
|
|
|
3.1 OS Hardening PrinciplesOperating-system hardening can be time consuming and even confusing. Like many OSes designed for a wide range of roles and user levels, Linux has historically tended to be "insecure by default": most distributions' default installations are designed to present the user with as many preconfigured and active applications as possible. Therefore, securing a Linux system not only requires you to understand the inner workings of your system; you may also have to undo work others have done in the interest of shielding you from those inner workings! Having said that, the principles of Linux hardening in specific and OS hardening in general can be summed up by a single maxim: "that which is not explicitly permitted is forbidden." As I mentioned in the previous chapter, this phrase was coined by Marcus Ranum in the context of building firewall rules and access-control lists. However, it scales very well to most other information security endeavors, including system hardening. Another concept originally forged in a somewhat different context is the Principle of Least Privilege. This was originally used by the National Institute of Standards and Technology (NIST) to describe the desired behavior of the "Role-Based Access Controls" it developed for mainframe systems: "a user [should] be given no more privilege than necessary to perform a job" (http://hissa.nist.gov/rbac/paper/node5.html). Nowadays people often extend the Principle of Least Privilege to include applications; i.e., no application or process should have more privileges in the local operating environment than it needs to function. The Principle of Least Privilege and Ranum's maxim sound like common sense (they are, in my opinion). As they apply to system hardening, the real work stems from these corollaries:
All of these corollaries are ways of implementing and enforcing the Principle of Least Privilege on a bastion host. We'll spend most of the rest of this chapter discussing each in depth with specific techniques and examples. We'll end the chapter by discussing Bastille Linux, a handy tool with which Red Hat and Mandrake Linux users can automate much of the hardening process. 3.1.1 Installing/Running Only Necessary SoftwareThis is the most obvious of our submaxims/corollaries. But what does "necessary" really mean? What if you don't know whether a given software package is necessary, especially if it was automatically installed when you set up the system? You have three allies in determining each package's appropriateness:
Common sense, for example, dictates that a firewall shouldn't be running apache and that a public FTP server doesn't need a C compiler. Remember, since our guiding principle is "that which is not expressly permitted must be denied," it follows that "that which is not necessary should be considered needlessly risky." If you don't know what a given command or package does, the simplest way to find out is via a man lookup. All manpages begin with a synopsis of the described command's function. I regularly use manpage lookups both to identify unfamiliar programs and to refresh my memory on things I don't use but have a vague recollection of being necessary. If there's no manpage for the command/package (or you don't know the name of any command associated with the package), try apropos <string> for a list of related manpages. If that fails, your package manager should, at the very least, be able to tell you what other packages, if any, depend on it. Even if this doesn't tell you what the package does, it may tell you whether it's necessary. For example, in reviewing the packages on my Red Hat system, suppose I see libglade installed but am not sure I need it. As it happens, there's no manpage for libglade, but I can ask rpm whether any other packages depend on it (Example 3-1). Example 3-1. Using man, apropos, and rpm to identify a package[mick@woofgang]$ man libglade No manual entry for libglade [mick@woofgang]$ apropos libglade libglade: nothing appropriate [mick@woofgang]$ rpm -q --whatrequires libglade memprof-0.3.0-8 rep-gtk-gnome-0.13-3 Aha...libglade is part of GNOME. If the system in question is a server, it probably doesn't need the X Window System at all, let alone a fancy frontend like GNOME, so I can safely uninstall libglade (along with the rest of GNOME). SuSE also has the rpm command, so Example 3-1 is equally applicable to it. Alternatively,
you can invoke yast, navigate to Package
Management Under Debian, dpkg has no simple means of tracing dependencies, but dselect handles them with aplomb. When you select a package for deletion (by marking it with a minus sign), dselect automatically lists the packages that depend on it, conveniently marking them for deletion too. To undo your original deletion flag, type "X"; to continue (accepting dselect's suggested additional package deletions), hit RETURN. 3.1.1.1 Commonly unnecessary packagesI highly recommend you not install the X Window System on publicly accessible servers. Server applications (Apache, ProFTPD, and Sendmail, to name a few) almost never require X; it's extremely doubtful that your bastion hosts really need X for their core functions. If a server is to run "headless" (without a monitor and thus administered remotely), then it certainly doesn't need a full X installation with GNOME, KDE, etc., and probably doesn't need even a minimal one. During Linux installation, deselecting X Window packages, especially the base packages, will return errors concerning "failed dependencies." You may be surprised at just how many applications make up a typical X installation. In all likelihood, you can safely deselect all of these applications, in addition to X itself. When in doubt, identify and install the package as described previously (and as much X as it needs skip the fancy window managers) only if you're positive you need it. If things don't work properly as a result of omitting a questionable package, you can always install the omitted packages later. Besides the X Window System and its associated window managers and applications, another entire category of applications inappropriate for Internet-connected systems is the software-development environment. To many Linux users, it feels strange to install Linux without also installing GCC, GNU Make, and at least enough other development tools with which to compile a kernel. But if you can build things on an Internet-connected server, so may a successful attacker. One of the first things any accomplished system cracker does upon compromising a system is to build a "rootkit," a set of standard Unix utilities such as ls, ps, netstat, and top, which appear to behave just like the system's native utilities. Rootkit utilities, however, are designed not to show directories, files, and connections related to the attacker's activities, making it much easier for said activities to go unnoticed. A working development environment on the target system makes it much easier for the attacker to build a rootkit that's optimized for your system. Of course, the attacker can still upload his own compiler or precompiled binaries of his rootkit tools. Hopefully, you're running Tripwire or some other system-integrity-checker, which will alert you to changes in important system files (see Chapter 11). Still, trusted internal systems, not exposed public systems, should be used for developing and building applications; the danger of making your bastion host "soft and chewy on the inside" (easy to abuse if compromised) is far greater than any convenience you'll gain from doing your builds on it. Similarly, there's one more type of application I recommend keeping off of your bastion hosts: network monitoring and scanning tools. This is should be obvious, but tcpdump, nmap, nessus, and other tools we commonly use to validate system/network security have tremendous potential for misuse. As with development tools, security-scanning tools are infinitely more useful to illegitimate users in this context than they are to you. If you want to scan the hosts in your DMZ network periodically (which is a useful way to "check your work"), invest a few hundred dollars in a used laptop system, which you can connect to and disconnect from the DMZ as needed. While any unneeded service should be either deleted or disabled, the following deserve particular attention:
Remember, one of our operating assumptions in the DMZ is that hosts therein are much more likely to be compromised than internal hosts. When installing software, you should maintain a strict policy of "that which isn't necessary may be used against me." Furthermore, consider not only whether you need a given application but also whether the host on which you're about to install it is truly the best place to run it (see "Division of Labor Between Servers," earlier in this chapter). 3.1.1.2 Disabling services without uninstalling themPerhaps there are certain software packages you want installed but don't need right away. Or perhaps other things you're running depend on a given package that has a nonessential daemon you wish to disable. If you run Red Hat or one of its derivatives (Mandrake, Yellow Dog, etc.), you should use chkconfig to manage startup services. chkconfig is a simple tool (Example 3-2). Example 3-2. chkconfig usage message[mick@woofgang mick]# chkconfig --help
chkconfig version 1.2.16 - Copyright (C) 1997-2000 Red Hat, Inc.
This may be freely redistributed under the terms of the GNU Public License.
usage: chkconfig --list [name]
chkconfig --add <name>
chkconfig --del <name>
chkconfig [--level <levels>] <name> <on|off|reset>)
To list all the startup services on my Red Hat system, I simply enter chkconfig --list. For each script in /etc/rc.d, chkconfig will list that script's startup status (on or off) at each runlevel. The output of Example 3-3 has been truncated for readability: Example 3-3. Listing all startup scripts' configuration[root@woofgang root]# chkconfig --list anacron 0:off 1:off 2:on 3:on 4:on 5:on 6:off httpd 0:off 1:off 2:off 3:off 4:off 5:off 6:off syslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off network 0:off 1:off 2:on 3:on 4:on 5:on 6:off linuxconf 0:off 1:off 2:on 3:off 4:off 5:off 6:off (etc.) To disable linuxconf in runlevel 2, I'd execute the commands shown in Example 3-4. Example 3-4. Disabling a service with chkconfig[root@woofgang root]# chkconfig --level 2 linuxconf off [root@woofgang root]# chkconfig --list linuxconf linuxconf 0:off 1:off 2:off 3:off 4:off 5:off 6:off (The second command, chkconfig --list linuxconf, is optional but useful in showing the results of the first.) On SuSE systems, edit the startup script itself (the one in /etc/init.d), and then run the command insserv (no flags or arguments necessary) to change automatically the symbolic links that determine the runlevels in which it's started. Each SuSE startup script begins with a header, comprised of comment lines, which dictate how init should treat it (Example 3-5). Example 3-5. A SuSE INIT INFO header# /etc/init.d/lpd # ### BEGIN INIT INFO # Provides: lpd # Required-Start: network route syslog named # Required-Stop: network route syslog # Default-Start: 2 3 5 # Default-Stop: # Description: print spooling service ### END INIT INFO For our purposes, the relevant settings are Default-Start, which lists the runlevels in which the script should be started, and Default-Stop, which lists the runlevels in which the script should be stopped. Actually, since any script started in runlevel 2, 3, or 5 is automatically stopped when that runlevel is exited, Default-Stop is often left empty. Any time you change a startup script's INIT INFO header on a SuSE system, you must then run the command insserv to tell SuSE to change the start/stop links accordingly (in /etc/init.d's "rc" subdirectories). insserv is run without arguments or flags. For more information about the SuSE's particular version of the System V init-script system, see SuSE's init.d(7) manpage. On all other Linux distributions, you can disable a service simply by deleting or renaming its links in the appropriate runlevel directories under /etc/rc.d/. For example, if you're configuring a web server that doesn't need to be its own DNS server, you probably want to disable BIND. The easiest way to do this without deleting anything is by renaming all links to /etc/init.d/ (Example 3-6). Example 3-6. Disabling a startup script by renaming its symbolic links[root@woofgang root]# mv /etc/rc.d/rc2.d/S30named /etc/rc.d/rc2.d/disabled_S30named [root@woofgang root]# mv /etc/rc.d/rc3.d/S30named /etc/rc.d/rc3.d/disabled_S30named [root@woofgang root]# mv /etc/rc.d/rc5.d/S30named /etc/rc.d/rc5.d/disabled_S30named (Note that your named startup script may have a different name and exist in different or additional subdirectories of /etc/rc.d.) 3.1.2 Keeping Software Up to DateIt isn't enough to weed out unnecessary software: all software that remains, including both the operating system itself and "user-space" applications, must be kept up to date. This is a more subtle problem than you might think, since many Linux distributions offer updates on both a package-by-package basis (e.g., the Red Hat Errata web site) and in the form of new distribution revisions (e.g., new CD-ROM sets). What, then, constitutes "up to date"? Does it mean you must immediately upgrade your entire system every time your distribution of choice releases a new set of CD-ROMs? Or is it okay simply to check the distribution's web page every six months or so? In my opinion, neither is a good approach. (Not that these are the only two choices; they represent extremes.) 3.1.2.1 Distribution (global) updates versus per-package updates
The good news is that
it's seldom necessary to upgrade a system completely
just because the distribution on which it's based
has undergone an incremental revision (e.g., 7.2
A "global" revision to an entire Linux distribution is not a security event in itself. Linux distributions are revised to add new software packages, reflect new functionality, and provide bug fixes. Security is hopefully enhanced too, but not necessarily. Thus, while there are various reasons to upgrade to a higher numbered revision of your Linux distribution (stability, new features, etc.), doing so won't magically make your system more secure. In general, it's good practice to stick with a given distribution version for as long as its vendor continues to provide package updates for it, and otherwise to upgrade to a newer (global) version only if it has really compelling new features. In any Linux distribution, an older but still supported version with all current patches applied is usually at least as secure as the newest version with patches and probably more secure than the new version without patches. In fact, don't assume that the CD-ROM set you just received in the mail directly from SuSE, for example, has no known bugs or security issues just because it's new. You should upgrade even a brand-new operating system (or at least check its distributor's web site for available updates) immediately after installing it. I do not advocate the practice of checking for vulnerabilities only periodically and not worrying about them in the interim: while better than never checking, this strategy is simply not proactive enough. Prospective attackers won't do you the courtesy of waiting after your quarterly upgrade session before striking. (If they do, then they know an awful lot about your system and will probably get in anyhow!) Therefore, I strongly recommend you get into the habit of applying security-related patches and upgrades in an ad-hoc manner i.e., apply each new patch as soon as it's announced.
3.1.2.2 Whither X-based updates?In subsequent sections of this chapter, I'll describe methods of updating packages in Red Hat, SuSE, and Debian systems. Each of these distributions supports both automated and manual means of updating packages, ranging from simple commands such as rpm -Uvh ./mynewrpm-2.0.3.rpm (which works in all rpm-based distributions: Red Hat, SuSE, etc.) to sophisticated graphical tools such as yast2 (SuSE only). Given that earlier in this chapter I recommended against installing the X Window System on your bastion hosts, it may seem contradictory for me to cover X-based update utilities. There are two good reasons to do so, however:
3.1.2.3 How to be notified of and obtain security updates: Red HatIf you run Red Hat 6.2 or later, the officially recommended method for obtaining and installing updates and bug/security fixes (errata in Red Hat's parlance) is to register with the Red Hat Network and then either schedule automatic updates on the Red Hat Network web site or perform them manually using the command up2date. While all official Red Hat packages may also be downloaded anonymously via FTP and HTTP, Red Hat Network registration is necessary to both schedule automatic notifications and downloads from Red Hat and use up2date. At first glance, the security of this arrangement is problematic: Red Hat encourages you to remotely store a list with Red Hat of the names and versions of all your system's packages and hardware. This list is transferred via HTTPS and can only be perused by you and the fine professionals at Red Hat. In my opinion, however, the truly security conscious should avoid providing essential system details to strangers. There is a way around this. If you can live without automatically scheduled updates and customized update lists from Red Hat, you can still use up2date to generate system-specific update lists locally (rather than have them pushed to you by Red Hat). You can then download and install the relevant updates automatically, having registered no more than your email address and system version/architecture with Red Hat Network. First, to register with the Red Hat Network, execute the command rhn_register . (If you aren't running X, then use the --nox flag, e.g., rhn_register --nox.) In rhn_register's Step 2 screen (Step 1 is simply a license click-though dialogue), you'll be prompted for a username, password, and email address: all three are required. You will then be prompted to provide as little or as much contact information as you care to disclose, but all of it is optional. In Step 3 (system profile: hardware), you should enter a profile name, but I recommend you uncheck the box next to "Include information about hardware and network." Similarly, in the screen after that, I recommend you uncheck the box next to "Include RPM packages installed on this system in my System Profile." By deselecting these two options, you will prevent your system's hardware, network, and software-package information from being sent to and stored at Red Hat. Now, when you click the "Next" button to send your profile, nothing but your Red Hat Network username/password and your email address will be registered. You can now use up2date without worrying quite so much about who possesses intimate details about your system. Note there's one more useful Red Hat Network feature you'll subsequently miss: automatic, customized security emails. Therefore, be sure to subscribe to the Redhat-Watch-list mailing list using the online form at https://listman.redhat.com. This way, you'll receive emails concerning all Red Hat bug and security notices (i.e., for all software packages in all supported versions of Red Hat), but since only official Red Hat notices may be posted to the list, you needn't worry about Red Hat swamping you with email. If you're worried anyhow, a "daily digest" format is available (in which all the day's postings are sent to you in a single message). Once you've registered with the Red Hat Network via rhn_register (regardless of whether you opt to send hardware/package info), you can run up2date. First, you need to configure up2date, but this task has its own command, up2date-config (Figure 3-1). By default, both up2date and up2date-config use X-Windows; but like rhn_register, both support the --nox flag if you prefer to run them from a text console. Figure 3-1. up2date-config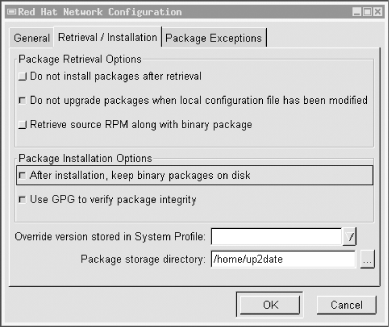 up2date-config is fairly self-explanatory, and you should need to run it only once (though you may run it at any time). A couple of settings, though, are worth noting. First is whether up2date should verify each package's cryptographic signature with gpg. I highly recommend you use this feature (it's selected by default), as it reduces the odds that up2date will install any package that has been corrupted or "trojaned" by a clever web site hacker. Also, if you're downloading updates to a central host from which you plan to "push" (upload) them to other systems, you'll definitely want to select the option "After installation, keep binary packages on disk" and define a "Package storage directory." You may or may not want to select "Do not install packages after retrieval." The equivalents of these settings in up2date's ncurses mode (up2date-config --nox) are keepAfterInstall, storageDir, and retrieveOnly, respectively.
Now you can run up2date. up2date will use information stored locally by rhn_register to authenticate your machine to the Red Hat Network, after which it will download a list of (the names/versions of) updates released since the last time you ran up2date. If you specified any packages to skip in up2date-config, up2date won't bother checking for updates to those packages. Figure 3-2 shows a screen from a file server of mine on which I run custom kernels and therefore don't care to download kernel-related rpms. Figure 3-2. Red Hat's up2date: skipping unwanted updates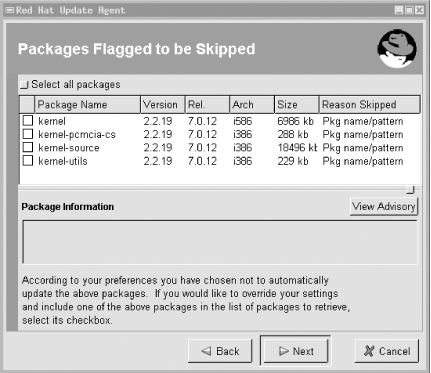 After installing Red Hat, registering with the Red Hat Network, configuring up2date and running it for the first time to make your system completely current, you can take a brief break from updating. That break should last, however, no longer than it takes to receive a new security advisory email from Redhat-Watch that's relevant to your system.
3.1.2.4 RPM updates for the extremely cautiousup2date's speed, convenience, and automated signature checking are appealing. On the other hand, there's something to be said for fully manual application of security updates. Updating a small number of packages really isn't much more trouble with plain old rpm than with up2date, and it has the additional benefit of not requiring Red Hat Network registration. Best of all from a security standpoint, what you see is what you get: you don't have to rely on up2date to relay faithfully any and all errors returned in the downloading, signaturechecking, and package-installation steps. Here, then, is a simple procedure for applying manual updates to systems running Red Hat, Mandrake, SuSE, and other rpm-based distributions:
Note that in both rpm usages, you may use wildcards or multiple filenames to act on more than one package, e.g.: rpm --checksig ./perl-* and then, assuming the signature checks were successful: rpm -Uhv ./perl-* 3.1.2.5 How to be notified of and obtain security updates: SuSEAs with so much else, automatic updates on SuSE systems can be handled through yast and yast2. Chances are if you run a version of SuSE prior to 8.0, you'll want both of these on your bastion host, since yast2 didn't fully replace yast until SuSE 8.0. Either can be used for software updates, so let's discuss both. To use yast to automatically update all packages
for which new RPM files are available, start
yast and select add/remove
programs This method takes a long time: depending on which mirror you download your patches from, such an update can last anywhere from one to several hours. In practice, therefore, I recommend using the "upgrade entire system" option immediately after installing SuSE. Afterwards, you'll want to download and install updates individually as they're released by using plain old rpm (e.g., rpm -Uvh ./mynewpackage.rpm). The best way to keep on top of new security updates is to subscribe to the official SuSE security-announcement mailing list, suse-security-announce. To subscribe, use the online form at http://www.suse.com/en/support/mailinglists/index.html. Whenever you receive notice that one of the packages on your system has a vulnerability addressed by a new patch, follow the instructions in the notice to download the new package, verify its GNUpg signature (as of SuSE Linux version 7.1, all SuSE RPMs are signed with the key [email protected]), and install it. This procedure is essentially the same as that described earlier in the section "RPM updates for the extremely cautious."
3.1.2.6 SuSE's online-update featureIn addition to yast and rpm, you can also use yast2 to update SuSE packages. This method is particularly useful for performing a batch update of your entire system after installing SuSE. yast2 uses X by default, but will automatically run in ncurses mode (i.e., with an ASCII interface structured identically to the X interface) if the environment variable DISPLAY isn't set. In yast2, start the "Software" applet, and select "Online Update." You have the choice of either an automatic update in which all new patches are identified, downloaded, and installed or a manual update in which you're given the choice of which new patches should be downloaded and installed (Figure 3-3). In either option, you can click the "Expert" button to specify an FTP server other than ftp.suse.com. Figure 3-3. Selecting patches in yast2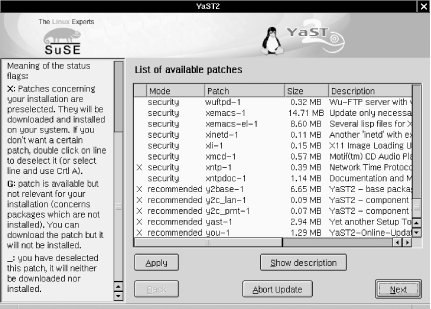 Overall, yast2's Online Update functionality is simple and fast. The only error I've encountered running it on my two SuSE servers was the result of invoking yast2 from an xterm as an unprivileged user: yast2 claimed that it couldn't find the update list on ftp.suse.com, which wasn't exactly true. The real problem was that yast2 couldn't write that file locally where it needed to because it was running with my non-root privileges. Invoking yast2 from a window-manager menu (in any window manager that susewm configures) obviates this problem: you will be prompted for the root password if you aren't running X as root. Running X as root, of course, is another workaround, but not one I recommend due to the overall insecurity of X-Windows. A better approach is to open a terminal window and issue these commands (output omitted): bash-$ su bash-# export DISPLAY="" bash-# yast2 Setting the environment variable DISPLAY to null in this way (make sure not to put any whitespace between the quotation marks) will force yast2 to run in your terminal window in ncurses mode; it won't matter which user started the underlying X session. 3.1.2.7 How to be notified of and obtain security updates: DebianAs is typical of Debian GNU/Linux, updating Debian packages is less flashy yet simpler than with most other distributions. The process consists mainly of two commands (actually, one command, apt-get, invoked twice but with different options): apt-get update apt-get -u upgrade The first command, apt-get update, updates your locally cached lists of available packages (which are stored, if you're curious, in /var/state/apt/lists). This is necessary for apt-get to determine which of your currently installed packages have been updated. The second command, apt-get -u upgrade, causes apt-get to actually fetch and install the new versions of your local outdated packages. Note that as with most other Linux package formats, the deb format includes pre- and post-installation scripts; therefore, it isn't necessarily a good idea to run an apt-get upgrade unattended, since one or more scripts may prompt you for configuration information. That's really all there is to it! Naturally, errors are possible: a common cause is outdated FTP/HTTP links in /etc/apt/sources.list. If apt-get seems to take too long to fetch package lists and/or reports that it can't find files, try deleting or replacing the sources.list entry corresponding to the server that apt-get was querying before it returned the error. For a current list of Debian download sites worldwide, see http://www.debian.org/distrib/ftplist. Another common error is new dependencies (ones that didn't apply when you originally installed a given package), which will cause apt-get to skip the affected package. This is fixed by simply invoking apt-get again, this time telling it to install the package plus any others on which it depends. For example, suppose that in the course of an upgrade session, apt-get reports that it's skipping the package blozzo. After apt-get finishes the rest of the upgrade session, you enter the command: apt-get install blozzo apt-get will then attempt to install the latest version of blozzo and will additionally do a more thorough job of trying to resolve its dependencies. If your old version of blozzo is hopelessly obsolete, however, it may be necessary to upgrade your entire distribution; this is done with the command apt-get -u dist-upgrade. Detailed instructions on using apt-get can be found in the apt-get(8) manpage, as well as in the APT HOWTO (available at http://www.debian.org/doc/manuals/apt-howto). To receive prompt, official notification of Debian security fixes, subscribe to the debian-security-announce email list. An online subscription form is available at http://www.debian.org/MailingLists/subscribe.
3.1.3 Deleting Unnecessary User Accounts and Restricting Shell AccessOne of the popular distributions' more annoying quirks is the inclusion of a long list of entries in /etc/passwd for application-specific user accounts, regardless of whether those applications are even installed. (For example, my SuSE 7.1 system created 48 entries during installation!) While few of these are privileged accounts, many can be used for interactive login (i.e., they specify a real shell rather than /bin/false). This is not unique to SuSE: my Red Hat 7.0 system created 33 accounts during installation, and my Debian 2.2 system installed 26. While it's by no means certain that a given unused account can and will be targeted by attackers, I personally prefer to err on the side of caution, even if that makes me look superstitious in some peoples' eyes. Therefore, I recommend that you check /etc/passwd and comment out any unnecessary entries. If you aren't sure what a given account is used for but see that account has an actual shell specified, one way to determine whether an account is active is to see whether it owns any files, and if so, when they were last modified. This is easily achieved using the find command. Suppose I have a recently installed web server whose /etc/passwd file contains, among many others, the following entry: yard:x:29:29:YARD Database Admin:/usr/lib/YARD:/bin/bash I have no idea what the YARD database might be used for. Manpage lookups and rpm queries suggest that it isn't even installed. Still, before I comment out yard's entry in /etc/passwd, I want to make sure the account isn't active. It's time to try find / -user and ls -lu (Example 3-7). Example 3-7. Using find with the -user flagroot@woofgang:~ # find / -user yard -print /usr/lib/YARD root@woofgang:~ # ls -lu /usr/lib/YARD/ total 20 drwxr-xr-x 2 yard yard 35 Jan 17 2001 . drwxr-xr-x 59 root root 13878 Dec 13 18:31 .. As we see in Example 3-7, yard owns only one directory, /usr/lib/YARD, and it's empty. Furthermore, according to ls -lu (which displays and lists files by access times), the directory hasn't been accessed since January 17. Since the system was installed in October, this date must refer to the directory's creation on my installation media by SuSE! Clearly, I can safely assume that this account isn't in use. Some accounts that are usually necessary if present are as follows:
Some accounts that are often unnecessary, at least on bastion hosts, are as follows:
If nothing else, you should change the final field (default shell), in unknown or process-specific accounts' entries in /etc/passwd, from a real shell to /bin/false only accounts used by human beings should need shells. 3.1.4 Restricting Access to Known UsersSome FTP daemons allow anonymous login by default. If your FTP server is intended to provide public FTP services, that's fine; but if it isn't, then there's no good reason to leave anonymous FTP enabled. The same goes for any other service running on a publicly accessible system: if that service supports but doesn't actually require anonymous connections, then the service should be configured to accept connections only from authenticated, valid users. Restricting access to FTP, HTTP, and other services is described in subsequent chapters. 3.1.5 Running Services in chrooted FilesystemsOne of our most important threat models is that of the hijacked daemon: if a malicious user manages to take over and effectively "become" a process on our system, he will assume the privileges on our system that that process has. Naturally, developers are always on the alert for vulnerabilities, such as buffer overflows, that compromise their applications, which is why you must keep on top of your distribution's security advisories and package updates. However, it's equally important to mitigate the risk of potential daemon vulnerabilities, i.e., vulnerabilities that might be unknown to anyone but the "bad guys." There are two primary means of doing so: running the process with as low a set of privileges as possible (see the next section) and running the process in a chroot jail. Normally, a process can see and interact with as much of a system's filesystem as the user account under which the process runs. Since most of the typical Linux host's filesystem is world-readable, that amounts to a lot of real estate. The chroot system call functionally transposes a process into a subset of the filesystem, effectively redefining the / directory for that process to a small subdirectory under the real root. For example, suppose a system has the following filesystem hierarchy (see Figure 3-4). Figure 3-4. Example network architecture For most processes and users, configuration files are found in /etc, commands are found in /usr/bin, and various "volatile" files such as logs are found in /var. However, we don't want our DNS daemon, named, to "see" the entire filesystem, so we run it chrooted to /var/named. Thus, from named's perspective, /var/named/etc is /etc, /var/named/usr/bin is /usr/bin, and /var/named/var appears as /var. This isn't a foolproof method of containment, but it helps. Many important network daemons now support command-line flags and other built-in means of being run chrooted. Subsequent chapters on these daemons describe in detail how to use this functionality. (Actually, almost any process can be run chrooted if invoked via the chroot command, but this usually requires a much more involved chroot jail than do commands with built-in chroot functionality. Most applications are compiled to use shared libraries and won't work unless they can find those libraries in the expected locations. Therefore, copies of those libraries must be placed in particular subdirectories of the chroot jail.)
3.1.6 Minimizing Use of SUID=rootNormally, when you execute a command or application, it runs with your user and group privileges. This is how file and directory permissions are enforced: when I, as user mick, issue the command ls /root, the system doesn't really know that mick is trying to see what's in root's home directory. It knows only that the command ls, running with mick's privileges, is trying to exercise read privileges on the directory /root. /root probably has permissions drwx------; so unless mick's UID is zero, the command will fail. Sometimes, however, a command's permissions include a set user-ID (SUID) bit or a set group-ID (SGID) bit, indicated by an "s" where normally there would be an "x" (see Example 3-8). Example 3-8. A program with its SUID bit set-rwsr-xr-x 1 root root 22560 Jan 19 2001 crontab This causes that command to run not with the privilege level of the user who executed it, but of the user or group who owns that command. If the owner's user or group ID is 0 (root), then the command will run with superuser privileges no matter who actually executes it. Needless to say, this is extremely dangerous! The SUID and SGID bits are most often used for commands and daemons that normal users might need to execute, but that also need access to parts of the filesystem not normally accessible to those users. For some utilities like su and passwd, this is inevitable: you can't change your password unless the command passwd can alter /etc/shadow (or /etc/passwd), but obviously, these files can't be directly writable by ordinary users. Such utilities are very carefully coded to make them nearly impossible to abuse. Some applications that run SUID or SGID have only limited need of root privileges, while others needn't really be run by unprivileged users. For example, mount is commonly run SUID=root, but on a server-class system there's no good reason for anybody but root to be mounting and unmounting volumes, so mount can therefore have its SUID bit unset. 3.1.6.1 Identifying and dealing with SUID=root filesThe simplest way to identify files with their SUID and SGID bits set is with the find command. To find all root-owned regular files with SUID and SGID set, we use the following two commands: find / -perm +4000 -user root -type f -print find / -perm +2000 -group root -type f -print If you determine that a file thus identified doesn't need to run SUID/SGID, you can use this command to unset SUID: chmod u-s /full/path/to/filename and this command to unset GUID: chmod g-s /full/path/to/filename Note that doing so will replace the SUID or SGID permission with a normal "x": the file will still be executable, just not with its owner's/group's permissions. Bastille Linux, the hardening utility covered later in this chapter, has an entire module devoted to unsetting SUID and SGID bits. However, Bastille deals only with some SUID files common to many systems; it doesn't actually identify all SUID/GUID files specific to your system. Therefore, by all means use Bastille to streamline this process, but don't rely solely on it.
3.1.7 Configuring, Managing, and Monitoring LogsThis is something we should do but often fail to follow through on. You can't check logs that don't exist, and you can't learn anything from logs you don't read. Make sure your important services are logging at an appropriate level, know where those logs are stored and whether/how they're rotated when they get large, and get in the habit of checking the current logs for anomalies. Chapter 10 is all about setting up, maintaining, and monitoring system logs. If you're setting up a system right now as you read this, I highly recommend you skip ahead to Chapter 10 before you go much further. 3.1.8 Every System Can Be Its Own Firewall: Using iptables for Local SecurityIn my opinion, the best Linux tool for logging and controlling access to local daemons is the same one we use to log and control access to the network: iptables (or ipchains, if you're still using a 2.2 kernel). I've said that it's beyond the scope of this book to cover Linux firewalls in depth, but let's examine some examples of using iptables to enhance local security.[1]
3.1.8.1 Using iptables: preparatory stepsFirst, you need a kernel compiled with netfilter, Linux 2.4's packet filtering code. Most distributions' stock 2.4 kernels should include support for netfilter and its most important supporting modules. If you compile your own kernel, though, this option is listed in the "networking" section of the make menuconfig GUI and is called "Network Packet Filtering."
In addition, under the subsection "IP: Netfilter Configuration," you should select "Connection Tracking," "IP tables support" and, if applicable, "FTP protocol support" and "IRC protocol support." Any of the options in the Netfilter Configuration subsection can be compiled either statically or as modules. (For our purposes i.e., for a server rather than a gateway you should not need any of the NAT or Packet Mangling modules.) Second, you need the iptables command. Your distribution of choice, if recent enough, almost certainly has a binary package for this; otherwise, you can download its source code from http://netfilter.samba.org. Needless to say, this code compiles extremely easily on Linux systems (good thing, since iptables and netfilter are supported only on Linux). Third, you need to formulate a high-level access policy for your system. Suppose you have a combination FTP and WWW server that you need to bastionize. It has only one (physical) network interface, as well as a routable IP address in our DMZ network (Figure 3-5). Figure 3-5. Example network architecture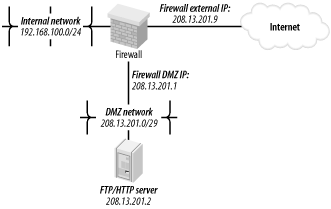 Table 3-1 shows a simple but complete example policy for this bastion host (not for the firewall, with which you should not confuse it).
Even such a brief sketch will help you create a much more effective iptables configuration than if you skip this step; it's analogous to sketching a flowchart before writing a C program. Having a plan before writing packet filters is important for a couple of reasons. First, a packet-filter configuration needs to be the technical manifestation of a larger security policy. If there's no larger policy, then you run the risk of writing an answer that may or may not correspond to an actual question. Second, this stuff is complicated and very difficult to improvise. Enduring several failed attempts and possibly losing productivity as a result may cause you to give up altogether. Packet filtering at the host level, though, is too important a tool to abandon unnecessarily. Returning to Table 3-1, we've decided that all inbound FTP and HTTP traffic will be permitted, as will administrative traffic via inbound SSH (see Chapter 4 if you don't know why this should be your only means of remote administration). The server itself will be permitted to initiate outbound pings (for diagnostic purposes), and DNS queries so our logs can contain hostnames and not just IP addresses. Our next task is to write iptables commands that will implement this policy. First, a little background. 3.1.8.2 How netfilter worksLinux 2.4's netfilter code provides the Linux kernel with "stateful" (connection-tracking) packet filtering, even for the complex FTP and IRC application protocols. This is an important step forward for Linux: the 2.2 kernel's ipchains firewall code was not nearly as sophisticated. In addition, netfilter has powerful Network Address Translation (NAT) features, the ability to "mangle" (rewrite the headers of) forwarded packets, and support for filters based on MAC addresses (Ethernet addresses) and on specific network interfaces. It also supports the creation of custom "chains" of filters, which can be matched against, in addition to the default chains. The bad news is that this means it takes a lot of reading, a strong grasp of TCP/IP networking, and some experimentation to build a firewall that takes full advantage of netfilter. The good news is that that's not what we're trying to do here. To use netfilter/iptables to protect a single host is much, much less involved than using it to protect an entire network. Not only are the three default filter chains INPUT, FORWARD, and OUTPUT sufficient; since our bastion host has only one network interface and is not a gateway, we don't even need FORWARD. (Unless, that is, we're using stunnel or some other local tunneling/redirecting technology.) Each packet that the kernel handles is first evaluated for routing: if destined for the local machine, it's checked against the INPUT chain. If originating from the local machine, it's checked against the OUTPUT chain. If entering a local interface but not destined for this host, it's checked against the FORWARD chain. This is illustrated in Figure 3-6. Figure 3-6. How each packet traverses netfilter's built-in packet-filter chains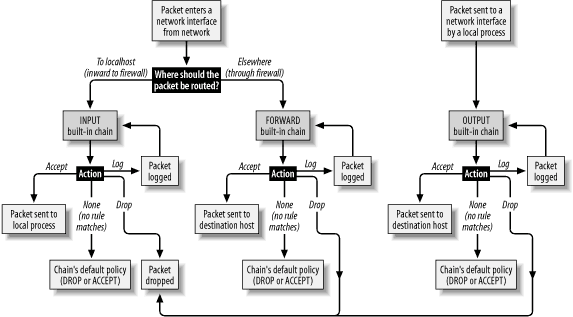 (Note that Figure 3-6 doesn't show the PREFILTER or POSTFILTER tables or how custom chains are handled; see http://netfilter.samba.org for more information on these.) When a rule matches a packet, the rule may ACCEPT or DROP it, in which case, the packet is done being filtered; the rule may LOG it, which is a special case wherein the packet is copied to the local syslog facility but also continues its way down the chain of filters; or the rule may transfer the packet to a different chain of filters (i.e., a NAT chain or a custom chain). If a packet is checked against all rules in a chain without being matched, the chain's default policy is applied. For INPUT, FORWARD, and OUTPUT, the default policy is ACCEPT, unless you specify otherwise. I highly recommend that the default policies of all chains in any production system be set to DROP. 3.1.8.3 Using iptablesThere are basically two ways to use iptables: to add, delete, and replace individual netfilter rules; and to list or manipulate one or more chains of rules. Since netfilter has no built-in means of recording or retaining rules between system boots, rules are typically added via startup script. Like route, iptables is a command you shouldn't have to invoke interactively too often outside of testing or troubleshooting scenarios. To view all rules presently loaded into netfilter, we use this command: iptables --list We can also specify a single chain to view, rather than viewing all chains at once: iptables --list INPUT To see numbered rules (by default, they're listed without numbers), use the --line-numbers option: iptables --line-numbers --list INPUT To remove all rules from all chains, we use: iptables --flush iptables --list is probably the most useful command-line invocation of iptables. Actually adding rules requires considerably more flags and options (another reason we usually do so from scripts). The basic syntax for writing iptables rules is: iptables -I [nsert] chain_name rule_# rule_specification
-D [elete]
-R [eplace]
-A [ppend]
where chain_name is INPUT, OUTPUT, FORWARD, or the name of a custom chain; rule_# is the number of the rule to delete, insert a new rule before, or replace; and rule_specification is the rest of the command line, which specifies the new rule. rule_# isn't used with -A, which appends the rule to the end of the specified chain. With -I, -D, and -R, the default rule_# is 1. For example, to delete the third rule in the OUTPUT chain, we'd use the command: iptables -D OUTPUT 3 To append a rule to the bottom of the INPUT chain, we'd use a command like the one in Example 3-9. Example 3-9. Appending a rule to the INPUT chainiptables -A INPUT -p tcp --dport 80 -j ACCEPT -m state --state NEW In Example 3-9, everything following the word INPUT makes up the command's Rule Specification. Table 3-2 is a simplified list of some of the most useful options that can be included in packet-filter (as opposed to NAT) Rule Specifications.
Table 3-2 is only a partial list, and I've omitted some flag options within that list in the interests of simplicity and focus. For example, the option -f can be used to match TCP packet fragments, but this isn't worth explaining here since it's rendered unnecessary by --state, which I recommend using on bastion hosts. At this point we're ready to dissect a sample iptables script. Example 3-9 continues our FTP/HTTP scenario and is in fact condensed from a working script on one of my SuSE servers (I've omitted SuSE-isms here, but the complete SuSE script is listed in the Appendix). If you want to see the whole thing, it's listed towards the end of this section and again in the Appendix. For now, though, we're going to take it a few lines at a time. Let's start with the commands at the beginning, which load some kernel modules and ensure that netfilter is starting empty (Example 3-10). Example 3-10. Initializing netfiltermodprobe ip_tables modprobe ip_conntrack_ftp # Flush old rules, old custom tables $IPTABLES --flush $IPTABLES --delete-chain # Set default-deny policies for all three default chains $IPTABLES -P INPUT DROP $IPTABLES -P FORWARD DROP $IPTABLES -P OUTPUT DROP We use modprobe rather than insmod because modprobe probes for and loads any additional modules on which the requested module depends. modprobe ip_conntrack_ftp, for example, loads not only the FTP connection-tracking module ip_conntrack_ftp, but also the generic connection-tracking module ip_conntrack, on which ip_conntrack_ftp depends. There's no reason for any rules or custom chains to be active yet, but to be sure we're starting out fresh, we use the --flush and --delete-chain commands. We then set all three default chains' default policies to DROP remember, the default is ACCEPT, which I strongly recommend against (being contrary to the Principle of Least Privilege). Moving on, we have loopback policies (Example 3-11). Example 3-11. Loopback policies# Give free reign to loopback interfaces $IPTABLES -A INPUT -i lo -j ACCEPT $IPTABLES -A OUTPUT -o lo -j ACCEPT Aha, our first Rule Specifications! They're very simple, too; they say "anything arriving or exiting on a loopback interface should be allowed." This is necessary because local applications such as the X Window System sometimes "bounce" data to each other over the TCP/IP stack via loopback. Next come some rules that match packets whose source IP addresses are non-Internet-routable and therefore presumed spoofed (Example 3-12). Example 3-12. Anti-IP-spoofing rules# Do some rudimentary anti-IP-spoofing drops $IPTABLES -A INPUT -s 255.0.0.0/8 -j LOG --log-prefix "Spoofed source IP!" $IPTABLES -A INPUT -s 255.0.0.0/8 -j DROP $IPTABLES -A INPUT -s 0.0.0.0/8 -j LOG --log-prefix "Spoofed source IP!" $IPTABLES -A INPUT -s 0.0.0.0/8 -j DROP $IPTABLES -A INPUT -s 127.0.0.0/8 -j LOG --log-prefix "Spoofed source IP!" $IPTABLES -A INPUT -s 127.0.0.0/8 -j DROP $IPTABLES -A INPUT -s 192.168.0.0/16 -j LOG --log-prefix "Spoofed source IP!" $IPTABLES -A INPUT -s 192.168.0.0/16 -j DROP $IPTABLES -A INPUT -s 172.16.0.0/12 -j LOG --log-prefix " Spoofed source IP!" $IPTABLES -A INPUT -s 172.16.0.0/12 -j DROP $IPTABLES -A INPUT -s 10.0.0.0/8 -j LOG --log-prefix " Spoofed source IP!" $IPTABLES -A INPUT -s 10.0.0.0/8 -j DROP $IPTABLES -A INPUT -s 208.13.201.2 -j LOG --log-prefix "Spoofed Woofgang!" $IPTABLES -A INPUT -s 208.13.201.2 -j DROP Prospective attackers use IP-spoofing to mimic trusted hosts that might be allowed by firewall rules or other access controls. One class of IP addresses we can easily identify as likely spoof candidates are those specified in RFC 1918 as "reserved for internal use": 10.0.0.0/8, 172.16.0.0/12, and 192.168.0.0/16. Addresses in these ranges are not deliverable over the Internet, so you can safely assume that any packet arriving at our Internet-connected host bearing such a source-IP is either a freak or an imposter. This assumption doesn't work if, for example, the internal network on the other side of your firewall is numbered with "RFC 1918 addresses" that are not translated or masqueraded by the firewall prior to arriving at your bastion host. This would be both unusual and unadvisable: you should treat your internal IP addresses as confidential data. But if not one word of this paragraph makes sense, don't worry: we're not going to consider such a scenario. If our bastion host's own IP address is used as a source IP of inbound packets, we can assume that that IP is bogus. One might use this particular brand of spoofed packet to try to trick the bastion host into showering itself with packets. If our example host's IP is 208.13.201.2, then the rule to block these is as follows: $IPTABLES -A INPUT -s 208.13.201.2 -j DROP which of course is what we've got in Example 3-13. Note that each of these antispoofing rules consists of a pair: one rule to log the packet, followed by the actual DROP rule. This is important: once a packet matches a DROP rule, it isn't checked against any further rules, but after a LOG action, the packet is. Anything you want logged, therefore, must be logged before being dropped. There's one other type of tomfoolery we want to squash early in our rule base, and that's the possibility of strange TCP packets (Example 3-13). Example 3-13. Anti-stealth-scanning rule# Tell netfilter that all TCP sessions do indeed begin with SYN $IPTABLES -A INPUT -p tcp ! --syn -m state --state NEW -j LOG --log-prefix "Stealth scan attempt?" $IPTABLES -A INPUT -p tcp ! --syn -m state --state NEW -j DROP This pair of rules addresses a situation in which the first packet to arrive from a given host is not a simple SYN packet, but is instead a SYN-ACK, a FIN, or some weird hybrid. Without these rules, such a packet would be allowed if netfilter interprets it as the first packet in a new permitted connection. Due to an idiosyncrasy (no pun intended) of netfilter's connection-tracking engine, this is possible. The odds are slim, however, that a SYN-less "new connection" packet is anything but a "Stealth scan" or some other form of skullduggery. Finally, we arrive at the heart of our packet-filtering policy the parts that are specific to our example bastion host. Let's start this section with the INPUT rules (Example 3-14). Example 3-14. The INPUT chain# Accept inbound packets that are part of previously-OK'ed sessions $IPTABLES -A INPUT -j ACCEPT -m state --state ESTABLISHED,RELATED # Accept inbound packets which initiate SSH sessions $IPTABLES -A INPUT -p tcp -j ACCEPT --dport 22 -m state --state NEW # Accept inbound packets which initiate FTP sessions $IPTABLES -A INPUT -p tcp -j ACCEPT --dport 21 -m state --state NEW # Accept inbound packets which initiate HTTP sessions $IPTABLES -A INPUT -p tcp -j ACCEPT --dport 80 -m state --state NEW # Log anything not accepted above $IPTABLES -A INPUT -j LOG --log-prefix "Dropped by default:" The first rule in this part of the INPUT chain tells netfilter to pass any inbound packets that are part of previously accepted and tracked connections. We'll return to the subject of connection tracking momentarily. The next rule allows new inbound SSH sessions to be started. SSH, of course, has its own access controls (passwords, DSA/RSA keys, etc.), but this rule would be even better if it limited SSH connections by source IP. Suppose for example's sake that our internal network is behind a firewall that performs IP Masquerading: all packets originating from the internal network are rewritten to contain the firewall's external or DMZ IP address as their source IPs. Since our bastion host is on the other side of the firewall, we can match packets coming from the entire internal network by checking for a source-IP address of the firewall's DMZ interface. Here's what our SSH rule would look like, restricted to internal users (assume the firewall's DMZ IP address is 208.13.201.1): $IPTABLES -A INPUT -p tcp -j ACCEPT -s 208.13.201.1 --dport 22 -m state --state NEW Since SSH is used only by our internal administrators to manage the FTP/HTTP bastion host and not by any external users (we hope), this restriction is a good idea. The next two rules in Example 3-14 allow new inbound FTP and HTTP connections, respectively. Since this is a public FTP/WWW server, we don't need to restrict these services by IP or network. But wait...isn't FTP a fairly complicated protocol? Do we need separate rules for FTP data streams in addition to this rule allowing FTP control channels? No! Thanks to netfilter's ip_conntrack_ftp module, our kernel has the intelligence to associate FTP PORT commands (used for directory listings and file transfers) with established FTP connections, in spite of the fact that PORT commands occur on random high ports. Our single FTP rule, along with our blanket "allow ESTABLISHED/RELATED" rule, is all we need. The last rule in our INPUT chain is sort of a "clean-up" rule. Since each packet traverses the chain sequentially from top to bottom, we can assume any packet that hasn't matched so far is destined for our chain's default policy, which of course is DROP. We don't need to go so far as to add an explicit DROP rule to the end of the chain, but if we want to log packets that make it that far, we do need a logging rule. This is the purpose of the last rule in Example 3-14, which has no match criteria other than the implied "this packet matches none of the above." The top four rules in Example 3-14 are the core of our INPUT policy: "allow new inbound SSH, FTP, and HTTP sessions, and all subsequent packets pertinent to them." Example 3-15 is an even shorter list of rules, forming the core of our OUTPUT chain. Example 3-15. OUTPUT chain of rules# If it's part of an approved connection, let it out $IPTABLES -I OUTPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT # Allow outbound ping (comment-out when not needed!) $IPTABLES -A OUTPUT -p icmp -j ACCEPT --icmp-type echo-request # Allow outbound DNS queries, e.g. to resolve IPs in logs $IPTABLES -A OUTPUT -p udp --dport 53 -m state --state NEW -j ACCEPT # Log anything not accepted above - if nothing else, for t-shooting $IPTABLES -A OUTPUT -j LOG --log-prefix "Dropped by default:" Again we begin with a rule permitting packets associated with already-established (allowed) connections. The next two rules are not strictly necessary, allowing as they do outbound ping and DNS Query transactions. ping is a useful tool for testing basic IP connectivity, but there have been various Denial of Service exploits over the years involving ping. Therefore, that particular rule should perhaps be considered temporary, pending our bastion host entering full production status. The outbound DNS is a convenience for whoever winds up monitoring this host's logs: without DNS, the system's system-logging facility won't be able to resolve IP addresses to names, making for more arduous log parsing. On the other hand, DNS can also slow down logging, so it may be undesirable anyhow. Regardless, it's a minimal security risk far less than that posed by ping so this rule is safely left in place if desired. Finally, we end with another rule to log "default DROPs." That's our complete policy! The full script is listed in Example 3-16 (and in even more complete form in Appendix A). Example 3-16. iptables script for a bastion host running FTP and HTTP services#! /bin/sh
# init.d/localfw
#
# System startup script for Woofgang's local packet filters
#
# last modified 30 Dec 2001 mdb
#
IPTABLES=/usr/sbin/iptables
test -x $IPTABLES || exit 5
case "$1" in
start)
echo -n "Loading Woofgang's Packet Filters"
# SETUP -- stuff necessary for any host
# Load kernel modules first
modprobe ip_tables
modprobe ip_conntrack_ftp
# Flush old rules, old custom tables
$IPTABLES --flush
$IPTABLES --delete-chain
# Set default-deny policies for all three default chains
$IPTABLES -P INPUT DROP
$IPTABLES -P FORWARD DROP
$IPTABLES -P OUTPUT DROP
# Give free reign to loopback interfaces
$IPTABLES -A INPUT -i lo -j ACCEPT
$IPTABLES -A OUTPUT -o lo -j ACCEPT
# Do some rudimentary anti-IP-spoofing drops
$IPTABLES -A INPUT -s 255.0.0.0/8 -j LOG --log-prefix "Spoofed source IP!"
$IPTABLES -A INPUT -s 255.0.0.0/8 -j DROP
$IPTABLES -A INPUT -s 0.0.0.0/8 -j LOG --log-prefix "Spoofed source IP!"
$IPTABLES -A INPUT -s 0.0.0.0/8 -j DROP
$IPTABLES -A INPUT -s 127.0.0.0/8 -j LOG --log-prefix "Spoofed source IP!"
$IPTABLES -A INPUT -s 127.0.0.0/8 -j DROP
$IPTABLES -A INPUT -s 192.168.0.0/16 -j LOG --log-prefix "Spoofed source IP!"
$IPTABLES -A INPUT -s 192.168.0.0/16 -j DROP
$IPTABLES -A INPUT -s 172.16.0.0/12 -j LOG --log-prefix " Spoofed source IP!"
$IPTABLES -A INPUT -s 172.16.0.0/12 -j DROP
$IPTABLES -A INPUT -s 10.0.0.0/8 -j LOG --log-prefix " Spoofed source IP!"
$IPTABLES -A INPUT -s 10.0.0.0/8 -j DROP
$IPTABLES -A INPUT -s 208.13.201.2 -j LOG --log-prefix "Spoofed Woofgang!"
$IPTABLES -A INPUT -s 208.13.201.2 -j DROP
# Tell netfilter that all TCP sessions do indeed begin with SYN
$IPTABLES -A INPUT -p tcp ! --syn -m state --state NEW -j LOG --log-prefix "Stealth scan
attempt?"
$IPTABLES -A INPUT -p tcp ! --syn -m state --state NEW -j DROP
# Finally, the meat of our packet-filtering policy:
# INBOUND POLICY
# Accept inbound packets that are part of previously-OK'ed sessions
$IPTABLES -A INPUT -j ACCEPT -m state --state ESTABLISHED,RELATED
# Accept inbound packets which initiate SSH sessions
$IPTABLES -A INPUT -p tcp -j ACCEPT --dport 22 -m state --state NEW
# Accept inbound packets which initiate FTP sessions
$IPTABLES -A INPUT -p tcp -j ACCEPT --dport 21 -m state --state NEW
# Accept inbound packets which initiate HTTP sessions
$IPTABLES -A INPUT -p tcp -j ACCEPT --dport 80 -m state --state NEW
# Log anything not accepted above
$IPTABLES -A INPUT -j LOG --log-prefix "Dropped by default:"
# OUTBOUND POLICY
# If it's part of an approved connection, let it out
$IPTABLES -I OUTPUT 1 -m state --state RELATED,ESTABLISHED -j ACCEPT
# Allow outbound ping (comment-out when not needed!)
$IPTABLES -A OUTPUT -p icmp -j ACCEPT --icmp-type echo-request
# Allow outbound DNS queries, e.g. to resolve IPs in logs
$IPTABLES -A OUTPUT -p udp --dport 53 -m state --state NEW -j ACCEPT
# Log anything not accepted above - if nothing else, for t-shooting
$IPTABLES -A OUTPUT -j LOG --log-prefix "Dropped by default:"
;;
wide_open)
echo -n "DANGER!! Unloading Woofgang's Packet Filters!!"
# Unload filters and reset default policies to ACCEPT.
# FOR EMERGENCY USE ONLY -- else use `stop'!!
$IPTABLES --flush
$IPTABLES -P INPUT ACCEPT
$IPTABLES -P FORWARD ACCEPT
$IPTABLES -P OUTPUT ACCEPT
;;
stop)
echo -n "Portcullis rope CUT..."
# Unload all fw rules, leaving default-drop policies
$IPTABLES --flush
;;
status)
echo "Querying iptables status (via iptables --list)..."
$IPTABLES --line-numbers -v --list
;;
*)
echo "Usage: $0 {start|stop|wide_open|status}"
exit 1
;;
esac
We've covered only a subset of netfilter's features, but it's an extremely useful subset. While local packet filters aren't a cure-all for system security, they're one of the thicker layers of our security onion, and well worth the time and effort it takes to learn iptables and fine-tune your filtering policies. 3.1.9 Checking Your Work with ScannersYou may have heard scare stories about how easy it is for evil system crackers to probe potential victims' systems for vulnerabilities using software tools readily available on the Internet. The bad news is that these stories are generally true. The good news is that many of these tools are extremely useful (and even designed) for the legitimate purpose of scanning your own systems for weaknesses. In my opinion, scanning is a useful step in the system-hardening process, one that should be carried out after most other hardening tasks are completed and that should repeated periodically as a sanity check. Let's discuss, then, some uses of nmap and nessus, arguably the best port scanner and security scanner (respectively) available for Linux. 3.1.9.1 Types of scans and their usesThere are basically two types of system scans. Port scans look for open TCP and UDP ports i.e., for "listening services." Security scans go a step further and probe identified services for known weaknesses. In terms of sophistication, doing a port scan is like counting how many doors and windows a house has; running a security scan is more like rattling all the doorknobs and checking the windows for alarm sensors. 3.1.9.2 Why we (good guys) scanWhy scan? If you're a system cracker, you scan to determine what services a system is running and which well-known vulnerabilities apply to them. If you're a system administrator, you scan for essentially the same reasons, but in the interest of fixing (or at least understanding) your systems, not breaking into them. It may sound odd for good guys to use the same kinds of tools as the bad guys they're trying to thwart. After all, we don't test dead-bolt locks by trying to kick down our own doors. But system security is exponentially more complicated than physical security. It's nowhere near as easy to gauge the relative security of a networked computer system as is the door to your house. Therefore, we security-conscious geeks are obliged to take seriously any tool that can provide some sort of sanity check, even an incomplete and imperfect one (as is anything that tries to measure a moving target like system security). This is despite or even because of that tool's usefulness to the bad guys. Security and port scanners give us the closest thing to a "security benchmark" as we can reasonably hope for. 3.1.9.3 nmap, world champion port scannerThe basic premise of port scanning is simple: if you try to connect to a given port, you can determine whether that port is closed/inactive or whether an application (i.e., web server, FTP dæmon, etc.) is accepting connections there. As it happens, it is easy to write a simple port scanner that uses the local connect( ) system call to attempt TCP connections on various ports; with the right modules, you can even do this with Perl. However, this method is also the most obtrusive and obvious way to scan, and it tends to result in numerous log entries on one's target systems. Enter nmap, by Fyodor. nmap can do simple connect( ) scans if you like, but its real forte is stealth scanning . Stealth scanning uses packets that have unusual flags or don't comply with a normal TCP state to trigger a response from each target system without actually completing a TCP connection. nmap supports not one, but four different kinds of stealth scans, plus TCP Connect scanning, UDP scanning, RPC scanning, ping sweeps, and even operating-system fingerprinting. It also boasts a number of features more useful to black-hat than white-hat hackers, such as FTP-bounce scanning, ACK scanning, and Window firewall scanning (many of which can pass through firewalls undetected but are of little interest to this book's highly ethical readers). In short, nmap is by far the most feature-rich and versatile port-scanner available today. Here, then, is a summary of the most important types of scans nmap can do:
Whew! Quite a list of scanning methods and I've left out ACK scans and Window scans (see the manpage nmap(1), if you're interested). nmap has another very useful feature: OS fingerprinting. Based on characteristics of a target's responses to various arcane packets that nmap sends, nmap can make an educated guess as to which operating system each target host is running. 3.1.9.4 Getting and installing nmapSo useful and popular is nmap that it is now included in most Linux distributions. Red Hat 7.0 and Debian 2.2, my two current flavors of choice, both come with nmap (under Applications/System and Extra/Net, respectively). Therefore, the easiest way for most Linux users to install nmap is via their system's package manager (e.g., RPM, dselect, or YAST) and preferred OS installation medium (CD-ROM, FTP, etc.).
If, however, you want the very latest version of nmap or its source code, both are available from http://www.insecure.org/ (Fyodor's web site) in RPM and TGZ formats. Should you wish to compile nmap from source, simply download and expand the tarball, and then enter the commands listed in Example 3-17 (allowing for any difference in the expanded source code's directory name; nmap v2.54 may be obsolete by the time you read this). Example 3-17. Compiling nmaproot@woofgang: # cd nmap-2.54BETA30 root@woofgang: # ./configure root@woofgang: # make root@woofgang: # make install 3.1.9.5 Using nmapThere are two different ways to run nmap. The most powerful and flexible way is via the command prompt. There is also a GUI called nmapfe, which constructs and executes an nmap scan for you (Figure 3-7). Figure 3-7. Sample nmapfe session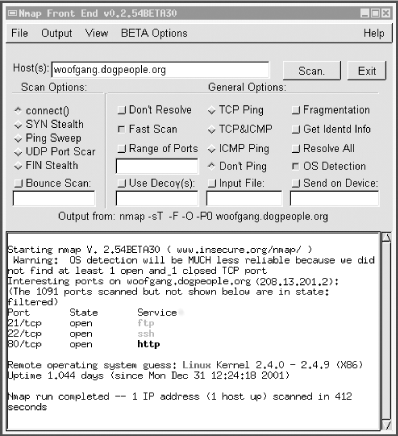 nmapfe is useful for quick-and-dirty scans or as an aid to learning nmap's command-line syntax. But I strongly recommend learning nmap proper: nmap is quick and easy to use even without a GUI. The syntax for simple scans is as follows: nmap [-s (scan-type)] [-p (port-range)]|-F (options) target The -s flag must be immediately followed by one of the following:
(If the -s flag is omitted altogether, the default scan type is TCP Connect.) For example, -sSUR tells nmap to perform a SYN scan, a UDP scan, and finally an RPC scan/identification on the specified target(s). -sTSR would fail, however, since TCP Connect and TCP SYN are both TCP scans. If you state a port range using the -p flag, you can combine commas and dashes to create a very specific group of ports to be scanned. For example, typing -p 20-23,80,53,600-1024 tells nmap to scan ports 20 through 23, 80, 53, and 600 through 1024. Don't use any spaces in your port range, however. Alternatively, you can use the -F flag (short for "fast scan"), which tells nmap to scan only those ports listed in the file /usr/share/nmap/nmap-services; these are ports Fyodor has found to frequently yield interesting results. The "target" expression can be a hostname, a host IP address, a network IP address, or a range of IP addresses. Wildcards may be used. For example, 192.168.17.* expands to all 255 IP addresses in the network 192.168.17.0/24 (in fact, you could use 192.168.17.0/24 instead); 10.13.[1,2,4].* expands to 10.13.1.0/24, 10.13.2.0/24, and 10.13.4.0/24. As you can see, nmap is very flexible in the types of target expressions it understands. 3.1.9.6 Some simple port scansLet's examine a basic scan (Example 3-18). This is my favorite "sanity check" against hardened systems: it's nothing fancy, but thorough enough to help validate the target's iptables configuration and other hardening measures. For this purpose, I like to use a plain-vanilla TCP Connect scan, since it's fast and since the target is my own system i.e., there's no reason to be stealthy. I also like the -F option, which probes nearly all "privileged ports" (0-1023) plus the most commonly used "registered ports" (1024-49,151). This can take considerably less time than probing all 65,535 TCP and/or UDP ports. Another option I usually use is -P0, which tells nmap not to ping the target. This is important for the following reasons:
The other option I like to include in my basic scans is -O, which attempts " OS fingerprinting." It's good to know how obvious certain characteristics of my systems are, such as Operating System, kernel version, uptime, etc. An accurate nmap OS fingerprint of one of my painstakingly hardened bastion hosts never fails to provide me with an appropriately humble appreciation of how exposed any host on the Internet is: there's always some measure of intelligence that can be gained in this way. And so we come to our example scan (Example 3-18). The output was obtained using nmap Version 2.54BETA30 (the most current as of this writing) running on Red Hat 7.0. The target system is none other than woofgang, the example FTP/WWW server we've been bastionizing throughout this chapter. Example 3-18. Simple scan against a bastion host[root@mcgruff]# nmap -sT -F -P0 -O woofgang.dogpeople.org Starting nmap V. 2.54BETA30 ( www.insecure.org/nmap/ ) Warning: OS detection will be MUCH less reliable because we did not find at least 1 open and 1 closed TCP port Interesting ports on woofgang.dogpeople.org (208.13.201.2): (The 1091 ports scanned but not shown below are in state: filtered) Port State Service 21/tcp open ftp 22/tcp open ssh 80/tcp open http Remote operating system guess: Linux Kernel 2.4.0 - 2.4.9 (X86) Uptime 1.163 days (since Mon Dec 31 12:24:18 2001) Nmap run completed 1 IP address (1 host up) scanned in 127 seconds (Notice anything familiar about the scan in Example 3-18? It's identical to the one portrayed in Figure 3-7!) Good, our bastion host responded exactly the way we expected: it's listening on TCP ports 21, 22, and 80 and not responding on any others. So far, our iptables configuration appears to be doing the job. Note that despite warning us to the contrary, nmap correctly guessed woofgang's Operating System, and it also gleaned its uptime! nmap doesn't go so far as guessing which distribution, but it does a remarkable job of identifying which version of the Linux kernel is being run. (The target was running 2.4.17, which is extremely close to nmap's guess of "2.4.0-2.4.9.") Let's add just a couple of options to this scan to make it more comprehensive. First, let's include UDP. We're not expecting to see any listening UDP ports. This is achieved by adding a "U" to our -s specification i.e., -sTU. While we're at it, let's throw in RPC too; our bastion host shouldn't be accepting any Remote Procedure Call connections. Like the UDP option, this can be added to our TCP scan directive e.g., -sTUR. The UDP and RPC scans go particularly well together: RPC is a UDP-intensive protocol. When nmap finds an RPC service on an open port, it appends the RPC application's name in parentheses, including the version number, if nmap can make a credible guess at one. Our new, beefier scan is shown in Example 3-19. Example 3-19. A more comprehensive scan[root@mcgruff]# nmap -sTUR -F -P0 -O woofgang.dogpeople.org Starting nmap V. 2.54BETA30 ( www.insecure.org/nmap/ ) Warning: OS detection will be MUCH less reliable because we did not find at least 1 open and 1 closed TCP port Interesting ports on woofgang.dogpeople.org (208.13.201.2): (The 2070 ports scanned but not shown below are in state: filtered) Port State Service (RPC) 21/tcp open ftp 22/tcp open ssh 80/tcp open http Remote operating system guess: Linux Kernel 2.4.0 - 2.4.9 (X86) Uptime 1.180 days (since Mon Dec 31 12:24:18 2001) Nmap run completed 1 IP address (1 host up) scanned in 718 seconds Whew, no surprises: nmap found no UDP or RPC listening ports. Interestingly, the scan took a long time: 718 seconds, just shy of 12 minutes! This is because woofgang is running netfilter and is configured to drop nonallowed packets rather than to "reject" them. Without netfilter, the kernel would reply to attempted connections on inactive ports with "icmp port-unreachable" and/or TCP RST packets, depending on the type of scan. In the absence of these courteous replies, nmap is compelled to wait for each connection attempt to timeout before concluding the port isn't open, making for a lengthy scan. nmap isn't stupid, however: it reported that "The 2070 ports scanned but not shown below are in state: filtered." So, is our bastion host secure? Clearly it's on the right track, but let's perform one more sanity check: a security scan. 3.1.9.7 Nessus, a full-featured security scannerSeeing what "points of entry" a host offers is a good start in evaluating that host's security. But how do we interpret the information nmap gives us? For example, in Examples 3-7 and 3-8, we determined that the host woofgang is accepting SSH, FTP, and HTTP connections. But just what does this mean? Sure, we know that this host is running a web server on TCP port 80, an FTP server on TCP 21, and a SSH daemon on TCP port 22. But which of these services are actually exploitable, and if so, how? This is where security scanners come into play. At the risk of getting ahead of ourselves, let's look at the output from a Nessus scan of woofgang (Figure 3-8). Figure 3-8. Nessus scan of woofgang Space doesn't permit me to show the entire (expanded) report, but even in this abbreviated version, we can see that Nessus identified one apparent "hole" (vulnerability) in our target system. It also generated three warnings and provided five supplemental security notes. 3.1.9.8 Security Scanners ExplainedWhereas a port scanner like nmap (which, again, is the gold standard in port scanners) tells you what's listening, a security scanner like Nessus tells you what's vulnerable. Since you need to know what's listening before even trying to probe for actual weaknesses, security scanners usually either contain or are linked to port scanners. As it happens, Nessus invokes nmap as the initial step in each scan. Once a security scanner has determined which services are present, it performs various checks to determine which software packages are running, which version each package seems to have, and whether they're subject to any known vulnerabilities. Predictably, this level of intelligence requires a good vulnerability database that must be updated periodically as new vulnerabilities come to light. Ideally, the database should be user editable i.e., it should be possible for you to create custom vulnerability tests particular to your environment and needs. This also ensures that should the scanner's developer not immediately release an update for a new vulnerability, you can create the update yourself. Not all security scanners have this level of customizability, but Nessus does. After a security scanner locates, identifies, and analyzes the listening services on each host it's been configured to scan, it creates a report of its findings. The better scanners don't stop at pointing out vulnerabilities; they explain them in detail and suggest how to fix them. So meaty are the reports generated by good security scanners that highly paid consultants have been known to present them as the primary deliverables of supposedly comprehensive security audits. This is a questionable practice, but it emphasizes the fact that a good security scan produces a lot of data. There are a number of free security scanners available: VLAD, SAINT, and Nessus are just a few. Nessus, however, stands out as a viable alternative to powerful commercial products such as ISS' Internet Scanner and NAI's CyberCop Scanner. Developed primarily by Renaud Deraison and Jordan Hrycaj, Nessus surely ranks with the GIMP and Apache as tools that equal and often exceed the usability and flexibility of their commercial counterparts. 3.1.9.9 Nessus' architectureNessus has two major parts: a server, which runs all scans, and a client, with which you control scans and view reports. This distributed architecture makes Nessus flexible and also allows you to avoid monopolizing your workstation's CPU cycles with scanning activities. It also allows you to mix and match platforms: you can use the Unix variant of your choice as the server, with your choice of X-windows, Java, or MS-Windows clients. (Note, however, that the Java client no longer appears to be in active development.) nessusd listens for client connections on TCP port 3001 and also TCP 1241 (1241 was recently assigned to Nessus by the Internet Assigned Numbers Authority; 3001 will be phased out eventually). Client sessions are authenticated using an El Gamal-based public-key scheme and encrypted using a stream cipher whose session key is negotiated dynamically for each connection. In this regard, Nessus' "cipher layer" (implemented by Jordan Hrycaj using his libpeks library) behaves very similarly to SSL. Nessus' client component, nessus, can be configured either to log in transparently (i.e., with no password associated with your private key) or with a password that protects your private key and thus prevents unauthorized users from connecting to the Nessus server from your workstation. Once you've connected with a Nessus server, you're presented with a list of "plug-ins" (vulnerability tests) supported by the server and a number of other options. If you've installed Nessus "experimental features," you may also be given the option to run a "detached" scan that can continue running even if you close your client session; the scan's output will be saved on the server for you to retrieve later. A whole page of options pertaining to the creation and maintenance of a Knowledge Base can also be compiled in, which allows you to store scan data and use it to track your hosts' security from scan to scan (e.g., to run "differential" scans). Note that these are both experimental features; they must be explicitly compiled into Nessus due to minor stability issues, but these will have been fixed (and the features fully integrated) by the time Nessus Version 1.2 is released. I mention them here because the Detached Scan feature, in particular, is a good example of the value of Nessus' client-server architecture. Once you've configured and begun a scan, Nessus invokes each appropriate module and plug-in as specified and/or applicable, beginning with an nmap scan. The results of one plug-in's test may affect how or even whether subsequent tests are run; Nessus is pretty intelligent that way. When the scan is finished, the results are sent back to the client. (If the session-saving feature is enabled, the results may also be stored on the server.) 3.1.9.10 Getting and installing NessusNessus, like most open source packages, is available in both source-code and binary distributions. Red Hat 7.x binaries of Nessus Version 1.1.8 (the latest development/beta version at this writing) are available from http://freshrpms.org, courtesy of Matthias Saou. If you don't use Red Hat 7, if your distribution doesn't have its own Nessus packages, or if you want to use experimental features, you'll need to compile Nessus from source. Not to worry, though. If you install a few prerequisites and follow Nessus' installation instructions, this should not be a big deal. The Nessus FAQ (http://www.nessus.org/doc/faq.html) and Nessus Mailing List (http://list.nessus.org) provide ample hints for compiling and installing Nessus. Nessus' prerequisites are as follows:
Once you've installed these, your distribution may have further prerequisites; I'm personally aware of two such situations. First, gmp-2.0 is needed for Red Hat 7.0 (which usually includes gmp-3.0, but not 2.0; you'll need to use rpm's --force option if you install gmp-2.0 with gmp-3.0 already in place, which won't break anything). This package is available from http://www.redhat.com/swr/i686/gmp-2.0.2-5.i686.html. Second, to install or compile Nessus on SuSE Linux, you must first install the packages bison, flex, gtkdev, and glibdev. See http://www.nessus.org/posix.html for more details. After all prerequisites are in place, you're ready to compile or install your Nessus packages. The compiling process has been fully automated: simply download the file nessus-installer.sh from one of the sites listed at http://www.nessus.org/posix.html, and invoke it with the command: sh ./nessus-installer.sh to automatically configure, compile, and install Nessus from source. nessus-installer.sh is an interactive script. You will be prompted for some paths and asked whether to include the "experimental" session-saving and knowledge-base features. Session saving allows both crash recovery (e.g., the resumption of a scan interrupted by an application or OS crash) and Detached Scans (see earlier). The knowledge-base feature allows you to store scan results in a database on the server, which, in turn, allows you to run differential scans. I highly recommend compiling in these features; I've noticed no added instability as a result. The installation script may take a while to prepare source code and even longer to compile it. Make sure you've got plenty of space on the volume where /tmp resides: this is where the installer unzips and builds the Nessus source-code tree. If in doubt, you can rename /tmp to /tmp.bak and create a symbolic link named /tmp that points to a volume with more space. After everything's been built and installed, you'll have several new binaries in /usr/local/bin and /usr/local/sbin, a large collection of Nessus plug-ins in /usr/local/lib/nessus/plugins, and new manpages for the Nessus programs nessus, nessus-adduser, getpass, and nessus-update-plugins. You'll be presented with this message (Example 3-20). Example 3-20. "Success" message from nessus-installer.sh--------------------------------------------------------------------------------
Nessus installation : Finished
--------------------------------------------------------------------------------
Congratulations ! Nessus is now installed on this host
. Create a nessusd certificate using $prefix/sbin/nessus-mkcert
. Add a nessusd user use $prefix/sbin/nessus-adduser
. Start the Nessus daemon (nessusd) use $prefix/sbin/nessusd -D
. Start the Nessus client (nessus) use $prefix/bin/nessus
. To uninstall Nessus, use $prefix/sbin/uninstall-nessus
. A step by step demo of Nessus is available at :
http://www.nessus.org/demo/
Press ENTER to quit
Note that the first bullet point is incorrect: there is no nessus-mkcert binary. To generate your nessusd certificate automatically, simply enter the command nessusd: the first time it's run, the daemon will generate its own certificate and then quit. The other instructions, though (beginning with "Add a nessusd user..."), are correct.
3.1.9.11 Nessus clientsUnless you're only going to use the Nessus server as its own client (i.e., run both nessusd and nessus on the same host), you'll need to perform additional installations of Nessus on each host you wish to use as a client. While the Nessus server (the host running nessusd) must be a Unix host, clients can run on either Unix or MS Windows. Compiling and installing Nessus on Unix client machines is no different than on servers (as described earlier). Installing any of the Windows clients (WinNessus, NessusW, and NessusWX) is a bit simpler, as all three are available in binary form. Personally, of the three, I prefer WinNessus, since it so closely resembles the Unix GUI (I'm lazy that way!). All three Windows clients are available at http://www.nessus.org/win32.html. Before we talk about proper use of the Nessus client, though, we'd better start our daemon. 3.1.9.12 Running and maintaining nessusdSo we're back at our Nessus server's console and ready to fire up nessusd for the first time. nessusd is different from many other daemons in that it can either be invoked as a "proper" daemon (i.e, running in the background) or with flags and parameters that reconfigure Nessus. To actually start the daemon in "daemon mode," we enter nessusd -D &. As we'd expect with a client-server application, we also need to create some Nessus user accounts on our server. These are independent of the server's local Unix user accounts. Nessus accounts can be created in two ways. First and quickest, we can invoke nessusd with the -P flag, immediately followed with a username and a "one-time" password. This neither interferes with a running nessusd daemon nor starts a new one; it does, however, immediately update Nessus' user database and transparently restarts the daemon. For example, to add user "bobo" with a password of "scuz00DL", we enter the following: nessusd -P bobo,scuz00DL The password ("scuz00DL" in the previous example) is called a "one-time" password because by default, after bobo first logs in and gives this password, his public key will be registered with the Nessus server. Subsequent logins will not require him to enter this password again (they'll be authenticated transparently using an SSL-like challenge-response transaction). The second and more powerful way to create new user accounts on the server is to use the nessus-adduser command. This script actually does most of its magic by invoking nessusd, but presents you with a convenient interface for managing users with more granularity than a simple nessusd -P. You are prompted not only for a username and one-time password, but also IP addresses from which the user may connect and rules that restrict which hosts the user may scan with Nessus. I leave it to you to read the nessus-adduser manpage if you're interested in this level of user-account management. Our remaining space here is better spent discussing how to build, run, and interpret Nessus scans. Before we leave the topic of authentication, though, I should mention the other kind of authentication Nessus uses, this one local to each client session. When you start nessus for the first time (the client, not the daemon), you are prompted for a passphrase. This passphrase protects a private key that's stored in the home directory of the Unix account you're logged into when you start nessus, and you'll be prompted for it whenever you start nessus. Then, when you connect to a Nessus server, your private key will be used in the transparent challenge-response transaction described earlier that actually authenticates you to the remote nessusd process. If all this seems confusing, don't worry: just remember that the password you're prompted for each time you start nessus has nothing to do with the password you use the first time you connect to a Nessus server. 3.1.9.13 Performing security scans with NessusAnd now the real fun begins! After Nessus has been installed and at least one user account set up, you're ready to scan. First, start a client session, and enter your client-private-key's passphrase when prompted (by the way, you can change or delete this passphrase with the command nessus -C, which will prompt you for your current passphrase and what you'd like to change it to). Next, enter the name or IP address of the "Nessusd host" (server) to which you wish to connect, the port on which it's listening, your preferred encryption method (the default should be fine), and your Nessus login/username (Figure 3-9). The defaults for Port and Encryption are usually fine. Figure 3-9. User "Bobo's" first login to a Nessus server When you're ready to connect, click the "Log in" button. If this is the first time you've connected to the server using the specified login, you'll be prompted for your "one-time" password (next time, you won't be). With that, you should be connected and ready to build a scan! If you click the "Plugins" tab, you're presented with a list of all vulnerability tests available on the Nessus server, grouped by "family" (Figure 3-10). Click on a family's name (these are listed in the upper half of the window) to see a list of that family's plug-ins below. Click on a family's checkbox to enable or disable all its plug-ins. Figure 3-10. Plugins screen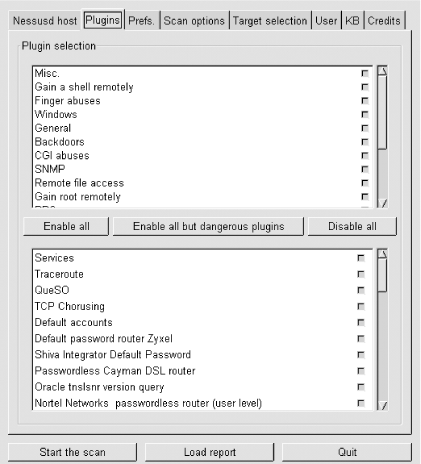 If you don't know what a given plug-in does, click on its name: an information window will pop up. If you "hover" the mouse pointer over a plug-in's name, a summary caption will pop up that states very briefly what the plug-in does. Plug-ins with yellow triangles next to their checkboxes are dangerous: the particular tests they perform have the potential to interrupt or even crash services on the target (victim) host. By the way, don't be too worried about selecting all or a large number of plug-ins: Nessus is intelligent enough to skip, for example, Windows tests on non-Windows hosts. In general, Nessus is efficient in deciding which tests to run and in which circumstances. The next screen to configure is "Prefs" (Figure 3-11). Contrary to what you might think, this screen contains not general, but plug-in-specific preferences, some of which are mandatory for their corresponding plug-in to work properly. Be sure to scroll down the entire list and provide as much information as you can. Take particular care with the Ping section (at the very top): more often than not, selecting either ping method (TCP or ICMP) can cause Nessus to decide mistakenly that hosts are down when in fact they are up. Nessus will not perform any tests on a host that doesn't reply to pings; so when in doubt, don't ping.
Figure 3-11. Plugins Prefs screen After Prefs comes "Scan Options" (Figure 3-12). Note that the Nessus installation in Figure 3-12 was compiled with the "Save Session" feature, as evidenced by the "Detached Scan" and "Continuous Scan" options, which would otherwise be absent.
Figure 3-12. Scan options screen The "Optimize the test" option tells Nessus to avoid all apparently inapplicable tests, but this can at least theoretically result in "false negatives." Balance the risk of false negatives against the advantage of a complete scan as quickly as possible. Speaking of speed, if you care about it, you probably want to avoid using the "Do a reverse (DNS) lookup..." feature, which attempts to determine the hostnames for all scanned IP addresses. Now we specify our targets. We specify these in the "Target(s):" field of the "Target Selection" screen (Figure 3-13). This can contain hostnames, IP addresses, network addresses in the format x.x.x.x/y (where x.x.x.x is the network number and y is the number of bits in the subnet mask e.g., 192.168.1.0/24), in a comma-separated list. Figure 3-13. Target selection screen The "Perform a DNS zone transfer option" instructs Nessus to obtain all available DNS information on any domain names or subdomain names referred to in the "Target(s):" box. Note that most Internet DNS servers are configured to deny zone-transfer requests to TCP port 53 by unknown hosts. The other options in this screen have to do with the experimental Save Session feature I mentioned earlier see http://www.nessus.org/documentation.html for more information on what the experimental features do and how to use them. Finally, one last screen before we begin our scan (we're skipping "KB," which applies only if you've compiled and wish to use the Knowledge Base features): "User" (Figure 3-14). In this screen, we can change our client passphrase (this has the same effect as nessus -C), and we can fine-tune the targets we specified in the "Target selection" screen. Figure 3-14. User screen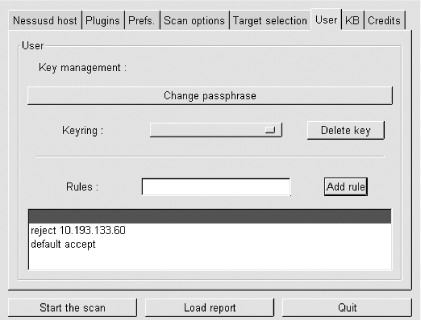 The specifications you type in this text box are called "rules," and they follow a simple format: accept address, deny address, or default [accept | reject]. The rules listed in Figure 3-14 mean "don't scan 10.193.133.60, but scan everything else specified in the Target screen." Finally, the payoff for all our careful scan setup: click the "Start the scan" button at the bottom of the screen. The scan's length will vary, depending mainly on how many hosts you're scanning and how many tests you've enabled. The end result? A report such as that shown earlier in Figure 3-8. From the Report window, you can save the report to a file, besides viewing the report and drilling down into its various details. Supported report file formats include HTML, ASCII, LATEX, and of course a proprietary Nessus Report format, "NSR" (which you should use for reports from which you wish to view again within Nessus). Read this report carefully, be sure to expand all "+" boxes, and fix the things Nessus turns up. Nessus can find problems and can even suggest solutions, but it won't fix things for you. Also, Nessus won't necessarily find everything wrong with your system. Returning to our woofgang example (see Figure 3-8), Nessus has determined that woofgang is running a vulnerable version of OpenSSH! Even after all the things we've done so far to harden this host, there's still a major vulnerability to take care of. We'll have to upgrade woofgang's OpenSSH packages before putting this system into production. Interestingly, I had run yast2's "Online Update" utility on the host I used in these examples, but evidently not recently enough to catch the new OpenSSH packages. This is an excellent illustration of how judicious use of security scanning can augment your other security practices. 3.1.10 Understanding and Using Available Security FeaturesThis corollary to the principle of least privilege is probably one of the most obvious but least observed. Since many applications' security features aren't enabled by default (running as an unprivileged user, running in a chroot jail, etc.), those features tend not to be enabled, period. Call it laziness or call it a logical aversion to fixing what doesn't seem to be broken, but many people tinker with an application only enough to get it working, indefinitely postponing that crucial next step of securing it too. This is especially easy to justify with a server that's supposedly protected by a firewall and maybe even by local packet filters: it's covered, right? Maybe, but maybe not. Firewalls and packet filters protect against certain types of network attacks (hopefully, most of them), but they can't protect you against vulnerabilities in the applications that firewalls/filters still allow. As we saw with woofgang, the server we hardened with iptables and then scanned with nmap and Nessus, it only takes one vulnerable application (OpenSSH, in this case) to endanger a system. It's therefore imperative that a variety of security strategies and tools are employed. This is called "Defense in Depth," and it's one of the most important concepts in information security. 3.1.11 Documenting Bastion Hosts' ConfigurationsFinally, document the steps you take in configuring and hardening your bastion hosts. Maintaining external documentation of this kind serves three important functions. First, it saves time when building subsequent, similar systems. Second, it helps you to rebuild the system quickly in the event of a hard-drive crash, system compromise, or any other event requiring a "bare-metal recovery." Third, good documentation can also be used to disseminate important information beyond one key person's head. (Even if you work alone, it can keep key information from being lost altogether should it get misplaced somewhere in that head!) |
|
|
|
