Regular Expression Concepts
As we
mentioned earlier, regular expressions are patterns of literals and
metacharacters that match target combinations of characters embedded
within input data:
- Literal character
-
A plain honest-to-goodness character, which mostly means no harm to
anyone and which goes about under the motto, "What
you see is what you get". So when you see the letter
n by itself, without a mischievous backslash
nearby, it means "please match the letter
n at this position, and nothing
else".
- Metacharacter
-
A nonalphabetic keyboard character, such as ^,
*, $, and so on, which
either has a special meaning or can give special meaning to
surrounding characters. For instance, the \
metacharacter backslash gives a special meaning to the letter
n, making it into the newline character,
\n.
Matching, Substitution, and Translation
There
are three main types of regular expression. All three work only on
scalars, usually strings:
- m// is for match
-
At the basic level,
m// simply tells you whether the required
regular expression is matched, or exists, within the input data.
Because matching is so ubiquitous within Perl, just the simple use of
// will indicate to Perl that
you're performing a match. If you change the
delimiters, however, you do need to explicitly use the
m prefix, as in m%my
match%. (We'll say more about delimiters
shortly.)
- s/// is for substitute
-
If you want to replace the located
matches with something else, you call up the substitution operator.
You always need to use the s prefix.
- tr/// is for translate
-
Although St. Peter at the Perly
gates would fail to recognize tr/// as a
definitive regular expression operator,
it's so close in form and function that we can
usually get away with fudging the issue. The translate operator takes
a range of characters on its left side, and replaces them with
another range of specified characters on its right side. Its typical
use is to capitalize a passage of text, or shift some number ranges.
To keep old sed users happy,
tr/// also possesses a synonym, the
y/// operator, which behaves in an identical fashion. A
typical translation program to uppercase every line of an input file
would look like this:
while(<>){
tr/a-z/A-Z/;
print;
}
Regular expression input
A special
double character is used to indicate the scalar value the regex
should work on. This is the =~ pattern binding
operator. Although this looks a lot like an =
assignment operator, try to think of it being more like the word
"contains":
print "I have found a match" if $target_string =~ /corleone/;
This translates into English, as follows:
Print out the phrase, `I have found a
match' if the variable
$target_string contains the
matching word `corleone'.
As with awk, the good angel of
=~ has a naughty devil partner-in-crime for
negative assertions, !~:
print "I have failed to find a match" if $target_string !~ /michael/;
This translates to:
Print out the phrase `I have failed to find a
match' if $target_string
fails to contain the word
`michael'.
 |
You can use any nonalphanumeric or non-space
character as a delimiter within Perl regexes. This is particularly
useful when you're matching strings that contain
/ Unix slash characters, which you need to
otherwise escape with a \ backslash character. A
typically required match pattern string might be
"/etc/passwd". When
using the standard match syntax, this would become
/\/etc\/passwd/, a process known as
toothpicking. You can avoid this unsightly use
by changing the delimiter character directly following from the now
compulsory match function character, m, thus
m#/etc/passwd#. No more fangs!
You can also use four sets of brackets,
m<...>, m{...},
m(...), and m[...]. The
first two are usually preferred because their bracket characters are
less frequently used within regexes. You can also mix and match
brackets for substitutions, s{...}<...>,
though you may still prefer s(...)(...) or even
s#...#...#. As a rule of thumb, use delimiters
that aren't going to appear in your regex to keep
everything clean. For example s<><>
is a good one if you're not dealing with
XML or HTML.
|
|
The implicit use of $_
As with many other places in Perl, if
no scalar variable is supplied to our regular expression via the
=~ or !~ constructs,
it's assumed that the scalar value under
consideration is the $_ default value. The good
angel of =~ is also assumed:
$_ = "Who is greater, Von Mises or Hayek?";
print if /greater/;
The print statement here could be fully expanded
to:
print $_ if $_ =~ m/greater/;
Either of the two preceding print statements would translate to:
Print the full contents of the $_ variable, if
$_ contains a match for the
word `greater'.
The Implicit Left-to-Right Assumption
Some rules are so implicit in Perl
(and in regular expressions in general) that it's
hard to spot them as assumptions as opposed to incontrovertible facts
of life. The important one to watch out for is that regular
expressions work in a left-to-right fashion.
This may seem obvious to native English speakers, but if
you're a fluent writer of
right-to-left Arabic or Hebrew script, or
you're trying to match
right-to-left Unicode data, the importance of
this assumption becomes more significant. If there are two or more
matches on a single line, it is the left-most one that is matched
first. Without the special /g global suffix,
which we'll talk about later, it is only this first
match that is either then validated, recorded, or substituted. (As
with all computer languages that ultimately originate from the
English language, Perl goes left-to-right, following the
left-to-right convention of Latin, which followed the left-to-right
tradition of fourth century BC classical Greek.)
Let's run our first regular expression to take a
look at this concept. Try to keep an open mind on the following
syntactical details, just for the moment; we promise to get to the
meaty details of regular bracketing, curly bracketing, list context,
and so on, a bit later. All we need to know for now is that
we're looking for a seven-character phrase, in the
supplied text, starting with the word
"Bag," and we're
going to store this in the
$seven_letter_Bag_phrase variable. As
we'll also cover later, the
.{4} notation picks up any four characters,
except \n newlines:
#!/usr/bin/perl
use strict;
my $party_text =
"When Mr. Bilbo Baggins of Bag End announced that " .
"he would shortly be celebrating his eleventy-first " .
"birthday with a party of special magnificence, there " .
"was much talk and excitement in Hobbiton.";
my ($seven_letter_Bag_phrase) = ($party_text =~ m/(Bag.{4})/);
So what got stored inside the
$seven_letter_Bag_phrase variable?:
print "Seven Letter Bag Phrase: >", $seven_letter_Bag_phrase, "<\n";
This provides an output of:
Seven Letter Bag Phrase: >Baggins<
This may be a surprise. Our clever plan was to get you to guess
"Bag End," as this may seem at
first glance the slightly more obvious match within the supplied
$party_text variable. However using our
left-to-right rule, the first match found was in fact
"Baggins." As soon as
we'd matched this, it was game over. To get the
actual word "Bag," followed by a
space and then a three-letter word, we'd have to
tune our regular expression accordingly. For instance, we could
re-tune our original code like this, to make sure there is an
\s for space character after the word
"Bag":
my ($seven_letter_Bag_phrase) = ($party_text =~ m/(Bag\s.{3})/);
print "Seven Letter Bag Phrase: >", $seven_letter_Bag_phrase, "<\n";
This produces:
Seven Letter Bag Phrase: >Bag End<
(We'll also explain more about
\s later.)
Planning regular expressions is like planning killer attack moves in
chess. It's easy to go forward with all bishops
blazing, but we've got to leave ourselves covered at
the back. Let's summarize the rules we followed
here:
In the first case, we were after "Bag
End," so we played a quick
Bag.{4} move to go and grab it.
We then got punished for our hastiness, because this matched the more
left "Baggins," too.
By replaying the move with Bag\s.{3}, we got the
desired result.
Our regex opponent had to concede to us the "Bag
End" phrase we were after originally. Fantastic!
Regular expressions can also be likened to the perfect jury. They
must always get the guilty party (or match), and must always release
the innocent bystander (or fail to match an unwanted pattern). Of
course in the real world, perfect juries are uncommon, and we
therefore tend to err on the side of letting the odd guilty person go
(or miss the odd match), in order to make sure innocent bystanders
(or false matches) are never wrongly convicted. Getting regular
expressions to match exact requirements can be equally troublesome.
It is only through fine-tuning and the constant honing of regex
common law that we're able to achieve ultimate grand
regex mastery.
Regular Expression Architectures
There
are two major regular expression engine types.
- The DFA (Deterministic Finite Automaton)
-
With a name taking us back to Kleene's 1951 paper on
neural nerve nets, the DFA engine powers many regex tools, including
most versions of Alfred Aho's
egrep, and awk, as well as
lex and flex. Basically,
while the DFA filters the input text, it simultaneously holds every
single possible combination of text the regex could be searching for.
Think of a police cell filling with the usual suspects, until the
guilty party is recognized or the match found. The DFA engine
therefore provides fast, consistent matches.
- The NFA (Nondeterministic Finite Automaton)
-
The alternative backtracker NFA engine drives Perl,
sed, vi, and most versions
of grep. It is controlled much more by the
actual regex. It works by bumping and grinding through the input text
one character at a time. If it goes up a blind alley, it backtracks
to the last position that still makes sense (the saved state), and
then begins working through the regex again, bumping and grinding
once more through the text. It's a bit like a mad
genius film editor, checking out a film sequence one frame at a time,
and then cutting backwards and forwards until the Holy
Grail's final cut is discovered. The NFA approach is
illustrated in Figure C-2, where the Witch King of
Angmar has crafted a regex to try to find Baggins.
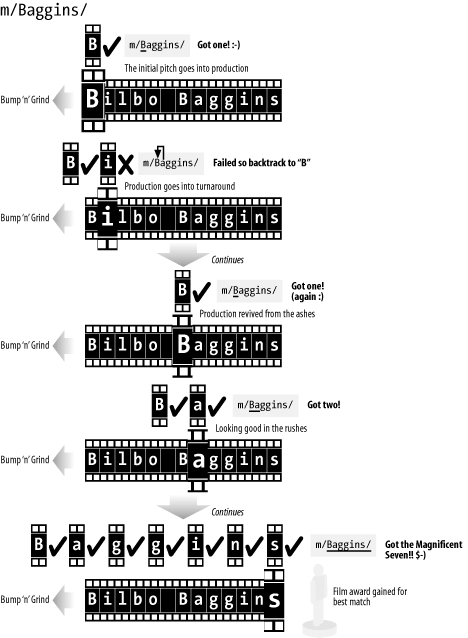
Although the NFA is logically slower than the DFA engine at finding
matches, it has two major advantages which often overcome this speed
gap:
Its backtracking architecture allows the NFA to save and store marked
snippets of information as it works through the text. Think of
Theseus trying to locate the Cretan Minotaur in the labyrinth at
Knossos. He could use Ariadne's ball of silken
thread to retrace his way out from blind alleys and dead ends, until
in the end he found and slaughtered the Minotaur (or got his match).
He could then get out of the maze, once again using the thread,
bringing with him his life and his sword. The DFA would approach the
situation differently. If there were 99 blind alleys, it would send
in 100 gladiators, only one of which would find and kill the Minotaur
(or get the match). Then all 100 gladiators would stay where they
were (99 stuck up blind alleys, 1 in the central chamber), all
incapable of going anywhere except forwards into the nearest wall.
The task would be achieved, and the Minotaur would be dead, but no
gladiators would be able to re-emerge into the light. This is
illustrated in Figure C-3.
The other disadvantage of the DFA engine is that its swordsmen slaves
would never benefit from a map. Their orders are always to just keep
piling into the Labyrinth, like the Roman soldiers in The
Life of Brian, until every possible cubby-hole, including
the central chamber, is covered. In other words whatever regex you
provide, as long as it's logically similar to
another regex looking for the same match, it makes no speed
difference to the match. The same 100 gladiators will always end up
in the same 100 locations, one of which will
happen to be the final match in the central
chamber. NFA regexes, on the other hand, are very different. If you
become skilled at regexes (or skilled at solving mazes), you can
begin directing the route of Theseus beforehand by drawing him a map
(or a better regex). And the better your map-drawing or predictive
skills become, the fewer blind alleys Theseus will hit, the less
backtracking he'll have to do, and the quicker
he'll find the Minotaur. Because you can craft your
regex in this way to speed up the game, the NFA appeals to code
crafters and Perl hackers everywhere.
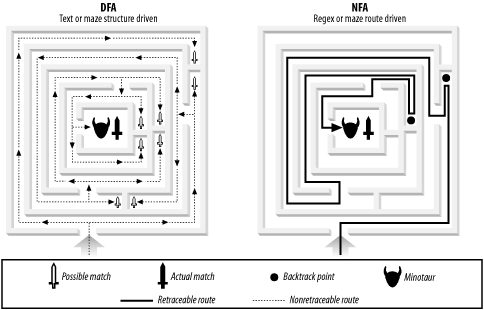
|
