
Linux Network Administrator's Guide, 2nd Edition
By Olaf Kirch & Terry Dawson2nd Edition June 2000
1-56592-400-2, Order Number: 4002
506 pages, $34.95
|
|
|
|
|
Linux Network Administrator's Guide, 2nd EditionBy Olaf Kirch & Terry Dawson2nd Edition June 2000 1-56592-400-2, Order Number: 4002 506 pages, $34.95 |
Chapter 2
Issues of TCP/IP NetworkingContents:
Networking Interfaces
IP Addresses
Address Resolution
IP Routing
The Internet Control Message Protocol
Resolving Host NamesIn this chapter we turn to the configuration decisions you'll need to make when connecting your Linux machine to a TCP/IP network, including dealing with IP addresses, hostnames, and routing issues. This chapter gives you the background you need in order to understand what your setup requires, while the next chapters cover the tools you will use.
To learn more about TCP/IP and the reasons behind it, refer to the three-volume set Internetworking with TCP/IP, by Douglas R. Comer (Prentice Hall). For a more detailed guide to managing a TCP/IP network, see TCP/IP Network Administration by Craig Hunt (O'Reilly).
Networking Interfaces
To hide the diversity of equipment that may be used in a networking environment, TCP/IP defines an abstract interface through which the hardware is accessed. This interface offers a set of operations that is the same for all types of hardware and basically deals with sending and receiving packets.
For each peripheral networking device, a corresponding interface has to be present in the kernel. For example, Ethernet interfaces in Linux are called by such names as eth0 and eth1; PPP (discussed in Chapter 8, The Point-to-Point Protocol) interfaces are named ppp0 and ppp1; and FDDI interfaces are given names like fddi0 and fddi1. These interface names are used for configuration purposes when you want to specify a particular physical device in a configuration command, and they have no meaning beyond this use.
Before being used by TCP/IP networking, an interface must be assigned an IP address that serves as its identification when communicating with the rest of the world. This address is different from the interface name mentioned previously; if you compare an interface to a door, the address is like the nameplate pinned on it.
Other device parameters may be set, like the maximum size of datagrams that can be processed by a particular piece of hardware, which is referred to as Maximum Transfer Unit (MTU). Other attributes will be introduced later. Fortunately, most attributes have sensible defaults.
IP Addresses
As mentioned in Chapter 1, Introduction to Networking, the IP networking protocol understands addresses as 32-bit numbers. Each machine must be assigned a number unique to the networking environment.[1] If you are running a local network that does not have TCP/IP traffic with other networks, you may assign these numbers according to your personal preferences. There are some IP address ranges that have been reserved for such private networks. These ranges are listed in Table 2.1. However, for sites on the Internet, numbers are assigned by a central authority, the Network Information Center (NIC).[2]
[1] The version of the Internet Protocol most frequently used on the Internet is Version 4. A lot of effort has been expended in designing a replacement called IP Version 6. IPv6 uses a different addressing scheme and larger addresses. Linux has an implementation of IPv6, but it isn't ready to document it in this book yet. The Linux kernel support for IPv6 is good, but a large number of network applications need to be modified to support it as well. Stay tuned.
[2] Frequently, IP addresses will be assigned to you by the provider from whom you buy your IP connectivity. However, you may also apply to the NIC directly for an IP address for your network by sending email to [email protected], or by using the form at http://www.internic.net/.
IP addresses are split up into four eight-bit numbers called octets for readability. For example, quark.physics.groucho.edu has an IP address of 0x954C0C04, which is written as 149.76.12.4. This format is often referred to as dotted quad notation.
Another reason for this notation is that IP addresses are split into a network number, which is contained in the leading octets, and a host number, which is the remainder. When applying to the NIC for IP addresses, you are not assigned an address for each single host you plan to use. Instead, you are given a network number and allowed to assign all valid IP addresses within this range to hosts on your network according to your preferences.
The size of the host part depends on the size of the network. To accommodate different needs, several classes of networks, defining different places to split IP addresses, have been defined. The class networks are described here:
- Class A
Class A comprises networks 1.0.0.0 through 127.0.0.0. The network number is contained in the first octet. This class provides for a 24-bit host part, allowing roughly 1.6 million hosts per network.
- Class B
Class B contains networks 128.0.0.0 through 191.255.0.0; the network number is in the first two octets. This class allows for 16,320 nets with 65,024 hosts each.
- Class C
Class C networks range from 192.0.0.0 through 223.255.255.0, with the network number contained in the first three octets. This class allows for nearly 2 million networks with up to 254 hosts.
- Classes D, E, and F
Addresses falling into the range of 224.0.0.0 through 254.0.0.0 are either experimental or are reserved for special purpose use and don't specify any network. IP Multicast, which is a service that allows material to be transmitted to many points on an internet at one time, has been assigned addresses from within this range.
If we go back to the example in Chapter 1, we find that 149.76.12.4, the address of quark, refers to host 12.4 on the class B network 149.76.0.0.
You may have noticed that not all possible values in the previous list were allowed for each octet in the host part. This is because octets 0 and 255 are reserved for special purposes. An address where all host part bits are 0 refers to the network, and an address where all bits of the host part are 1 is called a broadcast address. This refers to all hosts on the specified network simultaneously. Thus, 149.76.255.255 is not a valid host address, but refers to all hosts on network 149.76.0.0.
A number of network addresses are reserved for special purposes. 0.0.0.0 and 127.0.0.0 are two such addresses. The first is called the default route, and the latter is the loopback address. The default route has to do with the way the IP routes datagrams.
Network 127.0.0.0 is reserved for IP traffic local to your host. Usually, address 127.0.0.1 will be assigned to a special interface on your host, the loopback interface, which acts like a closed circuit. Any IP packet handed to this interface from TCP or UDP will be returned to them as if it had just arrived from some network. This allows you to develop and test networking software without ever using a "real" network. The loopback network also allows you to use networking software on a standalone host. This may not be as uncommon as it sounds; for instance, many UUCP sites don't have IP connectivity at all, but still want to run the INN news system. For proper operation on Linux, INN requires the loopback interface.
Some address ranges from each of the network classes have been set aside and designated "reserved" or "private" address ranges. These addresses are reserved for use by private networks and are not routed on the Internet. They are commonly used by organizations building their own intranet, but even small networks often find them useful. The reserved network addresses appear in Table 2.1.
Table 2.1: IP Address Ranges Reserved for Private Use Class Networks A 10.0.0.0 through 10.255.255.255 B 172.16.0.0 through 172.31.0.0 C 192.168.0.0 through 192.168.255.0 Address Resolution
Now that you've seen how IP addresses are composed, you may be wondering how they are used on an Ethernet or Token Ring network to address different hosts. After all, these protocols have their own addresses to identify hosts that have absolutely nothing in common with an IP address, don't they? Right.
A mechanism is needed to map IP addresses onto the addresses of the underlying network. The mechanism used is the Address Resolution Protocol (ARP). In fact, ARP is not confined to Ethernet or Token Ring, but is used on other types of networks, such as the amateur radio AX.25 protocol. The idea underlying ARP is exactly what most people do when they have to find Mr. X in a throng of 150 people: the person who wants him calls out loudly enough that everyone in the room can hear them, expecting him to respond if he is there. When he responds, we know which person he is.
When ARP wants to find the Ethernet address corresponding to a given IP address, it uses an Ethernet feature called broadcasting, in which a datagram is addressed to all stations on the network simultaneously. The broadcast datagram sent by ARP contains a query for the IP address. Each receiving host compares this query to its own IP address and if it matches, returns an ARP reply to the inquiring host. The inquiring host can now extract the sender's Ethernet address from the reply.
You may wonder how a host can reach an Internet address that may be on a different network halfway around the world. The answer to this question involves routing, namely finding the physical location of a host in a network. We will discuss this issue further in the next section.
Let's talk a little more about ARP. Once a host has discovered an Ethernet address, it stores it in its ARP cache so that it doesn't have to query for it again the next time it wants to send a datagram to the host in question. However, it is unwise to keep this information forever; the remote host's Ethernet card may be replaced because of technical problems, so the ARP entry becomes invalid. Therefore, entries in the ARP cache are discarded after some time to force another query for the IP address.
Sometimes it is also necessary to find the IP address associated with a given Ethernet address. This happens when a diskless machine wants to boot from a server on the network, which is a common situation on Local Area Networks. A diskless client, however, has virtually no information about itself -- except for its Ethernet address! So it broadcasts a message containing a request asking a boot server to provide it with an IP address. There's another protocol for this situation named Reverse Address Resolution Protocol (RARP). Along with the BOOTP protocol, it serves to define a procedure for bootstrapping diskless clients over the network.
IP Routing
We now take up the question of finding the host that datagrams go to based on the IP address. Different parts of the address are handled in different ways; it is your job to set up the files that indicate how to treat each part.
IP Networks
When you write a letter to someone, you usually put a complete address on the envelope specifying the country, state, and Zip Code. After you put it in the mailbox, the post office will deliver it to its destination: it will be sent to the country indicated, where the national service will dispatch it to the proper state and region. The advantage of this hierarchical scheme is obvious: wherever you post the letter, the local postmaster knows roughly which direction to forward the letter, but the postmaster doesn't care which way the letter will travel once it reaches its country of destination.
IP networks are structured similarly. The whole Internet consists of a number of proper networks, called autonomous systems. Each system performs routing between its member hosts internally so that the task of delivering a datagram is reduced to finding a path to the destination host's network. As soon as the datagram is handed to any host on that particular network, further processing is done exclusively by the network itself.
Subnetworks
This structure is reflected by splitting IP addresses into a host and network part, as explained previously. By default, the destination network is derived from the network part of the IP address. Thus, hosts with identical IP network numbers should be found within the same network.[3]
[3] Autonomous systems are slightly more general. They may comprise more than one IP network.
It makes sense to offer a similar scheme inside the network, too, since it may consist of a collection of hundreds of smaller networks, with the smallest units being physical networks like Ethernets. Therefore, IP allows you to subdivide an IP network into several subnets.
A subnet takes responsibility for delivering datagrams to a certain range of IP addresses. It is an extension of the concept of splitting bit fields, as in the A, B, and C classes. However, the network part is now extended to include some bits from the host part. The number of bits that are interpreted as the subnet number is given by the so-called subnet mask, or netmask. This is a 32-bit number too, which specifies the bit mask for the network part of the IP address.
The campus network of Groucho Marx University is an example of such a network. It has a class B network number of 149.76.0.0, and its netmask is therefore 255.255.0.0.
Internally, GMU's campus network consists of several smaller networks, such various departments' LANs. So the range of IP addresses is broken up into 254 subnets, 149.76.1.0 through 149.76.254.0. For example, the department of Theoretical Physics has been assigned 149.76.12.0. The campus backbone is a network in its own right, and is given 149.76.1.0. These subnets share the same IP network number, while the third octet is used to distinguish between them. They will thus use a subnet mask of 255.255.255.0.
Figure 2.1 shows how 149.76.12.4, the address of quark, is interpreted differently when the address is taken as an ordinary class B network and when used with subnetting.
Figure 2.1: Subnetting a class B network
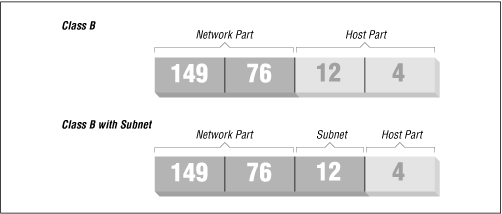
It is worth noting that subnetting (the technique of generating subnets) is only an internal division of the network. Subnets are generated by the network owner (or the administrators). Frequently, subnets are created to reflect existing boundaries, be they physical (between two Ethernets), administrative (between two departments), or geographical (between two locations), and authority over each subnet is delegated to some contact person. However, this structure affects only the network's internal behavior, and is completely invisible to the outside world.
Gateways
Subnetting is not only a benefit to the organization; it is frequently a natural consequence of hardware boundaries. The viewpoint of a host on a given physical network, such as an Ethernet, is a very limited one: it can only talk to the host of the network it is on. All other hosts can be accessed only through special-purpose machines called gateways. A gateway is a host that is connected to two or more physical networks simultaneously and is configured to switch packets between them.
Figure 2.2 shows part of the network topology at Groucho Marx University (GMU). Hosts that are on two subnets at the same time are shown with both addresses.
Figure 2.2: A part of the net topology at Groucho Marx University
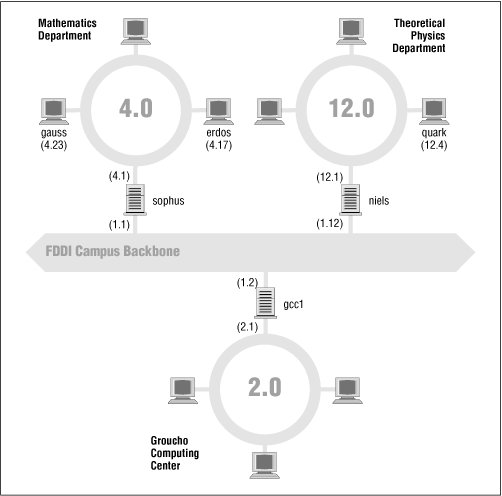
Different physical networks have to belong to different IP networks for IP to be able to recognize if a host is on a local network. For example, the network number 149.76.4.0 is reserved for hosts on the mathematics LAN. When sending a datagram to quark, the network software on erdos immediately sees from the IP address 149.76.12.4 that the destination host is on a different physical network, and therefore can be reached only through a gateway (sophus by default).
sophus itself is connected to two distinct subnets: the Mathematics department and the campus backbone. It accesses each through a different interface, eth0 and fddi0, respectively. Now, what IP address do we assign it? Should we give it one on subnet 149.76.1.0, or on 149.76.4.0?
The answer is: "both." sophus has been assigned the address 149.76.1.1 for use on the 149.76.1.0 network and address 149.76.4.1 for use on the 149.76.4.0 network. A gateway must be assigned one IP address for each network it belongs to. These addresses -- along with the corresponding netmask -- are tied to the interface through which the subnet is accessed. Thus, the interface and address mapping for sophus would look like this:
Interface Address Netmask eth0 149.76.4.1 255.255.255.0 fddi0 149.76.1.1 255.255.255.0 lo 127.0.0.1 255.0.0.0 The last entry describes the loopback interface lo, which we talked about earlier.
Generally, you can ignore the subtle difference between attaching an address to a host or its interface. For hosts that are on one network only, like erdos, you would generally refer to the host as having this-and-that IP address, although strictly speaking, it's the Ethernet interface that has this IP address. The distinction is really important only when you refer to a gateway.
The Routing Table
We now focus our attention on how IP chooses a gateway to use to deliver a datagram to a remote network.
We have seen that erdos, when given a datagram for quark, checks the destination address and finds that it is not on the local network. erdos therefore sends the datagram to the default gateway sophus, which is now faced with the same task. sophus recognizes that quark is not on any of the networks it is connected to directly, so it has to find yet another gateway to forward it through. The correct choice would be niels, the gateway to the Physics department. sophus thus needs information to associate a destination network with a suitable gateway.
IP uses a table for this task that associates networks with the gateways by which they may be reached. A catch-all entry (the default route) must generally be supplied too; this is the gateway associated with network 0.0.0.0. All destination addresses match this route, since none of the 32 bits are required to match, and therefore packets to an unknown network are sent through the default route. On sophus, the table might look like this:
Network Netmask Gateway Interface 149.76.1.0 255.255.255.0 - fddi0 149.76.2.0 255.255.255.0 149.76.1.2 fddi0 149.76.3.0 255.255.255.0 149.76.1.3 fddi0 149.76.4.0 255.255.255.0 - eth0 149.76.5.0 255.255.255.0 149.76.1.5 fddi0 ... ... ... ... 0.0.0.0 0.0.0.0 149.76.1.2 fddi0 If you need to use a route to a network that sophus is directly connected to, you don't need a gateway; the gateway column here contains a hyphen.
The process for identifying whether a particular destination address matches a route is a mathematical operation. The process is quite simple, but it requires an understanding of binary arithmetic and logic: A route matches a destination if the network address logically ANDed with the netmask precisely equals the destination address logically ANDed with the netmask.
Translation: a route matches if the number of bits of the network address specified by the netmask (starting from the left-most bit, the high order bit of byte one of the address) match that same number of bits in the destination address.
When the IP implementation is searching for the best route to a destination, it may find a number of routing entries that match the target address. For example, we know that the default route matches every destination, but datagrams destined for locally attached networks will match their local route, too. How does IP know which route to use? It is here that the netmask plays an important role. While both routes match the destination, one of the routes has a larger netmask than the other. We previously mentioned that the netmask was used to break up our address space into smaller networks. The larger a netmask is, the more specifically a target address is matched; when routing datagrams, we should always choose the route that has the largest netmask. The default route has a netmask of zero bits, and in the configuration presented above, the locally attached networks have a 24-bit netmask. If a datagram matches a locally attached network, it will be routed to the appropriate device in preference to following the default route because the local network route matches with a greater number of bits. The only datagrams that will be routed via the default route are those that don't match any other route.
You can build routing tables by a variety of means. For small LANs, it is usually most efficient to construct them by hand and feed them to IP using the route command at boot time (see Chapter 5, Configuring TCP/IP Networking). For larger networks, they are built and adjusted at runtime by routing daemons; these daemons run on central hosts of the network and exchange routing information to compute "optimal" routes between the member networks.
Depending on the size of the network, you'll need to use different routing protocols. For routing inside autonomous systems (such as the Groucho Marx campus), the internal routing protocols are used. The most prominent one of these is the Routing Information Protocol (RIP), which is implemented by the BSD routed daemon. For routing between autonomous systems, external routing protocols like External Gateway Protocol (EGP) or Border Gateway Protocol (BGP) have to be used; these protocols, including RIP, have been implemented in the University of Cornell's gated daemon.
Metric Values
We depend on dynamic routing to choose the best route to a destination host or network based on the number of hops. Hops are the gateways a datagram has to pass before reaching a host or network. The shorter a route is, the better RIP rates it. Very long routes with 16 or more hops are regarded as unusable and are discarded.
RIP manages routing information internal to your local network, but you have to run gated on all hosts. At boot time, gated checks for all active network interfaces. If there is more than one active interface (not counting the loopback interface), it assumes the host is switching packets between several networks and will actively exchange and broadcast routing information. Otherwise, it will only passively receive RIP updates and update the local routing table.
When broadcasting information from the local routing table, gated computes the length of the route from the so-called metric value associated with the routing table entry. This metric value is set by the system administrator when configuring the route, and should reflect the actual route cost.[4] Therefore, the metric of a route to a subnet that the host is directly connected to should always be zero, while a route going through two gateways should have a metric of two. You don't have to bother with metrics if you don't use RIP or gated.
[4] The cost of a route can be thought of, in a simple case, as the number of hops required to reach the destination. Proper calculation of route costs can be a fine art in complex network designs.
The Internet Control Message Protocol
IP has a companion protocol that we haven't talked about yet. This is the Internet Control Message Protocol (ICMP), used by the kernel networking code to communicate error messages to other hosts. For instance, assume that you are on erdos again and want to telnet to port 12345 on quark, but there's no process listening on that port. When the first TCP packet for this port arrives on quark, the networking layer will recognize this arrival and immediately return an ICMP message to erdos stating "Port Unreachable."
The ICMP protocol provides several different messages, many of which deal with error conditions. However, there is one very interesting message called the Redirect message. It is generated by the routing module when it detects that another host is using it as a gateway, even though a much shorter route exists. For example, after booting, the routing table of sophus may be incomplete. It might contain the routes to the Mathematics network, to the FDDI backbone, and the default route pointing at the Groucho Computing Center's gateway (gcc1). Thus, packets for quark would be sent to gcc1 rather than to niels, the gateway to the Physics department. When receiving such a datagram, gcc1 will notice that this is a poor choice of route and will forward the packet to niels, meanwhile returning an ICMP Redirect message to sophus telling it of the superior route.
This seems to be a very clever way to avoid manually setting up any but the most basic routes. However, be warned that relying on dynamic routing schemes, be it RIP or ICMP Redirect messages, is not always a good idea. ICMP Redirect and RIP offer you little or no choice in verifying that some routing information is indeed authentic. This situation allows malicious good-for-nothings to disrupt your entire network traffic, or even worse. Consequently, the Linux networking code treats Network Redirect messages as if they were Host Redirects. This minimizes the damage of an attack by restricting it to just one host, rather than the whole network. On the flip side, it means that a little more traffic is generated in the event of a legitimate condition, as each host causes the generation of an ICMP Redirect message. It is generally considered bad practice to rely on ICMP redirects for anything these days.
Resolving Host Names
As described previously, addressing in TCP/IP networking, at least for IP Version 4, revolves around 32-bit numbers. However, you will have a hard time remembering more than a few of these numbers. Therefore, hosts are generally known by "ordinary" names such as gauss or strange. It becomes the application's duty to find the IP address corresponding to this name. This process is called hostname resolution.
When an application needs to find the IP address of a given host, it relies on the library functions gethostbyname(3) and gethostbyaddr(3). Traditionally, these and a number of related procedures were grouped in a separate library called the resolverlibrary; on Linux, these functions are part of the standard libc. Colloquially, this collection of functions is therefore referred to as "the resolver." Resolver name configuration is detailed in Chapter 6, Name Service and Resolver Configuration.
On a small network like an Ethernet or even a cluster of Ethernets, it is not very difficult to maintain tables mapping hostnames to addresses. This information is usually kept in a file named /etc/hosts. When adding or removing hosts, or reassigning addresses, all you have to do is update the hosts file on all hosts. Obviously, this will become burdensome with networks that comprise more than a handful of machines.
One solution to this problem is the Network Information System (NIS), developed by Sun Microsystems, colloquially called YP or Yellow Pages. NIS stores the hosts file (and other information) in a database on a master host from which clients may retrieve it as needed. Still, this approach is suitable only for medium-sized networks such as LANs, because it involves maintaining the entire hosts database centrally and distributing it to all servers. NIS installation and configuration is discussed in detail in Chapter 13, The Network Information System.
On the Internet, address information was initially stored in a single HOSTS.TXT database, too. This file was maintained at the Network Information Center (NIC), and had to be downloaded and installed by all participating sites. When the network grew, several problems with this scheme arose. Besides the administrative overhead involved in installing HOSTS.TXT regularly, the load on the servers that distributed it became too high. Even more severe, all names had to be registered with the NIC, which made sure that no name was issued twice.
This is why a new name resolution scheme was adopted in 1994: the Domain Name System. DNS was designed by Paul Mockapetris and addresses both problems simultaneously. We discuss the Domain Name System in detail in Chapter 6.
Back to: Sample Chapter Index
Back to: Linux Network Administrator's Guide, 2nd Edition
© 2001, O'Reilly & Associates, Inc.
[email protected]