| [ Team LiB ] |
|
6.3 Defining the Vocabulary: ElementsHow to start defining the vocabulary for this type of system? Compatible with most application efforts, the first step to creating the vocabulary is to define the business domain elements and their properties of interest within the given business scope. 6.3.1 The PostCon Domain ElementsDefining the business elements for a new system is the same process whether the domain is being defined for use within a more traditional relational database or within a system with data defined and managed through RDF-capable processes. Following from existing data modeling techniques, you first describe the major entities and their properties, then describe how these entities are related to one another. PostCon has one major or root element, the web site resource; the system is interested in this resource from six different perspectives:
The set of PostCon objects consists of a web resource, its bio, a movement associated with the resource, presentation and type information, and other related resources. Each object is then described by a set of properties. Many of these are compatible with HTML meta tag elements such as Title and Content and should be synchronized with the values included within the HTML; others are unique to the system. The main system elements are then described by a set of properties, as defined in Table 6-1.
The Unique Resource ID (URI) is defined once for the content and follows it regardless of the content's current location. The Resource Title property is equivalent to the HTML Title element, and the Resource Description is equivalent to the Description meta tag, which contains a short abstract of the resource's contents: <meta name="description" content="Dynamic Earth site focuses on science and the world and universe around us. You can never know too much"> The material within the content attribute is used for the Resource Description content. The Content Author is equivalent to the Author meta tag, and the Content Owner is equivalent to the Copyright meta tag: <meta name="author" content="Shelley Powers"> <meta name="copyright" content="© 1997-2003 Burningbird"> The Content Status for the web resource contains information about the current status of the document, such as whether it has been deleted or is still active. The Relevancy Expiration is a date when the content author expects the resource contents to become dated and no longer viable. The Requires property also provides information about the viability of the content, such as being dependent on Version 1.0 of a specific product release. The History of the resource tracks its movement throughout the network, as well as the date and reason for the move. This is particularly useful when providing information about deleted content. The Related material provides information about replacement URLs for content that is no longer viable, and the Recommendation material covers additional recommended material complementary to the material, while the Presentation reflects information necessary to "consume" the resource, as it were. For a specific web resource, there is one Resource bio, Relevancy, History, and Presentation sections, but many related items. Additionally, within the History section there can be many movements. This and the domain information are then used to prototype the RDF vocabulary, as described next. 6.3.2 Prototyping the VocabularyBefore creating a formal RDFS document for the new vocabulary, you should prototype the model with several different instances of it, to ensure that the results corroborate the expected outcome. During this process, check the validity of your data with the RDF Validator, which validates the result against the standard and also provides an edged graph and N-Triples breakdown of the RDF.
As a test case for the PostCon vocabulary, information about the giant squid articles introduced in Chapter 2 through Chapter 4 is recorded using the domain elements from the last section. The articles are particularly useful as test cases because they have been moved about, are related to each other, reference, and are referenced by external resources. About the only thing that the articles don't demonstrate is when a web resource has been deleted, and we'll test this out with another document later. When creating a new vocabulary, the first thing to do is define the URI for the vocabulary namespace. By convention, this should be the URL of the RDFS document when it is eventually made. In the case of PostCon, I used the following URL for the namespace: http://burningbird.net/postcon/elements/1.0/ This is actually fairly descriptivethis is the location of the set of PostCon Version 1.0 vocabulary elements. When the RDFS document for the vocabulary is finished, it will be dropped into this location primarily for use by utilities that make use of it for RDF/XML exploration (covered in Chapter 7).
Next up is determining what the URI of the web resource is. We could actually create an identifier for our resources, but my preference for the PostCon system is just to use it as the identifier the URL of the resource when it was first defined within the PostCon RDF/XML vocabulary. What's important is that it be consistent and uniqueany other requirements are purely system dependent, not RDF/XML dependent. I used the first document in the article series as the test case, and since it was located within the domain burningbird.net and within the articles subdirectory, its URI became: http://burningbird.net/articles/monsters1.htm However, to simplify the model, xml:base (explained in Chapter 3) is used and set to a value of http://burningbird.net/articles, and the resource URI is set to monsters1.htm. The other top-level predicates are added sans their predicates to give a relatively flat model at this point. Example 6-1 shows the RDF/XML at this stage. Example 6-1. First cut of PostCon vocabulary, with scalar values<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"
xml:base="http://burningbird.net/articles/">
<rdf:Description rdf:about="monsters1.htm">
<pstcn:bio />
<pstcn:relevancy />
<pstcn:presentation />
<pstcn:history />
<pstcn:related />
</rdf:Description>
</rdf:RDF>
Next, we'll start adding the other predicates to the model, but first, there's one change we want to make to the model. As it is currently defined, we have the resource, but we don't necessarily know what it is. It is a web resource, but by the model's definition it could be any other resource that can be defined by an arbitrary URI, including a person, a place, or a thing. To refine the model, then, we'll add an rdf:type predicate to it, with a value of http://burningbird.net/postcon/elements/1.0/Resource. However, to make the model as simple as possible, we'll use an RDF/XML shortcut (detailed in Section 3.5) and replace the rdf:Description block with a reference to this new class: <pstcn:Resource>
<pstcn:bio />
<pstcn:relevancy />
<pstcn:presentation />
<pstcn:history />
<pstcn:related />
</pstcn:Resource>
The directed graph that results from this change, as shown in Figure 6-1, is no different than if we had used the more formal rdf:Description block with the associated rdf:type predicate. Figure 6-1. The graph of our PostCon example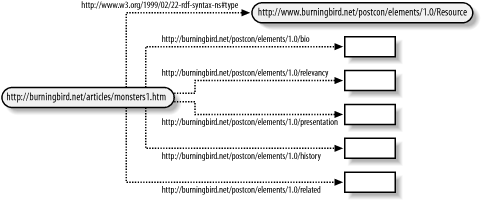 Next we'll start adding the predicates, beginning with pstcn:bio. Since RDF/XML requires a striped syntax of node-arc-node-arc, and rdf:bio is acting as an arc, rdf:bio's contents must be redefined as a blank nodea resource without a URI. Adding an rdf:Description block to rdf:bio and then adding its predicates as shown in Example 6-2 accomplishes redefining rdf:bio as a blank node. The predicates are named the same as the attributes defined in Table 6-1, but converted to QNames per the RDF/XML requirement. Changes to the RDF/XML are boldfaced. Example 6-2. Adding in the pstcn:bio predicates<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"
xml:base="http://burningbird.net/articles/">
<pstcn:Resource rdf:about="monsters1.htm">
<pstcn:bio>
<rdf:Description>
<pstcn:title>Tale of Two Monsters: Legends</pstcn:title>
<pstcn:abstract>
When I think of "monsters" I think of the creatures of
legends and tales, from the books and movies, and
I think of the creatures that have entertained me for years.
</pstcn:abstract>
<pstcn:description>
Part 1 of four-part series on cryptozoology, legends,
Nessie the Loch Ness Monster and the giant squid.
</pstcn:description>
<pstcn:dateCreated>1999-08-01T00:00:00-06:00</pstcn:dateCreated>
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:owner>Burningbird Network</pstcn:owner>
</rdf:Description>
</pstcn:bio>
<pstcn:relevancy />
<pstcn:presentation />
<pstcn:history />
<pstcn:related />
</pstcn:Resource>
</rdf:RDF>
The rdf:bio resource isn't given a URI because one doesn't exist for it. The resulting graph shows a computer-generated blank node identifier assigned to the resource. Again, in the interests of simplifying the model as much as possible, another RDF/XML shortcut is applied to the model. In this case, the attribute rdf:parseType is added to the pstcn:bio element, and its value is set to "Resource". Doing this, we can eliminate the rdf:Description block: <pstcn:bio rdf:parseType="Resource">
<pstcn:title>Tale of Two Monsters: Legends</pstcn:title>
<pstcn:abstract>
When I think of "monsters" I think of the creatures of
legends and tales, from the books and movies, and
I think of the creatures that have entertained me for years.
</pstcn:abstract>
<pstcn:description>
Part 1 of four-part series on cryptozoology, legends,
Nessie the Loch Ness Monster and the giant squid.
</pstcn:description>
<pstcn:dateCreated>1999-08-01T00:00:00-06:00</pstcn:dateCreated>
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:owner>Burningbird Network</pstcn:owner>
</pstcn:bio>
Though simplified with this syntactic change, the resulting directed graph of the model at this point, as shown in Figure 6-2, is equivalent to the longer, more formal syntax. Figure 6-2. RDF directed graph of model defined in Example 6-2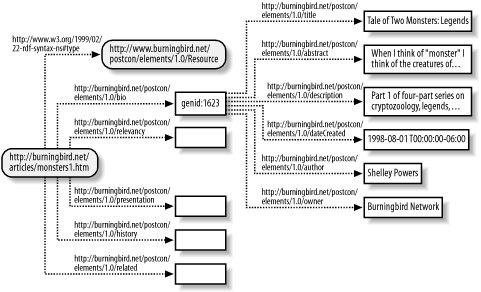 In Figure 6-2, I show the bio properties grouped via a blank node. Coming from a relational database background, my first inclination is to group related properties into a resource and link this back to the primary resource, rather than "flatten" the model and include each property as a direct attribute of the original resource. I follow this approach with RDF, primarily because, in my opinion, it leads to cleaner RDF processingwhether that processing occurs manually or through automation. If I had listed each of the "grouped" properties directly with the resource, there's no breakdown for relevancy or for the resource's bio. If a specific process was interested only in the biographical elements, each bio-related attribute would then have to be defined as biographically related to highlight it from the other properties. Now, if the bio-related properties were defined within one specific RDF "entity" (resource), it's a simple matter to process only bio properties just by processing all elements within the designated bio resource. Whether you're generating RDF through an API, consuming it with an RDF parser, or visually looking at an RDF document, grouping the properties through derived resources makes sense. The other groupings of attributes, such as relevancy and presentation, are completed in the same manner as bio and I won't cover all that here. However, the Related predicate is handled differently and is therefore covered in the next section.
6.3.3 Adding Repeating ValuesNot all recorded values occur as single properties within the PostCon vocabularya web resource can move many times, and there can be more than one recommended resource to replace an outdated item. The vocabulary must be able to handle repeating properties. Within the RDF specification, you can use the same predicate in multiple statements, such as the following: <pstcn:related rdf:resource="monsters2.htm" /> <pstcn:related rdf:resource="monsters3.htm" /> <pstcn:related rdf:resource="monsters4.htm" /> The distinguishing aspect of these statements then becomes the object, the predicate value. Attached to the primary resource, this syntax states that there are three related resources for the entity being defined. It also states that there's no order to the resources, and the only point of connectivity between the resources is that they're related, in some way, to the original entity. There is neither an implicit nor an explicit grouping between the items. At this point, the RDF/XML just shows the three related resources, and the resulting directed graph would show these items with ovals drawn around the objects as well as the resource. However, if I wanted to include additional information about the relationship between the related resources and the resource being defined in the document, I could do so in a couple of ways. First, I can define the related resource using the rdf:parseType="Resource" setting as I did with pstcn:bio. The problem with this is that each of the related resources actually does have a URI, and using rdf:parseType, I'd lose this information. Instead, what I'll use is the rdf:resource attribute. This allows me to specify the URI for the resource. Since these resources are related but separate from the main resource, I tend to want my model to reflect this, so I'll define the related resources as separate resources, related only through the URI. Example 6-3 shows the RDF/XML for the PostCon instance with the three related resources, each of them defined using the pstcn:Resource class, and each including the related resource attributes of title and reason. Example 6-3. Adding in related PostCon resources<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"
xml:base="http://burningbird.net/articles/">
<pstcn:Resource rdf:about="monsters1.htm">
<pstcn:bio rdf:parseType="Resource">
<pstcn:title>Tale of Two Monsters: Legends</pstcn:title>
<pstcn:abstract>
When I think of "monsters" I think of the creatures of
legends and tales, from the books and movies, and
I think of the creatures that have entertained me for years.
</pstcn:abstract>
<pstcn:description>
Part 1 of four-part series on cryptozoology, legends,
Nessie the Loch Ness Monster and the giant squid.
</pstcn:description>
<pstcn:dateCreated>1999-08-01T00:00:00-06:00</pstcn:dateCreated>
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:owner>Burningbird Network</pstcn:owner>
</pstcn:bio>
<pstcn:related rdf:resource="monsters2.htm" />
<pstcn:related rdf:resource="monsters3.htm" />
<pstcn:related rdf:resource="monsters4.htm" />
</pstcn:Resource>
<pstcn:Resource rdf:about="monsters2.htm">
<pstcn:title>Cryptozooloy</pstcn:title>
<pstcn:reason>First in the Tale of Two Monsters series.</pstcn:reason>
</pstcn:Resource>
<pstcn:Resource rdf:about="monsters3.htm">
<pstcn:title>A Tale of Two Monsters: Architeuthis Dux </pstcn:title>
<pstcn:reason>Second in the Tale of Two Monsters series.</pstcn:reason>
</pstcn:Resource>
<pstcn:Resource rdf:about="monsters4.htm">
<pstcn:title>Nessie, the Loch Ness Monster </pstcn:title>
<pstcn:reason>Fourth in the Tale of Two Monsters series.</pstcn:reason>
</pstcn:Resource>
</rdf:RDF>
Since the predicates associated with each related resource are simple and nonrepeating, I'm going to apply another shortcut to simplify the modelsimple nonrepeating predicates can be listed as attributes on the resource: <pstcn:Resource rdf:about="monsters2.htm"
pstcn:title="Cryptozooloy"
pstcn:reason="First in the Tale of Two Monsters series." />
<pstcn:Resource rdf:about="monsters3.htm"
pstcn:title="A Tale of Two Monsters: Architeuthis Dux"
pstcn:reason="Second in the Tale of Two Monsters series." />
<pstcn:Resource rdf:about="monsters4.htm"
pstcn:title="Nessie, the Loch Ness Monster"
pstcn:reason="Fourth in the Tale of Two Monsters series." />
The resulting RDF/XML and directed graph are the same. The only difference this change makes is to make the XML simpler and a little easier to read. It's also more comfortable for people familiar with XML, though, as stated earlier, it does tend to obscure the RDF constructs. Another reason to use this shortcut is that, if I preferred not to list the resources separately, I could list them as is with the predicates redefined as attributes, directly back into main resource. You couldn't do this using the rdf:resource attribute because you couldn't add formalized predicates to the block without generating errors. You would have to use the more formal node-arc-node by defining the predicate (pstcn:related), which would contain the rdf:Description block, which would then contain the related predicates: <pstcn:related>
<rdf:Description rdf:about="monsters3.htm"
pstcn:title="A Tale of Two Monsters: Architeuthis Dux"
pstcn:reason="Second in the Tale of Two Monsters series." />
</pstcn:related>
However, you can add predicates to the related resources that have been defined through the use of pstcn:Resource, by using the predicates as attributes shortcut, as demonstrated in Example 6-4. Example 6-4. Embedding related resources directly in main resource<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"
xml:base="http://burningbird.net/articles/">
<pstcn:Resource rdf:about="monsters1.htm">
<pstcn:bio rdf:parseType="Resource">
<pstcn:title>Tale of Two Monsters: Legends</pstcn:title>
<pstcn:abstract>
When I think of "monsters" I think of the creatures of
legends and tales, from the books and movies, and
I think of the creatures that have entertained me for years.
</pstcn:abstract>
<pstcn:description>
Part 1 of four-part series on cryptozoology, legends,
Nessie the Loch Ness Monster and the giant squid.
</pstcn:description>
<pstcn:dateCreated>1999-08-01T00:00:00-06:00</pstcn:dateCreated>
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:owner>Burningbird Network</pstcn:owner>
</pstcn:bio>
<pstcn:Resource rdf:resource="monsters2.htm"
pstcn:title="Cryptozooloy"
pstcn:reason="First in the Tale of Two Monsters series." />
<pstcn:Resource rdf:resource="monsters3.htm"
pstcn:title="A Tale of Two Monsters: Architeuthis Dux"
pstcn:reason="Second in the Tale of Two Monsters series." />
<pstcn:Resource rdf:resource="monsters4.htm"
pstcn:title="Nessie, the Loch Ness Monster"
pstcn:reason="Fourth in the Tale of Two Monsters series." />
</pstcn:Resource>
</rdf:RDF>
In some ways, this demonstrates that you either commit to using formal syntax all the way, or you commit to using abbreviated (shortcut) syntax all the wayat least for one complete RDF construct, such as the related items. Since my reasons for wanting to list the related resources separately remain, even though the RDF/XML and resulting directed graph are identical, I'll continue to use the approach demonstrated in Example 6-3. If I want to show that predicates are related to one another in some way beyond just being related to the defined entity, I'll use a container to group the items and then attach that container to the entity. The next section describes how. 6.3.4 Adding a ContainerThe PostCon vocabulary considers movements of the web resource related to one another. The first movement occurs when the resource is added to the web site; the second and each additional movement are related to one another by the date and time of the movement. Infinite numbers of movements are possible. To group like items that are related to one another as well as to the main resource, I could use either an RDF Container or a Collection. Both provide the grouping-of-related-items semantics that I need, but the relationship and number of items within the grouping differ based on which construct I use. And that's how I'll determine which to use. As described in Chapter 4, a Container is a group of related items that has no nth pointin other words, it could possibly contain an infinite number of items. A Collection, on the other hand, always has an endpoint, the implicit rdf:nil. Use of Collection creates the assumption that the grouping is of a finite number of objects. Additional tool-based semantics are associated with containers and collectionssuch as sequence with rdf:Seq and so onbut these aren't enforced within the RDF data model/graph, so I won't depend on them to make my decision about what to use. Instead, I'll rely on the one factor that is semantically defined in the RDF graph: whether the number of items in the group is infinite. Since I determined that a web resource can have infinite movements, I will choose an RDF Container. I now face additional choices, such as which container type to use. There is no enforcement of the Container differences within RDF, but there is a general assumption about behavior attached to each, so I'll want to pick the RDF Container type (Seq, Bag, or Alt) that fits my vocabulary model. Since each movement is unique, the Bag type isn't a good fit because an implicit assumption associated with it is that items can be duplicated. Nor is the Alt type a good fit, because it implicitly represents items that are alternatives to each other. The best fit is Seq, which has implicit associated semantics of related items in a sequence, from first to last. This fits history particularly well. Each movement has its own URI representing the movement itself, so each one can be identified distinctly. Because of this, my preference is, again, to list these out separately, related to the main resource through the container. Example 6-5 shows the PostCon vocabulary after adding in the Seq container. Note that I created a new class for the movement, pstcn:Movement. I couldn't use pstcn:Resource, because the movements really aren't resources. I could have also left the resources defined in generic rdf:Description blocks, but I prefer to embed as much information into the model as possible, and defining the new classMovementprovides a type to go with each movement definition, independent of the relationship defined by history earlier in the main resource. Example 6-5. PostCon vocabulary instance showing Movement and related resources<?xml version="1.0"?>
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:pstcn="http://burningbird.net/postcon/elements/1.0/"
xml:base="http://burningbird.net/articles/">
<pstcn:Resource rdf:about="monsters1.htm">
<!--biography of resource-->
<pstcn:bio rdf:parseType="Resource">
<pstcn:title>Tale of Two Monsters: Legends</pstcn:title>
<pstcn:abstract>
When I think of "monsters" I think of the creatures of
legends and tales, from the books and movies, and
I think of the creatures that have entertained me for years.
</pstcn:abstract>
<pstcn:description>
Part 1 of four-part series on cryptozoology, legends,
Nessie the Loch Ness Monster and the giant squid.
</pstcn:description>
<pstcn:dateCreated>1999-08-01T00:00:00-06:00</pstcn:dateCreated>
<pstcn:author>Shelley Powers</pstcn:author>
<pstcn:owner>Burningbird Network</pstcn:owner>
</pstcn:bio>
<!--related resources-->
<pstcn:related rdf:resource="monsters2.htm" />
<pstcn:related rdf:resource="monsters3.htm" />
<pstcn:related rdf:resource="monsters4.htm" />
<!--resource movements-->
<pstcn:history>
<rdf:Seq>
<rdf:_1 rdf:resource="http://www.yasd.com/dynaearth/monsters1.htm" />
<rdf:_2 rdf:resource="http://www.dynamicearth.com/articles/monsters1.htm" />
<rdf:_3 rdf:resource="http://burningbird.net/articles/monsters1.htm" />
</rdf:Seq>
</pstcn:history>
</pstcn:Resource>
<!--related resource defintions-->
<pstcn:Resource rdf:about="monsters2.htm">
<pstcn:title>Cryptozooloy</pstcn:title>
<pstcn:reason>First in the Tale of Two Monsters series.</pstcn:reason>
</pstcn:Resource>
<pstcn:Resource rdf:about="monsters3.htm">
<pstcn:title>A Tale of Two Monsters: Architeuthis Dux (Giant Squid)</pstcn:title>
<pstcn:reason>Second in the Tale of Two Monsters series.</pstcn:reason>
</pstcn:Resource>
<pstcn:Resource rdf:about="monsters4.htm">
<pstcn:title>Nessie, the Loch Ness Monster </pstcn:title>
<pstcn:reason>Fourth in the Tale of Two Monsters series.</pstcn:reason>
</pstcn:Resource>
<!--resource movement definitions-->
<pstcn:Movement rdf:about="http://www.yasd.com/dynaearth/monsters1.htm">
<pstcn:movementType>Add</pstcn:movementType>
<pstcn:reason>New Article</pstcn:reason>
<pstcn:date>1998-01-01T00:00:00-05:00</pstcn:date>
</pstcn:Movement>
<pstcn:Movement rdf:about="http://www.dynamicearth.com/articles/monsters1.htm">
<pstcn:movementType>Move</pstcn:movementType>
<pstcn:reason>moved to dynamicearth.com domain</pstcn:reason>
<pstcn:date>1999-10-31:T00:00:00-05:00</pstcn:date>
</pstcn:Movement>
<pstcn:Movement rdf:about="http://burningbird.net/articles/monsters1.htm">
<pstcn:movementType>Move</pstcn:movementType>
<pstcn:reason>Moved to burningbird.net</pstcn:reason>
<pstcn:date>2002-11-01:T00:00:00-05:00</pstcn:date>
</pstcn:Movement>
</rdf:RDF>
There is also something intriguing in this RDF/XML examplethe actual resource is defined both as the document Resource and as a Movement (in fact, the last movement for the history since the resource was defined in the PostCon system before any additional movements were made). This is perfectly legitimate and results in an interesting directed graph of a resource that has an arc pointing back to itself, as demonstrated in Figure 6-3. Figure 6-3. A resource containing a predicate whose value is the same URI as the original resource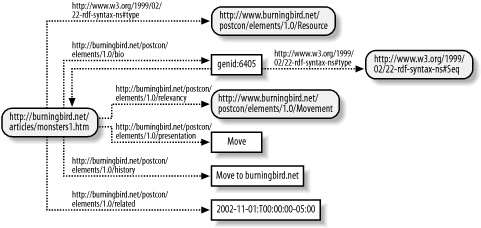 Also notice in the figure that the original resource now has two type properties associated with it: one for Resource and one for Movement. Again, this is perfectly legitimate RDF. In fact, the more knowledge we can put into the model, and the simpler the syntax, the better. 6.3.5 Adding in a ValueThe example RDF/XML demonstrated to this point has focused on bio, history, and related resources. The other PostCon classesRelevancy and Presentationare treated the same as bio, except for one new construct: the Presentation's Required property. Unlike other properties defined in the document up to this point, Requires is neither a straight resource property nor is it a literalit's a value that has an associated type that determines how the value is treated. The ideal RDF/XML construct to use to represent this is rdf:value. Without replicating all of the Relevancy properties, the following RDF/XML demonstrates how rdf:value would work for pstcn:requires. The pstcn:requires property is defined with an rdf:parseType of "Resource", and has two attributes: pstcn:type, which specifies the type of required resource, and rdf:value, which signals the actual value. Two resources are required: <pstcn:presentation rdf:parseType="Resource">
<pstcn:requires rdf:parseType="Resource">
<pstcn:type>stylesheet</pstcn:type>
<rdf:value>http://burningbird.net/de.css</rdf:value>
</pstcn:requires>
<pstcn:requires rdf:parseType="Resource">
<pstcn:type>logo</pstcn:type>
<rdf:value>http://burningbird.net/mm/dynamicearth.jpg</rdf:value>
</pstcn:requires>
</pstcn:presentation>
The intended semantics for rdf:value are that it always references the actual value of the predicateanything else is just definitive information about how that predicate is treated. The rest of the vocabulary uses the same constructs as have been used to this point and is omitted for brevity. A complete example of the vocabulary is given later, after a few modifications are made to merge the vocabulary with the Dublin Core. In the meantime, though, testing the vocabulary demonstrated to this point with other web site test cases shows that it tests out with all the business domain data. At this point, we can be comfortable that the vocabulary matches the system needs. The next step is to formalize the vocabulary schema using RDF Schema. |
| [ Team LiB ] |
|
