
|
|
|
Match SuffixesWe'll complete this appendix by looking at how we can alter the operation of regexes with the various suffixes listed in Table C-8, including /g used in the double-word substitution in the previous section.
/i Ignore CaseThe /i suffix simply makes the match ignore the alphabetic case on the match side of the equation. Consider the following example. We have the following file to process: http Http HTtp HTTp HTTP hTTP htTP httP We'll work this through following code snippet, which has yet to use the /i suffix: while(<>){
print if /http/; # No /i suffix
}
This processes the file to produce: http Now we'll change the code snippet to include the /i suffix: while(<>){
print if /http/i; # /i suffix in place
}
The code now totally ignores case, and prints the following list: http Http HTtp HTTp HTTP hTTP htTP httP /g Global MatchingWhen used with the match operator, the global suffix /g will gradually break down a string into parsed components, as shown in Example C-4. Global matching parseGlobal.pl#!perl -w
$_ = "/usr/local/apache/conf/httpd.conf";
while (m#/([\w.]+)#g){
print $1, "\n";
}
When executed, parseGlobal.pl breaks down the input string into its wordy components: $ perl parser.pl usr local apache conf httpd.conf Let's look at some examples of global replacements:
/s & /m Single- and Multiple-Line MatchingThe /s and /m suffixes are often used in combination, especially when many lines of data have been packed into a single scalar variable. Their combined use can best be seen in Figure C-9. Figure C-9. Single- and multiple-line suffixes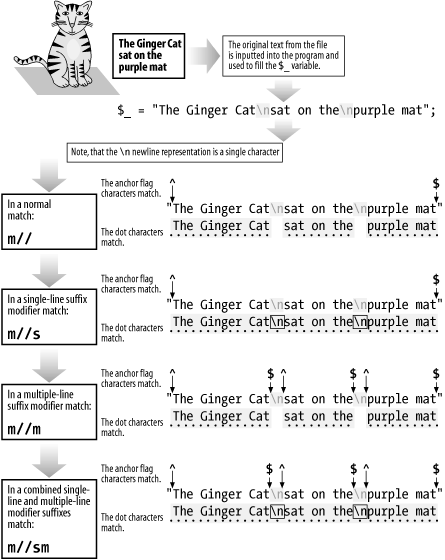 /o Compile Only OnceTo avoid recompiling regexes unnecessarily, you can use the /o suffix. A typical usage of /o is shown in the following example:
This leaves us with an interesting clothing choice! It's often tempting to spice up many Perl programs via a liberal use of the /o suffix, but beware. Many Perl programmers have spent many long hours tracking down impossible "I-must-be-going-mad" bugs, finally realizing that they should have removed the /o suffixes. No matter what value $today_match goes to in the previous example, the regular expression will continue to search for Sun until the cows come home in the twenty-third century. /e EvaluationsOften overlooked, /e is a rough diamond of a suffix and is especially useful for mathematical and scientific munge purposes. Basically it takes the right side of a substitution and evaluates it as a code expression, as if embedded in a do{...} code block. Let's run through a quick example:
You may think /e is pretty clever, but it gets better. You can wrap unending amounts of eval{...} commands around the original do{...} code block by adding an extra evaluation command to the suffix, /ee. This will take whatever the first expression evaluation gives you, and then evaluate it, so that the following two lines are equivalent: s/PATTERN/CODE/ee s/PATTERN/eval(CODE)/e Let's work through another example to cover it:
/x The Expressive ModifierYou may have noticed that some of the regexes we've talked about were starting to get rather long and trickier to follow until we broke them down across several lines. This is where /x steps out from behind the curtain. Some years ago, Jeffrey Friedl, author of Mastering Regular Expressions, was replying to a regex question on comp.lang.perl.misc when he pretty-printed a very large regular expression to make it easier to read. Larry Wall saw the post and liked it so much that he immediately added the /x suffix to Perl. This made it possible for everyone to create indented regexes containing embedded comments. Essentially, within /x regexes you can use any amount of whitespace, and the regex will ignore it. You can also put comments within the regex, prefixed by the usual Perl # hash comment character. If you do want to include spaces or # hashes within the actual regex, you merely backslash them, or use the \s escape for spaces. Let's work through a regex problem and see how we can help solve it more clearly with the assistance of /x: We have an Oracle PL/SQL program file, mars_rocket.sql, which has some C-style comments within it which we wish to remove. There is a reason for this, but it's classified: /*
|| Create this procedure to fire the positioning rockets when
|| we approach the Martian surface.
*/
CREATE OR REPLACE PROCEDURE mars_rocket (v_thrust_in IN NUMBER)
AS
v_momentum NUMBER; /* Adjustment factor */
v_twist NUMBER; /* Rotational factor */
BEGIN
/*
|| Loop and then fire.
*/
LOOP
EXIT WHEN v_thrust_in = 0;
v_twist := v_thrust_in + mars_env.gravi_bind; /* Newton :-) */
v_momentum := v_thrust_in + mars_env.mass_emc; /* Einstein :-) */
mars_env.fire_retros(v_twist, v_momentum); /* Fire in the hole */
END LOOP;
/* Fired and forgotten. */
END mars_rocket;
/
Example C-5 shows our program to remove these comments, making use of the /x suffix. Removing C-style comments with the /x suffix xErase.pl#!perl -w
# Open the target file, and the target.
open(MARS_IN, $ARGV[0]) or die "Could not read $ARGV[0]";
open(MARS_OUT, ">$ARGV[1]")
or die "Could not open $ARGV[1], to write to";
# Slurp the entire file
$/ = undef; # Houston, - Undefining the input record separator.
$_ = <MARS_IN>; # Entire file slurped into
# the single default $_ variable.
# The main substitution begins:
s{
# The search pattern brackets are {},
# and the replacement brackets are [].
# We're removing all C-style comments, so
# the replacement is completely empty.
/\* # We're looking for the C-style comment
# start marker. We have to escape the
# Kleene Star, to make it a normal asterisk.
.*? # We're then looking for any character,
# including the \n newline, though we're
# doing this minimally, to avoid stripping
# out everything between the first comment
# and the last.
\*/ # We then find the first C-style comment
# terminator. Once again, we've had to
# backslash the asterisk.
}
[]gsx;
# The gsx suffixes mean:
#
# g: We're replacing every match we find within the file.
# s: Because we've slurped the entire file into a single variable,
# including \n newlines, we need to treat the entire thing as a
# single line, so . dot will match \n newlines, and catch comments
# which spread over more than one line.
# x: The "expressive" syntax means we can break down a potentially
# confusing regex, over many lines, and use comments :-)
# Now print out the new file without C-style comments and close down.
print MARS_OUT $_;
close(MARS_IN);
close(MARS_OUT);
Because of the /x suffix within the program, we can now fully expand the match pattern with white space, and pepper it with plenty of comments. This will help our Marsonauts figure out what our regex is trying to do when they come to maintain the script halfway through on the trip out. Now we test run the program, to create the mars_bar.sql output file: $ perl xErase.pl mars_rocket.sql mars_bar.sql The mars.bar.sql output file has now had all of its C-style comments removed: CREATE OR REPLACE PROCEDURE mars_rocket (v_thrust_in IN NUMBER)
AS
v_momentum NUMBER;
v_twist NUMBER;
BEGIN
LOOP
EXIT WHEN v_thrust_in = 0;
v_twist := v_thrust_in + mars_env.gravi_bind;
v_momentum := v_thrust_in + mars_env.mass_emc;
mars_env.fire_retros(v_twist, v_momentum);
END LOOP;
END mars_rocket;
/
We can almost see Tom Hanks, getting excited about this in the follow-up movie. This appendix barely touches upon Perl's regular expression capabilities. There is much more to discover. (The Camel and Owl books are good places to start, as is the online perldoc perlre command.) Nobody ever stops learning about regexes. Just when you think you possess a complete knowledge, another little wrinkle turns up. This is especially true today with the growing use of Unicode. But hey, where would life be if every day were utterly predictable? As Mithrandir said to Sam, Merry, and Pippin at the Grey Havens, on the last day of Middle-Earth's Third Age:
|
|
|
|