| [ Team LiB ] |
|
7.2 ParsersRDF/XML parsers are usually included as part of a broader API. For instance, Jena has a parser, as do other APIs in other languages. Parsers aren't typically accessed directly, however, because you generally want to do something else with all that data after parsing it into an application-specific stream of data. However, accessing parsers directly can be handy for a couple of reasons. The primary reason is to validate an RDF/XML documenta compliant RDF/XML parser should return meaningful error messages and warnings when it encounters erroneous or suspicious RDF/XML. Another reason to run a parser directly is to create another serialization of the RDF/XML, but in a different format, such as a set of N-Triples. When I'm creating a new RDF application, I run my example RDF/XML documents through an N-Triples parser to get the N-Triples; I then use these to help with my coding of the application.
In this section, we'll take a quick look at some parsers, beginning with ARP, the parser that forms the core of the well-used RDF Validator. 7.2.1 ARP2ARP stands for Another RDF/XML Parser. ARP2 is the second generation of this parser, which has been modified to work with the newest RDF specifications. ARP is part of the Jena Toolkit, discussed in Chapter 8, but is also a separate installation in its own right. You can download and install ARP without having to download and install Jena. However, you have to have Java installed, at least JRE 1.4 or above.
Normally ARP is used within another application, but there is one class that you can access at the command line as a method of testing the viability of your RDF/XML documentthe NTriple class. Once ARP2 is installed, you can run NTriple from the command line thus: java com.hp.hpl.jena.rdf.arp.NTriple http://burningbird.net/articles/monsters1.rdf NTriple produces either a listing of N-Triples from the RDF/XML, or produces errors if there's something wrong with the syntax. A partial sampling of the command-line output from the parser of the file shown in the command line is given in Example 7-1. Example 7-1. Sample output from triples generated by ARPhttp://burningbird.net/articles/monsters1.htm> <http://www.w3.org/1999/02/22-rdf-syntax- ns#type> <http://burningbird.net/postcon/elements/1.0/Resource> . _:jARP1 <http://purl.org/dc/elements/1.1/title> "Tale of Two Monsters: Legends" . _:jARP1 <http://purl.org/dc/terms/abstract> "\n When I think of \"monsters\" I think of the creatures of \n legends and tales, from the books and movies, and \n I think of the creatures that have entertained me for years.\n \t " . _:jARP1 <http://purl.org/dc/elements/1.1/description> "\n Part 1 of four-part series on cryptozoology, legends, \n Nessie the Loch Ness Monster and the giant squid.\n " . _:jARP1 <http://purl.org/dc/elements/1.1/created> "1999-08-01T00:00:00-06:00" . _:jARP1 <http://purl.org/dc/elements/1.1/creator> "Shelley Powers" . _:jARP1 <http://purl.org/dc/elements/1.1/publisher> "Burningbird Network" . <http://burningbird.net/articles/monsters1.htm> <http://burningbird.net/postcon/elements/ 1.0/Bio> _:jARP1 . _:jARP2 <http://burningbird.net/postcon/elements/1.0/currentStatus> "Active" . _:jARP2 <http://purl.org/dc/terms/valid> "2003-12-01T00:00:00-06:00" . _:jARP2 <http://purl.org/dc/elements/1.1/subject> "legends" . _:jARP2 <http://purl.org/dc/elements/1.1/subject> "giant squid" . _:jARP2 <http://purl.org/dc/elements/1.1/subject> "Loch Ness Monster" . _:jARP2 <http://purl.org/dc/elements/1.1/subject> "Architeuthis Dux" . _:jARP2 <http://purl.org/dc/elements/1.1/subject> "Nessie" . _:jARP2 <http://purl.org/dc/terms/isReferencedBy> "http://www.pibburns.com/cryptozo.htm" . _:jARP2 <http://purl.org/dc/terms/references> "http://www.nrcc.utmb.edu/" . <http://burningbird.net/articles/monsters1.htm> <http://burningbird.net/postcon/elements/ 1.0/Relevancy> _:jARP2 . Notice that the parser returns annotated text, showing line returns and maintaining the integrity of the text as it found it in the document.
The NTriple command format is: java <class-path> com.hp.hpl.jena.arp.NTriple ( [ -[xstfu]][ -b xmlBase -[eiw] NNN[,NNN...] ] [ file ] [ url ] )... Note, though, that with the release of ARP2 that I downloaded (which was alpha), I had to change the classpath to com.hp.hpl.jena.rdf.arp.NTriple. NTriple can work with files on a filesystem or accessed through a URL. The other options for NTriple are given in Table 7-1.
In particular, if you're working with the new RDF/XML specification constructs, such as rdf:nodeID or rdf:datatype, you may want to test it with ARP, suppressing triples. Example 7-2 shows an RDF/XML document that's actually generated by Jena. It features the newer rdf:nodeID attribute, which breaks down on older parsers. However, I modified the file to change one of the legitimate uses of rdf:resource to rdf:about (in bold). Example 7-2. RDF/XML document with one error<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:NS0='http://burningbird.net/postcon/elements/1.0/'
xmlns:dc='http://purl.org/dc/elements/1.0/'
>
<rdf:Description rdf:nodeID='A0'>
<dc:creator>Shelley Powers</dc:creator>
<dc:publisher>Burningbird</dc:publisher>
<dc:title xml:lang='en'>Tale of Two Monsters: Legends</dc:title>
</rdf:Description>
<rdf:Description rdf:about='http://burningbird.net/articles/monsters1.htm'>
<NS0:related rdf:about='http://burningbird.net/articles/monsters2.htm'/>
<NS0:related rdf:resource='http://burningbird.net/articles/monsters3.htm'/>
<NS0:Bio rdf:nodeID='A0'/>
</rdf:Description>
</rdf:RDF>
Running the NTriple application with the -t option returns the following error from this file: C:\>java com.hp.hpl.jena.rdf.arp.NTriple -t c:\writing\rdfbook\java\pracRDFThird
.rdf
Error: file:/c:/writing/rdfbook/java/pracRDFThird.rdf[12:77]: {E201} Syntax error
when processing attribute rdf:about.
Cannot have attribute rdf:about in this context.
As you can see, ARP2 not only finds the error, it also gives you the location of the error and the reason the error occurs. ARP2 works from the command line only, but if you're more interested in a parser with a GUI frontend, you might want to try out ICS-FORTH's Validating RDF Parser. 7.2.2 ICS-FORTH Validating RDF ParserThe ICS-FORTH Validating RDF Parser (VRP), like ARP, is part of a suite of tools but can also be downloaded separately. In addition, again like ARP, the only requirement to run the tool is a Java Runtime Environment installed, JRE 1.4 or up.
VRP is a set of Java classes that you can use within your own Java classes. However, the parser also comes with a Swing-based GUI frontend that you can use directly without having to touch any code. To access the GUI for the parser, once you've downloaded and unzipped the file containing the source, you're ready to start using it. Start up the parser by typing the following line: java -classpath <path to VRP directory>/classes GUI.VRPGUI The page that opens has two text input fields, one for an input file and one for recording the results. Below these are a set of checkboxes that switch on specific tests, such as ones for checking the syntax, checking for class hierarchy loops, and so on. Figure 7-3 shows the tool after I validated the test document (at http://burningbird.net/articles/monsters1.rdf ), asking for validation only and having the tool test the syntax and class and property hierarchy loops. VRP can also open an HTML or XHTML document with RDF/XML embedded in it (as described in Chapter 3). Figure 7-3. ICS-FORTH'sValidating RDF Parser (VRP) standalone application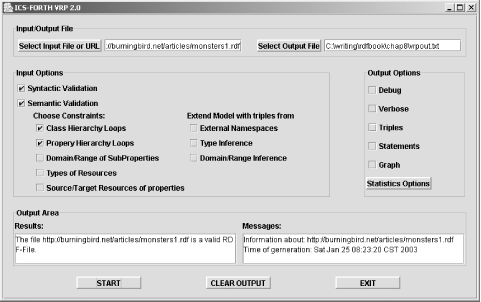 As you can see from the image, VRP has several input and output options. For instance, I can run the test again, this time checking the Triples, Statements, and Graph options for output. The tool first asks me for permission to overwrite the output file and then runs the tests, printing output to the Results window in the application as well as to the file. The Graph option provides a text description of what would be the RDF directed graph rather than a true graphical representation. A sampling from this file, the classes as defined in the RDFS graph output, are shown in Example 7-3. Note that the information associated with each schema class, such as the isDefinedBy, comment, and label information, isn't showing in the graph, though we know it to be present in the schema. Example 7-3. VRP graph results describing document's classesThe classes of the Model: http://burningbird.net/postcon/elements/1.0/#Movement subClassOf: [] comment: [] label: [] seeAlso: [] isDefinedBy: [] value: [] type: [] http://www.w3.org/1999/02/22-rdf-syntax-ns#Seq subClassOf: [] comment: [] label: [] seeAlso: [] isDefinedBy: [] value: [] type: [] http://burningbird.net/postcon/elements/1.0/#Resource subClassOf: [] comment: [] label: [] seeAlso: [] isDefinedBy: [] value: [] type: [] The version of the tool I used expands the absolute URIs for the classes and properties by converting them to URI fragments, such as #Resource and #Movement, before concatenating them to the URI. The base URI is specified with a trailing slash, just as occurs with the Dublin Core schema. The relative URIs should not have been "corrected" to URI fragments before resolution into absolute URIs. Because of this correction, the schema elements could not resolve correctly (as they did within BrownSauce).
This could be why the tool didn't pick up the schema information for the items, or why it may not open related schema documents. Hard to say. One thing the tool does do is correctly resolve the RDF classes in the document, as compared to the RDF properties. This can be very helpful when you're creating an RDF Schema for a vocabulary and do not recall which elements are classes and which are properties. The checks you can perform on a specific document are:
The semantic check for types of resources failed with all models I tested this against, including Dublin Core, RSS, and FOAF (Friend of a Friend) RDF/XML documents. This check is looking for a specific type information for each resource, something not available in most models. However, the example PostCon vocabulary file (at http://burningbird.net/articles/monsters1.rdf ) did pass all other tests. When I selected the option to include external namespace triples, the model again failed, but the results as a graph were quite interesting. The results include information from the schema for PostCon, such as the following for the pstcn:movementType property: http://burningbird.net/postcon/elements/1.0/movementType range: [http://www.w3.org/2000/01/rdf-schema#Literal] domain: [http://postcon/elements/1.0/Movement] subPropertyOf: [] links: comment: [Type of Movement (allowable values of Move, Add, Remove)] label: [Movement Type] seeAlso: [] isDefinedBy: [http://burningbird.net/postcon/elements/1.0/] value: [] type: [http://www.w3.org/1999/02/22-rdf-syntax-ns#Property] Notice the links property and that it has no value. However, later in the document, you'll see the graph for pstcn:movementType: http://burningbird.net/postcon/elements/1.0/#movementType range: [] domain: [] subPropertyOf: [] links: (http://www.yasd.com/dynaearth/monsters1.htm, Add) (http://www. dynamicearth.com/articles/monsters1.htm, Move) (http:/burningbird.net/articles/ monsters1.htm, Move) comment: [] label: [] seeAlso: [] isDefinedBy: [] value: [] type: [] Again, the automatic use of fragment identifiers breaks the information up; however, combine both blocks and you have a relatively good idea of all the dimensions of the PostCon property pstcn:movementType. In addition to Graph, other VRP outputs are:
I would definitely consider running VRP against an in-progress vocabulary while you're designing your schema and then try it with External Namespaces as a test with some of your models as a check on the schema. |
| [ Team LiB ] |
|
