
|
|
|
MetacharactersMost regular expressions rarely look for exact literal matches (such as m/Saruman/) but more often for fuzzy matches, as in our earlier Baggins code snippet. For example, suppose we have possession of a secret file called listOfPowers.txt. This was discovered within the bowels of Orthanc by Gandalf before he left for the Blessed Realm. It consists of the following names: Saruman Aragorn, son of Arathorn Frodo Baggins Mithrandir Sauron Bombadill Durin's Bane Smaug Elrond Galadriel Witch-King Celeborn Radagast Dain Ironfoot Denethor We'd like to find all the Powers known to have existed within Middle-Earth in the Third Age, whose names begin with an "S" and end with an "n." Example C-1 is the program we use. Using regex metacharacters findTheBaddies.pl#!perl
while(<>){
print if /S.*n/;
}
Notice the use of two special metacharacters, the . (dot) and the * (Kleene Star), within our main match expression. Before we explain how these are being used, let's see what we get: $ perl findTheBaddies.pl listOfPowers.txt Saruman Sauron The results seem appropriate, but notice how we failed to pick up Smaug or anything else that nearly matches. So how are these two metacharacters combining? Before we answer this question, let's examine all of Perl's main regex metacharacters in Table C-3.
Figure C-4. Variable numeric character requirements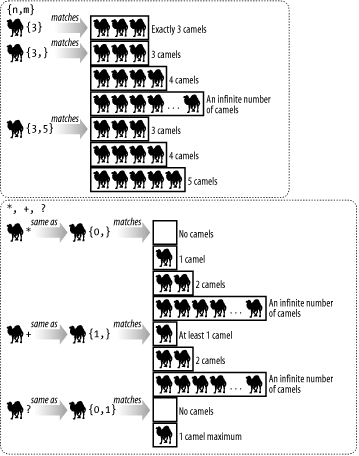 To answer our original question, we can now see how the /S.*n/ match worked its magic on the listOfPowers.txt file:
In the following sections, we'll examine how we can further refine such munge requirements to search for other fuzzy data, while keeping track of what falls within our fuzzy requirements and what falls outside them. Character Class ShortcutsIf you've ever used character class ranges with an older version of grep, you may have used a command like the following one to find words of at least one character in length: $ grep '[a-zA-Z0-9][a-zA-Z0-9]*' myFile.txt This seems reasonable enough, and the ranges are nice because they've cut out the typing in of many alphabetical characters. But this is still too much work for a Perlhead; a similar match in Perl would involve just three keystrokes: \w+ There are many other such regex shortcuts in Perl for other character class ranges. To illustrate these, including \w, we'll first detail some double-quotish characters which are recognized within Perl regexes, in Table C-4. Table C-5 will then display some of the best-known character class shortcuts. (Fortunately, many of these have now made their way into more modern versions of grep and egrep, too.)
BoundariesIn addition to the ^ (caret) and $ (dollar) string anchors, there are two other special boundary assertions commonly used in Perl regexes. These are described in Table C-6.
Beware of punctuation within words such as "Let's", as in Figure C-5. Remember that \w is both for alphanumerics and the underscore, but it never covers punctuation marks, such as apostrophes. Sometimes it's better to use matches, such as the following, to pick up words containing punctuation:
Figure C-5. Word boundaries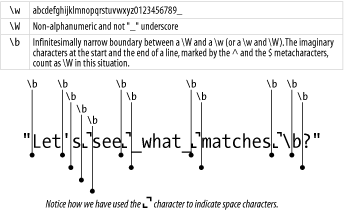 This means: "Some spaces, followed by some nonspaces, followed by some more spaces." The sequential non-space characters can be a word containing apostrophes. Notice how it may also be difficult, at first glance, to pick out the difference between the \s and the \S shortcuts. GreedinessIf the first great principle of Perl regexes is the left-most match wins, the second great principle is that by default any match will try to take as much text as it can. More specifically, the mass character quantifiers will always try to grab the maximal possible match. These quantifiers include:
Particularly when they're used in combination with the . (dot) character, they will always try to eat as much as they can, unless we tell them otherwise. For instance, let's take a typical line out of an /etc/passwd file line: andyd:fruitbat:/home/andyd:dba,apache,users:/bin/ksh You might expect the substitution s/.*:/jkstill:/ to produce the following: jkstill:fruitbat:/home/andyd:dba,apache,users:/bin/ksh You might have thought the .* would only take the andyd, and allow the colon character to match the first colon. But this doesn't happen. Instead, the .* will try and grab as much as it possibly can get away with. Remember that the . dot character can match anything, except \n newlines, and that includes colons. What the preceding substitution actually produces is: jkstill:/bin/ksh This may go against common sense, but it is the result of default greedy behavior. Perl regexes operate greedily via the NFA mechanism of backtracking and by saving success states. This is illustrated in Figure C-6, which we've broken down into seven steps:.
Figure C-6. Greedy matching, save states and backtracking When you're munging large quantities of data, be sure to take this greedy behavior into account when crafting your regular expressions. Now that we know how the NFA works on greediness, we can think about the regex pathways that will take up the least amount of work. However, sometimes we would rather avoid this maximally greedy behavior perhaps we want just the bare minimum. In the case under consideration, all we really wanted to do was to replace andyd: with jkstill:. So how do we do this? With the multiply useful ? (question mark character), summarized in Figure C-7. What we have in the top portion of Figure C-7 is a maximally greedy regex, which eats as much it can, while still ultimately producing the match. In the bottom half, the regex has been limited by the shackles of the extra question mark suffix. It is now a minimalist regex, and will match as little as it can to find a successful match. It may be less than happy about this, but what can it do? Figure C-7. The question mark and its effect on greediness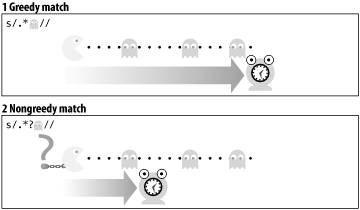 In our earlier example, if we use a substitution regex of s/.*?:/jkstill:/, we now get the result of: jkstill:fruitbat:/home/andyd:dba,apache,users:/bin/ksh Incidentally, the greediness-restraining ? (question mark) suffix is, in addition to the other main use of ?, a quantifier in its own right equivalent to {0,1}. All the multiple quantifiers are similarly restrained, as in Table C-7.
Interpolated StringsVariables found within Perl regexes behave similarly to interpolated strings within print statements. This is because of two levels of parsing:
For instance: $orginal_Gandalf = "Olorin";
$wizard_String = "Olorin or Mithrandir? ";
if ($wizard_String =~ m/$original_Gandalf/)
{
print "Wizard found! <|:-))))"
}
This interpolates the $original_Gandalf variable inside the match, which expands to Olorin and then processes the regex on the $wizard_String input data to see if it contains Olorin. The resultant output is: Wizard found! <|:-)))) However, although regexes can generally be treated in the same way double-quoted interpolated strings are treated, this varies slightly with the special use of metacharacters. For instance, Example C-2 will fail. almostInterpolated.pl Checking interpolation in regexes#!perl -w
use strict;
my $regex_pattern = "[*Casablanca";
my $input_film = "[*Casablanca";
if ($input_film =~ m/$regex_pattern/)
{
print "Is the Maltese Falcon just as good?\n";
}
If we run almostInterpolated.pl, we get a rude awakening: $ perl almostInterpolated.pl Unmatched [ before HERE mark in regex m/[ << HERE *Casablanca/ at almostInterpolated. pl line 10. This is because [ is a special regex metacharacter for character classes, as described in Table C-3, which needs a matching ] dancing partner. Because we're looking for the [ square bracket opener as an actual literal within the string, we need to backslash it to escape its special meaning. Fortunately, we can avoid pasting backslashes everywhere into our pattern. We can use the quotemeta( ) built-in function instead. What this does is return the input string value with all nonalphanumeric characters, including the underscore, backslashed for our convenience: my $regex_pattern = quotemeta('[*Casablanca');
my $input_film = "[*Casablanca";
if ($input_film =~ m/$regex_pattern/)
{
print "Is the Maltese Falcon just as good?\n";
}
Now we get: $ perl almostInterpolated.pl Is the Maltese Falcon just as good? Scalar or List Context ResultsA match in a scalar setting will generally produce either a 1 for true (if it finds a match) or an empty string "" for false (if it fails to find the required match): # Scalar context on the LHS, left hand side. $my_string = "Galadriel and Celeborn"; # Note below how the =~ symbol takes precedence over the = symbol. # What happens in the following, is that the $my_string =~ m/Galad/ # operation takes place, and then the $result = (match operation) # comes second. $result = $my_string =~ m/Galad/; print "Expecting 1: result: >", $result, "<\n"; $result = $my_string =~ /Legolas and Gimli/; print "Expecting Empty String: result: >", $result, "<\n"; Fingers crossed, we get the results we're after: Expecting 1: result: >1< Expecting Empty String: result: >< Excellent. This behavior of returning 1 or "" differs if Perl detects that a list array is required on the left-hand side of the equation (i.e., whether it is in scalar context or list context). In this case, if anything within a match is marked for storage with parentheses, these values are copied across into the list array elements on the left-hand side. If no valid match is found, these array elements are left empty: # Array context on the LHS $my_string = "Galadriel and Celeborn"; # Once again, the =~ operation takes precedence over the = operation, # and the wantarray( ) function detects that a list is required on the # left-hand side. ($queen, $king) = $my_string =~ m/(Galad\w+)\s+\w+\s+(\w+)/; # Valid results expected print "Value Expected, Queen: >", $queen, "<\n"; print "Value Expected, King: >", $king, "<\n"; ($queen, $king) = $my_string =~ m/(Legolas\w+)\s+\w+\s+(\w+)/; print "Empty String Expected, Queen: >", $queen, "<\n"; print "Empty String Expected, King: >", $king, "<\n"; When executed, this provides: Value Expected, Queen: >Galadriel< Value Expected, King: >Celeborn< Empty String Expected, Queen: >< Empty String Expected, King: >< This is a bit fiddly, but if you work through a few examples of your own, it should begin to make sense. Alternation and MemoryWe promised earlier, when we were discussing list contexts and the internal use of the wantarray( ) function, that we'd cover backreferences. So what's the mechanism behind backreference memory storage? Capturing backreferencesAs we explained earlier, backreferences are made possible by the architecture of the NFA engine, which always leaves a ball of string back into the labyrinth. Think of the bracketing as paired knots in the string, which tell the regular expression what to retrieve. We can see this in action in Figure C-8, where we're using backreferences to store the noted values in special built-in variables, rather than returning them as part of a list. Note also the use of the /i regex suffix in Figure C-8, which ignores the alphabetic case of the target string under scrutiny. Figure C-8. Capturing backreferences and ignoring case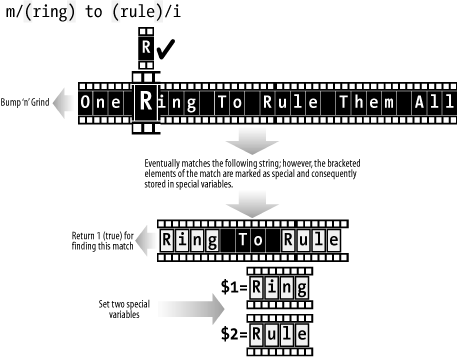 Note the following:
Let's run through Example C-3, with a range from $1 to $12. Capturing multi-bracketed values roundDozen.pl#!perl -w # Start with a large match, involving twelve captures $_ = "abcdefghijklmnopqrstuvwxyz"; # a b c d e f g h i j k l m n o p q r s t u v w x y z m/(.(.(.(.(.(.(.(.(.(.(.(.).).).).).).).).).).).)/; # 1 2 3 4 5 6 7 8 9 t e w w e t 9 8 7 6 5 4 3 2 1 backreferences # t = ten, e = eleven, w = twelve print '$1 :', $1, "\n"; print '$2 :', $2, "\n"; print '$3 :', $3, "\n"; print '$4 :', $4, "\n"; print '$5 :', $5, "\n"; print '$6 :', $6, "\n"; print '$7 :', $7, "\n"; print '$8 :', $8, "\n"; print '$9 :', $9, "\n"; print '$10 :', $10, "\n"; print '$11 :', $11, "\n"; print '$12 :', $12, "\n"; # Now let's go for a small match, which only fills # up $1, $2 and $3 $_ = "1234567890"; # 1 2 3 4 5 6 7 8 9 0 m/(.(.(.).).)/; # 1 2 3 3 2 1 backreferences print '$1 :', $1, "\n"; print '$2 :', $2, "\n"; print '$3 :', $3, "\n"; print '$4 :', $4, "\n"; print '$5 :', $5, "\n"; print '$6 :', $6, "\n"; print '$7 :', $7, "\n"; print '$8 :', $8, "\n"; print '$9 :', $9, "\n"; print '$10 :', $10, "\n"; print '$11 :', $11, "\n"; print '$12 :', $12, "\n"; Running this script produces the following results: $ perl roundDozen.pl $1 :abcdefghijklmnopqrstuvw $2 :bcdefghijklmnopqrstuv $3 :cdefghijklmnopqrstu $4 :defghijklmnopqrst $5 :efghijklmnopqrs $6 :fghijklmnopqr $7 :ghijklmnopq $8 :hijklmnop $9 :ijklmno $10 :jklmn $11 :klm $12 :l $1 :12345 $2 :234 $3 :3 Use of uninitialized value in print at roundDozen.pl line 32. $4 : Use of uninitialized value in print at roundDozen.pl line 33. $5 : Use of uninitialized value in print at roundDozen.pl line 34. $6 : Use of uninitialized value in print at roundDozen.pl line 35. $7 : Use of uninitialized value in print at roundDozen.pl line 36. $8 : Use of uninitialized value in print at roundDozen.pl line 37. $9 : Use of uninitialized value in print at roundDozen.pl line 38. $10 : Use of uninitialized value in print at roundDozen.pl line 39. $11 : Use of uninitialized value in print at roundDozen.pl line 40. $12 : Note the following:
You can also use backreferences within the actual matches. The rule is that if these are used on the left side of the substitution or within an ordinary match, you must use the \1 style notation (instead of $1). On the other hand, on the right-hand side of the substitution you can use the straight $1 notation. For instance, you might be trying to replace all double-word typos in a piece of text with equivalent single words: #!perl -w
# Our input string has two double-word typos,
# "work work", and "was was". We'd like to remove both of them.
$_ = "Ludwig von Mises greatest work work was Human Action, " .
"and F.A. Hayek's greatest work was was the Road to Serfdom.";
# On the left side of the substitution, to pick up
# the double-word, we have to use \1 in the match,
# and on the right side substitution we use $1 to replace
# both instances of the same word with a single string value.
s#\b(\w+)\b\s+\1\b#$1#g; # Substitute double-word typos
print;
Note the following:
Our solution code produces the following output text: Ludwig von Mises greatest work was Human Action, and F.A. Hayek's greatest work was the Road to Serfdom. |
|
|
|
