| [ Team LiB ] |
|
2.3 The Basic RDF Data Model and the RDF GraphThe RDF Core Working Group decided on the RDF grapha directed labeled graphas the default method for describing RDF data models for two reasons. First, as you'll see in the examples, the graphs are extremely easy to read. There is no confusion about what is a subject and what are the subject's property and this property's value. Additionally, there can be no confusion about the statements being made, even within a complex RDF data model. The second reason the Working Group settled on RDF graphs as the default description technique is that there are RDF data models that can be represented in RDF graphs, but not in RDF/XML.
The RDF directed graph consists of a set of nodes connected by arcs, forming a pattern of node-arc-node. Additionally, the nodes come in three varieties: uriref, blank nodes, and literals. A uriref node consists of a Uniform Resource Identifier (URI) reference that provides a specific identifier unique to the node. There's been discussion that a uriref must point to something that's accessible on the Web (i.e., provide a location of something that when accessed on the Internet returns something). However, there is no formal requirement that urirefs have a direct connectivity with actual web resources. In fact, if RDF is to become a generic means of recording data, it can't restrict urirefs to being "real" data sources. Blank nodes are nodes that don't have a URI. When identifying a resource is meaningful, or the resource is identified within the specific graph, a URI is given for that resource. However, when identification of the resource doesn't exist within the specific graph at the time the graph was recorded, or it isn't meaningful, the resource is diagrammed as a blank node. Within a directed graph, resource nodes identified as urirefs are drawn with an ellipse around them, and the URI is shown within the circle; blank nodes are shown as an empty circle. Specific implementations of the graph, such as those generated by the RDF Validator, draw a circle containing a generated identifier, used to distinguish blank nodes from each other within the single instance of the graph. The literals consist of three partsa character string and an optional language tag and data type. Literal values represent RDF objects only, never subjects or predicates. RDF literals are drawn with rectangles around them. The arcs are directional and labeled with the RDF predicates. They are drawn starting from the resource and terminating at the object, with arrows documenting the direction from resource to object (in all instances of RDF graphs I've seen, this is from right to left). Figure 2-1 shows a directed graph of the example statement discussed in the previous section. In the figure, the subject is contained within the oval to the left, the object literal is within the box, and the predicate is used to label the arrowed line drawn from the subject to the object. Figure 2-1. RDF directed graph of giant squid article statementAs you can see in the figure, the direction of the arrow is from the subject to the object. In addition, the predicate is given a uriref equal to the schema for the RDF vocabulary elements and the element that serves as predicate itself. Every arc, without exception, must be labeled within the graph. Blank nodes are valid RDF, but most RDF parsers and building tools generate a unique identifier for each blank node. For example, Figure 2-2 shows an RDF graph generated by the W3C RDF Validator, complete with generated identifier in place of the blank node, in the format of: genid(unique identifier) The identifier shown in the figure is genid:158, the number being the next number available for labeling a blank node and having no significance by itself. The use of genid isn't required, but the recommended format for blank node identifiers is some form similar to that used by the validator. Figure 2-2. Example of autogenerated identifier representing blank node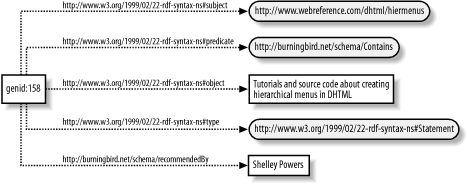 Blank nodes (sometimes referred to as bnodes or, previously, anonymous nodes) can be problematic within automated processes because the identifier that's generated for each will change from one application run to the next. Because of this, you can't depend on the identifier remaining the same. However, since blank nodes represent placeholder nodes rather than more meaningful nodes, this shouldn't be a problem. Still, you'll want to be aware of the nonpersistent names given to blank nodes by RDF parsers.
The components of the RDF graphthe uriref, bnode, literal, and arcare the only components used to document a specific instance of an RDF data model. This small number of components isn't surprising when you consider that, as demonstrated earlier, an RDF triple is a fact comprised of subject-predicate-object. Only when we start recording more complicated assertions and start merging several triples together do the RDF graph and the resulting RDF/XML begin to appear more complex. |
| [ Team LiB ] |
|
