| [ Team LiB ] |
|
4.2 Defining the SchemaThe first step in implementing a directory is determining what information to store in the directory. The naming context of your server has already been defined as: dc=plainjoe,dc=org Store contact information for employees in the people organzational unit: ou=people,dc=plainjoe,dc=org There are several ways to identify the data that should be placed in an employee's entry. Information stored in an existing Human Resources database can provide a good starting point. Of course, you may not want to place all of this information in your directory. As a general rule, I prefer not to put information in a directory if that data probably won't be used. If it turns out that the data is actually necessary, you can always add it later. Eliminating unnecessary data at the start means that there's less to worry about when you start thinking about protecting the directory against unauthorized access. An alternative to starting with an existing database is to determine which employee attributes you wish to make available and define a schema to match that list. The reverse also works: you can select a standard schema and use the attributes already defined. I prefer this approach because it makes it easy to change from one server vendor to another. Widely used, standard schemas are more likely to be supported by a wide range of vendors. Custom, in-house schemas may need to be redesigned to adapt to a new vendor (or even a new version from the same vendor). For your directory, the inetOrgPerson schema defined in RFC 2798 is more than adequate. From Section 3.5.1 in Chapter 3, we know that this object class and associated attributes are defined in OpenLDAP's inetorgperson.schema file. As shown in Figure 4-1, an inetOrgPerson is a descendant of the organizationalPerson, which was itself derived from the person object class. Figure 4-1. Hierarchy of the inetOrgPerson object class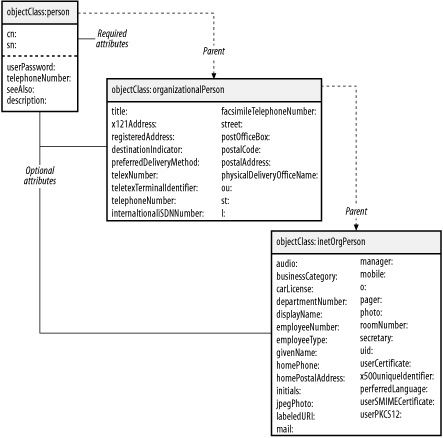 The union of these object classes defines the set of required and optional attributes that are available. This means that the only required attributes in an inetOrgPerson object are the cn and sn attributes derived from the person object class.
Your directory will use the cn attribute as the RDN for each entry. Remember that the RDN of an entry must be unique among siblings of a common parent. In larger organizations, two people may have the same first and last name. In these cases, using a more specific value for the cn, such as including a middle name (or initial), can alleviate name collisions. Another way to reduce the number of name collisions is to redesign the directory layout to reduce the total number of user entries sharing a common parent. In other words, group employees in some type of logical container, such as a departmental organizational unit. Figure 4-2 illustrates how this design avoids namespace conflicts. In this directory the "John Arbuckle" in sales is different from the "John Arbuckle" in engineering because the entries possess different parent nodes. Figure 4-2. Using organizational unit to avoid collisions of common names (cn)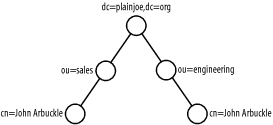 For our example, going with a single container of ou=people is fine; furthermore, our employee base is small enough to use an employee's common name (cn) without fear of conflict. Figure 4-3 shows the directory namespace developed so far. Figure 4-3. Directory namespace for company address book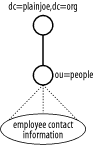 Here is an employee entry that contains the attributes needed for our directory. Notice that the two required attributes outlined in Figure 4-1, cn and sn, are present in addition to several optional attributes. ## LDIF entry for employee "Gerald W. Carter" dn: cn=Gerald W. Carter,ou=people,dc=plainjoe,dc=org objectClass: inetOrgPerson cn: Gerald W. Carter sn: Carter mail: [email protected] mail: [email protected] labeledURI: http://www.plainjoe.org/ roomNumber: 1234 Dudley Hall departmentNumber: Engineering telephoneNumber: 222-555-2345 pager: 222-555-6789 mobile: 222-555-1011 |
| [ Team LiB ] |
|
