| I l@ve RuBoard |
The next major built-in type is the Python string an ordered collection of characters, used to store and represent text-based information. From a functional perspective, strings can be used to represent just about anything that can be encoded as text: symbols and words (e.g., your name), contents of text files loaded into memory, and so on.
You've probably used strings in other languages too; Python's strings serve the same role as character arrays in languages such as C, but Python's strings are a higher level tool. Unlike C, there is no char type in Python, only one-character strings. And strictly speaking, Python strings are categorized as immutable sequences big words that just mean that they respond to common sequence operations but can't be changed in place. In fact, strings are representative of the larger class of objects called sequences; we'll have more to say about what this means in a moment, but pay attention to the operations introduced here, because they'll work the same on types we'll see later.
Table 2.4 introduces common string constants and operations. Strings support expression operations such as concatenation (combining strings), slicing (extracting sections), indexing (fetching by offset), and so on. Python also provides a set of utility modules for processing strings you import. For instance, the string module exports most of the standard C library's string handling tools, and the regex and re modules add regular expression matching for strings (all of which are discussed in Chapter 8).
Empty strings are written as two quotes with nothing in between. Notice that string constants can be written enclosed in either single or double quotes; the two forms work the same, but having both allows a quote character to appear inside a string without escaping it with a backslash (more on backslashes later). The third line in the table also mentions a triple-quoted form; when strings are enclosed in three quotes, they may span any number of lines. Python collects all the triple-quoted text into a multiline string with embedded newline characters.
Rather than getting into too many details right away, let's interact with the Python interpreter again to illustrate the operations in Table 2.4.
Strings can be concatenated using the + operator, and repeated using the * operator. Formally, adding two string objects creates a new string object with the contents of its operands joined; repetition is much like adding a string to itself a number of times. In both cases, Python lets you create arbitrarily sized strings; there's no need to predeclare anything in Python, including the sizes of data structures.[5] Python also provides a len built-in function that returns the length of strings (and other objects with a length):
[5] Unlike C character arrays, you don't need to allocate or manage storage arrays when using Python strings. Simply create string objects as needed, and let Python manage the underlying memory space. Internally, Python reclaims unused objects' memory space automatically, using a reference-count garbage collection strategy. Each object keeps track of the number of names, data-structures, etc. that reference it; when the count reaches zero, Python frees the object's space. This scheme means Python doesn't have to stop and scan all of memory to find unused space to free; it also means that objects that reference themselves might not be collected automatically.
% python
>>> len('abc') # length: number items
3
>>> 'abc' + 'def' # concatenation: a new string
'abcdef'
>>> 'Ni!' * 4 # like "Ni!" + "Ni!" + ...
'Ni!Ni!Ni!Ni!'
Notice that operator overloading is at work here already: we're using the same operators that were called addition and multiplication when we looked at numbers. Python is smart enough to do the correct operation, because it knows the types of objects being added and multiplied. But be careful; Python doesn't allow you to mix numbers and strings in + and * expressions: 'abc' + 9 raises an error, instead of automatically converting 9 to a string. As shown in the last line in Table 2.4, you can also iterate over strings in loops using for statements and test membership with the in expression operator:
>>> myjob = "hacker" >>> for c in myjob: print c, # step though items ... h a c k e r >>> "k" in myjob # 1 means true 1
But since you need to know something about statements and the meaning of truth in Python to really understand for and in, let's defer details on these examples until later.
Because strings are defined as an ordered collection of characters, we can access their components by position. In Python, characters in a string are fetched by indexingproviding the numeric offset of the desired component in square brackets after the string. As in C, Python offsets start at zero and end at one less than the length of the string. Unlike C, Python also lets you fetch items from sequences such as strings using negative offsets. Technically, negative offsets are added to the length of a string to derive a positive offset. But you can also think of negative offsets as counting backwards from the end (or right, if you prefer).
>>> S = 'spam'
>>> S[0], S[-2] # indexing from front or end
('s', 'a')
>>> S[1:3], S[1:], S[:-1] # slicing: extract section
('pa', 'pam', 'spa')
In the first line, we define a four-character string and assign it the name S. We then index it two ways: S[0] fetches the item at offset from the left (the one-character string 's'), and S[-2] gets the item at offset 2 from the end (or equivalently, at offset (4 + -2) from the front). Offsets and slices map to cells as shown in Figure 2.1.
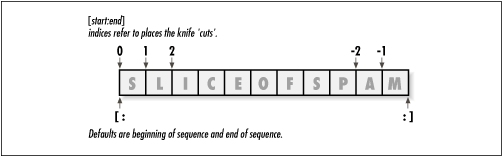
The last line in the example above is our first look at slicing. When we index a sequence object such as a string on a pair of offsets, Python returns a new object containing the contiguous section identified by the offsets pair. The left offset is taken to be the lower bound, and the right is the upper bound; Python fetches all items from the lower bound, up to but not including the upper bound, and returns a new object containing the fetched items.
For instance, S[1:3] extracts items at offsets 1 and 2, S[1:] gets all items past the first (the upper bound defaults to the length of the string), and S[:-1] gets all but the last item (the lower bound defaults to zero). This may sound confusing on first glance, but indexing and slicing are simple and powerful to use, once you get the knack. Here's a summary of the details for reference; remember, if you're unsure about what a slice means, try it out interactively.
Fetches components at offsets (the first item is at offset zero)
Negative indexes mean to count from the end (added to the positive length)
S[0] fetches the first item
S[-2] fetches the second from the end (it's the same as S[len(S) - 2])
Extracts contiguous sections of a sequence
Slice boundaries default to zero and the sequence length, if omitted
S[1:3] fetches from offsets 1 up to, but not including, 3
S[1:] fetches from offsets 1 through the end (length)
S[:-1] fetches from offsets up to, but not including, the last item
Later in this chapter, we'll see that the syntax used to index by offset (the square brackets) is also used to index dictionaries by key; the operations look the same, but have different interpretations.
Remember those big wordsimmutable sequence? The immutable part means that you can't change a string in-place (e.g., by assigning to an index). So how do we modify text information in Python? To change a string, we just need to build and assign a new one using tools such as concatenation and slicing:
>>> S = 'spam' >>> S[0] = "x" Raises an error!
>>> S = S + 'Spam!' # to change a string, make a new one >>> S 'spamSpam!' >>> S = S[:4] + 'Burger' + S[-1] >>> S 'spamBurger!' >>> 'That is %d %s bird!' % (1, 'dead') # like C sprintf That is 1 dead bird!
Python also overloads the % operator to work on strings (it means remainder-of-division for numbers). When applied to strings, it serves the same role as C's sprintf function: it provides a simple way to format strings. To make it go, simply provide a format string on the left (with embedded conversion targetse.g., %d), along with an object (or objects) on the right that you want Python to insert into the string on the left, at the conversion targets. For instance, in the last line above, the integer 1 is plugged into the string where the %d appears, and the string 'dead' is inserted at the %s. String formatting is important enough to warrant a few more examples:
>>> exclamation = "Ni" >>> "The knights who say %s!" % exclamation 'The knights who say Ni!' >>> "%d %s %d you" % (1, 'spam', 4) '1 spam 4 you' >>> "%s -- %s -- %s" % (42, 3.14159, [1, 2, 3]) '42 -- 3.14159 -- [1, 2, 3]'
In the first example, plug the string "Ni" into the target on the left, replacing the %s marker. In the second, insert three values into the target string; when there is more than one value being inserted, you need to group the values on the right in parentheses (which really means they are put in a tuple, as we'll see shortly).
Python's string % operator always returns a new string as its result, which you can print or not. It also supports all the usual C printf format codes. Table 2.5 lists the more common string-format target codes. One special case worth noting is that %s converts any object to its string representation, so it's often the only conversion code you need to remember. For example, the last line in the previous example converts integer, floating point, and list objects to strings using %s (lists are up next). Formatting also allows for a dictionary of values on the right, but since we haven't told you what dictionaries are yet, we'll finesse this extension here.
|
% |
String (or any object's print format) |
%X |
Hex integer (uppercase) |
|
%c |
Character |
%e |
Floating-point format 1[6] |
|
%d |
Decimal (int) |
%E |
Floating-point format 2 |
|
%i |
Integer |
%f |
Floating-point format 3 |
|
%u |
Unsigned (int) |
%g |
Floating-point format 4 |
|
%o |
Octal integer |
%G |
Floating-point format 5 |
|
%x |
Hex integer |
%% |
Literal % |
[6] The floating-point codes produce alternative representations for floating-point numbers. See printf documentation for details; better yet, try these formats out in the Python interactive interpreter to see how the alternative floating-point formats look (e.g., "%e %f %g" % (1.1, 2.2, 3.3)).
As previously mentioned, Python provides utility modules for processing strings. The string module is perhaps the most common and useful. It includes tools for converting case, searching strings for substrings, converting strings to numbers, and much more (the Python library reference manual has an exhaustive list of string tools).
>>> import string # standard utilities module
>>> S = "spammify"
>>> string.upper(S) # convert to uppercase
'SPAMMIFY'
>>> string.find(S, "mm") # return index of substring
3
>>> string.atoi("42"), `42` # convert from/to string
(42, '42')
>>> string.join(string.split(S, "mm"), "XX")
'spaXXify'
The last example is more complex, and we'll defer a better description until later in the book. But the short story is that the split function chops up a string into a list of substrings around a passed-in delimiter or whitespace; join puts them back together, with a passed-in delimiter or space between each. This may seem like a roundabout way to replace "mm" with "XX", but it's one way to perform arbitrary global substring replacements. We study these, and more advanced text processing tools, later in the book.
Incidentally, notice the second-to-last line in the previous example: the atoi function converts a string to a number, and backquotes around any object convert that object to its string representation (here, `42` converts a number to a string). Remember that you can't mix strings and numbers types around operators such as +, but you can manually convert before that operation if needed:
>>> "spam" + 42 Raises an error
>>> "spam" + `42`
'spam42'
>>> string.atoi("42") + 1
43
Later, we'll also meet a built-in function called eval that converts a string to any kind of object; string.atoi and its relatives convert only to numbers, but this restriction means they are usually faster.
Finally, we'd like to show you a few of the different ways to write string constants; all produce the same kind of object (a string), so the special syntax here is just for our convenience. Earlier, we mentioned that strings can be enclosed in single or double quotes, which allows embedded quotes of the opposite flavor. Here's an example:
>>> mixed = "Guido's" # single in double >>> mixed "Guido's" >>> mixed = 'Guido"s' # double in single >>> mixed 'Guido"s' >>> mixed = 'Guido\'s' # backslash escape >>> mixed "Guido's"
Notice the last two lines: you can also escape a quote (to tell Python it's not really the end of the string) by preceding it with a backslash. In fact, you can escape all kinds of special characters inside strings, as listed in Table 2.6; Python replaces the escape code characters with the special character they represent. In general, the rules for escape codes in Python strings are just like those in C strings.[7] Also like C, Python concatenates adjacent string constants for us:
[7] But note that you normally don't need to terminate Python strings with a \0 null character as you would in C. Since Python keeps track of a string's length internally, there's usually no need to manage terminators in your programs. In fact, Python strings can contain the null byte \0, unlike typical usage in C. For instance, we'll see in a moment that file data is represented as strings in Python programs; binary data read from or written to files can contain nulls because strings can too.
>>> split = "This" "is" "concatenated" >>> split 'Thisisconcatenated'
And last but not least, here's Python's triple-quoted string constant form in action: Python collects all the lines in such a quoted block and concatenates them in a single multiline string, putting an end-of-line character between each line. The end-of-line prints as a "\012" here (remember, this is an octal integer); you can also call it "\n" as in C. For instance, a line of text with an embedded tab and a line-feed at the end might be written in a program as python\tstuff\n (see Table 2.6).
>>> big = """This is ... a multi-line block ... of text; Python puts ... an end-of-line marker ... after each line.""" >>> >>> big 'This is\012a multi-line block\012of text; Python puts\012an end-of-line marker\012after each line.'
Python also has a special string constant form called raw strings, which don't treat backslashes as potential escape codes (see Table 2.6). For instance, strings r'a\b\c' and R"a\b\c" retain their backslashes as real (literal) backslash characters. Since raw strings are mostly used for writing regular expressions, we'll defer further details until we explore regular expressions in Chapter 8.
\newline |
Ignored (a continuation) |
\n |
Newline (linefeed) |
\\ |
Backslash (keeps one \) |
\v |
Vertical tab |
\' |
Single quote (keeps ') |
\t |
Horizontal tab |
\" |
Double quote (keeps ") |
\r |
Carriage return |
\a |
Bell |
\f |
Formfeed |
\b |
Backspace |
\0XX |
Octal value XX |
\e |
Escape (usually) |
\xXX |
Hex value XX |
\000 |
Null (doesn't end string) |
\other |
Any other char (retained) |
Now that we've seen our first composite data type, let's pause a minute to define a few general type concepts that apply to most of our types from here on. One of the nice things about Python is that a few general ideas usually apply to lots of situations. In regard to built-in types, it turns out that operations work the same for all types in a category, so we only need to define most ideas once. We've only seen numbers and strings so far, but they are representative of two of the three major type categories in Python, so you already know more about other types than you think.
When we introduced strings, we mentioned that they are immutable sequences: they can't be changed in place (the immutable part), and are ordered collections accessed by offsets (the sequence bit). Now, it so happens that all the sequences seen in this chapter respond to the same sequence operations we previously saw at work on stringsconcatenation, indexing, iteration, and so on. In fact, there are three type (and operation) categories in Python:
Numbers support addition, multiplication, etc.
Sequences support indexing, slicing, concatenation, etc.
Mappings support indexing by key, etc.
We haven't seen mappings yet (we'll get to dictionaries in a few pages), but other types are going to be mostly more of the same. For example, for any sequence objects X and Y:
X + Y makes a new sequence object with the contents of both operands.
X * N makes a new sequence object with N copies of the sequence operand X.
In other words, these operations work the same on any kind of sequence. The only difference is that you get back a new result object that is the same type as the operands X and Y (if you concatenate strings, you get back a new string, not a list). Indexing, slicing, and other sequence operations work the same on all sequences too; the type of the objects being processed tells Python which flavor to perform.
The immutable classification might sound abstract, but it's an important constraint to know and tends to trip up new users. If we say an object type is immutable, you shouldn't change it without making a copy; Python raises an error if you do. In general, immutable types give us some degree of integrity, by guaranteeing that an object won't be changed by another part of a program. We'll see why this matters when we study shared object references later in this chapter.
| I l@ve RuBoard |