| [ Team LiB ] |
|
7.1 BrownSauceAfter you've worked with RDF/XML for a while, you can read the formatted data and the structures quite easily. However, many people prefer to use a visual tool of some form for this purpose. There are graphical tools and editors, which I'll discuss later, but for now I want to demonstrate BrownSauce, a specialized RDF/XML browser. One of the most useful tools I used while writing this book was BrownSauce, a Java-based RDF/XML browser created by Damian Steer. It's web based but can run locally on your desktop even if you don't have a web server installed; the only requirement is a Java Runtime Environment (JRE). BrownSauce parses RDF/XML documents and transforms them into a very readable format. One of its better features is its addition of hypertext links from the properties and classes in the RDF/XML document to the actual vocabulary schema definition in a separate page.
Once you've downloaded and installed BrownSauce, following the installation instructions, start the Java-based server that allows you to access the application by double-clicking on run.bat if you're running a Windows system or by running run.sh in a shell if you're a Unix or Mac OS X user. BrownSauce starts in port 8080 by default so you'll access the browser (typically) using: http://localhost:8080/brownsauce/brownsauce.html When the main BrownSauce page opens, you're shown two rows of form fields. The first row contains fields for entering a source and a resource URI. The first two fields enable browsing for a specific RDF resource within a given RDF/XML document. This tends to be what I use. For instance, to look at the example RDF/XML document used in the previous chapters, I'll enter the following values: Source: http://burningbird.net/articles/monsters1.rdf Resource: http://burningbird.net/articles/monsters1.htm The page that opens, shown in Figure 7-1, displays all the predicates for the resource and their associated values. Figure 7-1. BrownSauce opening page for monsters1.rdf RDF/XML document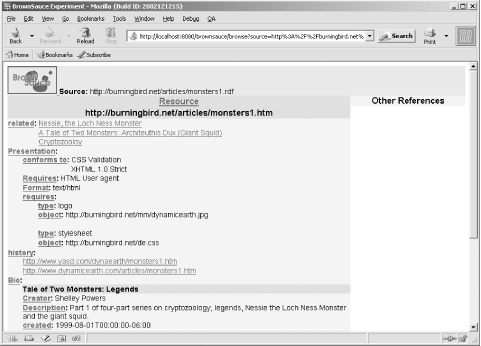 As you can see from the figure, the display is quite easy to read, making effective use of whitespace. All non-hypertext-linked values are literals from the modelthose items that would be drawn with a rectangular box within an RDF directed graph. What's interesting is that BrownSauce looked for a subproperty of rdfs:label in this case the dc:title attribute from the main resource and actually used different CSS styling in the page to make it stand out. (Yet another reason to make use of existing vocabularies such as Dublin Core as much as possible: many tools will already be aware of them and able to treat them specially.) In addition, BrownSauce also made other subtle modifications to the values it found to make the content more readable. As an illustration, the pstcn:currentStatus predicate was displayed as Current Status in the document. The label was, again, pulled from the rdfs:label property within the PostCon schemaanother reason to make sure your RDF Schema document is up-to-date and accessible. BrownSauce also resolves some of the more complex RDF/XML constructs. For instance, the rdf:Seq that lists the history of a specific resource defined in the document is shown only by the predicate name, with hypertext link items to each event's resource for additional information. In addition, the use of rdf:value, which is a structured resource, is resolved to the type information (pstcn:type) and an object reference to the actual value itself. All of the predicates are hypertext linked. If you click on one of them, information from the schema for the item is displayed. Clicking on Current Status opens a new page with schema information for the status element, as shown in Figure 7-2. Figure 7-2. Schema definition for PostCon currentStatus property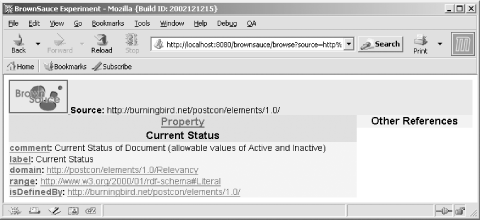 BrownSauce loads all the schemas from all the vocabularies, so no matter what predicate you click, you should find the schema definition if one has been provided. And if rdfs:comment and rdfs:label predicates are used, these will be shown also. (Yet another reason to make sure you use RDFS predicates rather than Dublin Core to describe schema elements, as some vocabularies have done.) You can modify BrownSauce's appearance by modifying the accompanying bs.css file. Schemas are cached, which makes reading additional documents using the same schemas quicker. BrownSauce doesn't provide parsed access to data, nor does it allow you to edit it. What it does do is provide a human-readable format for examining RDF/XML documents. In particular, if you're defining domain data using RDF/XML, BrownSauce allows the domain experts who may not be RDF literate a chance to look at the data without having to be comfortable with either XML or RDF/XML. No matter how comfortable you are with RDF/XML, BrownSauce is a great tool to test your documents, your vocabulary, and the vocabulary's associated schema. |
| [ Team LiB ] |
|
