| [ Team LiB ] |
|
5.1 RDF Vocabulary: Describing the DataThe last few chapters have emphasized that the RDF specification is about metadatadata about data. This is a key RDF concept; by creating a domain-neutral specification to describe resources, the same specification can then be used with many different domains but still be processed by the same RDF agents or parsed by the same RDF parsers. Because of the importance of understanding metadata's role within RDF, we'll start by taking a closer look at the concept of metadata, particularly as it's used in applications today. 5.1.1 Metadata's Role in Existing ApplicationsIf you've worked with any kind of relational database such as Oracle, Sybase, MySQL, or Microsoft's SQL Server, you've used metadata. The way that these database management systems can be used for many different applications, and to store many different types of data, is by using metadata structures. For instance, an application database might have three database tables such as CUSTOMER, ORDER, and CUSTOMER_ORDER, with both the CUSTOMER and ORDER tables related to the third CUSTOMER_ORDER table through primary/foreign key relationships, as diagrammed in Figure 5-1. Figure 5-1. Three related database tables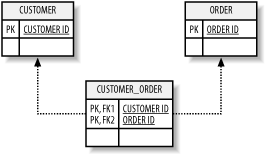 The ORDER table could have other fields associated with it such as ORDER_DATE and TOTAL_COST, each containing values describing the order date and cost, respectively. Additional information could be stored about the fields, such as the ORDER_DATE is a timestamp and a required value, while the total cost field is a currency value that can be null. To create storage specifically designed to store CUSTOMER, ORDER, and CUSTOMER_ORDER might be effective for one application but won't be useful for another application that needs to store information about objects such as STUDENT and CLASS (for an academic setting). In other words, change the domain and the domain-specific storage constructs become pretty useless. To facilitate multiple uses of the same storage mechanism for different domains, the relational database schema defines elements such as database tables, primary and foreign keys, and columns that provide a domain-neutral description of the information about the different aspects of the CUSTOMER, ORDER, and CUSTOMER_ORDER objects. In SQL Server, the information would be stored in constructs such as TABLES, COLUMNS, and KEY_COLUMN_USAGE. COLUMNS contain a row for each element within the domain being described. Therefore, TABLES would contain one row for each of the application data objects CUSTOMER, CUSTOMER_ORDER, and ORDER; the COLUMNS table would contain one row for each table column; and so on. More complex information such as column constraints and foreign key relationships are also stored, individually, as rows within some metadata table.
At runtime, the database management system hides the higher-level nature of the data storage by allowing applications to access objects such as CUSTOMER, CUSTOMER_ORDER, and ORDER, directly, as if they were actual objects rather than mappings between domain elements and a generic relational database schema. This process works so well that there are few companies in the world that don't have at least one relational database, and many have several. The concept of runtime metadata can be extended to applications other than just relational databases. Large multiuse applications such as PeopleSoft, SAP, and Oracle Financials also make use of the concept of real-time metadata. Even without viewing each of these application's actual data stores, one can assume that the applications allow extensions to their systems by the expedient of recording metadata as records rather than as columns within a table. With this, the applications can create a generic application that follows a well-defined business modelsuch as a Customer Resource Management (CRM) systemthat can then be extended and used within many different types of businesses. RDF acts in a manner similar to a relational database system or these large, multiple-purpose application frameworks. Within RDF, instead of creating a custom XML vocabulary to describe resources, you use a predefined syntax and schema that allow you to store information about the resource domain, but in such a way that automated RDF processes can access and process the data regardless of the domain. Based on this domain-neutral approach, you don't store information about a web resource in a domain-specific XML element called WEB_PAGE; instead, you store it in an rdf:Description element and use RDF to define the properties for this new resource. This same syntax can then be used to describe online books, photos, or even an article on giant squids (as demonstrated in Chapter 2). Most importantly, the same automated processes can manipulate the information regardless of either the resource or the domain. Within relational database systems, the metadata process works because the schema used to capture the business information follows specific rules and makes use of a common set of system objects, such as tables and columns. The same applies to RDF: for all this to work, the RDF Schema also has to be described, and that's where the concept of metadata about metadata enters the picture. It is at this point that the RDF Schema enters the RDF specification universe. 5.1.2 RDF Schema: Metadata RepositoryIn the last section, you had a chance to see that relational databases can provide storage for a multitude of domains through the use of a set of objects that store information about every aspect of the domain, but in a neutral manner. These objects form what is known as the database system's system objects or metadata schema objects. Within SQL Server, the objects can be queried through a custom view called the INFORMATION_SCHEMA, which contains references to elements such as the aforementioned TABLES and COLUMNS, though the actual internal tables are hidden to allow the SQL Server architects to make changes if necessary without impacting the exposed view. The basic elements underlying the INFORMATION_SCHEMA view, such as TABLES and COLUMNS, aren't specific to any one relational database vendor; they're based on the relational database schema, defined within an industry standard. All of these elements are then governed by well-understood (and mathematically proven) rules and procedures. Because of this, you can use different relational database systems and be assured that for certain basic objects and functionality, the exposed behavior is the same regardless of the type of system. Within an Oracle database, you can have at most one primary key for a table; this same rule applies to a table within Microsoft's SQL Server and a table within Sybase. In other words, the relational database schema, its objects, rules, and regulations are the metadata used to define and describe the metadata (TABLES, COLUMNS) that are then used to describe and manage domain-specific data (CUSTOMER, ORDER, CUSTOMER_ORDER).
The RDF Schema provides the same functionality as the relational database schema. It provides the resources necessary to describe the objects and properties of a domain-specific schemaa vocabulary used to describe objects and their attributes and relationships within a specific area of interest. The best way to fully understand how the RDF Schema works is by looking at the elements that make up the schema. |
| [ Team LiB ] |
|
