;
}
This function has the following arguments:
5.6.3.5 Incremental decryptionThe CBC decryption API is largely similar to the encryption API, with one major exception. When encrypting, we can output a block of data every time we take in a block of data. When decrypting, that's not possible. We can decrypt data, but until we know that a block isn't the final block, we can't output it because part of the block may be padding. Of course, with padding turned off, that restriction could go away, but our API acts the same with padding off, just to ensure consistent behavior. The spc_cbc_decrypt_update( ) function, shown later in this section, has the following signature: int spc_decrypt_update(SPC_CBC_CTX *ctx, unsigned char *in, size_t il,
unsigned char *out, size_t *ol);
This function has the following arguments:
This function can output up to SPC_BLOCK_SZ - 1 bytes more than is input, depending on how much data has previously been buffered. int spc_cbc_decrypt_update(SPC_CBC_CTX *ctx, unsigned char *in, size_t il,
unsigned char *out, size_t *ol) {
int i;
unsigned char *next_iv, *start = out;
/* If there's not enough stuff to fit in ctbuf, dump it in there and return */
if (il < SPC_BLOCK_SZ - ctx->ix) {
while (il--) ctx->ctbuf[ctx->ix++] = *in++;
if (ol) *ol = 0;
return 1;
}
/* If there's stuff in ctbuf, fill it. */
if (ctx->ix % SPC_BLOCK_SZ) {
while (ctx->ix < SPC_BLOCK_SZ) {
ctx->ctbuf[ctx->ix++] = *in++;
--il;
}
}
if (!il) {
if (ol) *ol = 0;
return 1;
}
/* If we get here, and the ctbuf is full, it can't be padding. Spill it. */
if (ctx->ix) {
SPC_DO_DECRYPT(&(ctx->ks), ctx->ctbuf, out);
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++) {
((int *)out)[i] ^= ((int *)ctx->iv)[i];
((int *)ctx->iv)[i] = ((int *)ctx->ctbuf)[i];
}
out += SPC_BLOCK_SZ;
}
if (il > SPC_BLOCK_SZ) {
SPC_DO_DECRYPT(&(ctx->ks), in, out);
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((int *)out)[i] ^= ((int *)ctx->iv)[i];
next_iv = in;
out += SPC_BLOCK_SZ;
in += SPC_BLOCK_SZ;
il -= SPC_BLOCK_SZ;
} else next_iv = ctx->iv;
while (il > SPC_BLOCK_SZ) {
SPC_DO_DECRYPT(&(ctx->ks), in, out);
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((int *)out)[i] ^= ((int *)next_iv)[i];
next_iv = in;
out += SPC_BLOCK_SZ;
in += SPC_BLOCK_SZ;
il -= SPC_BLOCK_SZ;
}
/* Store the IV. */
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((int *)ctx->iv)[i] = ((int *)next_iv)[i];
ctx->ix = 0;
while (il--) ctx->ctbuf[ctx->ix++] = *in++;
if (ol) *ol = out - start;
return 1;
}
Finalizing CBC-mode decryption is done with spc_cbc_decrypt_final( ), whose listing follows. This function will return 1 if there are no problems or 0 if the total input length is not a multiple of the block size or if padding is on and the padding is incorrect. If the call is successful and padding is on, the function will write into the output buffer anywhere from 0 to SPC_BLOCK_SZ bytes. If padding is off, a successful function will always write SPC_BLOCK_SZ bytes into the output buffer. As with spc_cbc_encrypt_final( ), this function will securely erase the contents of the context object before returning. int spc_cbc_decrypt_final(SPC_CBC_CTX *ctx, unsigned char *out, size_t *ol) {
unsigned int i;
unsigned char pad;
if (ctx->ix != SPC_BLOCK_SZ) {
if (ol) *ol = 0;
/* If there was no input, and there's no padding, then everything is OK. */
spc_memset(&(ctx->ks), 0, sizeof(SPC_KEY_SCHED));
spc_memset(ctx, 0, sizeof(SPC_CBC_CTX));
return (!ctx->ix && !ctx->pad);
}
if (!ctx->pad) {
SPC_DO_DECRYPT(&(ctx->ks), ctx->ctbuf, out);
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((int *)out)[i] ^= ((int *)ctx->iv)[i];
if (ol) *ol = SPC_BLOCK_SZ;
spc_memset(ctx, 0, sizeof(SPC_CBC_CTX));
return 1;
}
SPC_DO_DECRYPT(&(ctx->ks), ctx->ctbuf, ctx->ctbuf);
spc_memset(&(ctx->ks), 0, sizeof(SPC_KEY_SCHED));
for (i = 0; i < SPC_BLOCK_SZ / sizeof(int); i++)
((int *)ctx->ctbuf)[i] ^= ((int *)ctx->iv)[i];
pad = ctx->ctbuf[SPC_BLOCK_SZ - 1];
if (pad > SPC_BLOCK_SZ) {
if (ol) *ol = 0;
spc_memset(ctx, 0, sizeof(SPC_CBC_CTX));
return 0;
}
for (i = 1; i < pad; i++) {
if (ctx->ctbuf[SPC_BLOCK_SZ - 1 - i] != pad) {
if (ol) *ol = 0;
spc_memset(ctx, 0, sizeof(SPC_CBC_CTX));
return 0;
}
}
for (i = 0; i < SPC_BLOCK_SZ - pad; i++)
*out++ = ctx->ctbuf[i];
if (ol) *ol = SPC_BLOCK_SZ - pad;
spc_memset(ctx, 0, sizeof(SPC_CBC_CTX));
return 1;
}
5.6.4 See Also
|
| [ Team LiB ] |
|
