| [ Team LiB ] |
|
2.1 Information Flow and Other MetaphorsPublishing on the Web can be visualized as a flow of information. Ultimately, information goes from the brain of the writer to the brain of the reader, but we don't want to concern ourselves with the biological bits right now. Let's assume that whatever content you have created is safely digitized and located on a computer. The job now is to serve this file to your readers. If you have written your content directly in HTML and uploaded it into the correct directory on your server, this step is already done. Most people, however, rely on some form of Content Management System (CMS). The definition of CMS is quite fluid. Software vendors will say that a real CMS must be a multithousand-dollar application running on expensive hardware, others will point to free web-based weblogging services such as Blogger, and still others will say that a CMS is anything that takes raw content and does something with it to present it to the public � this can include plain human intervention with a text editor and some patience. Whichever camp you fall into, your CMS will most likely have the structure shown in Figure 2-1. Here we see that the raw content is held in a repository, then passed through some form of transformation, and finally served to the end user in the correct format. This process can take any of the following paths: Figure 2-1. An outline of a theoretical CMS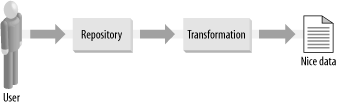
Of course, we can easily add more than one repository:
With Content Management Systems of any worth, the transformation step can be replicated. Not only can we take more than one input, but we can also create more than one output from the content. In this way, we can produce both HTML and an RSS feed as shown in Figure 2-2. Figure 2-2. A CMS producing HTML and an RSS feed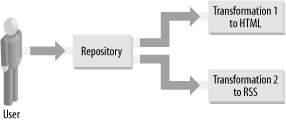 In the popular weblogging CMSs, such as Movable Type, the transformations are made with templates containing variables. The CMS replaces the variables with the correct values and saves the static file in the correct path on the web server. Other CMSs may run the translation stage on the fly, with script-driven XSLT or PHP transformations creating the requested document. In this case, the final document may never be saved to disk at all. It must be said that it is perfectly OK for a CMS to produce RSS exclusively. There are many situations in which you might want to create an RSS feed only. This is not a problem � indeed, it probably indicates something quite innovative. |
| [ Team LiB ] |
|
 Perl script
Perl script