|
|
|
4.1 Types of HierarchiesThere are two types of hierarchies that we recognize in this chapter: specialized hierarchies and general hierarchies. In a specialized hierarchy, you are limited in the maximum depth of the hierarchy. As you'll see in the recipes, SQL is quite unique since you can implement proper general hierarchies with unlimited depth. In a general hierarchy, you cannot define a maximum depth. In the first part of this chapter, we are going to show you how specialized hierarchies can be implemented in a SQL Server database. We'll also show you how you can make use of their special property. Our recipe solutions are based on a real-world example of a hierarchical structure used to manage permissions in an online trading system. Next, our discussion will turn to general hierarchies. Because general hierarchies allow nodes to be nested to any depth, manipulating them requires using generalized solutions. Often, these solutions involve recursion. We'll begin by showing you what you can do using a pure hierarchical model, and we'll show both recursive and nonrecursive algorithms. Then, we'll show you how you can improve the efficiency of a hierarchical model by adding what we term service information to it. Before going further into the chapter, we'd like to review some of the terminology that we use when we discuss hierarchies. Figure 4-1 illustrates a hierarchical structure, and many of the elements are labeled with the terms that we use to refer to them. Figure 4-1. A hierarchical structure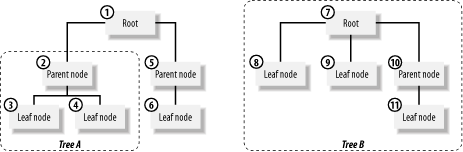 The following list contains our definitions for the terms shown in Figure 4-1, as well as for some other terms that we use in this chapter:
In a hierarchy, child nodes are subordinate to, and belong to, their parents. If you delete a node, or move a node, that operation affects not only the node on which you are operating, but also all of its children. For example, if you delete node 2, as shown in Figure 4-1, you are also implicitly deleting nodes 3 and 4. 4.1.1 Specialized HierarchiesSpecialized hierarchies can be found in almost any real-world application. However, they aren't always manifested in an obvious way, and programmers often don't even realize that what they are actually doing is programming a hierarchy. When programming for a specialized hierarchy, you can take advantage of limitations such as a limited number of nodes, a limited number of levels, the fact that only leaves hold data, or some other specialized aspect of the hierarchy in question. As a basis for the recipes in this chapter, we've used a permission-hierarchy example that is taken from an online trading system that is actually in production use. We've simplified our example somewhat for demonstration purposes. The purpose of the mechanism is to implement support for an order-routing system in which traders have different permissions relating to trades that they can make. An automatic system processes orders according to given permission rules. If a trader sends an order through a system for which he is not authorized, the system rejects the order before submitting it to the market. The following data is an example of some of the rules that the system must enforce: Trader Type Limit --------------------------- Alex Shares 100 Alex Futures 10 Alex Bond 10 Cindy Shares 1000 Cindy Bonds 1000 Michael Shares 200 ... As you can see, there are several types of permissions granted to each trader. Alex, for example, can trade shares of stock in blocks of no more than 100 shares. Cindy, on the other hand, is allowed to trade in blocks of up to 1,000 shares. If you were designing a database structure to hold rules like these, the simplistic approach would be simply to define permissions for each specific trader using the system. However, it's likely to be more practical to group those permissions so that supervisors can easily grant a set of permissions to a particular trader. For example, you could have permission groups for commodity traders, future traders, and spot market traders. The resulting hierarchy would be the limited hierarchy shown in Figure 4-2. Figure 4-2. The limited-trading permission hierarchy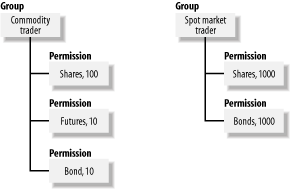 Some might look at this scheme and see two distinct entities: groups and permissions. That's probably a valid view, but we would argue that, at a higher level of abstraction, this structure represents a limited hierarchy of only two levels. The highest level is the group level, and the level below that is the permission level. When writing code to query and manage this hierarchy, you can take advantage of the fact that it's limited to only two levels of depth. You can use solutions that are specific for that case that are more efficient than those that you would need to navigate a more generalized and unrestricted hierarchy. The recipes we have in this chapter highlight the considerations that you need to take into account, as well as the efficiencies that you gain, when working with a specialized hierarchy such as that shown in Figure 4-2. 4.1.2 General HierarchiesThe standard model for representing general hierarchies is to set up a parent/child relationship. The implementation in Transact-SQL, however, is different from tree-structure implementations in other programming languages. Hierarchical structures implemented in Transact-SQL have two characteristics that distinguish them from hierarchical structures implemented in a programming language such as C:
Programmers using C, or other procedural languages, to implement hierarchies usually deal with fixed-size structures in which the parent and child nodes are linked with pointers. Moving from one node to another is fairly inexpensive in terms of the resources that are consumed, because such a move involves only the swapping of a couple of pointers in memory. With SQL, on the other hand, a move between nodes usually involves disk I/O, because each node ends up being a row in a table. Disk I/O is expensive in terms of the time and resources consumed, so SQL programmers need to be very careful about the number of visits they make to each node. An advantage of SQL, though, is that it's easy to allow for an unlimited number of children. Unlike the fixed structures often used in procedural languages, database tables have no arbitrary limit on the number of rows they may contain. The design of a hierarchy is a good example of a case in which how you model your data is much more important than the actual algorithms that you use to manipulate your data. The following CREATE TABLE statement shows the structure most often used to represent general hierarchies in a relational database: CREATE TABLE Hierarchy( VertexId INTEGER, Parent INTEGER, ... PRIMARY KEY(VertexId) ) In this structure, each row in the Hierarchy table represents one node. The VertexId field contains a unique address for each node. Each node then points back to its parent by storing the parent's VertexId value in the Parent field. Using such a structure, you can create an unlimited number of children for each parent. SQL programmers have been using this type of structure for some time, and it looks great from a design point of view. However, SQL has strangely weak support for hierarchies. If you aren't careful, the code you write to manipulate a hierarchical structure, such as the one shown here, can be inefficient and lead to a host of performance problems. We have several recipes in this chapter that show reasonably efficient solutions for common operations that you'll need to perform on generalized hierarchical data. These solutions are based on the example of a project-tracking database that you manage. In this project-tracking database, you store data about projects and their subprojects. Any given project can be broken up into an arbitrary number of subprojects for planning purposes. Those subprojects can be further broken up into even smaller subprojects. This process can continue for any number of levels of depth. Eventually, you get down to the bottom-level in which the subprojects have no children. A subproject with no children is referred to as a task. Your job is to build SQL queries, procedures, and functions in support of a project-tracking application. Data about projects and subprojects is stored in the Projects table, which is defined as follows: CREATE TABLE Projects( Name VARCHAR(20), Cost INTEGER, Parent INTEGER, VertexId INTEGER, Primary key(VertexId) ) The first two columns the Name and Cost columns represent the actual project and subproject data. In a real application, you would have more information than that, but these two columns will suffice for the purposes of example. The remaining two columns in the table are used to define the hierarchy. The VertexId column contains a unique identifier for each project, subproject, and task. The Parent column in any given row points to the parent project or subproject for that row. Figure 4-3 provides a visual illustration of this hierarchy. Figure 4-3. The general project-tracking hierarchy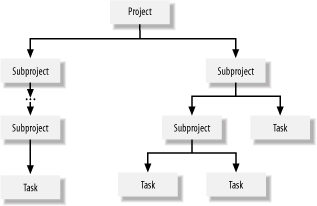 The scripts named ch04.*.objects.sql (downloadable from this book's web site) will create and populate all the tables used in this chapter's recipes. When you run the script, you'll get the following data in the Projects table: Name Cost Parent VertexId -------------------- ----------- ----------- ----------- New SW 0 0 1 Specifications 0 1 2 Interviews 5 2 3 Drafts 10 2 4 Consolidations 2 2 5 Final document 15 2 6 Presentation 1 6 7 Prototype 0 1 8 UI Design 10 8 9 Calculations 10 8 10 Correctness Testing 3 10 11 Database 10 8 12 Development 30 1 13 UI Implementation 10 13 14 Coding 20 13 15 Initial testing 40 13 16 Beta testing 40 1 17 Final adjustments 5 17 18 Production testing 20 1 19 As you can see, the Parent column is used to maintain the hierarchical structure of the project data. Each child has only one parent, so only one Parent column is needed for each row in the table. Consequently, an unlimited number of children can be created for any given project or subproject. Figure 4-4 shows a graphical view of our example project. Figure 4-4. The sample project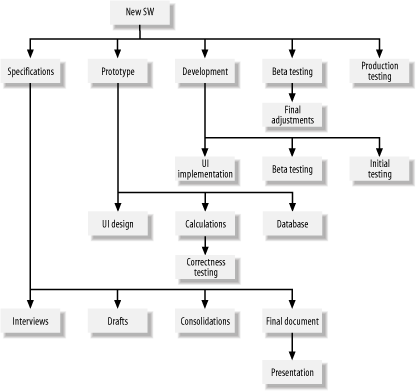 |
|
|
|